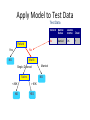
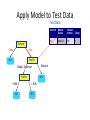
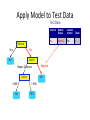
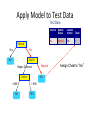
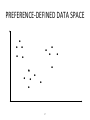
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
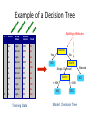
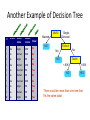
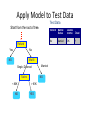
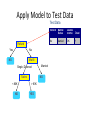
CEEC 2015 TUTORIAL: TEXT ANALYTICS Uni Essex Kruschwitz, Poesio, AlthobaiG Language & ComputaGon Group THE PLAN FOR THE TUTORIAL • 14-‐15: Lecture 1, Intro to NLP & InformaGon Retrieval (Kruschwitz) • 15-‐16: Lecture 2, Text Mining (Poesio) • 16-‐16:30: Coffee break • 16:30-‐17:30: Lab, SenGment Analysis (Poesio) • 17:30-‐18:30: Lab, GATE/NER (AlthobaiG) WEB PAGE • h`p://csee.essex.ac.uk/staff/poesio/Teach/ TextAnalyGcsTutorial/ Text AnalyGcs Massimo Poesio Lecture 2: Machine Learning in NLP / ClassificaGon / SenGment Analysis / Stylometry / InformaGon ExtracGon APPLICATIONS OF TEXT ANALYTICS • Text analyGcs techniques are widely used these days, for at least two reasons: 1. The explosion of the Web in general and of social media in parGcular, and the increasing shie to digital documents, have enormously increased both the need to manage these textual data and the desire to take advantage of the opportunity 2. For a number of these tasks, decent results can be obtained using methods that do not require high-‐performance linguisGc processing EXAMPLE: IS THIS SPAM? From: "" <[email protected]> Subject: real estate is the only way... gem oalvgkay Anyone can buy real estate with no money down Stop paying rent TODAY ! There is no need to spend hundreds or even thousands for similar courses I am 22 years old and I have already purchased 6 properGes using the methods outlined in this truly INCREDIBLE ebook. Change your life NOW ! =========================================== ====== Click Below to order: h`p://www.wholesaledaily.com/sales/nmd.htm =========================================== ====== Dear Hamming Seminar Members The next Hamming Seminar will take place on Wednesday 25th May and the details are as follows Who: Dave Robertson Title: Formal Reasoning Gets Social Abstract: For much of its history, formal knowledge representation has aimed to describe knowledge independently of the personal and social context in which it is used, with the advantage that we can automate reasoning with such knowledge using mechanisms that also are context independent. This sounds good until you try it on a large scale and find out how sensitive to context much of reasoning actually is. Humans, however, are great hoarders of information and sophisticated tools now make the acquisition of many forms of local knowledge easy. The question is: how to combine this beyond narrow individual use, given that knowledge (and reasoning) will inevitably be contextualised in ways that may be hidden from the people/systems that may interact to use it? This is the social side of knowledge representation and automated reasoning. I will discuss how the formal reasoning community has adapted to this new view of scale. When: 4pm, Wednesday 25 May 2011 Where: Room G07, Informatics Forum There will be wine and nibbles afterwards in the atrium café area. EXAMPLE: IS THIS SPAM? Palm Garden Hotel E-Newsletter February, 2013 Aroi Dee Thai Restaurant Tel: (603) 8943 2233 Tantalising Thai Cuisine Love Thai Cuisine? A visit to Aroi Dee Thai Restaurant is a must. With our team of talented and experienced Thai Chefs, taste the tantalising and authentic dishes they prepare. A selection of Nyonya cuisine also available ... more Aroi Dee Thai Restaurant Tel: (603) 8943 2233 Chinese New Year Set Menus on 28 Jan - 24 Feb A 9 course menu featuring Prosperity Combination Yee Sang and Jelly Fish as the starter. This is followed by Braised Assorted Seafood Soup with Beancurd and Fish Roe, Roasted Crispy Chicken Cantonese Style and Steamed Red Mullet Fish with Light Soya Sauce. Continue the meal with Wok Fried Prawns with Marmite Sauce, Braised Mushroom with Beancurd and Broccoli and Steamed Lotus Leaf Rice with