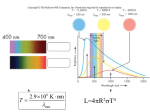
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Modeling the Point Spread Function Using Principal Component Analysis A thesis presented to the faculty of the College of Arts and Sciences of Ohio University In partial fulfillment of the requirements for the degree Master of Science Brett A. Ragozzine November 2008 © 2008 Brett A. Ragozzine. All Rights Reserved. 2 This thesis titled Modeling the Point Spread Function Using Principal Component Analysis by BRETT A. RAGOZZINE has been approved for the Department of Physics and Astronomy and the College of Arts and Sciences by Douglas I. Clowe Assistant Professor of Physics and Astronomy Benjamin M. Ogles Dean, College of Arts and Sciences 3 ABSTRACT RAGOZZINE, BRETT A., M.S., November 2008, Physics and Astronomy Modeling the Point Spread Function Using Principal Component Analysis (59 pp.) Director of Thesis: Douglas I. Clowe It is important in astronomy and cosmology to accurately describe the shapes of many objects. Telescope images are distorted by the point spread function, which is produced by many physical sources. A new model is needed to describe the point spread function variations on shorter scales than the distance between stars. Principal Component Analysis is a method whereby a large collection of images can create its own global solution based on the point spread function of the stars contained therein. A convenient way to describe each star is by representing them with shapelets, or localized, orthogonal basis functions. Shapelets are capable of accurately modeling stars with relatively few components. This research shows how models that describe individual images can be combined to create a global PSF pattern that describes all images in the set. Approved: _____________________________________________________________ Douglas I. Clowe Assistant Professor of Physics and Astronomy 4 This thesis is dedicated to my sweet wife who is my best friend, my greatest support, and the love of my life. Thanks, Angie. You’re the best! Mwah! 5 ACKNOWLEDGMENTS I would like to thank Dr. Clowe for his help in many areas of this research project, including programming in C, tracking down bus errors and segmentation faults, teaching me about observational astronomy, explaining in detail some of the causes of PSF, providing an unexpected laugh once in a while, and for being so patient while explaining how different parts of PCA work…over and over again. Many thanks to Kellen Murphy, Desiree Cotto-Figueroa, Dave Riethmiller, and Gcina Mavimbela for adding a bit of non-physics flavor to our physics-filled lives. Thanks, guys. 6 TABLE OF CONTENTS Abstract ................................................................................................................................3 Dedication ............................................................................................................................4 Acknowledgments................................................................................................................5 List of Tables .......................................................................................................................7 List of Figures ......................................................................................................................8 Chapter 1: Introduction ........................................................................................................9 Chapter 2: Techniques .......................................................................................................15 Shapelets ................................................................................................................15 Principal Component Analysis ..............................................................................22 shapefit ............................................................................................................25 fitcoeff ............................................................................................................27 Chapter 3: Data Analysis ...................................................................................................32 Image Set ...............................................................................................................32 Testing shapefit ...............................................................................................33 Modeling Real Stars with shapefit ..................................................................35 Testing fitcoeff ...............................................................................................42 Modeling Real Stars with fitcoeff ..................................................................43 Results....................................................................................................................48 Chapter 4: Conclusion........................................................................................................54 References..........................................................................................................................59 7 LIST OF TABLES Table 1: The First Several Hermite Polynomials...............................................................16 Table 2: Normalized Coefficients of a 5th order PCA .......................................................47 Table 3: Normalized Coefficients of a 6th order PCA .......................................................53 8 LIST OF FIGURES Figure 1: Graph of Hermite Polynomials...........................................................................17 Figure 2: Gaussian-weighted Hermite Polynomials ..........................................................18 Figure 3: 2D Projection of Shapelets .................................................................................19 Figure 4: Reconstruction of a Star Using Shapelets ..........................................................38 Figure 5: χ2 vs. Different Orders of PCA ..........................................................................45 Figure 6: χ2 of Six Stars with Increasing Principal Components ......................................46 Figure 7: Visual Output of testfit ...............................................................................49 Figure 8: Visual Output of testpca ...............................................................................50 Figure 9: χ2 vs. Three Types of PSF Models.....................................................................52 9 1. INTRODUCTION An important task in astronomy and cosmology is to determine the shape of objects, including stars and galaxies. Object shapes are distorted due to diffraction by the aperture of the telescope, imperfect optics, imperfect tracking systems, temperature variations in the camera, vibrations, optical changes during telescope refocusing, and turbulence in the atmosphere (a concern for ground-based telescopes). Whereas spacebased telescopes are above the Earth and are unaffected by the atmosphere and weather, images are still significantly distorted by these other causes. Astronomers are working to improve models that describe the blurring and smearing of light in images (Hoekstra, 2004; Paulin-Henriksson et al, 2007). The pattern of this spreading of light is known as the point spread function (PSF). A good measurement of the PSF comes from analyzing individual stars because they are essentially point sources. Stars are effectively point sources because they are typically on the order of hundreds or thousands of light years away from us and most stars are approximately the size of our Sun, whose diameter is 1.4x109 m (Carroll and Ostlie, 1996). The angular diameter that a star subtends is the diameter of the star divided by its distance from us, or about (1.4x109 m /200 light years) * (1 light year/9x1015 m) ~ 8x10–10 radians * (2x105 arcsec/radian) ~ 10–4 arcsec. (1) 10 Compared to a pixel on a charge-coupled device (CCD), the common detector in modern telescope cameras, which has an angular size on the order of 0.1–0.2 arcsec for most cameras, stars are seen as point sources. Because of this point source nature, the light from stars should fall onto a single pixel on the CCD. However, star light actually spreads out over a much larger area than one pixel. The PSF pattern generally has a strongly peaked Gaussian component to it, as well as non-Gaussian wings that extend well away from the peak. This pattern of light that falls on the CCD from an individual star is a very good representation of the PSF at that location in the image. The PSF pattern of individual stars can be used to model the PSF in other regions of the image. One way is to apply the PSF of one star to nearby, extended objects. Modeling the PSF in this manner is highly dependent on the brightness of the nearest star because faint stars are noisier than bright stars and the PSF is affected by noise. This technique is also limited by how far the neighbor is from the star because the PSF changes across an image and, in general, the farther the neighboring object is from the star, the less accurate the PSF model is. Another way to create a PSF model is to create a function from the changing PSF pattern of all the stars in the image. This model can be applied more accurately to regions between stars than is possible by the method of applying the PSF of individual stars to close neighbors. It is limited to modeling oscillations with scales larger than the distance between stars and cannot account for the PSF that varies on shorter scales between stars. It is also limited by the number of stars in the image and is affected by the noise in the PSF of each individual star. 11 A better model is needed that can capture variations between stars so that the PSF can be applied to every object in an image. Such a model might need to be a higher order function than can be created by a single image. Observational campaigns in the near future, such as LSST (www.lsst.org/lsst_home.shtml), will