Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Warehousing for Scientific Behavioral
Data
by
Baiju H. Devani
A thesis submitted to the
School of Computing
in conformity with the requirements for
the degree of Master of Science
Queen’s University
Kingston, Ontario, Canada
June 2004
c Baiju H. Devani, 2004
Copyright Abstract
Building a data management model for scientific applications poses challenges not
normally encountered in commercial database development. Complex relationships
and data types, evolving schema, and large data volumes (in terabyte) are some
commonly cited challenges with scientific data. In this thesis, we propose a data
warehouse model to manage and analyze scientific behavioral data.
Data warehousing is popular in customer-centered environments and encapsulates the process of transforming and aggregating operational data and bringing it to
a platform optimized for Online Analytical Processing (OLAP). A database schema
ubiquitous with data warehousing is the dimensional or the star schema. In this
paper, we develop a proof-of-concept data warehouse system for a scientific laboratory at Queen’s University that is conducting behavioral studies in the area of limb
kinematics. The system is based on three primary technologies: a Perl based parsing
grammar for transforming and cleaning source data, an object-relational data management system based on IBM’s Universal DB2 system, and a Java-based front-end
interface that is accessible through MathWork Inc’s Matlab system.
i
Acknowledgments
I would like to thank Queen’s University for giving me the opportunity to pursue an
MSc. degree. I would also like to thank my supervisors, Dr. Glasgow, Dr. Martin,
and Dr. Scott, for their academic guidance and support throughout this period. I
appreciate their patience, and their confidence in me.
I would also like to thank my family, especially my parents, for their steadfast
moral and financial support. I could not have come this far without their blessings.
Finally, I would like thank all my friends for making my stay in Kingston memorable. I have had some good times and I take good memories with me. A special
thanks to Noorin for always being there to provide support during stressful times,
and also, always being there to celebrate my successes.
ii
Contents
Abstract
i
Acknowledgments
ii
Contents
iii
List of Tables
vi
List of Figures
vii
1 Introduction
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.2 Thesis Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2 Scientific Problem Description
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2 Limb Kinematics And Primary Motor Cortex . . . . . . . . .
2.3 Information/Data Management Problems Posed By KINARM
2.3.1 Management . . . . . . . . . . . . . . . . . . . . . . . .
2.3.2 Complexity . . . . . . . . . . . . . . . . . . . . . . . .
2.3.3 Relevance . . . . . . . . . . . . . . . . . . . . . . . . .
2.3.4 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3 Background
3.1 Introduction . . . . . . . . . . . . . . . . . . . .
3.2 Conceptual Framework . . . . . . . . . . . . . .
3.2.1 Relational Database Model . . . . . . . .
3.2.2 Object-Oriented Model . . . . . . . . . .
3.2.3 Object-Relational Model . . . . . . . . .
3.2.4 Analytical Versus Transaction Processing
iii
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
Systems
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
1
1
3
.
.
.
.
.
.
.
.
5
5
6
8
9
9
11
11
12
.
.
.
.
.
.
13
13
14
14
16
19
20
3.3
3.4
3.5
3.6
Data Warehouse . . . .
Related Work . . . . .
Research Methodology
Summary . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
21
26
28
32
4 System Overview
4.1 Introduction . . . . . . . . .
4.2 System Requirements . . . .
4.3 Existing Data Organization
4.4 System Architecture . . . .
4.4.1 Parse Grammar . . .
4.4.2 Data Warehouse . .
4.4.3 Matlab Interface . .
4.5 Summary . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
33
33
33
36
39
41
43
49
50
5 Analysis
5.1 Introduction . . . . . . .
5.2 Query Support . . . . .
5.2.1 Metadata Query
5.2.2 Trial Data Query
5.3 Data Management . . .
5.4 Data Analysis . . . . . .
5.5 Operational Aspects . .
5.6 Emergent Issues . . . . .
5.6.1 Schema Evolution
5.6.2 Scalability . . . .
5.7 Summary . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
51
51
52
53
58
63
64
67
68
68
69
70
.
.
.
.
.
.
72
72
74
74
76
77
78
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
6 Conclusion And Future Works
6.1 Thesis Summary . . . . . . . . . . . . .
6.2 Key Limitations And Possible Solutions .
6.2.1 Arrays To Store Signals . . . . .
6.2.2 Source Data Upload . . . . . . .
6.3 Future Work . . . . . . . . . . . . . . . .
6.4 Summary . . . . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Bibliography
79
Appendices
83
iv
A Matlab Scripts
A.1 Metadata query 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
A.2 Metadata query 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
A.3 Trial data query . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
84
84
86
89
B Statistical Formulae
92
C A sample .pro file
94
D Regular Expressions For Parsing Grammer
96
Glossary
100
v
List of Tables
3.1
Research Process . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
31
5.1
File-based System Versus The Data Warehouse System . . . . . . . .
71
6.1
Research Evaluation Criteria . . . . . . . . . . . . . . . . . . . . . . .
73
vi
List of Figures
2.1
The KINARM Device . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.1
3.2
3.3
3.4
3.5
A Simple Relational DBMs model
A Simple Object-Oriented Model
Data Warehouse Architecture . .
Dimensional Schema . . . . . . .
IS Research Steps . . . . . . . . .
4.1
4.2
4.3
4.4
4.5
4.6
4.7
4.8
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
15
17
22
25
30
Data Flow In The File-based System . . .
.pro Data Structure . . . . . . . . . . . . .
Data Warehouse System Overview . . . . .
Parsing Grammar Rules . . . . . . . . . .
Grammar tree . . . . . . . . . . . . . . . .
System Schema . . . . . . . . . . . . . . .
User-defined Objects And Typed Tables In
Data Hierarchy In Typed Fact Table . . .
. . .
. . .
. . .
. . .
. . .
. . .
DB2
. . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
37
38
40
41
42
44
45
47
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
Metadata Query 1 . . . . . . . . . . . . .
Metadata Query 1 - Results . . . . . . . .
Metadata Query 2 . . . . . . . . . . . . .
Metadata Query 2 - Results . . . . . . . .
Trial Data Query . . . . . . . . . . . . . .
Trial Data Query - Results . . . . . . . . .
Trial Data Query - Results 2 . . . . . . . .
Results From Java-based Matlab Interface
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
54
55
56
57
59
60
61
66
6.1
6.2
Array Structure In A Fact Table . . . . . . . . . . . . . . . . . . . . .
Sample Query With Array Structures . . . . . . . . . . . . . . . . . .
75
76
vii
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
7
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Chapter 1
Introduction
1.1
Motivation
Data management systems were popularized in the 1970’s by the introduction of
the relational data model. Since then, these systems have evolved from being used
primarily for transactional processing workloads to systems that integrate and store
large amounts of data primarily for analytical purposes. These analytical systems,
commonly referred to as data warehouses, support complex analysis of data and
decision making in organizations. Data warehousing facilitates the use of technologies
such as on-line analytical processing (OLAP), decision support systems (DSS), and
data mining software, all of which try to make sense of the large amounts of data
generated by organizations [19, 31, 22].
The success of data warehouses in the business world motivates us to examine
its use in a scientific environment. To scientists, the tasks of collecting, storing, and
analyzing data are part of their core activity. Scientists are in the business of generating knowledge from data, yet, database systems in general, and data warehouses
1
CHAPTER 1. INTRODUCTION
2
in particular, are not as popular in the scientific community as they are in the business community. One reason for this is that traditional database systems assume
that the data and the processes generating the data are well defined. Scientific data
and processes on the other hand are inherently shifting with domain knowledge. A
data model for such an environment needs to be flexible and should easily allow such
data/schema evolution without rendering historical data useless. This is especially
hard to implement in traditional database systems due to structural rigidities imposed on the data types and relationships among the data. Furthermore, scientific
research generates large amounts of data with complex relationships. For example,
scientific laboratories conducting behavioral experiments may collect data with high
dimensionality and millions of data points per experiment.
The challenge from a data modelling and analysis point of view is to develop a
model that captures the complexity and richness of the data while creating an efficient
framework for storing, querying, and analyzing scientific data.
Research Statement: The purpose of this thesis is to propose a data warehousing
model, based on an object-relational database management system, to address
the problems of managing and analyzing large amounts of data generated from
scientific behavioral experiments.
In order to accomplish this goal, the following objectives are identified:
1. Identify applicable models and technologies and develop a data warehouse for
a specific scientific problem to act as a proof-of-concept system.
2. Demonstrate the effectiveness and efficiency of the system by:
CHAPTER 1. INTRODUCTION
3
(a) Developing tools or interfaces that allow researchers to query and analyze
data.
(b) Illustrating the value added by the data warehouse system in terms of
facilitating more efficient management and analysis of behavioral data.
3. Finally, through system implementation, we will identify lessons learnt and
solutions that could be applied to future data warehouse projects for behavioral
data.
As a proof-of-concept system, we have developed a data warehouse model for
behavioral research done by Dr. Stephen Scott, professor of Anatomy and Cell biology
at Queen’s University, and his group. Dr. Scott’s research investigates limb motor
coordination and the role of different regions of the brain in such movements [42,
43]. This research generates large amounts of complex data and gives us an ideal
opportunity to develop a data warehouse system for a practical problem. Dr. Scott’s
research and data are described in detail in Chapter 2.