Yam and Assorted Preserved Meat. Complete the meal with refreshing desserts of Chilled Sea Coconut and Sno more THE ROLE OF MACHINE LEARNING • In modern text analyGcs, instead of giving the program an algorithm to do a task, we give an algorithm for learning how to do the task • Specifically, given a set of examples, the system learns a funcGon that does a good job of expressing the relaGonship: – Categorizing email messages as a funcGon from emails to their category (spam, useful) – A checker playing strategy a funcGon from moves to their values (winning, losing) SUPERVISED AND UNSUPERVISED METHODS • Both supervised and unsupervised ML is used in text analyGcs – Supervised: spam detecGon, senGment analysis, informaGon extracGon – Unsupervised: document clustering, summarizaGon CLASSIFICATION SPAM NON-‐SPAM EXAMPLE: DECISION TREES • A DECISION TREE is a classifier in the form of a tree structure, where each node is either a: – Leaf node - indicates the value of the target attribute (class) of examples, or – Decision node - specifies some test to be carried out on a single attribute-value, with one branch and sub-tree for each possible outcome of the test. • A decision tree can be used to classify an example by starGng at the root of the tree and moving through it unGl a leaf node, which provides the classificaGon of the instance. Example of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No 5 No Divorced 95K Yes 6 No Married No 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes 60K Splitting Attributes Refund Yes No NO MarSt Single, Divorced TaxInc < 80K NO NO > 80K YES 10 Training Data Married Model: Decision Tree Another Example of Decision Tree 10 Tid Refund Marital Status Taxable Income Cheat 1 Yes Single 125K No 2 No Married 100K No 3 No Single 70K No 4 Yes Married 120K No 5 No Divorced 95K Yes 6 No Married No 7 Yes Divorced 220K No 8 No Single 85K Yes 9 No Married 75K No 10 No Single 90K Yes 60K Married MarSt NO Single, Divorced Refund No Yes NO TaxInc < 80K NO > 80K YES There could be more than one tree that fits the same data! Decision Tree ClassificaGon Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K No 2 No Medium 100K No 3 No Small 70K No 4 Yes Medium 120K No 5 No Large 95K Yes 6 No Medium 60K No 7 Yes Large 220K No 8 No Small 85K Yes 9 No Medium 75K No 10 No Small 90K Yes Tree Induction algorithm Induction Learn Model Model 10 Training Set Tid Attrib1 Attrib2 11 No Small 55K ? 12 Yes Medium 80K ? 13 Yes Large 110K ? 14 No Small 95K ? 15 No Large 67K ? 10 Test Set Attrib3 Apply Model Class Deduction Decision Tree Apply Model to Test Data Test Data Start from the root of tree. Refund Yes 10 No NO MarSt Single, Divorced TaxInc < 80K NO Married NO > 80K YES Refund Marital Status Taxable Income Cheat No 80K Married ? Apply Model to Test Data Test Data Refund Yes 10 No NO MarSt Single, Divorced TaxInc < 80K NO Married NO > 80K YES Refund Marital Status Taxable Income Cheat No 80K Married ? Apply Model to Test Data Test Data Refund 10 Yes No NO MarSt Single, Divorced TaxInc < 80K NO Married NO > 80K YES Refund Marital Status Taxable Income Cheat No 80K Married ? Apply Model to Test Data Test Data Refund 10 Yes No NO MarSt Single, Divorced TaxInc < 80K NO Married NO > 80K YES Refund Marital Status Taxable Income Cheat No 80K Married ? Apply Model to Test Data Test Data Refund 10 Yes No NO MarSt Single, Divorced TaxInc < 80K NO Married NO > 80K YES Refund Marital Status Taxable Income Cheat No 80K Married ? Apply Model to Test Data Test Data Refund No NO MarSt Single, Divorced TaxInc NO Taxable Income Cheat No 80K Married ? 10 Yes < 80K Refund Marital Status Married NO > 80K YES Assign Cheat to “No” Decision Tree ClassificaGon Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K No 2 No Medium 100K No 3 No Small 70K No 4 Yes Medium 120K No 5 No Large 95K Yes 6 No Medium 60K No 7 Yes Large 220K No 8 No Small 85K Yes 9 No Medium 75K No 10 No Small 90K Yes Tree Induction algorithm Induction Learn Model Model 10 Training Set Tid Attrib1 Attrib2 11 No Small 55K ? 12 Yes Medium 80K ? 13 Yes Large 110K ? 14 No Small 95K ? 15 No Large 67K ? 