perform large surveys and take many images of each target, reducing the random noise in each image. Random noise scales as a factor of 1/ N , where N is the number of objects added together to increase the signal to noise, and combining any number of images will improve the quality of an object. Currently, however, the systematic noise in measurements made in areas such as weak lensing and photometry are not adversely affected by a poor PSF model. The random noise in these measurements far outweighs the systematic noise caused by the PSF; thus there has been little need for a superior PSF model. As images from large surveys are combined to reduce the random noise, the systematic noise caused by the PSF will become important, furthering the need for a better way to model the PSF (Jarvis and Jain, 2004). In order to model the global PSF, Jarvis and Jain (2004) used a method called Principle Component Analysis (PCA), which uses the PSF model of each image to create a global model that describes the overall PSF of all images in a set. This global model is of higher order than the functions that describe the individual images. PCA is not limited to function models created by individual frames and, because it uses the PSF of every star in every image, it probes the PSF on shorter scales than is possible by using any single image. Effort spent to capture a single clear image with many stars in order to find a higher order two-dimensional solution will not be generally applicable to other images 12 because the PSF continually changes, even by real time thermal fluctuations while an image is being taken. PCA is affected by random noise, but the effects are reduced by using a large collections of images; it can then model the global pattern of changes in the PSF. PCA is a powerful method of modeling the PSF because it is not limited to the number of stars in an image. Using PCA, a large data set of images replaces the need for a large number of stars in an image. The more images that are used, the more constraints there are to solve for a higher order global solution. The PSF varies between images due to many factors, which may not all be predictable or linked to a known physical source, but if enough images are used, the largest contributing factors can be monitored and a global PSF pattern can be constructed. It is not necessary to attribute each principal component with the cause of its contributing PSF, but can be pursued if desired. PCA works independently of knowing the physical causes that contribute to the global PSF. It also gets around the problem of needing a large number of stars in one image as well as the problem of the PSF changing rapidly between stars. Using many images, stars sample the PSF in random locations in each image and PCA essentially scans the entire PSF one image at a time. An additional problem for space-based telescopes are cosmic rays, or high energy particles that collide with the CCD and leave a bright imprint in the image. Cosmic rays are characterized by their brightness and width; they are typically much narrower than stars and, thus, the PSF. Many cosmic rays hit the CCD at large angles from its plane, leaving bright spots that can cover several pixels. Some cosmic rays hit the CCD and very small angles, leaving bright streaks in an image. In any case, cosmic rays interfere with the analysis of the PSF pattern when they land near or overlay stars. 13 Images that have cosmic rays will be noisier than we would normally want, but noise should not affect the results of the PCA. In addition, the PCA should not be affected by cosmic rays because the principal components capture systematic variations in the PSF and are not affected by random effects such as cosmic rays. Jee et al. (2007) applied the method of PCA to space-based images taken with the Hubble Space Telescope (HST). They used PCA on a single image with ~870 stars and created principal components from each star’s pixel values. This method is limited because it models the PSF using just one image and takes an extremely large number of principal components to do PCA. Both Jarvis and Jain (2004) and Jee et al. (2007) concluded that PCA reduces the global model to a few of the initial principal components and that these principal components are created from the data set itself. The purpose of this research is to 1) use PCA to create a global PSF model using a large collection of images taken with the HST, 2) use the global PSF model to find a polynomial solution that describes the PSF to higher order than any individual image can attain by using its stars alone, and 3) model higher order fluctuations between stars that other models are unable to do. An improved PSF model will enhance many astronomical research areas including photometry, measuring the shapes of galaxies and active galactic nuclei, and gravitational weak lensing. This paper shows the application of PCA on a set of images taken with the Hubble Space Telescope, using a polynomial that fits the PSF function of each image to create a global model. Chapter 2 shows the method used to create a PSF model of each image and the application of PCA, Chapter 3 is a detailed look at the routines that were 14 created for this research and analyzes the data from PCA, and Chapter 4 discusses the results and conclusion of the analysis and suggests further improvements for PCA. 15 2. TECHNIQUES The purpose of this thesis is to perform PCA using shapelets as basis functions to model the global PSF pattern in a set of HST images. The global PSF model is of higher order than can be created by individual frames and describes the PSF better than any single image. Shapelets Orthogonal basis functions can be used to model any analytic function to any desired degree of accuracy. A well chosen set of orthogonal basis functions can model a function with a finite number of terms while a poorly chosen set may require an infinite number of terms. For example, Fourier analysis, which uses an infinite set of orthogonal sine and cosine basis functions, can be used to describe any one-to-one function. It can model simple functions, but may require an infinite number of terms to do so (Arfken and Weber, chapter 14). The reason it takes an infinite number of sine and cosine terms to describe a simple shape such as a square wave or triangular saw tooth is because sine and cosine functions are oscillatory and unlike squares and triangles. It takes an infinite number of terms in order to overcome the very different nature between the basis functions and the shape of the function being modeled. A function F(x,y) can be represented as a set of basis functions fn (x,y) with an appropriate weight given to each basis function, F(x,y) = Σn cn fn (x,y), (2) 16 where cn is the coefficient that describes the amount of each basis function and the index n describes how many functions are used to model F(x,y). The index n can be finite or infinite, depending on the nature of the problem and the desired accuracy of the solution. In order to model a star’s PSF, which is strongly peaked in the center and has wings that extend out to some distance, a good choice of basis functions is one that models both of these features and is capable of describing the PSF with a finite number of terms. Refregier (2003) showed that stars can be modeled well with Gaussian-weighted Hermite polynomials, or “shapelets”, which are centralized in nature and whose higher order terms reach out beyond the central peak. Shapelets can describe the bright core and the wings of a star’s PSF very well using a finite number of terms. The Hermite polynomial portion of each basis function is created iteratively by the recursion relation Hn (x) = 2x Hn-1 (x) – 2(n – 1) Hn-2 (x), (3) each of which uses the previous two polynomials in the series (Arfken and Weber, chapter 13). The first several polynomials in the Hermite series are listed in Table 1 and their behavior can be seen in Figure 1. Each nth Hermite function is an nth order polynomial of its argument. Table 1. The first several Hermite functions H0 (x) = 1 H1 (x) = 2x H2 (x) = 4x 2 – 2 H3 (x) = 8x3 – 12x H4 (x) = 16x4 – 48x2 + 12 17 Figure 1. A graph of the first several Hermite polynomials. Their construction is based on the recursive relation Hn (x) = 2x Hn-1 (x) – 2(n – 1) Hn-2 (x). Combining the Hermite polynomials with the Gaussian weight function, Massey and Refregier (2005) show that the nth shapelet basis function in one dimension (1D) is described by φn (x) = (2n π1/2 n! β)–1/2 Hn (x/β) exp(–x2/2β2), (4) where n is the order of the desired Hermite polynomial and β is the parameter that describes the width and curvature of the shapelets. The first several basis functions in 1D can be seen in Figure 2. Arfken and Weber (2005) show that these basis functions are orthogonal because they follow the relation ∫ ∞ −∞ Hn(x) Hm(x) exp(–x2) dx = 0, n ≠ m. (5) 18 Figure 3 is a top-down look on the two-dimensional (2D) shapelets of different orders in n and m. This view is a 2D projection of 3D shapelets; the light regions represent positive values of brightness and the dark regions represent negative values. Each shapelet features (n+1) and (m+1) wiggles in their respective dimensions. As can be seen from this figure, the width of each basis function increases slightly with each higher n and m. Figure 2. The first few 1D Gaussian-weighted Hermite polynomials and each of the basis functions have (n+1) peaks. This graph is borrowed from Refregier (2003). 