1.2
Thesis Organization
The thesis is organized as follows. In Chapter 2, gives a background on Dr. Scott’s
research and the data management and analysis problems it poses. Chapter 3 outlines
the background on core data management systems, discusses related works in this
area, and describes a research methodology for this thesis. Chapter 4 describes the
data warehouse that is developed as a proof-of-concept system, and discusses key
design decisions taken prior to, and during implementation. Chapter 5 evaluates the
CHAPTER 1. INTRODUCTION
4
data warehouse system and test it against the current file-based approach. Finally,
in Chapter 6, summarizes this thesis, and describe future works in this area.
Chapter 2
Scientific Problem Description
2.1
Introduction
As a proof-of-concept system for this thesis, we have developed a data warehouse
for Dr. Stephen Scott’s research laboratory in the Department of Anatomy and
Cell biology, Queen’s University. Dr. Scott’s research group is studying the role of
the primary motor cortex (region of the brain) in controlling limb movements. The
data generated by the lab has all the qualities of scientific data that make it hard
to model, namely: a) large volume, b) evolving/changing structure, and c) complex
relationships among the data. In this chapter, we explore these issues to gain a better
understanding of both the data that is to be managed, and the underlying scientific
process generating the data.
The chapter begins by outlining the research paradigm used by Dr. Scott’s lab
and the data it generates. We then describe the key characteristics of the data and
the challenges posed from a data management and analysis point of view.
5
6
CHAPTER 2. SCIENTIFIC PROBLEM DESCRIPTION
2.2
Limb Kinematics And Primary Motor Cortex
While it is generally accepted that the primary motor cortex plays a significant role in
multi-joint limb movements, the exact nature of the role is not yet clear [42, 43]. One
research paradigm, pioneered by Dr. Stephen Scott, to study this problem is using
KINARM (Kinesiological Instrument for Normal and Altered Reaching Movement).
The KINARM device (shown in Figure 2.1) is an exoskeleton
1
that can sense and
perturb planar limb movements. This allows researchers to record brain activity
while measuring and manipulating the physics of the limb. Furthermore, KINARM
behaviors are visually guided, thus allowing researchers to understand how sensory
information guides motor action.
Using the paradigm above, researchers study a number of motor behaviors or
tasks. For example, a simple task involves the subject moving the limb to a target
projected on a planar surface. The movement is constrained by requirements such as
moving to the target in a certain amount of time and following straight hand paths
to the target. During task execution, KINARM measures variables of interest related
to limb movement. In this way, a number of complex behavioral experiments can be
designed. These experiments vary in either:
• Spatial positions of the targets (direction of movement).
• Mechanics of the movements. For example, loads that aid or resist the movement are added such that the subject has to overcome the load to reach the
target, or has to resist the load to avoid overshooting the target.
• The sequence of the movement (order in which subjects move to the target).
1
Exoskeleton here refers to an mechanical structure on the outside of the body
CHAPTER 2. SCIENTIFIC PROBLEM DESCRIPTION
a
7
b
Figure 2.1: The KINARM device is the primary device used in Dr. Scott’s lab for
studying multi-joint limb movement [42, 43]. (a) shows the limb placed
in the exoskeleton which is attached to motor linkages that can independently manipulate the elbow and shoulder joints during a task. The red
dot shows a target light projected on the horizontal movement plane. An
experimental task consists of movements to different spatial targets under
varying load conditions. (b) Electrodes passed transdurally record neural
activity in cortical region during various tasks.
CHAPTER 2. SCIENTIFIC PROBLEM DESCRIPTION
8
The goal of these task experiments is to dissociate the limb motion from the
underlying muscular/neural forces used to generate it and thereby gain insight into
how such precise movements are coordinated and generated by the brain.
2.3
Information/Data Management Problems Posed
By KINARM
The KINARM research paradigm described above generates large amounts of behavioral data. For example, the neural data, measured at a frequency of 4000Hz, can
result in thousands of data points per movement (even when re-sampled at a lower frequency). At present, data is stored in files saved on standard 700MB disks. There are
currently about 150 disks making a total database of roughly a 120GB. Furthermore,
with new equipment being installed, such as the Plexon data acquisition system [37],
the rate of data acquisition is going to increase and a terabyte database is conceivable
in the near future.
Also, in addition to large data volumes, the above paradigm generates a complex
data-set in terms of the types of data collected (Electromyogram (EMG), neural, and
kinesiological), the relationships between data entities, and the temporal nature of
data. The resulting data management and analysis problems are described below and
grouped into four categories: data management, complexity, relevancy, and analysis.
CHAPTER 2. SCIENTIFIC PROBLEM DESCRIPTION
2.3.1
9
Management
As described above, significant data volumes are collected during behavioral experiments. With the current file-based set-up, such volumes present the following problems:
1. Lack of query tools: This makes data management a daunting task. For example, a simple question such as “Do we have enough cells for analysis xyz ?”
requires a researcher to manually sift through written logs of experiments and
identify cells of interest.
2. Uncontrolled data redundancy: Since there is no centrally accessible and shared
data repository, individual researchers copy and store data relevant to their
analysis on local hard drives. Such uncontrolled redundancy wastes hardware
resources and makes it hard to maintain data consistency. For example, correction of corrupt data or new experimental data needs to be communicated to
every potential user.
2.3.2
Complexity
Not only are large data volumes collected from behavioral experiments, but also the
data collected is complex. Data complexity arises from the following factors:
1. Complex relationships between the data types. For example, each experiment or
task is a set of movements to different spatial targets. Data for each movement
towards a target is stored in separate files. Each file has metadata describing
global aspects of the movement, and trial specific metadata. A more detailed
CHAPTER 2. SCIENTIFIC PROBLEM DESCRIPTION
10
discussion of the data organization is given in Chapter 4, however, at present it
is sufficient to take note of this complexity.
2. Another source of complexity is the evolving/shifting nature of the data model
and the underlying scientific process. Since a data model is an abstraction of
a real world concept, the model has to change with changes in domain knowledge. For example, in this instance, as knowledge is gained from behavioral
experiments, new tasks or behaviors might be defined or new signals might be
introduced. Also, as new knowledge is gained, data needs to be re-analyzed.
Thus, capabilities such as ad-hoc querying and analysis become very important.
3. Finally, an additional source of complexity is the temporal nature of behavioral
data. A data signal in a behavioral experiment is recorded over a period of
movement of a limb towards a target. Such time series data adds complexity
to the analysis process because, in most cases, a researcher needs to analyze
different subsets of this series. For instance, a researcher could ask for cell
2
discharge rate between the time the target light was projected and the time the
movement started. Another source of complexity is the inherit temporal shift
in the different signals. For example, there is a lag between when a neuron
discharges and when that discharge translates to an observable limb behavior.
The data model should take into account the need to extract and analyze data
based on temporal queries.
2
The term cell and neuron are used interchangeably throughout the thesis and refers to a biological
cell which conducts electric neural impulses from one part of the body to another
CHAPTER 2. SCIENTIFIC PROBLEM DESCRIPTION
2.3.3
11
Relevance
Another challenge posed by KINARM is that biological data is inherently noisy. Furthermore, noise is also introduced from the device measuring the biological signals.
This means that raw data cannot be analyzed without filtering/processing it. However, this process involves a loss of information which might be required in the future
and thus raw data cannot be discarded. For example, a researcher might switch between analyzing raw data and filtered data depending on the signal of interest. The
data model should be able to conserve both views of the data as well as encapsulate a process of transforming raw data to processed data and provide an option of
accessing/querying either source (raw or processed).
2.3.4
Analysis
From a data analysis point of view, Dr. Scott’s research faces the following challenges
in the current environment:
1. As mentioned previously, lack of query capabilities makes it hard for data of
interest to be identified. For example, at present a researcher cannot ask the
following without writing a small program: “Retrieve data where task=a and
subject=b and date > 01/01/2001”. Additionally, there is no mechanism to
extract only signals relevant to a particular analysis. For example, in a typical
experiment, as many as 32 signals might be recorded. Of these, a researcher
might only need 2 signals for a particular analysis. However, this is not possible
in the current file-based system. With large data volumes, which is the case
here, a significant amount of time goes into disk I/O with most analysis requiring
large amounts of RAM (Random Access Memory). Also, significant effort and
CHAPTER 2. SCIENTIFIC PROBLEM DESCRIPTION
12
programming skill is required to simply access relevant data and bring it to the
analysis platform. This creates a steep learning curve for new researchers to the
lab, most of whom are from a life sciences background and are attached to the
lab for relatively short periods of time.
2. The current file-based environment does not provide adequate support for implementing data mining algorithms. With large data volumes and the nature of
the research at hand, data mining is a logical next step in terms of automating
analysis and knowledge generation. Evidence suggests that data mining efforts
can be significantly reduced by a data structure that can be queried. Hirji [24]
notes in his study that 30% of total effort in implementing data mining projects
is spent on data preparation. He further cites studies by Cabena et. al [9]
that suggest data preparation could take as much as 70% of the total effort. A
well structured data source with fast query capabilities can potentially aid data
mining. Thus one can argue that a database system is the logical predecessor
of any data mining efforts.
