Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Resilient Distributed Datasets: A
Fault-Tolerant Abstraction for
In-Memory Cluster Computing
Presentation by Zbigniew Chlebicki based on paper by Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin
Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica; University of California, Berkeley.
Some images and code samples are from paper, presentation for NSDI or Spark Project website ( http://spark-project.org/ ).
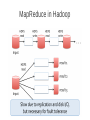
MapReduce in Hadoop
Resilient Distributed Datasets
(RDD)
●
●
Immutable, partitioned collection of records
Created by deterministic coarse-grained
transformations
●
Materialized on action
●
Fault-tolerant through lineage
●
Controllable persistence and partitioning
Example: Log mining
val file = spark.textFile(“hdfs://…”)
val errors = file.filter(
line => line.contains(“ERROR”)
).cache()
// Count all the errors
errors.count()
// Count errors mentioning MySQL
errors.filter(line => line.contains(“MySQL”)).count()
// Fetch the MySQL errors as an array of strings
errors.filter(line => line.contains(“MySQL”)).collect()
Example: Logistic Regression
val points = spark.textFile(…).map(parsePoint).cache()
var w = Vector.random(D) // current separating plane
for (i <- 1 to ITERATIONS) {
val gradient = points.map(p =>
(1 / (1 + exp(-p.y*(w dot p.x))) – 1) * p.y * p.x
).reduce(_ + _)
w -= gradient
}
println(“Final separating plane: “ + w)
Example: PageRank
links = // RDD of (url, neighbors) pairs
ranks = // RDD of (url, rank) pairs
for (i <- 1 to ITERATIONS) {
ranks = links.join(ranks).flatMap {
(url, (links, rank)) =>
links.map(dest => (dest, rank/links.size))
}.reduceByKey(_ + _)
}
Representation
abstract def compute(split: Split): Iterator[T]
abstract val dependencies: List[spark.Dependency[_]]
abstract def splits: Array[Split]
val partitioner: Option[Partitioner]
def preferredLocations(split: Split): Seq[String]
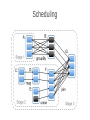
Scheduling
Evaluation: PageRank
Scalability
Fault Recovery (k-means)
Behavior with Insufficient RAM
(logistic regression)
User Applications
●
Conviva, data mining (40x speedup)
●
Mobile Millenium, traffic modeling
●
Twitter, spam classification
●
...
Expressing other Models
●
MapReduce, DryadLINQ
●
Pregel graph processing
●
Iterative MapReduce
●
SQL
Conclusion
●
●
RDDs are efficient, general and fault-tolerant
abstraction for cluster computing
20x faster then Hadoop for memory bound
applications
●
Can be used for interactive data mining
●
Available as Open Source at http://spark-project.org