19 Figure 3. This figure, adapted from Massey and Refregier (2005), is a 2D projection of the 3D shapelets up to sixth order. Notice how each higher order of n and m increases the number of peaks and the linear extent of each function. The discussion up to this point has been about continuous functions, but star light is captured by the CCD and stored as pixel values. The pixelated stars no longer represent the continuous distribution of light because pixels count the number of photons that fall in a given area and store this value for the entire pixel; this is not a continuous function of x and y. In order to model a pixelated function, Massey and Refregier (2005) show how to pixelate the shapelet basis functions. Once again, Hermite polynomials are a good choice for the basis functions because of their iterative relationship. Pixelating the continuous shapelet basis functions requires integration over each pixel and, because Hermite polynomials are recursive, the integration of each shapelet has an analytic (exact) solution; it does not rely on a numeric approximation. Massey and Refregier 20 (2005) show that pixelating the n shapelet is done by integrating φn (x) over the bounds th of each pixel in the relation In = ∫ b a φn (x) dx 1 2 φn-1(x)| ba + 1− In-2| ba , n n = –β (6) which are based on the previous shapelet and a previous value of the pixelated function over the boundaries of the pixel, a and b. The first two pixelated functions are derived by integrating the 0th and 1st basis functions over each pixel. Explicitly, I0 = = ∫ b ∫ b a φ0 (x) dx (20 π1/2 0! β) –1/2 (1) exp(–x2/2β2) a = βπ 1/ 2 β = βπ 1/ 2 2 ⎛ x ⎞ b erf ⎜ ⎟| a 2 ⎝β 2 ⎠ π ⎛ x ⎞ b erf ⎜ ⎟| a . ⎝β 2 ⎠ (7) The function I1 is derived in a similar manner and its result is I1 = – β 2 φ0 (x)| ba . (8) Because x and y are independent variables in the stars, the same equations are extended into 2D and each shapelet is created by Inm = ∫ b a φn (x) dx ∫ 21 d c φm (y) dy = In (x) Im (y). (9) Whereas the Hermite polynomials are orthogonal over the infinite set, the same is not true for the pixelated functions. These basis functions are not completely orthogonal because pixelated basis functions are unable to uniquely model oscillations on subpixel scales due to degeneracies which exist among the functions that oscillate on scales smaller than one pixel. Therefore, the number of basis functions in the set used to model the stars must be finite and the basis functions themselves must oscillate on scales of at least one pixel in order to retain their orthogonality (Berry et al. 2004). As long as the shapelet basis functions are orthogonal and non-degenerate, each star will be uniquely fit with coefficients with the following equation, F(x,y) = Σn Σm cnm fnm (x,y), (10) where fnm (x,y) is now the product of In (x) and Im (y). The stars in each image can now be expressed as a set of shapelet basis functions. The PSF pattern varies across an image similar to how the shapelet coefficients of each star vary across the image. By creating a 2D model of how the shapelet coefficients change in each image, a global model can be created from all image models to describe the overall PSF pattern in the data set. The global pattern can then be applied to nonstellar objects throughout the images. 22 Principal Component Analysis The method of principal component analysis (PCA) uses a large set of images and takes information from each image individually, rather than using an average image or an average of any subset of the images. Attempting to get a good, clean image of a crowded star field would have enough data points to model a higher order polynomial (Hoekstra 2004), but it offers little help to other images as the PSF varies between images. This is also true of trying to find an average PSF model; images that are taken outside these average conditions will not benefit from an average model (Jarvis and Jain, 2004). Each individual image is valuable in determining how the global PSF pattern behaves. Using a large collection of many images makes it possible to sample the changes in the PSF on all scales of oscillation and is capable of capturing fluctuations that occur on smaller scales than the distance between two stars in an arbitrary image. PCA begins by creating a 2D polynomial model for each image; the order of this polynomial depends on the smallest number of stars in any image in the data set. The same order of polynomial will be used to fit every shapelet coefficient in all the images. An ith order 2D polynomial has a number of terms terms = Σn=0to i = (i+1)(i+2)/2 (11) and requires at least the same number of data points to create the model. The coefficients of these functions are put into a matrix M of dimensions [m x terms], where m is the number of data images in the collection and each row of M holds the coefficients of a particular image’s polynomial solution. 23 The matrix M can be decomposed into its principal components by a process called singular value decomposition (SVD) (Jarvis and Jain, 2004) and is of the form M = USVT (12) where U has the same dimensions of M, that is [m x n], S is an [n x n] diagonal matrix that contains only positive values, and VT is also a matrix of dimensions [n x n] and holds the values of the principal components of the global PSF, where T is the transpose operator. U contains information in each row that describes how much the corresponding image is affected by each principal component. SVD orders the positive, diagonal values of S in order of its largest to smallest values. The 2D principal components of the global model are stored in VT in their order of importance in the global model. The principal components are the main ways that the PSF varies in the data set. Their importance is based on the diagonals of S. Together, SVT represents the appropriately scaled principal components in the model and the rows of U hold values that represent how much influence each component has in each frame (Press et al, 1992). Generally, M is an [m x n] matrix and will have a non-degenerate SVD solution if m ≥ n. This means there are more linearly independent rows to constrain the n unknown columns. A large data set ensures that m >> n and provides many times the number of constraints required. The power of SVD is that it can reduce the number of degrees of freedom of the M matrix by truncating the S matrix with a number of terms that will maintain the desired accuracy of the global PSF model. The positive terms in S determine the importance of the principal components in the model. By truncating S to include only its j most valuable terms, the U matrix is also reduced in size; the 24 dimensionality of S becomes [j x j] and the dimensions of U become [m x j], or the number of frames by the number of the most relevant principal components. PCA can now increase the order of the PSF’s global 2D solution by using a higher order polynomial to describe the combined, lower order principal components. Jarvis and Jain (2004) showed that a better fit could be created through PCA than was possible for any single image to create by itself. They applied the PCA technique to images taken with a ground-based telescope. Jee et al (2007) used PCA with HST data, but they used pixels as the basis functions instead of shapelets, arguing that shapelets were too localized and thus were not a good choice for basis functions. Their initial M matrix, for postage stamps of 31 x 31 pixels and ~870 stars, has dimensions [961 x 870]. While they showed that only 20 principal components could describe the PSF in that image, a better way to speed up the calculation time is to use shapelets as basis functions by reducing the number of columns in M. The purpose of PCA is to show that a polynomial of lower order that describes individual data images can be improved to a higher order fit by using a large set of images. By finding the contribution of the principal components, a higher order function can be found. The end goal is that the global PSF solution will model stars better than can be described by a single image polynomial. The remainder of this chapter includes descriptions of the routines that were written to represent stars as shapelets and the implementation of PCA. 25 shapefit shapefit takes each image file, with its associated catalog of star positions, and calculates the shapelet coefficients of each star. The required input into shapefit are the parameters β, nmax, xpix, and σ. The parameter β directly describes the curvature and extent of each shapelet, nmax defines the number of shapelets that represent each star in ndim = Σn=0to nmax = (nmax+1)(nmax+2)/2, (13) xpix is the number of pixels on a side of the square cut out around each star, also known as a postage stamp, and σ is the noise term taken from a statistical analysis of the image and is used to measure a goodness of fit. Also required by shapefit are one image file and its catalog of stars. shapefit takes the center of brightness from the input catalog and converts that position into postage stamp coordinates, then counts the star’s flux within a given number of pixels from the center (radius defaults to five pixels, but can be overridden by input). Its main purpose is to calculate the coefficients that minimizes the following χ2 equation, χ2 = (F(x,y)/flux – Σn Σm cnm fnm (x,y))2/σ2, (14) where F(x,y) is the postage stamp of the star, cnm are the shapelet coefficients for each basis function fnm (x,y). A Numerical Recipe routine named amoeba was adapted to solve for the best fitting shapelet coefficients by minimizing χ2 in Eqn. (14). The routine amoeba crawls through the parameter space, taking steps of various sizes and deciding which step, if any, is a better solution. The routine amoeba requires a set of linearly independent 26 vectors that span the space of the ndim basis functions. This spanning is done by creating an [ndim+1 x ndim] array p that contains an approximation to the solution in the first row (for fast calculation time) and linearly independent vectors in each remaining row whose diagonal elements determine the step size. After testing several stars and their approximate shapelet coefficients, the diagonal elements of p were chosesn to be 0.1. Whereas the coefficients range between zero and less than 0.1, this initial value also affects the time amoeba takes to search for the solution and it was ~25% faster than choosing 0.01 for the diagonal elements. The initial p thus looks like ⎛0 0 0 L 0⎞ ⎟ ⎜ 0 L 0⎟ ⎜0.1 0 ⎜ 0 0.1 0 L 0 ⎟ p= ⎜ ⎟. 