2.4
Summary
This chapter has briefly outlined behavioral research conducted in Dr. Scott’s lab.
We have also identified practical data management and analysis problems faced by
researchers in his lab. We now proceed by giving a background on data management
systems and data warehousing in the next chapter, and then outline a warehouse
system for Dr. Scott’s lab in Chapter 4.
Chapter 3
Background
3.1
Introduction
The previous chapter discussed Dr. Scott’s research, and the data analysis and management problems faced by researchers in his lab. This chapter has the following
three goals:
1. Give a background on data warehousing and the core data management technologies on which it is based.
2. Outline related works in the area of management and analysis systems for scientific data.
3. Outline a research methodology for this thesis.
13
CHAPTER 3. BACKGROUND
3.2
14
Conceptual Framework
Relational and object-oriented models are currently the most widely used database
technologies. The growth of relational database systems was driven by the need for
fast transaction processing type systems. The object-oriented database concepts were
driven by the need for better modelling and storage of complex data such as those
found in scientific applications. Furthermore, object-oriented programming languages
such as Java and C++ integrated well with object-oriented databases. More recently,
relational database technology has been augmented with object-oriented features and
are described as object-relational databases. These core technologies are described in
detail below.
3.2.1
Relational Database Model
Relational Database Management Systems (RDMs) were first introduced by Codd in
his seminal paper titled “A relational model of data for large shared data banks” in
1970 [12]. Since then it has been one of the most widely implemented and studied
database model. In this model, a database is described in terms of relations, attributes, and tuples. Plainly speaking, this translates to tables (relations), columns
(attributes), and rows (tuples). The value that a datum can take is constrained by
its domain. For example, the column “Name” could have a domain of ten characters.
Thus a table can be thought of as a collection of related data values [19]. Figure 3.1
illustrates a sample relational structure.
Each row in a table is normally identified by a unique primary key (or a set of keys
that are collectively unique) or by a foreign key that relates it to a tuple in another
table. For instance, consider Figure 3.1. The Student Information table is linked to
15
CHAPTER 3. BACKGROUND
the Parent information table via the StudentId field. This acts as the primary key
(PK) in the student data table, and a foreign key (FK) in the parent information
table. In this way relationships amongst tables can be defined. Furthermore, we
can identify the numeric relationship between the tuples in each table. In this case,
each student can have one or two parents. And each parent can have 1 or many
children (students). This is referred to as the cardinality of the relationship. Some
popular examples of RDBMs are: IBM’s Universal DB2 system [25], Microsoft SQL
Server [14], and Oracle Data Management System [16].
Student Information Table
StudentId
123456
654321
Last Name First Name
Doe
John
Smith
Karen
Gender
M
F
Parent Information Table
DOB
01/01/1980
30/03/1981
StudentId
123456
654321
654321
Last Name First Name
Doe
Senior
Smith
Catherine
Smith
Tom
ER View
Student Information
Parent Information
PK
StudentId
*
Last Name
First Name
Gender
DateOfBirth
Tuple
1 .. 2
FK1
StudentId
Last Name
First Name
Attribute Table
Figure 3.1: A simple relational model showing a one-to-many relationship between
student and parent information tables. The bottom portion represents
the schema in the Entity-Relationship (ER) notation. The top portion,
gives a physical view of the table by populating it with sample data points.
CHAPTER 3. BACKGROUND
16
The Structured Query Language (SQL) [29] serves as a standardized data definition, query, and update language for all relational database systems. SQL provides a
simple and efficient interface for describing and querying relational databases.
With three decades of experimentation, RDBMs have evolved into a robust database
technology with many strengths, including well developed concurrency controls, backup
and recovery functions, optimized query engines, and efficient indexing schemes. However, relational database systems have limited data modelling capabilities. The only
data structure available is the row-column structure. Furthermore, it is not suited for
the storage of complex data types such as multimedia objects and text. The system
is also rigid in terms of schema evolution. For example, dropping an attribute or a
column from a table would require the entire table to be recreated. These limitations
gave rise to a new database model - the object-oriented model.
3.2.2
Object-Oriented Model
Object-oriented Database Management Systems (OODBMs) are closely related to
object-oriented languages. Data is stored as objects that are described in terms
of their attributes, and functions that work on it [19]. Objects refer to abstract
entities that have attributes and methods/functions to manipulate or extract the
attributes. For example, consider the simple relational model outlined in Figure 3.1.
The same example is illustrated in an object-oriented model in Figure 3.2. This shows
a Student class being defined in terms of StudentId, LastName, FirstName, Gender,
DateOfBirth, and Parents attributes, and with methods such as getAge. In this case,
the Parents attribute is itself an object of the Parent class. In this way, we can
capture complex relationships between real-world entities.
17
CHAPTER 3. BACKGROUND
Student
1
+studentId : int
-lastName : string
-firstName : string
-gender : char
-dateOfBirth : string
-parents : Parent
Parent
-lastName : string
-firstName : string
1..2
+getName() : string
+GetParent() : string
+getAge() : int
+store()
2
+getName() : string
Class Student {
// member attributes
private int studentId;
private String lastName;
private String firstName;
private String gender;
private String dob;
// array of Parents.
private Parent [ ] parents;
// contructor
public void Student (int id, String lnam, String fname, String gen, String dateofbirth, Parent [ ] p) {
studentId = id;
lastName = lname;
firstName = fname;
gender = gen;
dob = dateofbirth;
parents = p;
}
// get student name
public String getName () {
}
// get parent name
public String getParent () {
}
// get age
public int getAge () {
}
// persistency method
public store () {
}
3
public class Studentdb {
public static void main(String[] args) {
// instantiate parent objects
Parent dad = new Parent("Smith", "Tom");
Parent mom = new Parent("Smithi", "Catherine");
Parent [] p = new Parent[2];
p[0] = dad;
p[1] = mom;
// create student object
Student s = new Student(654321,"Smith", "Karen",'F', "30/03/1981", p);
s.store
}
}
Figure 3.2: A simple object-oriented model for the example outlined in 3.1. (1) shows
the model in Unified Modelling Language (UML) notation. The Student
object is composed on lastName, firstName, gender, dateOfBirth, and
parents attributes. The parents attribute is itself an object of the Parent class. OODBMs supports storage and management of such objects,
thereby making them persistent. (2) shows the Java pseudo code for the
class corresponding to the Student object. (3) shows a instantiation of
the objects with sample data.
CHAPTER 3. BACKGROUND
18
Once this general class is defined, individual objects with unique identities can
be instantiated. However, the objects in a programming language are transient and
do not exist outside the program. An OODBMs facilitates storage, indexing and
retrieval of these objects, thereby giving them persistency and allowing objects to be
exchanged between applications. Support for concepts like inheritance, allows new
data classes to be described in terms of existing classes. Furthermore, unlike the
relational model, the object-oriented model tightly couples the data and application
programs. This means that both data and programs that manipulate the data can
be stored and managed on the same platform [4]. For instance, in the Student class
above, student information and the getAge method are stored together.
The strength of this model is in the flexibility it gives in storing abstract/complex
data types. This is particularly useful for scientific applications, as experimental data
can be stored in its natural form (without being decomposed into rows and columns).
Furthermore, data evolution is graceful in an object-oriented model. For example,
consider the problem of defining a new student class for part-time students. This
can be accommodated easily through the use of inheritance. That is, the new object
inherits all attributes of the existing student object and has an additional attribute
to indicate part-time status.
The weakness of this model is the lack of a standardized data model 1 . This
means that unlike SQL, object-oriented database systems do not have a standardized
access or query language. This makes object-oriented systems vendor specific, and
thus hard to migrate to a different system/vendor. Lack of standardization also
means that efforts at query language optimization are fragmented and differ from
1
The vendor initiated ODMG standard (Object Database Management Group) [10] was completed in 2001 (http://www.odmg.org/). However, it has yet to be widely accepted. OQL is the
query language based on this standard.
CHAPTER 3. BACKGROUND
19
system to system. Furthermore, although traversing among related objects (linked
objects) is fast, attribute selection and comparisons are not as optimized as they are
in relational systems [34]. For example, a query such as “select all students where
date of birth is greater that xyz” will execute faster on a relational system. This is
because operations such as join and select are highly optimized in relational systems.
Relational databases are a mature technology and have been fine-tuned for optimal
performance (at the cost of expressiveness). This is not yet the case for object-oriented
data management systems.
Despite these weaknesses, the popularity of the object-oriented approach to modelling scientific data is apparent from the excerpt below taken from a joint EU-US
workshop on large scientific databases [47]:
“The object-oriented languages and object persistency is becoming ubiquitous in scientific data processing: these technologies allow us to define
and store complex science objects and inter-relationships that we deal with
... We recommend the exploration of information models that have objectoriented characteristics of extensibility, so that the model is a serialization
of the object itself.” (pg. 15)
3.2.3
Object-Relational Model
Object-relational database systems (ORDBMs) were developed to incorporate the
robustness of relational systems with the expressiveness of object oriented models. A
number of database systems now offer the ability to develop, maintain, and manipulate objects within a relational framework [19]. This approach provides the familiar
structures and capabilities of RDBMs, and additionally provides key object-oriented
CHAPTER 3. BACKGROUND
20
functionalities such as user defined types, objects, and function. For example, abstract objects based on primitive data types (integers, characters, etc) can be defined
and stored in relational tables.