10 Test Set Attrib3 Apply Model Class Deduction Decision Tree Decision Tree InducGon • Many Algorithms: – Hunt’s Algorithm (one of the earliest) – CART – ID3, C4.5 – SLIQ,SPRINT WORD-‐BASED METHODS • In many cases, machine learning methods applied to text analyGcs tasks can achieve decent results relying only on the occurrence of WORDS – Or on meta-‐features easily extractable from a document IS THIS SPAM? From: "" <[email protected]> Subject: real estate is the only way... gem oalvgkay Anyone can buy real estate with no money down Stop paying rent TODAY ! There is no need to spend hundreds or even thousands for similar courses I am 22 years old and I have already purchased 6 properGes using the methods outlined in this truly INCREDIBLE ebook. Change your life NOW ! ================================================= Click Below to order: h`p://www.wholesaledaily.com/sales/nmd.htm ================================================= TEXT CATEGORIZATION • Given: – A descripGon of an instance, x∈X, where X is the instance language or instance space. • Issue: how to represent text documents. – A fixed set of categories: C = {c1, c2,…, cn} • Determine: – The category of x: c(x)∈C, where c(x) is a categoriza<on func<on whose domain is X and whose range is C. • We want to know how to build categorizaGon funcGons (“classifiers”). Document ClassificaGon “planning! language! proof! intelligence”! Testing! Data:! (AI)! (Programming)! (HCI)! Classes:! ML! Training! Data:! Planning! Semantics! Garb.Coll.! Multimedia! learning! planning! programming! garbage! ...! intelligence! temporal! semantics! collection! algorithm! reasoning! language! memory! reinforcement! plan! proof...! optimization! network...! language...! region...! GUI! ...! (Note: in real life there is oeen a hierarchy, not present in the above problem statement; and you get papers on ML approaches to Garb. Coll.) TEXT CLASSIFICATION WITH DT • Build a separate decision tree for each category • Use WORDS COUNTS as features Reuters Data Set (21578 -‐ ModApte split) • 9603 training, 3299 test arGcles; ave. 200 words • 118 categories – An arGcle can be in more than one category – Learn 118 binary category disGncGons Common categories (#train, #test) • Earn (2877, 1087) • Acquisitions (1650, 179) • Money-fx (538, 179) • Grain (433, 149) • Crude (389, 189) • Trade (369,119) • Interest (347, 131) • Ship (197, 89) • Wheat (212, 71) • Corn (182, 56) 28 AN EXAMPLE OF REUTERS TEXT FoundaGons of StaGsGcal Natural Language Processing, Manning and Schuetze Decision Tree for Reuter classificaGon FoundaGons of StaGsGcal Natural Language Processing, Manning and Schuetze SPAM CLASSIFICATION WITH DECISION TREES • One of the best known spam detectors, SpamAssassin, was based on decision trees SpamAssassin Features 100 From: address is in the user's black-list 4.0 Sender is on www.habeas.com Habeas Infringer List 3.994 Invalid Date: header (timezone does not exist) 3.970 Written in an undesired language 3.910 Listed in Razor2, see http://razor.sf.net/ 3.801 Subject is full of 8-bit characters 3.472 Claims compliance with Senate Bill 1618 3.437 exists:X-Precedence-Ref 3.371 Reverses Aging 3.350 Claims you can be removed from the list 3.284 'Hidden' assets 3.283 Claims to honor removal requests 3.261 Contains "Stop Snoring" 3.251 Received: contains a name with a faked IP-address 3.250 Received via a relay in list.dsbl.org 3.200 set indicates a foreign language 600.465 - Intro toCharacter NLP - J. Eisner 32 SpamAssassin Features 3.198 Forged eudoramail.com 'Received:' header found 3.193 Free Investment 3.180 Received via SBLed relay, seehttp://www.spamhaus.org/sbl/ 3.140 Character set doesn't exist 3.123 Dig up Dirt on Friends 3.090 No MX records for the From: domain 3.072 X-Mailer contains malformed Outlook Expressversion 3.044 Stock Disclaimer Statement 3.009 Apparently, NOT Multi Level Marketing 3.005 Bulk email software fingerprint (jpfree) found inheaders 2.991 exists:Complain-To 2.975 Bulk email software fingerprint (VC_IPA) found inheaders 2.968 Invalid Date: year begins with zero 2.932 Mentions Spam law "H.R. 3113" 2.900 Received forged, contains