0 0.1 M ⎟ ⎜0 ⎜ M M O 0⎟ ⎟ ⎜ 0 0 0 0.1⎠ ⎝0 (15) At each step, amoeba calculates the goodness of fit using a χ2 function. As it approaches the best solution, the step size decreases. It remembers the best steps in the coefficient space and continues to step toward a better fit and stops at an arbitrary tolerance, ftol, that was chosen to calculate the accuracy of each cnm down to about 10–4 to 10–5. The routine amoeba ends its search when each row of p is within ftol of minimizing χ2 and the best solution is returned in the top row of p. This accuracy in the shapelet coefficients was chosen because the χ2 stopped improving noticeably and because the number of calculations scales with ndim2, or nmax4. Thus the ideal nmax is that which achieves the best χ2 with the lowest number of 27 shapelets. As the coefficients are calculated for each star, they are appended to the star catalog along with an identifier that associates it with the appropriate image. After the shapelet coefficients are determined for each star, the individual catalogs from each image are combined into a master star catalog with stars grouped by image number. This master catalog is used for input to the routine fitcoeff for the PCA analysis. fitcoeff Now that we have the shapelet coefficients for each star in a master catalog, the next step is to get a global polynomial fit for each shapelet. The information that the routine fitcoeff requires as input are numimage, order, ndim, finalorder, and finaldxorder. The input numimage is the number of different images that were used to create the master catalog; order is the initial 2D polynomial order to use when modeling each shapelet coefficient in each separate image; ndim is the number of shapelet coefficients stored in the master catalog for each star; finalorder is the order of the PCA polynomial solution; and finaldxorder is the order of the PCA dx and dy in the principal components. The routine fitcoeff begins by reading in all stars from the master catalog, keeping track of the image, position, and shapelet coefficients of each star. The 2D polynomial solution that describes the variation of the shapelet coefficient across one image is of the form Pimage (x, y) = ∑i ∑j aij xiyj, (16) 28 where i + j ≤ order and the number of polynomial terms in the model is terms = (order+1)(order+2)/2. (17) The polynomial order was given as input to fitcoeff and the star positions are known; now we need to solve for the unknown ai,j. A 2D polynomial is created for each shapelet coefficient separately. This is achieved by minimizing the function χ2 = ∑star (shape_coeffstar – ∑i ∑j aij xi yj )2 / σ2, (18) by taking its derivative with respect to the unknown polynomial coefficients ai,j and setting it equal to zero: ∂ χ2 / ∂ ai’j’ = (2/σ2) ∑ star (shape_coeffstar – ∑i ∑j aij xi yj )( xi’yj’ ) = 0. (19) This equation reduces to ∑ star (shape_coeffstar xi’yj’ – ∑i ∑j aij xiyj xi’yj’’) = 0 (20) or ∑star (∑i ∑j aij xi yj xi’yj’ ) = ∑star (shape_coeffstar xi’yj’ ), (21) which takes the form of the linear equation Ax = b, (22) where the square matrix A holds the known polynomials, x is the unknown polynomial coefficients aij, and b holds the known solutions of each coefficient. 29 These expressions are simplified into one dimension over the primed and unprimed i's and j’s by mapping each 2D polynomial into a 1D polynomial before constructing the elements in A and b. We do this by mapping xm = xi yj, i + j ≤ m (23) and xn = xi’ yj’, i' + j’ ≤ n. (24) The matrix A will vary over all polynomial terms as Amn = ∑star ( ∑m ∑n xm xn ), (25) where the position of each star is used to calculate xm and xn; the vector b holds the solutions to the linear equation bn = ∑star shape_coeffstar ∑n xn. (26) The Numerical Recipes routine ludcmp, which stands for lower-upper (LU) decomposition and routine lubksb, which stands for LU back substitution, are used to solve this linear equation and return the correct coefficients in x, with an = aij, i + j ≤ m (27) LU decomposition is a method in which a square matrix (A, here) is decomposed into lower (L) and upper (U) triangular matrices, or matrices whose elements in the lower left or upper right can hold any value and the remaining elements in the matrix are zero. 30 The routine ludcmp performs the decomposition on matrix A and records the row permutations that it required; lubksb uses the LU matrices and one solution b to solve for the unknown aij. LU decomposition is a fast way to solve linear equations by the method known as Gaussian elimination. In Gaussian elimination, an upper triangular matrix is created through simple row operations performed on A and b, then back substitution provides a quick solution to the unknown variables. M holds the coefficients of each 2D polynomial as x is solved for each image; imageID corresponds to the row in M that holds its solution. One matrix M is created for each of the ndim shapelet basis functions. M is now ready to undergo SVD, using the Numerical Recipe routine svdcmp, which returns three matrices: U, S, and V. Only the information in U will be retained, but the j most important elements (rows) in the S matrix determines the number of columns to keep in U, reducing it from dimensions [m x n] to [m x j]. At this point, a higher order polynomial is created that essentially replaces the principal component information in SVT. This higher order model takes the form shape_coeffstar (x,y) = U Pj (n) (x,y), (28) where the polynomials P are based on the first j columns of U and can be up to an arbitrary nth order polynomial in x and y. The purpose of the principal components in P is to create a better fit of the stars in all images and particularly in the images that had too few stars to create such a high order polynomial on its own. To create this set of principal components in P, another set of linear equations must be solved. This time it takes on a more complicated form, that is, 2 k 2 31 2 χ = ∑star (shape_coeffstar - ∑j ∑k uij ajk x ) / σ . (29) By taking the derivative and setting it equal to zero, ∂ χ2 / ∂ aj’k’ = (2/σ2) ∑stars (shape_coeffstar - ∑j ∑k uij ajk xk )( ui’j’ xk’ ) = 0, (30) a new set of linear equations can be seen in the form Ax=b, ∑star (∑j ∑k uij ajk xk ui’j’ xk’) = ∑star (shape_coeffstar ui’j’ xk’). (31) Once again, the multi-dimensional polynomials are mapped into one dimension, along with the principal component they belong to, so that A and b can be constructed from one dimensional polynomials. Additional dx and dy polynomial terms are introduced into the model at this point to show if the position of a star’s central brightness within one pixel improves the global model of reconstructing stars. 32 3. DATA ANALYSIS This section describes the data files used in this research and a look deeper into the routines that were written, how they work, and the tests that were performed at various stages to make sure they work accurately. Image Set The image files used in this research were taken with the HST’s Advanced Camera for Surveys Wide Field Camera as part of the ESO Distant Cluster Survey (EDisCS) collaboration (Desai et al, 2007). 282 images were taken during 141 pointings, which means that two images were taken while the telescope was aimed at the same target coordinates. This data set was previously debiased, dark-subtracted, flat-field corrected and distortion corrected. The images were found to have many cosmic rays, but the analysis was continued without worrying about the influence this noise would cause because PCA should overcome such randomness with a large number of images in the set. However, it became apparent that the shapelets were modeling cosmic rays extremely well and the shapelet coefficients were being swayed too much; the shapelets were not modeling the star by itself. It was difficult to get the χ2 calculation for each star down to unity with so many cosmic rays that fell inside their postage stamps. Each set of frames pointed at the same target were combined to eliminate nearly all cosmic rays by comparing pixels at the same x and y coordinates in each frame and taking the lower pixel value of the two images. This was a fast way to get rid of as many cosmic rays as possible; it is not the ideal way to treat the real star light. Any cosmic rays 33 that remain in the combined images happened to fall on the CCD in the same place in both images, but it is extremely unlikely that many of these remaining cosmic rays will land within the 31 x 31 pixel postage stamps. Even in the cases where they do fall within a postage stamp, this noise due to cosmic rays should be overcome when using all images to perform the PCA. Testing shapefit To test the validity of the shapelet equations, the numerical integration of each basis function In = ∫ b a φn (x) dx, (32) was compared with the iterative form of In, I0 = βπ 1/ 2 2 ⎛ x ⎞ b erf ⎜ ⎟| a , ⎝β 2 ⎠ (33) I1 = – β 2 φ0 (x)| ba , (34) and the remaining In = – β 1 2 φn-1(x)| ba + 1− In-2| ba . n n (35) When modeling these 1D functions, it was very important to get enough pixels to get good agreement between In and the integral of φn (x) over all the pixels. Comparing a 34 th single n order shapelet, the biggest disagreement with small xpix occurred near the center of the Gaussian peak. With a large number of pixels, say 250 or more, the agreement was exact in every pixel for the whole function. Using approximately 30 or more pixels, the difference between the two normalized curves is below 1%. The noise in the core of a typical star in this survey is ~1/ pixel , where the brightest pixel in many stars is between 130 and 150 (before the pixels are normalized by the exposure time). As 1/ 130 ~ 11.4, a noise level of 11.4/130 ~ 8% is indicated. The difference between the shapelet reconstruction and a Gaussian curve is more accurate than the noise. This shows that the shapelets are sufficiently accurate on the scale of the 31 x 31 pixel postage stamps. To test the shapelet basis functions on stars, various stars were simulated in postage stamps of different sizes. Stars were created