The strengths of this model are obvious: robustness and expressiveness. If objectrelational technologies provide the same level of flexibility and extensibility as objectoriented systems, then one can potentially gain from the robustness of relational
database systems and expressiveness of object-oriented systems.
3.2.4
Analytical Versus Transaction Processing Systems
Having identified the core DBMs technologies, we now focus on two distinct types of
workloads for which a data management system could be built: Online Transaction
Processing (OLTP) workloads, and Online Analytical Processing (OLAP) workloads.
Workload refers to the types of queries that the data management system is expected
to perform most frequently. The database systems designed for each of these workloads differ in the way data is organized and stored.
OLTP workloads are characterized by large numbers of data transactions (inserts,
updates, and retrievals) in short periods of time [18]. The systems that are designed
to cater for such workloads are referred to as OLTP systems. For example, consider an
airline reservation system. This system performs thousands of small data inserts and
updates (submitted by numerous users), and fixed queries such as reservation lookups,
flight availability, etc. In order to optimize for such workloads, OLTP systems are
generally designed as highly normalized relational databases. Again, Codd [12] pioneered the idea of data normalization in relational systems. Data normalization is the
process of distributing data across multiple tables in order to reduce redundancy, and
CHAPTER 3. BACKGROUND
21
thus minimizing insert/update anomalies [12, 19]. For instance, consider the example
in Figure 3.1. An insert in the attendance table would not require repeated inserts
of student first name and last name values.
OLAP workloads on the other hand, are characterized by ad-hoc queries (on
large amounts of data) and infrequent updates. The systems designed to cater for
such workloads are referred to as OLAP systems [19]. OLAP systems are designed
specifically for analytical purposes. These system are popular in customer-centered
environments, and are commonly referred to as Decision Support Systems (DSS) [44].
This is because they pool low level data and deliver it in a form that is understandable
to novice end-users responsible for high level data analysis.
However, there are two pre-requisites for an effective OLAP system:
1. Data has to be in a consistent state (removing all anomalies such as missing
values, noisy data, etc). This means data has to be integrated from operational
system(s) to a platform dedicated for data analysis.
2. Data should be stored in a schema that is optimized for OLAP type workloads.
In our context, the data management and analysis requirements indicate a need
for an OLAP type system. This is best realized through a data warehouse.
3.3
Data Warehouse
A Data warehouse (see Figure 3.3) is best described by Inmon [28] as: “ a subject
oriented, integrated, non-volatile and time-variant collection of data in support of
management’s decisions.”
22
CHAPTER 3. BACKGROUND
Operational Data
Data extraction,
transformation,
cleaning
Data Warehouse
Analysis Tools
Figure 3.3: A high level architecture of a data warehouse system [36]
In our case, the data warehouse supports scientific research by making OLAP
like query capabilities available to researchers. The defining characteristics of a data
warehouse system (in the present context) are explained below:
Subject-oriented: Data is conceptually organized by experiment metadata such as
subject, task, direction, etc. The goal is to create an efficient data structure
that can support the retrieval of experimental data based on metadata criteria.
For example, select discharge frequency for task ‘a’ and subject ‘y’.
Integrated: In a warehouse system, data is generally integrated from multiple operational systems. Relevant data from these systems are extracted, cleaned,
parsed, and aggregated for upload to a DBMs. In our case, we have only one
operational system (the current file-based system). However, we have a large
variation, from experiment to experiment, in the types of data collected. For
example, EMG, cell, and kinesiological data.
Non-volatile: Data is stored for a long time and generally never deleted.
CHAPTER 3. BACKGROUND
23
Time-variant: Data in a warehouse system is temporal, thus making it possible to
analyze it for trends over time. In our case, we have temporal data in the sense
of experiments conducted on a certain date and at a certain time. However,
more importantly, the data is temporal in the sense that the actual experimental
data is collected over the period of a movement. For example, a cell firing is
sampled over a movement period of a subject reaching towards a target.
Dimensional/Star Schema
As defined above, data warehousing involves cleaning, aggregating and transforming
source data and storing it on a platform optimized for OLAP type workloads. Our
proposed schema for the data warehouse is a dimensional or star schema.
The dimensional schema (see Figure 3.4) is a simplified relational schema that
minimizes the number of table joins. Krippendorf and Song [32] describe it as: “a
central fact table or tables containing quantitative measures of a unitary or transactional nature (such as sales, shipments, holdings, or treatments) that is/are related
to multiple dimensional tables which contain information used to group and constrain
the facts of the fact table(s) in the course of a query” (pg. 4).
The two key types of tables in a dimensional schema are described below:
Fact table: Kimball [31] describes the “facts” in a fact table as numerical measurements of a business taken at an intersection of all dimensions. Facts are
generally numeric, continuously valued (not discrete), and additive. In our context, we have measurable scientific facts. The granularity of the fact table is
determined by the unit of measurement of the facts. For instance, in our case,
we can define a trial level granularity (that is, the basic unit of access would be
CHAPTER 3. BACKGROUND
24
an entire trial from an experiment), or define a fine granularity whereby each
instant in time of a trial is individually accessible through SQL.
Dimension table: A dimension table gives identity to the facts in a fact table. As
seen from Figure 3.4, each data point in a fact table is identified by keys derived
from the dimension table. Dimension table attributes are generally textual and
discrete [31]. For example, in Figure 3.4, a store dimension attribute such as
location is textual (city names), and discrete (finite set of cities).
The dimensional model advocates de-normalized dimension tables (dimensional
data is not necessarily distributed across different tables to minimize redundances).
The reason for this is that dimension tables are relatively small compared to the
fact table, so the cost of introducing redundancy is relatively small. By avoiding
normalization on the dimension table, we reduce the number of relational joins (tables
joined using primary and foreign keys) in the schema , thereby improving performance
for large select queries. For instance, in most cases, a large query on the fact table,
will involve at most one dimension and thus one join.
The dimensional schema has been widely used in data warehouse projects and
is popular for business applications [21]. By minimizing the number of joins, a dimensional schema ensures optimum query performance for OLAP type workloads.
Furthermore, fewer joins ensure that SQL queries are simple and do not require a
deep understanding of the data model, and thus enables novice users to easily submit
ad-hoc queries to the warehouse system. This is particularly valuable in our case,
since the end-users will have little or no programming/SQL background and are in
the lab for relatively short periods of time.
25
CHAPTER 3. BACKGROUND
Time_dimension
PK
time_key
month
quarter
year
Sales Fact
Product_dimension
PK
Store_dimension
product_key
product_attributes
PK
FK1
FK2
FK3
time_key
product_key
store_key
sales facts
store_key
store_attributes
Figure 3.4: A sample dimension or star schema. The sales “fact” is joined to three
dimension tables, each describing a different aspect of the fact. For example, one could aggregate sales facts based on a product or a store.
CHAPTER 3. BACKGROUND
3.4
26
Related Work
Although the data and application requirements of this project are quite unique,
important design decisions and functionalities can be inferred from much work in the
area of scientific data management and analysis [20, 1, 45, 33, 2, 23, 39, 6, 11]. In
this section, some of this work is briefly described to gain a better understanding of
the opportunities and challenges in modelling scientific data.
The Human Brain project implements an object-oriented system (based on O2
database technology [5]) that stores structural images of the brain and functional
metadata associated with it [20]. The user-defined metadata makes it possible for
scientists to easily share their research. For example, images 2 of neural activation areas can be stored with metadata describing the experiment, statistical techniques
used, methodology, etc. The architecture separates raster data (in this case 3D
images) and metadata storage and management. The RaSDaMan system (http:
//www.rasdaman.com/) manages the raster data and provides a powerful query language for it, while the 02 system gives persistency to metadata objects. The architecture and design of the system is geared towards efficient storing, querying, and
exchange of brain images.
Another system that uses an object-oriented approach is the LOGOS system [45].
This system is more task oriented and has a library of functions that manipulate
neuroscience data 3 . For example, raw data signal can be processed via built in
object functions before statistical analysis. The architecture also integrates external
software tools, such as simulators and statistical packages, with the database module.
2
Functional magnetic resonance images (fMRI).
Neuroscience data in this case refers to both 2D and 3D images, and physiological time series
data such as nerve cell discharges.
3
CHAPTER 3. BACKGROUND
27
The data is organized and stored as objects and classes of objects with persistency
provided by the ObjectStore system (object-oriented DBMs).
The Earth System Model Data Information System (ESMDIS) [11] uses an objectrelational model for managing data related to ocean-atmosphere dynamics. The ESMDIS design separates the metadata from the actual data. The metadata is stored
on the Informix object-relational DBMs system, while the data is stored in Network
Common Data Format (netCDF). netCDF is a portable, self-describing, array-based
data storage format [40]. Thus, although data is stored outside the DBMs environment, the netCDF format allows standardized access to the data, and is referenced
by metadata that can be queried.
The CenSSIS (Center for Subsurface Sensing and Imaging Systems) is a webenabled database system for storing scientific data, primarily images [48]. CenSSIS
stores the actual data (images) on a file server with links to the metadata which is
stored on a relational DBMs (Oracle). The relational system storing the metadata is
designed to ensure flexibility and extendability. For instance, the metadata tables are
organized in a hierarchy where specialized metadata tables are linked to a base metadata table through unique identifiers. Thus, as new types of images are incorporated
into the system, the metadata table hierarchy can be easily extended.