fake AOL relays 2.879 600.465 - Intro toAsks NLP - J. for credit card details Eisner 33 SpamAssassin Features 2.858 To: username at front of subject 2.851 Claims you actually asked for this spam 2.842 To header contains 'recipient' marker 2.826 Compare Rates 2.800 Received: says mail bounced all around the world 2.800 Mentions Spam Law "UCE-Mail Act" 2.796 Received via buggy SMTP server (MDaemon2.7.4SP4R) 2.795 Bulk email software fingerprint (StormPost) foundin headers 2.786 Broken CGI script message 2.784 Message-Id generated by a spam tool 2.783 Urges you to call now 2.782 Tells you it's an ad 2.782 RAND found, spammer forgot to run the random-IDgenerator 2.748 Cable Converter 2.744 No Age Restrictions 2.737 porn - Celebrity Porn 600.465 - Intro toPossible NLP - J. Eisner 34 SpamAssassin Features 2.782 Tells you it's an ad 2.782 RAND found, spammer forgot to run the random-IDgenerator 2.748 Cable Converter 2.744 No Age Restrictions 2.737 Possible porn - Celebrity Porn 2.735 Bulk email software fingerprint (JiXing) found inheaders 2.730 DNSBL: sender is Confirmed Spam Source 2.726 Bulk email software fingerprint (MMailer) found inheaders 2.720 exists:X-Encoding 2.720 DNSBL: sender is Confirmed Open Relay 2.702 SEC-mandated penny-stock warning -- thanks SEC 2.695 Claims you can be removed from the list 2.693 Removes Wrinkles 2.668 Offers a stock alert 2.660 Listed in DCC, seehttp://rhyolite.com/anti-spam/dcc/ 2.658 pyramid scheme phrase (1) 600.465 - Intro toCommon NLP - J. Eisner 35 OTHER LEARNING METHODS USED FOR TEXT CATEGORIZATION • Bayesian methods (Naïve Bayes) • Neural nets (e.g. ,perceptron) • Vector-‐space methods (k-‐NN, Rocchio, unsupervised) • SVMs PRACTICAL CORNER: ML TOOLS • These days one doesn’t need to implement one’s own machine learning algorithms, many freely available, open source playorms exist • Best known: WEKA – Supports most best known ML algorithms – Easy to use graphical interface – Can be downloaded from h`p://www.cs.waikato.ac.nz/ml/weka/ 22/09/2015 University of Waikato 38 INPUT FILES @relaGon heart-‐disease-‐simplified @a`ribute age numeric @a`ribute sex { female, male} @a`ribute chest_pain_type { typ_angina, asympt, non_anginal, atyp_angina} @a`ribute cholesterol numeric @a`ribute exercise_induced_angina { no, yes} @a`ribute class { present, not_present} @data 63,male,typ_angina,233,no,not_present 67,male,asympt,286,yes,present 67,male,asympt,229,yes,present 38,female,non_anginal,?,no,not_present ... 22/09/2015 39 Supervised vs. unsupervised learning • The setup for document classificaGon we just saw is called supervised learning in Machine Learning • In the domain of text, various names – Text classificaGon, text categorizaGon – Document classificaGon/categorizaGon – “AutomaGc” categorizaGon – RouGng, filtering … • In some cases however we don’t know the classes in advance • In this case we talk of unsupervised learning – Presumes no availability of training samples – Clusters output may not be themaGcally unified. Unsupervised methods for text analyGcs: (document) clustering • Clustering = discovering similariGes between objects – Individuals, Documents, … • ApplicaGons: – Recommender systems – Document organizaGon Recommending: restaurants • We have a list of all Wivenhoe restaurants – with ↑ and ↓ raGngs for some – as provided by some Uni Essex students / staff • Which restaurant(s) should I recommend to you? Input Algorithm 0 • Recommend to you the most popular restaurants – say # posiGve votes minus # negaGve votes • Ignores your culinary preferences – And judgements of those with similar preferences • How can we exploit the wisdom of “like-‐ minded” people? Another look at the input -‐ a matrix Now that we have a matrix View all other entries as zeros for now. PREFERENCE-‐DEFINED DATA SPACE . . . . . . . . . . . . . . . . 