with the equation F(x,y) = exp[ –(xt + yt ) / 2 r02 ], (36) where the power t in x and y was 5/3 to mimic the PSF seen in ground-based images, and 2, which is the curvature of a Gaussian and f00. The width, r0, ranged in value between 1.0 and 8.0 to simulate stars of many sizes. The simulated stars did not include any noise, making it easier to monitor the reconstruction of each star both visually and numerically and making sure the shapelets were properly integrated over the expected boundaries. When using the shapelets f10 and f01, which are the simplest odd functions in x and in y (see Figure 3), both should integrate to zero if the star is symmetric and there is no noise. Thus c10 and c01 should be identically zero if these two shapelets are coded correctly. The routine amoeba calculated the shapelet coefficients for several different 35 nmax and β values to make sure this was the case. In each case, c10 and c01 were ~ 0.1 times the magnitude of c20 and c02, and 10–3 compared to the value of c00. Another test to make sure the Gaussian f00 shapelet was lined up correctly, as well as the rest of the shapelets being coded properly, was to simulate a star with the function exp[–(x2+y2)/2β2 ] / βπ1/2 , (37) or f00 itself. Most of the power should be returned from amoeba in c00, which it was; the other cnm were at least 10–5 smaller than c00. Satisfied that the shapelets were correct, stellar centroids were created with fractional pixel values and the simulated stars were compared to the reconstructed stars. The large difference between them showed that something was wrong. Visually, the fit was shifted near the centroid coordinates, causing a dramatic peak and valley with the appearance of a deep volcano. It became apparent that the shapelets would have to be created for each star individually, depending on the centroid coordinates. Creating shapelets was changed to include the centroid as the peak of the f00 function; the integration boundaries, a and b, were both shifted according to the centroid. These tests showed that the stars were being modeled perfectly and that it was time to begin modeling real stars from the image files. Modeling Real Stars With shapefit When representing stars as a set of shapelets, the two critical parameters that determine the best fit are nmax and β. The parameter nmax determines the number of shapelets, ndim, in the set of basis functions and as nmax increases, a star is modeled with 36 increasing accuracy. Shapelets are so efficient that at high enough nmax they model the noise in the star and surrounding data in the postage stamp. The noise is not part of the PSF so modeling it misrepresents the PSF at that location. A sufficiently high nmax captures the PSF in the wings, but needs to stop before fitting the sky background outside the edges of the star light in the wings. Any higher nmax that ultimately models the random noise of a star comes at the cost of computing time and cannot help the PCA results. The best nmax is the lowest value that, when combined with the best β, results in the lowest χ2, or χ2 = Σx Σy ( pixelxy / flux – Σn Σm cnm In (x) Im (y) )2 / ( (σ/flux)2 + pixelxy / (exp_time*flux2)) / (numpix – ndim), (38) where In (x) Im (y) is the recreated pixel value of each fnm, pixelxy is the pixel value, flux is the flux of the star within five pixels of its center, σ is the statistical error, exp_time is 1020 seconds of exposure time, and numpix is the number of pixels in the star’s representation. The number of degrees of freedom in Eqn. (38) is represented by (numpix – ndim). The 961 pixels in the postage stamp used as numpix did not normalize χ2, but unity was reached when numpix was calculated by using the descriptor θmax introduced by Refregier (2003), which is a function of nmax and β, as θmax = β * sqrt( nmax + 0.5 ), (39) setting a scale of the largest features that can be described by shapelets. Here, θmax=1.3*sqrt(12.5) ~ 4.6 pixels. The number numpix counts the number of pixels whose centers fall within a circular region of radius ~ (1.8 θmax)2 and ranged between 218 and 37 224 pixels. The factor of 1.8 came from taking the radius of a typical star, at which pixel values reached 10–3 of the value of the central pixel (8 or 9 pixels away), and calculated what factor of θmax would reach the edge of the star. Eqn. (38) compares each normalized pixel with its reconstructed value. The nmax values that were tested with β were the even numbers between 0 and 18. Every odd shapelet coefficient is very near zero and there is no need to end the set of basis functions with an odd nmax. The reason is because each nth shapelet is the integral of the nth Hermite polynomial; odd n in nmax means odd nth shapelet and they all integrate to zero over symmetric boundaries, as in In = ∫ ∞ −∞ φn (x) dx = 0, for n odd. (40) Even shapelet coefficients have all the power in noiseless, symmetric stars, but the PSF is not symmetric and there is noise in real stars; thus the odd cnm are small, but are not identically zero. This was verified by calculating the χ2 of an arbitrary image over many values of nmax and several arbitrary values of β. Each pair of even (nmax) and odd (nmax+1) solutions gave essentially the same χ2, with the odd nmax results coming in slightly lower and the next even nmax ~10% better. The additional odd nmax shapelets create a better fit because there are more shapelets to model the noise in the star. Every star construction in nmax is accompanied by a value of β, which ranged during testing from less than a full pixel, 0.5, to several widths of the bright core, or 8.0 pixels. The statistics in the given star catalog showed that the radius of most stars was between 1.0 and 1.5 pixels, but tests were performed over a large range to make ensure 38 the best fit with shapelets. Many combinations of these two parameters were quickly discarded because of the poor fit they provided. The final nmax and β with the lowest χ2 values for all stars in an arbitrary image were nmax=12 and β=1.3 pixels. Accuracy in β began with half pixel accuracy and narrowed down to tenths of a pixel in the narrow range of finding the optimal 1.3 pixels. Figure 4 shows the reconstruction stages of a well behaved star. Notice how each higher order nmax has a wider extent and how χ2 decreases with each nmax. Also notice how the optimally chosen nmax and β describe the star out to the edge of its wings. Figure 4. This graph shows the shapelet reconstruction of a single star, which is shown at the top left. Each row is a reconstruction of the star using progressively higher dimensions of nmax. Column A represents the contribution of just the nth order shapelet components for this star, Column B is the sum of the reconstructed shapelets up to the current nmax, and Column C is the difference between the star 39 and Column B. Column D is the nmax of each row. The Column E is the calculated χ2 of the residual frame using Eqn. (38). The star closely resembles the background after the 12th order shapelets are added. The value of β used in this image was 1.3 pixels. The parameter β is critical because if it is too small, f00 will under fit the core, fail to reach the edges of the PSF in the wings, and the overall fit will be poor. If β is too large, f00 over shoots the core and the wings, and the overall fit will be poor. Besides looking for the smallest nmax with the lowest χ2 value, another important feature in the code was to make sure amoeba actually came to a best fit before timing out. amoeba fit typically well behaved stars with around 5x105 iterations. Poorly behaved stars easily reach the maximum steps allowed in amoeba without settling all legs near enough to the solution. With nmax of 14, many stars with β between 1.2 and 1.4 pixels would not come to a best solution within nearly 106 iterations. Because the routine amoeba calculations scale as nmax4, it is important to optimize the shapelet coefficients to be sufficiently accurate, but unnecessary iterations in amoeba come at a steep cost in calculation time. If amoeba were allowed enough iterations and nmax were raised higher, it would undoubtedly improve the χ2 of each star. At nmax=14, a star took nearly five minutes to reach approximately 106 iterations on a 2.33 GHz Intel processor. With enough time, one can send a collection of images through shapefit and model stars to arbitrary presicion by letting amoeba run without a step limit. This HST data set has 4498 stars; at five minutes per well behaved star, let alone the extra time for noisy postage stamps, it would take over 15 days of computer time to finish calculating the cnm for this data set. PCA is 40 more accurate with increasingly more images and stars, so a faster solution is a must. The time saved by stopping at nmax=12 instead of using 14, the time saved is Tcalc = nmax144 / nmax124 = 1.85. (41) While testing for accuracy of the shapelets themselves, the value ftol was 10–11 to make it easy to verify the cnm through various experiments. Now that the shapelets were tested and found to be accurate, ftol was increased to improve the calculation time without sacrificing desired accuracy in the shapelet coefficients. The value of ftol was increased to 10–7, which cut amoeba iterations down to about 8x104 to 1.5x105 for most stars, taking approximately one third of the calculation time, and keeping an accuracy of cnm around 10–4 or 10–5. At this point, shapefit calculated the coefficients for all 4498 stars in approximately 40 hours of computer time. Another important test was performed to make sure that the shapelet coefficients were at a global minimum and not just a local minimum. The p matrix in shapefit was first initialized with zeros in every element except the 0.1 diagonals. Now it was initialized with all elements set to 0.2 (far from the previously found solutions) and the diagonals were kept at 0.1. The results from each run returned the same shapelet coefficients to within 10–5 in all cases. This test also shows that the shapelet basis functions