The brief survey above identifies the following key themes that serve as useful
guides for this project:
1. The popularity of object-oriented features in these systems. This hinges on two
key requirements of scientific data: (1) Need for modeling complex data and
relationships, and (2) A need for flexible schema. If object-relational DBMs can
CHAPTER 3. BACKGROUND
28
deliver these functionalities, then there is a potential for combining the expressiveness of object-oriented systems with the robustness of relational systems.
2. A clear separation of metadata and data. In the cases above, we see that the
data is stored outside the DBMs environment, but indexed by metadata that
resides in a DBMs framework. As we will outline in Chapter 4, our system also
separates the metadata from the data (in this case, trial data). However, we
store both in the DBMs environment and at a fine level of granularity (the trial
data is not stored as character or binary objects).
For this thesis, we have chosen an object-relational database system for the warehouse implementation. As mentioned previously, object-relational systems provide
the flexibility of an object-oriented system together with the robustness of a relational system.
3.5
Research Methodology
Having outlined the fundamentals of DBMs and some related work in the area of
managing scientific data, we now focus on identifying a methodology for this research.
As outlined previously, the goal of the research is to develop a data management
and analysis system that efficiently and effectively stores, retrieves, and analyzes
large volumes of scientific behavioral data. Specifically, we propose a data warehouse
system based on an object-relational data management platform. The difficulties in
describing and defending a system development research methodology has been the
focus of a number of studies [35, 8, 7]. Furthermore, the challenges in evaluating such
research is articulated well by Weber [46] when he says: “The conundrum posed by
CHAPTER 3. BACKGROUND
29
design research for progress in a discipline emerges clearly when a paper describing
such research must be evaluated for publication in a learned journal. What are the
quality standards the reviewer must apply to decide upon its acceptability? Typically
the paper contains no theory, no hypothesis, no experimental design, and no data
analysis. Traditional evaluation criteria cannot be used. The paper’s contribution
requires an inherently subjective evaluation ” (p. 9)
To guide this research, we have adopted the methodology suggested by Nunamaker, Chen, and Pudin [35] and the evaluation criteria proposed by Burstein and
Gregor [8].
Nunamaker, Chen, and Pudin broadly describe system development research as
a concept-development-impact cycle where the proof of proposed concepts/theory
and impact of the theory are evaluated via system development. They suggest five
steps that we follow in this research. These steps, shown in figure 3.5, begin by
constructing a conceptual framework which evolves into a set of system requirements,
and finally into a prototype system. The methodology emphasizes the cyclic nature of
system development research in which knowledge about the system is gained through
incremental prototype development. Table 3.1 summarizes these steps and maps them
to the current research.
Burstein and Gregor expand on Nunamaker, Chen, and Pudin’s framework by
proposing five criteria for evaluating system development research. These criteria
address the issue of evaluating system development research in terms of significance,
internal validity, external validity, objectivity, and reliability of the system. In Chapter 6, we discuss these criteria in detail and use them as internal benchmarks for
evaluating our work.
30
CHAPTER 3. BACKGROUND
System Development
Research Process
Construct a
Conceptual
Framework
Develop a system
architecture
Analyze and Design
the system
Build the prototype
system
Observe and Evaluate
the system
Research Issues
- State meaningful research question
- Investigate the system functionalities and requirements
- Understand the system building process/procedures
- Study relevant disciplines for new approach and ideas
- Develop a unique architecture design for extensibility,
modularity, etc.
- Define functionalities of system components and
interrelationships among them
- Design the database/knowledge base schema and
process to carry out system functions
- Develop alternative solutions and choose one solution
- Learn about the concepts, framework, and design
through the system building process
- Gain insight about the problems and the complexity of the
system
- Observe the use of the system by case studies and field
studies
- Evaluate the system by laboratory experiments or field
experiments
- Develop new theories/models based on the observation
and experimentation of the system’s usage
- Consolidate experiences learned
Figure 3.5: IS Research steps from Nunamaker, et al (1991)
IS process as outlined by Nunamaker, et al
Mapping to current proposal
1. State meaningful research question
2. Investigate system functionalities and requirements
1. Research Goal: develop a data management and analysis system that
efficiently and effectively stores, retrieves, and analyzes large volumes
of scientific behavioral data. Specifically, we propose a data warehouse
system based on object-relational DBMs technology.
2. System requirements and functionalities are outlined and discussed in
Chapter 4.2:
• Data and metadata query support. Particularly temporal and
signal based slicing of data.
• Scalable and flexible schema.
• Developing an appropriate front-end analysis tool.
CHAPTER 3. BACKGROUND
Construct Conceptual Framework:
Develop system architecture:
1. Specify system components and interactions
2. Specify measurable requirements
1. Key components of the system are outlined in Chapter 4. These include
a parsing grammar, a data management system, and front-end analysis
tools.
2. Some of the requirements identified in Chapter 4 are measurable. However, some, such as the need for flexible schema, are inherently subjective.
Analyze and design system
1. Design to be based on theory and abstraction
1. A data warehouse system using a dimensional model based on objectrelational technology is proposed and designed. This design is based
on sound conceptual foundation outlined in this chapter.
Build system
A functioning data warehouse system is developed and currently contains 45GB
of experimental data.
Experiment, observe, and evaluate the system
The system is experimented and tested against the existing file-based system.
The testing has focused on measurable aspects such as query support and the
analysis interface. We also use the evaluation criteria suggested by Burstein
and Gregor as internal benchmarks for the system.
31
Table 3.1: A system development research methodology. The left hand column shows the research steps as outlined
by Nunamaker, et al [35], and the right hand column translates these steps to the current research.
CHAPTER 3. BACKGROUND
3.6
32
Summary
This chapter has outlined the data warehouse process and the foundational technologies on which it can be implemented. Furthermore, we have also looked at related
work in the area of scientific data management. Finally, we have identified and outlined a research methodology for this work. Thus, having laid down a solid research
foundation, the next chapter focuses on the actual data warehouse implementation.
Chapter 4
System Overview
4.1
Introduction
There are two primary goals for this chapter. First, to refine the problems identified
in chapter 2 into a set of requirements for the data warehouse system. Second, to
describe how data is currently organized in Dr. Scott’s lab, and then to outline
the data management system developed for storing, retrieving and analyzing the
data. The chapter also discusses key design decisions taken prior to, and during,
implementation.
4.2
System Requirements
From the data management and analysis problems identified in chapter 2 and through
consultations with end-users, we identify the following key requirements of the warehouse system:
1. Query support: From the discussion in chapter 2, we can identify two types of
33
CHAPTER 4. SYSTEM OVERVIEW
34
queries that can be expected of the data management system:
(a) Metadata queries: These are high level queries that allow researchers to
query metadata related to each experiment. For example, such queries
would answer questions such as “Do I have enough cells for analysis xyz?”.
The queries should be quick and not require a scan of the actual trial
data. The data model should thus capture metadata for each experiment.
Metadata in this case refers to data (mostly textual) that describes the
experiment. For example data such as subject information, experimental
events, etc.
(b) Trial data queries: These queries scan the actual trial data based on meta
data criteria. For example, a researcher should be able to retrieve individual data signals across different trials and different tasks based on criteria
such as subject, task, cell, etc. Furthermore, because we have event-based
time series data, data slicing based on time is also a key requirement. If
data is visualized as an n*m matrix where n represents each point in time
and m represents a signal at that point, then slicing can be thought of as
horizontal or temporal slicing of data. For example, a researcher might ask
for neural data in the first 20 milliseconds after the target light is projected
(reaction start time) and kinesiological data 60 milliseconds after target
illumination. Since data is logically organized into task experiments, such
operations should be possible across different trials and tasks.
2. Scalability: As mentioned earlier, data volumes are going to increase significantly as new recording equipment is introduced in the lab. Thus, the data
warehouse should be scalable both in terms of query time and data upload time.
CHAPTER 4. SYSTEM OVERVIEW
35
3. Schema evolution: the scientific process generating the data constantly shifts
and the data model should be able to evolve with these shifts. Furthermore,
programs that convert source data to match the database schema should also
be flexible enough to adapt to such changes. We can anticipate the following
schema evolution:
(a) New signals being measured or two experiments of the same type recording
different signals. For example, during a simple reaching task, one experiment might collect only cell data or only EMG data or both.
(b) Additional data types being recorded. For example, video or audio recording of the experiments could be collected in the future.
(c) Dropping signals. Some signals could be considered redundant and be
replaced by other signals. In a pure relational database, this would involve
dropping the entire table and copying its contents to a new table.
4. Analysis interface: Due to the nature of the analysis, SQL by itself is not sufficient for complex data analysis and visualization. Thus, the system has to interface with statistical tools, specifically MathWorks Inc’s Matlab software1 [27].
For this reason, a statistical front-end interface should be able to query and
retrieve the data in times comparable to the current file-based approach.
Having identified key requirements of the data warehouse system, we now outline
the existing data organization, before presenting the details of the warehouse system.