47 Similarity between two people • Similarity between their preference vectors. • Inner products are a good start. • Dave has similarity 3 with EsGe – but -‐2 with Cindy. • Perhaps recommend Black Buoy to Dave – and Bakehouse to Bob, etc. Algorithm 1.1 • You give me your preferences and I need to give you a recommendaGon. • I find the person “most similar” to you in my database and recommend something he likes. • Aspects to consider: – No a`empt to discern cuisines, etc. – What if you’ve been to all the restaurants he has? – Do you want to rely on one person’s opinions? Algorithm 1.k • You give me your preferences and I need to give you a recommendaGon. • I find the k people “most similar” to you in my database and recommend what’s most popular amongst them. • Issues: – A priori unclear what k should be – Risks being influenced by “unlike minds” Slightly more sophisGcated a`empt • Group similar users together into clusters • You give your preferences and seek a recommendaGon, then – Find the “nearest cluster” (what’s this?) – Recommend the restaurants most popular in this cluster • Features: – avoids data sparsity issues – sGll no a`empt to discern why you’re recommended what you’re recommended – how do you cluster? CLUSTERS • Can cluster Cindy Alice, Bob Fred .. Dave, EsGe …. DOCUMENT CLUSTERING • Consider clustering a large set of computer science documents – what do you expect to see in the vector space? Arch. Graphics Theory NLP AI DOCUMENTS AS BAGS OF WORDS DOCUMENT broad tech stock rally may signal trend -‐ traders. technology stocks rallied on tuesday, with gains scored broadly across many sectors, amid what some traders called a recovery from recent doldrums. INDEX broad may rally rallied signal stock stocks tech technology traders traders trend Doc as vector • Each doc j is a vector of D×idf values, one component for each term. • Can normalize to unit length. • So we have a vector space – terms are axes -‐ aka features – n docs live in this space – even with stemming, may have 10000+ dimensions – do we really want to use all terms? Other text categorizaGon applicaGons • SenGment analysis • Stylometry SENTIMENT ANALYSIS Id: Abc123 on 5-1-2008 “I bought an iPhone a few days ago. It is such a nice phone. The touch screen is really cool. The voice quality is clear too. It is much better than my old Blackberry, which was a terrible phone and so difficult to type with its tiny keys. However, my mother was mad with me as I did not tell her before I bought the phone. She also thought the phone was too expensive, …” SENTIMENT ANALYSIS Id: Abc123 on 5-1-2008 “I bought an iPhone a few days ago. It is such a nice phone. The touch screen is really cool. The voice quality is clear too. It is much better than my old Blackberry, which was a terrible phone and so difficult to type with its tiny keys. However, my mother was mad with me as I did not tell her before I bought the phone. She also thought the phone was too expensive, …” SENTIMENT ANALYSIS Id: Abc123 on 5-1-2008 “I bought an iPhone a few days ago. It is such a nice phone. The touch screen is really cool. The voice quality is clear too. It is much better than my old Blackberry, which was a terrible phone and so difficult to type with its tiny keys. However, my mother was mad with me as I did not tell her before I bought the phone. She also thought the phone was too expensive, …” HOW DOES IT WORK? • LEXICON-‐BASED tools: – Lookup words in the text in SENTIMENT LEXICON • E.g., LIWC (Pennebaker) / WordNet Affect / SenGWordnet – Classify text as posiGve / negaGve if contains a certain number of posiGve / negaGve words • WORD-‐BASED tools: – Use general techniques for supervised text classificaGon to learn which words are best indicators of a parGcular senGment STYLOMETRY Stylometry: Studying properties of the writers of documents based only on the linguistic style they exhibit. ! The best known type of stylometric task: “who wrote this document?” ! ! ! “Linguistic Style” Features: sentence length, word choices, syntactic structure, etc. Handwriting, content-based features, and contextual features are not considered. History of authorship attribution The classic stylometry problem: The Federalist Papers. ! 85 anonymous papers to persuade ratification of the Constitution. 