are orthogonal because the same solution was approached from below and then from above. Degeneracies in the basis functions would be evident if amoeba arrived at multiple minima with very different cnm. After the shapefit routine calculated the shapelet coefficients in all 141 frames, an imageID was assigned to each star before compiling a master catalog. The χ2 of each 41 star and image was loosely monitored to make sure there were no grossly poor fits among them. One image was found to have several stars with very large, negative χ2 values. That particular image had low values for all pixels and the noise dominated the signal; that image was discarded because it looked like something had gone wrong when the HST took one of the two images that were used to create it. Before proceeding onto the next routine, the values c01 and c10 for a large number of stars were analyzed and found to be very far from the expected value of zero compared to the next higher order shapelets, c02, c11, and c20; some were within a factor of two of these next higher order coefficients and many were within an order of magnitude. Using a similar technique to make sure the f10 and f01 shapelets were centered properly, a routine called adjustxy was written to move each centroid to a position that reduced c10 and c01 lower than approximately 10–2 of the values of c20 and c02. This was done using nmax=2 to model just the brightest part of the star rather than the whole star. Because of noise in the real data, the coefficients were not expected to be identically zero, even when using a small nmax. The routine adjustxy calls a modified version of amoeba named amoeba_newxy, which takes a p matrix as input that is initialized with the centroid in the stellar catalog, but offset an arbitrary 0.1 pixels as shown here: ⎛ xc yc ⎞ ⎜ ⎟ y c ⎟. p = ⎜ x c ± 0.1 ⎜ ⎟ y c ± 0.1⎠ ⎝ xc (42) The 0th row starts as the centroid x and y from the initial stellar catalog because the adjusted centroid is going to be very near the given initial location. Each step of 42 amoeba_newxy calls the original amoeba in order to find sufficiently small values of c10 and c01. In the end, the centroids had changed by marginal amounts, but these first order shapelet coefficients were now about a factor of ten smaller than the second order coefficients. To make sure the new centroid was the only local minimum that the routine would settle on, the new centroids were verified to converge to the same values when offsetting the diagonals of p by ± 0.1. The remaining 140 images had a minimum of 14 stars per image; just shy of the number needed to fit a fourth order 2D polynomial. A fourth order polynomial requires at least 15 stars while a third order 2D polynomial can be created from 10 stars. A third order polynomial was chosen in order to keep all the frames in the data set and to get the best possible global fit by using the maximum number of frames and catching as many stars in as many random positions across the CCD as possible. A master catalog was created from the catalog of each image as the input to fitcoeff. Testing fitcoeff To test the fitcoeff routine, 15 images were created, each with 100 randomly placed stars. Each star was given a single shapelet coefficient calculated by its position with hand made fourth order polynomials. A master catalog was created with stars assigned to the appropriate simulated image and, after running ludcmp and lubksb on all the frames, the rows of M held the correct coefficients of the hand made polynomials, showing that the subroutines worked as expected. The next step in fitcoeff is to perform SVD. After using svdcmp to create the U, S, and V arrays, it was necessary to verify that the Numerical Recipe was being used 43 correctly and that the results that came out of it were expected. Just three simulated frames were created using a first order polynomial in x and y in order to quickly solve the matrix multiplication USVT. One frame had shapelets that varied as x, another as y, and the other was just random. Multiplying these matrices returned the original M, showing that svdcmp was being used correctly. Looking at the values in V, the power of SVD became clear when the basis functions it calculated were not just x and y, but were instead 1 1 x+ y, 2 2 1 1 x− y, 2 2 (43) and the null vector. While it did not return the functions that created the shapelets, it did create an equally valid set of basis functions to describe the set of images. Modeling Real Stars With fitcoeff When running fitcoeff on an arbitrary image, it was found that three of the ten elements in the S matrix were clearly dominant by at least a factor of 103. The global polynomial, Pj(n), was created using the first three principal components. The fit was compared to the stars in an arbitrary image and the χ2 values were found to be worse than the 2D model created from the same image. A closer look at the U, S, and V matrices revealed that the relevance of each principal component was not fully responsible in the elements of S. When keeping all ten of the principal components to create a global model of Pj(n), the χ2 values were about the 44 same for each star, but a little noisier. When fitcoeff created a higher order model and was compared to the third order global model, every star had a worse χ2 fit and the higher the order, the worse the fit became. The expected improvement in each star’s fit through PCA was not realized. The claim that Jarvis and Jain (2004) made that a higher order global model could be created from a set of image models did not hold true. It may be that PCA is affected by noise whereas Jarvis and Jain (2004) claimed it would not be affected by noise. In order to improve the global model, the master list of stars was scrutinized for an overall goodness of fit. Of the 4498 stars, 1384 of them had individual χ2 values greater than 2.0. The routine shapefit was modified to keep stars with an arbitrary value of χ2 ≤ 2.0 and a best master catalog was created with the remaining 3114 stars in order to test if the global model would improve with less noise in the stars. The Pj(n) created using the (three) dominant terms in S were still a noisy approximation of the polynomial created by the stars in an arbitrary image, but when all ten principal components were constructed, the reconstruction was exact to at least 10–6. Still, the expected improvement in modeling stars with a higher order function did not occur. In order to test the idea that the global model might be held back by the images with the fewest stars, a select set of images was used to create a higher order model. These images held at least 21 stars and fitcoeff created a fifth order polynomial with 21 principal components. This fifth order solution was used to model an image with 13 stars (enough for a third order image polynomial) and was found to improve the χ2 of every star in the image compared to the image model. Approximately 18 of the 21 components adequately describe the global fit by comparing the relative power of each 45 subsequent principal component to the first one, as seen in Table 2. This shows the value of PCA by reducing the number of principal components needed to form a global model. Figure 5. This graph is a histogram of the χ2 of stars that were recreated using global fits of various orders. The blue line represents the stars recreated from a third order model using all 140 images and all 10 principal components; the overall trend is not very good. The black line is the fifth order global model created from 86 images containing at least 21 stars; it uses all 21 principal components. The red curve is a sixth order PCA solution, created from the same 86 images as was the black curve and includes all 21 principal components. Notice how the solution from the sixth order solution was about as good as, but not much better than, the fifth order solution. When applying a higher order PCA to images with fewer stars, the number of principal components that can be used in the reconstruction of a particular frame depends on the number of stars it has. The PSF in the frame with 13 stars can be reconstructed with up to 13 of the 21 principal components. While 18 of the 21 principal components in the fifth order PCA were needed to adequately reconstruct the global model up to fifth order, the first ten of them reconstructed the PSF better than its own third order image polynomial. 46 Figure 6. This graph shows the χ2 improvement of six arbitrary stars when using increasingly many principal components. The image contained 25 total stars and was fit with a fifth order global model. Table 2 lists the principal component coefficients of a fifth order PCA solution. It is quite clear that certain fluctuations in the PSF are modeled by a certain number of principal components. The zeroth order is modeled by the first component that is 106 greater than the remaining components, the second order is modeled by six components before a sudden drop off of 10-4 in the rest of the components, and the fifth order requires about 18 principal components before a sudden 102 drop in power. To test the stability of the U matrix, the routines svdcmp, ludcmp, and lubksb were used repeatedly to see what would happen to U and to the principal components that could be created from it. After just five repetitions, it was found that more than one coefficient oscillated around its initial value and then changed dramatically by a factor of two, showing that U was not stable. 