1
This is main statistical software currently used in Dr. Scott’s lab
CHAPTER 4. SYSTEM OVERVIEW
4.3
36
Existing Data Organization
At present, real time data from individual channels is collected by the National Instruments Corporation’s labVIEW software [15]. Two categories of data are collected,
analog data (neural and EMG recordings) and motor data such as hand and joint
position, velocity, torque and acceleration. This data is sampled at intervals of anywhere from 1000Hz to 4000Hz. The analog data and motor data is stored in separate
files and is processed by the Brainstorm software written in Matlab [41]. Figure 4.1
shows the current data/process flow. The analog and motor data is first re-sampled
at a lower frequency (200Hz) and interpolated into a single file (.sam file). The .sam
file is processed by the Brainstorm software, which applies data filters and adds additional header information for each trial to make the .pro files. The final step applies
aggregation functions to signal data and stores it as .avg files. Since .pro data is most
widely used in the lab for analysis, we will describe it in detail here.
Figure 4.2 shows the data organization in a .pro file (refer to appendix C for a
snapshot of a sample .pro file). Each .pro file is composed of three file-level headers
that contain metadata pertaining to all the data in the file. Each file contains data
from multiple trials of a movement in one direction. Furthermore, each trial has three
headers that contain metadata specific to that trial. Please refer to the lab technical
document for details on the data contained in all the headers [41]. A task or an
experiment generates multiple .pro files since it is composed of movements to a set of
different targets/directions.
The following are the variances one could find in the .pro files:
1. Different number of trials might be recorded.
37
CHAPTER 4. SYSTEM OVERVIEW
KINARM
Analog and Motor
data collected
labVIEW software
from KINARM
labVIEW software
.ANA file
.MOT file
.SAM
SAM file
file
Data is re-sampled
and filtered for
noise by Brainstorm
software
.PRO file
Stored in ASCII files
.AVG file
Figure 4.1: Data flow in the file based environment [41]. Data from KINARM is
successively filtered, processed and stored in separate files.
38
CHAPTER 4. SYSTEM OVERVIEW
PRO FILE
1
1
1
*
Trial
1
1
Header
1
1
Trial Header
1 1 1
1
TargetInfo
-TargetNum
-StartXPos
-...
1
1
1
1
1
Data
Experiment
StateCondition
ChannelConfig
-State
-LightsOn
-...
-ChanName
-MinValue
-MaxValue
1
-task
-subject
-cell
-...
1
*
TrialFeatures
StateTransitions
signals
-Method
-Value
-Trans1
-Trans2
-...
1
1
-SignalDat: array
Figure 4.2: A class diagram showing the structure of a .pro data file. Each .pro file
is composed of three file-level headers and data from one or more trials,
which in turn have three headers specific to the trial. The trial data is
composed of different types of signals, that vary from one .pro file to
another.
CHAPTER 4. SYSTEM OVERVIEW
39
2. Different number of signals and types of signals could be recorded. For example,
a .pro could have EMG, cell, or kinesiological data. Furthermore, the number
of channels for each type of signal might differ from one .pro file to another.
For example, different number of EMG channels could be recorded for each pro
file.
These variances are recognized by the parsing grammar described in Section 4.4.1.
4.4
System Architecture
In this section, we outline details of the system developed for Dr. Scott’s lab and
also describe the key design decisions taken prior to, and during, implementation.
System implementation was iterative, with changes being made as familiarity with
both the DB2 system and scientific data increased. Features were also added as
usability issues became apparent from end-user feedback during testing. The system,
to some extent, had to reflect the manner in which data is currently retrieved and
analyzed by researchers. We begin by outlining the final system and then describe
the rationale behind the design.
The .pro data file was selected as a starting point because it is the most commonly
used data file for analysis. The raw analog and motor data files are rarely used in
day-to-day analysis because they are noisy and sampled at a high frequency. The
Brainstorm software starts the process of cleaning the data and thus we could choose
data from either .sam, .pro, or .avg files for transfer to the warehouse system. By
starting with .pro data, we make the system instantly available to end-users. However,
since conversion from raw data to .pro data involves information loss, future work
will need to integrate .ana and .mot data into the warehouse system.
40
CHAPTER 4. SYSTEM OVERVIEW
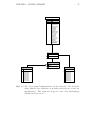
Current Data Flow
KINARM
ANALOG
FILES
1. Parse input data using
a Perl based grammar
MOTOR
FILES
2. Data import scripts makes use of bulk
loading utilities provided
by the database system
SAMLED
FILE
PROCESSED
FILE
PARSING
GRAMMER
1
AVERAGED
FILE
3. Query the database
using:
- DB2 tools such as
command line processor
and java based GUI
- A Matlab Interface
* Custom made Java
class that queries the
database using a JDBC
driver and stores the
data in Java objects
which are served to the
Matlab environment
Parsed Files
DB2 Import
Scripts
2
DB2
DATA WAREHOUSE
server
3
client
DB2 Interface tools
- Command Line Processor
- GUI
*Java class files
Matlab
Environment
ProInfo Struct
Figure 4.3: An overview of the data warehouse system. Data from .pro file is parsed
and uploaded to the data warehouse system. A custom made Matlab
interface uses a Java library to query the database and bring data to the
analysis platform.
CHAPTER 4. SYSTEM OVERVIEW
41
START RULE: EXPERIMENT_HEADER VERSION STATE CHANNEL FILE_INFO TRIAL_DATA(S)
{
Do something if parsed correctly
}
TRIAL_DATA: TRIAL_HEADER STATE_TRANS TRIAL_FEATURES SIGNAL_DATA
SIGNAL_DATA: DATA1|DATA2|DATA3|DATA4|DATA5
EXPERIMENT_HEADER: REGULAR EXPRESSION TO RECOGNIZE HEADER
VERSION: REGULAR EXPRESSION TO RECOGNIZE VERSION
STATE: REGULAR EXPRESSION TO RECOGNIZE STATE CONDITIONS
CHANNEL: REGULAR EXPRESSION TO RECOGNIZE CHANNELS
FILE_INFO: REGULAR EXPRESSION TO RECOGNIZE RAW DATA SOURCE
TRIAL_HEADER: REGULAR EXPRESSION TO RECOGNIZE TRIAL HEADER
STATE_TRANS: REGULAR EXPRESSION TO RECOGNIZE STATE TRANSITIONS
TRIAL_FEATURE: REGULAR EXPRESSION TO RECOGNIZE TRIAL FEATURES
DATA1: REGULAR EXPRESSION TO RECOGNIZE CELL(1) + KINESIOLOGICAL DATA
DATA2: REGULAR EXPRESSION TO RECOGNIZE CELL(1,2) + KINESIOLOGICAL DATA
DATA3: REGULAR EXPRESSION TO RECOGNIZE CELL(1) + KINESIOLOGICAL + EMG DATA
DATA4: REGULAR EXPRESSION TO RECOGNIZE CELL(1,2) + KINESIOLOGICAL + EMG DATA
DATA5: REGULAR EXPRESSION TO RECOGNIZE VARIABLE EMG + CELL CHANNEL DATA
Figure 4.4: Grammar rules that generate the parser. The left hand side of a statement
gives the rule name, and the right hand side gives the regular expression
for the data sequence to be parsed.
Figure 4.3 shows a high level view of the key components of the warehouse system.
The system can be divided into three key components: a parser for source data
transformation, a database for storing and querying the data, and finally the Matlab
interface to bring the data to the analysis platform. Each of these three components
are described below.
4.4.1
Parse Grammar
The starting point for the system is a perl based parser that processes the .pro data
files and extracts relevant data for upload to the data warehouse. The parser is based
42
CHAPTER 4. SYSTEM OVERVIEW
Start Rule
Header Information
Trial Header
Version
Trial Data
State Transitions
State
Trial Features
Data1
Data2
Channels
File Info
Signal Data
Data3
Data4
Data5
Figure 4.5: A tree diagram to illustrate the structure of the grammar shown in Figure 4.4
on a Perl programming language module, Parse::RecDescent [13], that generates the
parsing code based on a user-defined grammar. In essence, the grammar encodes
knowledge specific to a .pro data file as a set of rules and re-organizes source data to fit
the database schema. Figure 4.4 shows the grammar with actual regular expressions
given in appendix D. Each statement gives a rule name followed by the action to be
performed if the rule is satisfied. The start rule describes the overall structure of the
.pro file. This structure is better illustrated in Figure 4.5.
There are several advantages to using this rule-based parsing approach. First,
due to numerous variations in the input files, line by line parsing would be very
cumbersome programmatically. A grammar is much more elegant, modular, and
extensible. This ties in with the overall goal of making a system that can adapt
to changes in the scientific process generating the data. For example, the grammar
CHAPTER 4. SYSTEM OVERVIEW
43
already distinguishes between five types of .pro data formats (see rule SIGNAL DATA
in figure 4.4). When a new signal is recorded, this rule can be extended by adding
the regular expression for recognizing the new data format.
Secondly, a grammar makes it easier to code extensions, such as combining the
data parsing and upload steps into a single program. This could be considered as a
mediator-based approach to source data transformation. In such an approach, source
data is communicated to a mediator using data wrappers. The mediator then resolves
semantic and syntactic differences between the source and the warehouse schema using
transformation rules [17]. The choice of using the Perl programming language for this
task was based on easy to use data extraction features such as regular expressions,
and the availability of a simple recursive descent grammar module.