12 of these have disputed authorship. ! Stylometry has been used to show Madison authored the disputed documents. ! Used as a data set for countless stylometry studies. ! Modern Stylometry Based in Machine Learning ! SVMs, Genetic Algorithms, Neural Networks, Bayesian Classifiers… used extensively. ! Who wrote this? “On the far side of the river valley the road passed through a stark black burn. Charred and limbless trunks of trees stretching away on every side. Ash moving over the road and the sagging hands of blind wire strung from the blackened lightpoles whining thinly in the wind.” Applications of Stylometry In the Digital Humanities: Identification of unknown authors ! But many other applications as well: ! ! ! “In some criminal, civil, and security matters, language can be evidence… When you are faced with a suspicious document, whether you need to know who wrote it, or if it is a real threat or real suicide note, or if it is too close for comfort to some other document, you need reliable, validated methods.” Plagiarism, Forensics, Anonymity… How does it work? Linguistic Features Basic Measurements: ! Average syllable/word/sentence count, letter distribution, punctuation. ! Lexical Density ! Unique_Words / Total_Words ! Gunning-Fog Readability Index: ! 0.4 * ( Average_Sentence_Length + 100 * Complex_Word_Ratio ) ! Result: years of formal education required to read the text. ! Standard stylometric system ! Three features: word length, letter usage, punctuation usage. 95% base accuracy. Who wrote this? “On the far side of the river valley the road passed through a stark black burn. Charred and limbless trunks of trees stretching away on every side. Ash moving over the road and the sagging hands of blind wire strung from the blackened lightpoles whining thinly in the wind.” Cormac McCarthy PRACTICAL CORNER: TOOLS • As for all other types of classificaGon, can use Weka to learn associaGons between words and authors SENTIMENT ANALYSIS LAB • In this lab you will see how text categorizaGon using words works in pracGce, in the case of senGment analysis INFORMATION EXTRACTION INFORMATION EXTRACTION • Goal: being able to answer semanGc queries (a.k.a. “database queries”) using “unstructured” natural language sources • IdenGfy specific pieces of informaGon in a un-‐structured or semi-‐structured textual document. • Transform this unstructured informaGon into structured relaGons in a database/ontology. SupposiGons: • A lot of informaGon that could be represented in a structured semanGcally clear format isn’t • It may be costly, not desired, or not in one’s control (screen scraping) to change this. EXAMPLE OF IE APPLICATION: FINDING JOBS FROM THE WEB foodscience.com-Job2 JobTitle: Ice Cream Guru Employer: foodscience.com JobCategory: Travel/Hospitality JobFunction: Food Services JobLocation: Upper Midwest Contact Phone: 800-488-2611 DateExtracted: January 8, 2001 Source: www.foodscience.com/jobs_midwest.htm OtherCompanyJobs: foodscience.com-Job1 REFERENCES TO (NAMED) ENTITIES SITE LOC CULTURE HOW • Two tasks: – IdenGfying the part of text that menGons a text (RECOGNITION) – Classifying it (CLASSIFICATION) • The two tasks are reduced to a standard classificaGon task by having the system classify WORDS NE: THE IOB REPRESENTATION FEATURES FEATURES FEATURES EVALUATION TYPICAL PERFORMANCE DISAMBIGUATION TO WIKIPEDIA • Query: • Wikipedia: Giotto was called to work in Padua, and also in Rimini 81 May 2012 Truc-‐Vien T. Nguyen OTHER TYPES OF INFORMATION EXTRACTION • COREFERENCE resoluGon: – John was late. He should have arrived at 5 … • RELATION EXTRACTION – UDO works for the UNIVERSITY OF ESSEX • CROSS DOCUMENT COREFERENCE TOOLS • A number of informaGon extracGon tools can be downloaded freely – NER (standard enGGes): GATE (see lab 1) – D2W: Wikipedia Miner (see lab 2) PIPELINE AND INFORMATION EXTRACTION LAB • The lab run by Maha AlthobaiG this aeernoon will explain how to use a standard text mining tool, GATE, to do processing and informaGon extracGon READINGS • Fabrizio SebasGani. Machine Learning in Automated Text CategorizaGon. ACM Compu<ng Surveys, 34(1):1-‐47, 2002 • James Pennebaker. The Secret Life of Pronouns: What Our Words Say About Us. Bloomsbury, 2011. • Milne & Wi`en (2009). An Open-‐Source Toolkit for mining Wikipedia.