47 Table 2. Normalized coefficients of the fifth order PCA solution PC 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 y0 5.97E+01 -5.18E-05 -1.22E-05 -1.13E-06 3.21E-06 1.44E-06 6.42E-06 -1.97E-06 3.74E-06 5.70E-06 -2.47E-06 -2.52E-07 -1.68E-06 -9.44E-07 -5.84E-07 -1.47E-06 3.48E-08 -1.38E-06 1.41E-06 9.19E-08 1.82E-08 y1 -1.97E-02 5.38E-02 1.10E-02 -6.46E-09 -1.15E-08 -2.70E-09 -9.24E-09 3.71E-09 -5.27E-09 -7.86E-09 5.62E-09 -1.65E-09 1.23E-09 1.31E-09 4.01E-10 2.09E-09 -6.01E-10 1.51E-09 -1.78E-09 -2.50E-10 -7.83E-11 y2 -5.33E-06 -4.56E-05 -1.43E-05 -6.81E-06 -6.35E-06 -4.86E-07 3.61E-11 -3.87E-12 2.82E-12 4.63E-12 -4.15E-12 1.54E-12 -5.31E-13 -1.05E-12 -3.62E-13 -1.28E-12 6.29E-13 -1.17E-12 1.18E-12 1.10E-13 2.11E-14 y3 1.48E-09 1.48E-08 4.17E-09 5.30E-09 1.02E-08 1.02E-09 2.81E-09 -1.03E-09 -8.64E-11 1.42E-10 -8.30E-15 -9.15E-16 2.35E-16 4.17E-16 1.39E-17 1.22E-16 -3.09E-16 5.23E-16 -4.51E-16 1.98E-17 -3.13E-17 y4 2.95E-13 -2.18E-12 -3.01E-13 -1.48E-12 -3.72E-12 -4.58E-13 -1.35E-12 8.47E-13 2.13E-13 -1.59E-13 -1.88E-13 -7.26E-14 1.70E-14 -3.55E-15 2.54E-15 -2.45E-19 5.72E-20 -1.15E-19 8.59E-20 -2.02E-20 1.89E-20 y5 -6.85E-17 9.08E-17 -3.32E-17 9.54E-17 2.71E-16 3.27E-17 1.04E-16 -7.95E-17 -2.90E-17 2.36E-17 3.34E-17 1.26E-17 8.84E-20 2.03E-19 -8.78E-18 -1.61E-17 -5.82E-18 -1.27E-18 2.75E-19 -6.49E-20 5.59E-20 Table 2. These are the normalized coefficients of the fifth order principal components created from the 3114 best stars. After some number of principal components, it is evident that subsequent principal components contribute very little to a given order of polynomial in the global model by comparing coefficients in each column. The U and S matrices returned by svdcmp were not normalized, so in order to correctly compare the PCA coefficients by eye, each column in U was normalized by dividing each term by the variance of the column (umax – umin) and multiplying the corresponding element (row) of S by the same amount. When creating the PCA coefficients from the U matrix in Eqn. (28), any relevance previously hidden in U is transferred to the diagonals in S. The values shown in Table 2 have been normalized in this manner and are ensured to show the relevance of each principal component. 48 Results Two routines were created in order to visually and numerically monitor the goodness of fit of each reconstruction method. The first program is named testfit, which receives as input the shapelet coefficients of individual stars, the order of the polynomial with which to create a model for the single input image, ndim, xpix, and creates an image file for the output. The output file has five columns formatted in the following manner, from left to right, as seen in Figure 7. The first column is the 31 x 31 pixel postage stamp directly copied from the input image. The second column is the reconstruction of the star based solely on the shapelet coefficients that were calculated in shapefit. Column three is the difference between the first and second columns and the goodness of fit is visually verified by the checkered pattern of the size of the star. The pixel values in column three oscillate around zero and, in the best cases, are 10–3 better than the magnitude of the original star’s core pixels; in the worst cases the checkers are only smaller at the level ~5x10–2. Outside the core region, pixel values quickly drop off to 10–4 and continue to improve toward the edges of the reconstruction. The pattern in column three is the ideal model that the remaining comparisons will be based against. The fourth column is a reconstruction of the star using the image polynomial model; it is expected to be a worse fit than the ideal created in column two. Column five is the difference between the first and fourth columns; its checker pattern oscillates around zero, the pixel values are around 10–2 of those in the core, and improvement can be seen toward the edge at the level 10–4. 49 0.02 0.04 0.08 Figure 7. Visual output of the testfit routine. The first column is the original star. The second and fourth columns are individual shapelet reconstructions and third order image polynomial reconstructions, respectively. The third and fifth columns are the differences between the original star and the preceding column. The color bar is a logarithmic scale from 0 to 0.1. The routine testfit also outputs the χ2 goodness of fit of each star, using Eqn. (38), from the reconstructions in columns three and five. Comparing these values, column five is typically 20-40% higher than column three. These results show that a 50 polynomial model created from shapelets in a single image is worse than the ideal shapelet model of individual stars. 0.02 0.04 0.08 Figure 8. This picture similar to Figure 7, except that the second column is a stellar reconstruction using a fifth order PCA model. The construction here is much better than the image reconstruction of Figure 7 and some stars approach the ideal reconstruction of each star’s shapelet reconstruction. The color bar is a logarithmic scale from 0 to 0.1. The second program used to visually and numerically monitor the goodness of fit is named testpca; it shows the original stars from the input file and the results of the reconstruction using PCA. The columns are in a similar format where column one is the 51 original star, column two is the PCA reconstruction of the star, and column three is the difference between the first two columns. Many tests were performed to compare the final χ2 values between the PCA model and the image polynomial model. The first test was creating a third order polynomial model for all 140 frames; the PCA results from the three most significant principal components was a worse fit than the image polynomial. Upon inspection of S and V from SVD, it was apparent that some of the power in the latter principal components compensated for the low values in corresponding elements in S. When using the master catalog with all 4498 stars, which included 1384 noisy stars, keeping all ten principal components from the PCA results were unable to attain the χ2 values returned from the image polynomial. However, when using the best 3114 stars to do PCA on all 140 images, the χ2 results were identical to the image polynomial reconstruction; no improvement was made by PCA to create a higher order PSF model. Analyzing the ten principal components did not reveal a clear pattern of decreasing significance among any of the components. Perhaps a third order PCA model was insufficient to create a global description and if there had been more than ten components, the PCA reconstruction could have created a better model. To test this, a fifth order global model was created using all 86 images with at least 21 stars. Using testfit and testpca to compare the results, an image with 13 stars was found to be reconstructed better with the fifth order PCA than with the third order image polynomial and better than a third order PCA. The improvement reduced the χ2 values of well behaved stars from the range of 0.9 to 1.2 by ~10–20%, reaching 0.8 to 1.0. All noisier stars with image polynomial χ2 values above 1.3 were improved even more. Their χ2 52 values reached the 0.9 to 1.2 level, an improvement of ~30–50%; the noisiest stars, whose χ2 went as high as 4.0 or 6.0 also reached the 0.9 to 1.2 level, showing improvement of a few hundred percent. Figure 9. Plotted here is a semi-log histogram of the number stars vs. their χ2 values. The black curve is the ideal recreation of each star when represented by shapelets in an individual postage stamp. The red curve is the histogram of the stars in images with fewer than 15 stars, recreated using a third order image polynomial. The blue curve is a fifth order PCA solution applied to the images with less than 15 stars. Further analysis is required to determine why a global model of any order is not improved, and even worsens the χ2 of each star dramatically, when creating principal components of higher order than the image solutions before performing SVD on matrix M. Table 3 shows an example of the principal components of a sixth order PCA when fitcoeff used a fifth order polynomial on 86 images in the data set. The coefficients in a given column are all nearly as important as the first component to within 10-3. The Numerical Recipe routine svdcmp is based on receiving a matrix M of dimensions [m x n] and returning U, S, and V with dimensions [m x n], [n x n], and [n x 53 n], respectively. Therefore, the number of principal components is limited to the same number of polynomial terms and depends fully on the polynomial order. Jee et al (2007) used the same dimensions in U, S, and V as this research, but they used ~961 pixels as their basis functions (columns) in M and were not limited to the number of principal components in the polynomial order. Jarvis and Jain (2004) used dimensions [m x k], [k x k], and [k x n], which sets no limit on the number of principal components in the analysis. Table 3. Normalized coefficients of the sixth order PCA solution created from fifth order image polynomials. PC 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 y0 5.92E+01 -1.04E+00 -5.27E-01 -9.30E-01 -2.96E+00 -3.26E-01 -8.86E-01 5.38E-01 9.84E-02 1.32E-01 2.39E-01 1.71E-01 1.56E-03 -1.38E-01 -4.59E-01 -1.94E-01 -1.29E-01 1.37E-01 -1.09E-02 -1.00E-01 -7.31E-02 y1 -2.35E-02 5.75E-02 1.08E-02 3.84E-03 1.29E-02 1.90E-03 4.92E-03 -3.12E-03 3.52E-04 -4.02E-04 1.10E-04 -5.76E-04 -7.49E-04 4.79E-04 1.31E-03 6.32E-04 5.84E-04 -6.19E-05 -1.63E-04 1.83E-04 -2.96E-05 y2 4.56E-07 -4.93E-05 -1.33E-05 -1.15E-05 -2.15E-05 -2.86E-06 -6.35E-06 4.91E-06 -7.27E-07 9.75E-07 -8.36E-07 5.34E-07 8.90E-07 -5.96E-07 -1.26E-06 -6.36E-07 -6.46E-07 1.25E-08 3.41E-07 -2.84E-07 8.18E-08 y3 -2.42E-09 1.69E-08 3.73E-09 8.72E-09 2.05E-08 2.73E-09 7.52E-09 -5.32E-09 7.60E-10 -1.15E-09 9.17E-10 -1.55E-10 -5.15E-10 3.78E-10 6.73E-10 4.99E-10 3.94E-10 -2.74E-11 -2.90E-10 1.96E-10 -5.63E-11 y4 1.60E-12 -2.99E-12 -3.96E-13 -3.01E-12 -8.01E-12 -1.23E-12 -3.46E-12 2.99E-12 -4.44E-13 8.03E-13 -6.32E-13 -1.12E-13 2.00E-13 -1.33E-13 -2.10E-13 -2.65E-13 -1.59E-13 3.07E-14 1.17E-13 -6.87E-14 1.73E-14 y5 -2.78E-16 2.47E-16 2.81E-17 4.14E-16 1.12E-15 1.93E-16 5.43E-16 -5.50E-16 8.35E-17 -1.65E-16 1.26E-16 3.12E-17 -3.39E-17 2.27E-17 2.44E-17 4.21E-17 2.51E-17 -7.11E-18 -2.21E-17 1.15E-17 -1.83E-18 y6 1.31E-20 -1.20E-20 -6.96E-21 -2.52E-20 -6.55E-20 -1.27E-20 -3.49E-20 3.78E-20 -4.69E-21 1.11E-20 -6.98E-21 -1.82E-21 2.59E-21 -1.61E-21 -2.08E-21 -4.67E-21 -2.35E-21 7.44E-22 1.73E-21 -7.02E-22 2.13E-23 