4.4.2
Data Warehouse
The data warehouse module of the system shown in Figure 4.3 uses IBM’s DB2
Universal Database system [25]. DB2 is a leading relational database system. It also
supports object-oriented features such as user defined objects, and thus provides an
excellent opportunity to leverage the power of a mature relational database platform
while benefiting from the flexibility of object-oriented functionality. Furthermore,
DB2 is freely available for research purposes and is used by the Database Research
lab at Queen’s University.
The schema shown in Figure 4.6 is based on the dimensional model discussed in
Chapter 3. The fact table, labelled TRIAL DATA in the diagram, contains signal
data from every trial and for every experiment. Data in this table is qualified by
the following dimension tables: TRIAL HEADER, EXPERIMENT HEADER, and
44
CHAPTER 4. SYSTEM OVERVIEW
TRIAL_HEADER DIMENSION
STATE_CONDITIONS DIMENSION
TRIAL_DATA FACT
EXPERIMENT DIMENSION
PK TrialNum
PK Filenum
TargetNum
StartXPos
StartYPos
TarXPos
TarYPos
Scans
PK Filekey
1..*
1
STATE_TRANSITIONS DIMENSION
PK TrialNum
PK Filenum
Trans1
Trans2
Trans3
Trans4
Trans5
Trans6
Trans7
Trans8
1
1..*
Time
Handxpos
Handypos
Shoang
Elbang
Shovel
Elbvel
Handxacc
Handyacc
Shotor
Elbtor
Mot1tor
Mot2tor
Tanacc
Tanvel
Emg1
Emg2
Emg3
Emg4
Emg5
Emg6
Emg7
Emg8
Emg9
Emg10
FK1,FK2
TrialNum
FK1,FK2,FK3 Filenum
1..*
1
Monkey
Arm
Hemisphere
Mass
ArmLen
ForearmLen
Chamber
PenNum
PenX
PenY
Rate
Mot1
Mot2
Date
Proto
Version
MonkeyNum
Task
TaskRepetition
Target
Cellnum
1
State
LightsOn
LightsOff
TarPos
Motor
1..*
PosLim
TimeLim
TimeVar
FK1 Filenum
TRIAL_FEATURES DIMENSION
1 1..*
Feature
Method
Value
TrialNum
FK1 Filenum
Figure 4.6: The data warehouse schema. This is a star schema in which all trial data
is stored in large table referred to as the fact table. Data in the fact table
is qualified by the foreign keys linking it to the dimension tables. These
are smaller tables that identify each fact or row in the fact table.
45
CHAPTER 4. SYSTEM OVERVIEW
1
Oid
Name
Weight Arm length
Typed table based on structured
type
2
Regular Col 1
Regular Col 2
Subject Object
Col
Column in a table based on structured type
Figure 4.7: user-defined objects and typed tables in DB2. 1. shows it being stored
in a typed table where the attributes are mapped to table columns, 2.
shows the user-defined object stored in a regular table column.
STATE TRANSITIONS. Furthermore, the experiment dimension contains two subdimensions: STATE CONDITIONS and TRIAL FEATURES. Sub-dimensioning is
referred to as snowflaking in the data warehousing literature [31]. A direct relation to
the fact table would necessitate an extra primary key in the table since every trial has
multiple features and state conditions (that is a many-to-many relationship with the
fact table). A possible alternative would be to separate each condition and feature
into a separate relationship (or table). However, this increases processing in the data
parsing step. To keep the parsing step and the warehouse design relatively intuitive,
the sub-dimension tables are used.
All dimension tables are based on structured user-defined objects. In DB2 terminology, they are referred to as typed tables [3]. Typed tables allow user-defined
CHAPTER 4. SYSTEM OVERVIEW
46
objects and object hierarchies to be stored in DB2 tables as either rows or object
columns (see Figure 4.7). For example, we can define an object “Subject” with the
following attributes: name, weight, and arm length. This object can now be stored
in a table with each attribute translated to a column. The advantage of using typed
tables is the added flexibility it provides in terms of adding and dropping attributes.
Furthermore, it allows the attributes to be treated like columns in a table and so they
can be indexed and queried. The fact table, however, is designed as a regular table
for reasons outlined below.
Key Design Decisions
As discussed previously, a number of design decisions led to the final database schema
shown in Figure 4.6. Below are some of the key issues addressed during implementation:
1. Data granularity: One possible design for this database would be to store data
for each trial as a Binary Large Object (BLOB) or a Character Large Object
(CLOB). Although this coarse grained approach would make schema evolution
much simpler, we decided on a fine grained approach (that is, each data point
is explicitly stored as a row) because of the following reasons:
(a) CLOB and BLOB data cannot be queried by the database and thus horizontal or vertical slicing of data (time epochs within a trial or signal
filtering) is not possible using SQL queries. Storing signals as BLOBS or
CLOBS would essentially create an index for each signal or a set of signals
with data selection being done outside the Data Management System.
47
CHAPTER 4. SYSTEM OVERVIEW
BASE_DATA_HIERARCHY
base_data
PK,I1
OID
TIME
HANDXPOS
HANDYPOS
SHOANG
ELBANG
SHOVEL
ELBVEL
HANDXACC
HANDYACC
SHOTOR
ELBTOR
SHOACC
ELBACC
MOT1TOR
MOT2TOR
TANACC
TANVEL
TRIALNUM
FILENUM
data_cell1_noemg
cell1
data_cell12_noemg
cell2
data_cell12_emg
Channel1
Channel2
Channel3
Channel4
Channel5
Channel6
Channel7
Channel8
Channel9
Channel10
data_cell1_emg
channel1
channel2
channel3
channel4
channel5
channel6
channel7
channel8
channel9
channel10
Figure 4.8: The object-oriented implementation for the fact table. The fact table
starts with the base attributes, from which sub-tables are created using inheritance. This design was dropped because of the disadvantages
identified in Section 4.4.2.
CHAPTER 4. SYSTEM OVERVIEW
48
(b) The approach would necessitate an interface or application that is capable
of making sense of the binary or character data (i.e. parsing and tokenizing
the output data). For example, in the case of BLOB data, an application
would have to query the database and parse the binary output to Matlab
readable data.
(c) Finally, as discussed in Chapter 2, evidence from data mining research indicates that considerable effort goes into preparing input data for mining
algorithms. With all data points explicitly stored in rows and columns,
data extraction can be done relatively easily using SQL. This design therefore facilitates future data mining projects.
2. Typed versus regular fact table: Initially the fact table was designed as a typed
table. Figure 4.8 shows the data hierarchy in the original typed fact table. The
hierarchy starts with a set of kinesiological attributes/signals that are recorded
in every experiment. From this base type, additional objects are defined that
inherit the base attributes and add to it. For example, the data cell1 noemg
object inherits attributes from base data and additionally has a cell discharge
attribute. This is just one instance of possible object hierarchies for the data at
hand. Another object oriented design would be to identify three data objects:
kinesiological, neural, and EMG data objects, and then make a complex object
by combining the three. Although, such an approach gives more flexibility in
terms of schema evolution, there are a number of disadvantages:
(a) Typed tables require each object (or row) to have a unique identifier.
In this case, because we have time series data sampled at a very high
frequency, we would have millions and possibly billions of unique object
CHAPTER 4. SYSTEM OVERVIEW
49
identifiers. Furthermore, the physical implementation of the typed table
contains a system generated type id. This makes typed tables for trial data
expensive, both in terms of storage and insert time performance. With the
warehousing schema identified in Figure 4.6, trial data is identified by its
relationship to the dimension tables and thus does not need a unique identifier over and above the foreign keys derived from the dimension tables.
(b) Another issue is that the DB2 bulk loading command, LOAD, is not supported on typed tables [3]. This further deteriorates insert performance,
and also adds the overhead of writing a highly optimized loading script.
Data uploads in this case are significant, a single recording session could
collect anywhere from 1-2 GB of raw data and 100-200MB of re-sampled
data.
In terms of schema evolution, regular tables allow attributes or columns to be
added as required. In terms of dropping attributes, the entire table would need
to be dropped and recreated. However, dropping attributes at present seems
like an unlikely scenario.
4.4.3
Matlab Interface
As mentioned earlier, because of complex analysis, SQL by itself is not sufficient for
data analysis. Since the Matlab software is the primary analysis tool in the lab, a
custom interface was developed for it to communicate with the database.
The interface communicates with the DB2 system via a Java programming language class. The Matlab scripting environment allows Java objects to be instantiated
CHAPTER 4. SYSTEM OVERVIEW
50
and gives access to object methods and attributes. We therefore developed an application that uses Java Database Connectivity (JDBC) to communicate SQL statements
to the database and organizes the retrieved data in a Java object hierarchy. The Java
implementation makes the data much more portable and independent of either Matlab or the specific platform, which is important in situations where data needs to be
shared with other researchers or there is a migration to another statistical software.