Table 3. This table is similar in layout to Table 2, but for sixth order principal components. Notice how there is no clear pattern to the decrease in importance to any component in any polynomial power, showing the need for further analysis of creating a higher number of principal components from SVD. 54 4. CONCLUSION The purpose of this research was to 1) model the global point spread function of a large set of images using the method of Principal Component Analysis, 2) use this global model to describe other images in the data set, and 3) capture fluctuations in the global point spread function on scales that are shorter than the distance between stars. It is important to create a global model that captures the point spread function variations between stars and can be applied to objects between stars in any image. Principal Component Analysis is a powerful method of determining the point spread function by creating principal components directly from the data. Sampling images with many stars provides a way to describe the point spread function of less populated images in a better way than they can model by themselves. This research also showed that Principal Component Analysis can create a higher order polynomial to describe the point spread function than individual images can do for themselves. Using Gaussian-weighted Hermite polynomials, or shapelets, as basis functions proved to be a good choice for modeling the point spread function of stars because of their ability to model the bright core and extended wings typically found in stars. Shapelets are also able to describe the point spread function very well with a finite number of terms. The parameters nmax and β are critical when determining the typical shape of stars in a data set and reduce the number of basis functions required to represent stars. Using a good combination of nmax and β dramatically cuts down on the computation time required to model a large host of stars. With new observational campaigns, such as LSST, that will perform larger surveys than ever before, computation time must be kept to a minimum for each star. 55 This research showed that noise in images and in individual stars affects the global model to describe the point spread function. Jarvis and Jain (2004) concluded that the noise would be overcome by having a large set of images, but this is not the case. Creating image polynomials with the best stars improved Principal Component Analysis, but the large data set did not overcome the problem introduced by noisy stars or images on its own. However, this research did confirm the ability of Principal Component Analysis to create a global model using less than the full set of principal components calculated in singular value decomposition. Jarvis and Jain (2004) claimed that Principal Component Analysis was capable of creating a higher order global model of the point spread function from lower order image polynomials. This research showed that creating a third order Principal Component Analysis model exactly matched the third order reconstruction of image polynomials, but fourth order (and higher) solutions were much worse at describing the global point spread function. This may be because the principal components singular value decomposition calculated are well suited for that specific order. This research showed that the singular value decomposition solution is not unique in the very simple first order model. It was also shown that many more principal components are needed to create a higher order model than can be provided by singular value decomposition. The reason could be that the Numerical Recipe routine svdcmp returns a limited number of principal components, n. This was shown in attempting a fifth order Principal Component Analysis solution from third order image polynomials and in the case of trying to create a sixth order Principal Component Analysis solution from fifth order image polynomials. Table 56 3 showed that the sixth order principal components, put in order of importance by singular value decomposition, did not provide a clear decrease in significance and latter components even showed higher significance than the first component. This was quite different than was shown in Table 2, where a distinct cut off was present in all cases. The results showed that using a third order model to describe all frames in the data set did not provide a good Principal Component Analysis model of higher than third order. There were simply too few principal components to describe the global point spread function. This disagrees with the claim made by Jarvis and Jain (2004) that a higher order global solution can be created from image models. However, using some of the frames in the data set that had enough stars to create a fifth order image solution were able to create a better global model and improved the point spread function description of images containing fewer stars. The point spread function fluctuations appear to have some structure and are not completely random in nature. The fifth order Principal Component Analysis model was created from 86 images, but was able to reconstruct stars in the remaining 140 images better than their own third order image solution and third order Principal Component Analysis were able to do. The χ2 results were found to improve between 10-50% on most stars when using a fifth order polynomial on images that had too few stars to create such a high order function on their own; the worst stars were improved even more. These images were not even included in helping create the global model, yet they were very well described by the model created from other images in the data set. One avenue for future work is to perform singular value decomposition using a different algorithm than that provided by Numerical Recipes. The dimensions of the 57 matrices in singular value decomposition limit the number of principal components used to describe the global point spread function because S is always [n x n], where n is the number of terms in a polynomial of a given order. A better way might be to use an algorithm that allows the S matrix, which is created during singular value decomposition, to have an arbitrari number of elements, k. If enough principal components are created by having a higher dimension of S, it may be possible to create better models using all the images in a data set rather than just using the frames with the highest number of stars. When reconstructing stars in an image with a large number of principal components, k, the image is limited to using as many components as it has stars. However, this research showed that fitting a third order image that had 13 stars was well described by a fifth order global model. This agrees with both Jarvis and Jain (2004) and Jee et al (2007) who claimed that the point spread function could be modeled by a fewer principal components than were created by singular value decomposition. Using shapelets to model the point spread function proved to be effective in capturing the bright core and extended wings of each star with a finite number of basis functions. This umber of basis functions is far fewer than the 961 basis functions used by Jee et al (2007). The main differences between this research and that of Jarvis and Jain (2004) are 1) the singular value decomposition in svdcmp was limited to returning n principal components, limiting the effectiveness of the principal components and 2) a higher order global solution did not improve the reconstruction of stars. The advantage of this research compared to Jarvis and Jain (2004) is that this image set was space-based rather than 58 ground-based so the large affect of the atmosphere on the point spread function did not affect these images. The main differences of this research compared to Jee et al (2007) is that using pixels as basis functions allows for a larger number of principal components to be created through singular value decomposition. The advantages of this research compared to Jee et al (2007) are 1) using a large number of images is probes the point spread function as it varies with time, 2) using fewer basis functions requires less calculation time to create the principal components, and 3) shapelets are shown to be a accurately model the bright core and extended wings of stars. In conclusion, this research shows 1) that the global point spread function can be modeled by using a large set of images, 2) that shapelets are a good choice of orthogonal basis functions to model the point spread function of stars using a finite number of terms, 3) Principal Component Analysis reconstructs stars more accurately than a lower order image model can provide for itself by probing the point spread function between the stars in all images, 4) computation time is greatly reduced by using the best combination of shapelet parameters nmax and β, 5) Principal Component Analysis does not completely overcome noise in images, and 6) a higher order solution created from principal components does not improve the global model and is an even worse model in many cases. 59 REFERENCES Arfken, G. & Weber, H., 2005, Mathematical Methods for Physicists. Academic Press, Elsevier Berry, R., Hobson, M., & Withington, S., 2004, MNRAS, 34, 199 Carroll, B. & Ostlie, D., 1996, An Introduction to Modern Astrophysics. Addison-Wesley Publishing Company Desai, V. et al, 2007, ApJ, 660, 1151 Hoekstra, H., 2004, MNRAS, 347, 1337 Jarvis, M. & Jain, B. 2004, astro-ph/0412234v2. Jee, M. J., Blakeslee, J. P., Sirianni, A. R., Martel, A. R., White, R. L., & Ford, H. C., 2007, Publication of the Astronomical Society of the Pacific, 119, 1403. Massey, R. & Refregier, A. 2005, MNRAS, 363, 197 Paulin-Henriksson, S., Amara, A., Voigt, L., Refregier, Al, & Bridle, S. L., “PSF calibration requirements for dark energy from cosmic shear,” arXiv:0711.4886 (2007) Press, W., Teukolsky, S., Vetterling, W., & Flannery, B., 1992, Numerical Recipes. Cambridge Refregier, A., 2003, MNRAS, 338, 35 Refregier, A. & Bacon, D. 2003, MNRAS, 338, 48