Prior to the data warehouse implementation, the starting point for data analysis was a Matlab script that organized .pro data in a localized structure (proinfo
struct) [41]. Since this structure has been used for a number of years, a large library
of custom built functions and scripts crucial for data analysis rely on data being in
this structure. To ensure immediate usability of the data warehouse, the interface
returns a structure identical to the proinfo struct. The proinfo struct is a legacy
structure that imports all data related to a profile and does not truly use the power
of SQL to cut and slice the data. In the long run, functions that use the proinfo
struct can be phased out and replaced by more efficient ones based on SQL queries.
4.5
Summary
This chapter outlined the data management system implemented as a proof of concept
for this thesis and explained the rationale behind key design decisions. As noted, each
decision has potential benefits and drawbacks. The database design is constrained by
two factors: 1) the functionality provided by the database system and, 2) the need to
incorporate a large library of functions and data developed over a number of years.
The implications of both of these factors are discussed in Chapters 6.
Chapter 5
Analysis
5.1
Introduction
This chapter has two primary goals:
1. To demonstrate that the data warehouse system meets the key requirements
outlined in Chapter 4.
2. To identify new functionality added by the data warehouse system and compare it against the file-based approach. The idea is to illustrate how the new
capabilities add value to the end-users (researchers).
The chapter is organized as follows: sections 5.2, 5.3, and 5.4 show the added
capabilities of the data warehouse system and compare it to the file-based approach.
Section 5.5 deals with operational aspects of the warehouse system, specifically looking at data parsing and uploading to the data management system. Section 5.6 deals
with issues of schema evolution and scalability in the warehouse managed environment. These issues arise from the need to introduce a data model that is both efficient
51
CHAPTER 5. ANALYSIS
52
and flexible. Finally, section 5.7 summarizes the discussion in this chapter.
All testing outlined in this chapter is done on a machine with the following specifications:
1. Operating System: Windows XP Professional
2. CPU: Xeon 2.4Ghz processors * 2
3. RAM: 2 GB
4. Software: DB2 data management system V8.2 service pack 4
5. Java version 1.4.0
6. Matlab version 6.5.1
Currently, the database contains 45 Gigabytes of data. It is comprised of 20,721
distinct cell-data-task-subject combinations and 95,475,388 records in the fact table.
5.2
Query Support
The main benefit from the use of a data warehouse is the formal query support. SQL
provides easy and efficient access to the data warehouse. Researchers can query data
using different criteria, such as experiments, tasks, subjects, etc. Also, because of the
fine grained design of the data warehouse (data points are explicitly stored as rows
in the fact table), researchers can slice the data horizontally (by signal) or vertically
(by time epoch). Together with ease of use, there is added efficiency in terms of the
system resources needed to run large analytical tasks and the number of disk I/O’s.
CHAPTER 5. ANALYSIS
53
From an end-user point of view, there are two major classes of queries that are
executed frequently: metadata queries and trial data queries (or fact table queries).
To compare this new capability against existing file-based access scripts, we have
tested the running time of sample queries in each category against Matlab scripts for
the same task. The Matlab scripts for testing purposes were written by an experienced
Matlab programmer in Dr. Scott’s lab who is not involved in this research.
5.2.1
Metadata Query
To test metadata query capability, we have implemented two queries and compared
the performance against Matlab scripts written for the same task. Note that the warehouse system is expected to perform even better relative to the file-based approach
because:
1. The Matlab script randomly picks files from a local folder and does not select
data based on user criteria as does the SQL query. Thus the cost of searching
for relevant data in the file-based approach is not captured in this analysis.
2. Before each query, the DB2 buffer pool was reset. This minimizes the impact
of data buffering and results in the maximum number of physical reads of data.
Metadata Query 1 - Movement Onset Time
This is a simple query that retrieves the movement onset (MT start) time (an event
time stamp) from the dimension table containing trial features. The query (shown in
Figure 5.1) first selects file keys from the experiment header dimension based on user
criteria, and then retrieves the corresponding movement onset time value for each
CHAPTER 5. ANALYSIS
54
SELECT value as MTStart, filenum, trialnum
FROM experiment_header as ex, feature_dimension as featr
WHERE subject=’a’ AND task=’a’ AND cellnum < 50 AND
featr.feature=’MTstart’ AND featr.method=’State’ AND
ex.filenum=featr.filenum
ORDER BY filenum, trialnum
Figure 5.1: Sample metadata query that retrieves movement onset time (MTstart)
from the trial features dimension table
trial in the experiment. The same value was also retrieved from .pro files using a
Matlab script (code shown in Appendix A.1).
Figure 5.2 illustrates the results of running the SQL query and the corresponding
Matlab script. The queries were run multiple times, and the results indicate the
mean run time, the variance within the multiple runs are not significant. As can
be seen, SQL queries are at least 30 times faster than the file-based access script
written in Matlab. Also, the running time for the SQL query is essentially flat (slope
of 0.007 seconds per file), compared to the Matlab script which has a slope of 0.3
seconds/file. This is because of the fixed cost, in the file-based system, of opening
and reading the entire file into the Matlab environment. In Figure 5.2, “number of
files” simply refers to the number of records fetched from either the warehouse system
or the .pro data files. For example, “50 files” means 50 MT start values were retrieved
from the metadata tables (in case of SQL access) and .pro data files (in case of filebased access). Thus, the slight increase in SQL query time (0.007 seconds for every
additional file) can be explained partly by this increase in the result set, which has
55
CHAPTER 5. ANALYSIS
70
60
50
40
Time
(secs)
SQL - local machine
SQL - client machine
file-based access
30
20
10
0
50
100
150
SQL - local machine
0.9
1.1
1.5
1.9
SQL - client machine
1
1.1
1.5
1.8
33.2
52
65.5
file-based access
18
200
Number of Files
Figure 5.2: Results of running metadata query 1 shown in Figure 5.1. On average, the
SQL queries are about 30 times faster than the file-based access script.
Furthermore, the SQL query time is essentially constant, as the number of
files increases, whereas the Matlab script running time grows as a function
of number of files in the input set. The results also show that running the
query from a client machine over a local area network does not degrade
performance.
56
CHAPTER 5. ANALYSIS
SELECT DISTINCT ex.cellnum, ex.task, ex.date, ex.time
FROM experiment_header as ex,
(SELECT filekey,cellnum, date,time
WHERE task=’c’ AND subject=’c’ AND
(SELECT filekey,cellnum, date,time
WHERE task=’b’ AND subject=’c’ AND
from experiment_header
cellnum < 40) as taska,
from experiment_header
cellnum < 40) as taskb
WHERE
((taska.date < taskb.date) OR
((taska.date = taskb.date) AND (taska.time < taskb.time)
))
AND (taska.cellnum = taskb.cellnum)
AND ((ex.filekey=taska.filekey) or (ex.filekey = taskb.filekey))
ORDER BY cellnum,date,time
Figure 5.3: metadata query 2. Retrieves all cells which were recorded for both task
‘a’ and ‘b’, where task ‘a’ was recorded prior to task ‘b’.
to be written to an output file, and partly because the result criteria is wider (more
records match the criteria: “cellnum < x”).
Furthermore, since most end-users are going to query the database over a local
area network, the query was also executed from a client (remote) machine on the
same network as the database server. In this case, since the result set is much smaller
than the data set that is queried, running the query from a client machine does not
degrade performance.
Metadata Query 2 - Cell Selection Query
In this query, we retrieve the cells which are recorded for experimental task ‘a’ and
task ‘b’, where task ‘a’ is recorded prior to task ‘b’ (see query in Figure 5.3). This
is a common query that helps researchers identify whether there are enough cells for
57
CHAPTER 5. ANALYSIS
14
12
10
8
Time (secs)
6
SQL - local machine
SQL - client machine
File-based access
4
2
0
50
100
150
200
SQL - local
machine
0.36
0.36
0.34
0.36
SQL - client
machine
0.31
0.39
0.36
0.39
6.25
12.15
13.9
File-based access
5.6
Number of Files
Figure 5.4: Results comparing data warehouse performance against file-based access
for metadata query 2. Despite a better relative performance compared to
query 1, file-based access is still slower than the SQL query for the same
task. Again, running the query over a network client has no effect on
performance.
CHAPTER 5. ANALYSIS
58
data analysis across tasks and/or subjects.
This query is different from metadata query 1 in that the corresponding Matlab
script for the task is more efficient. It uses filenames to identify those that match
the task criteria and thus does not have to open/read all the files in the input set 1 .
Despite this, as the results in Figure 5.4 indicate, the Matlab script for the task (see
Appendix A.2 for code), is still about 26 times slower than the SQL query. Also, the
SQL query time is essentially flat (as the number of files increases), compared to the
Matlab script. A run time profiler for the Matlab script shows that the execution time
is dominated by calls to read pro.m script (the script that reads the file to memory).
So although there are fewer calls to read pro.m (when compared to metadata query
1), it still is the primary performance bottleneck.
5.2.2
Trial Data Query
To compare the data warehouse against the file based approach for trial data retrieval,
we ran a query that calculates cell discharge rate (spikes per second) between two
events: reaction start time (RTstart) and movement onset time (MTstart) 2 . Again,
the same task was performed using a Matlab script to retrieve relevant data from
.pro files. The SQL query is shown in Figure 5.5 and Matlab code for the task is
included in Appendix A.3. This task was selected for testing because it is a common
procedure executed by researchers. Furthermore, the query captures the key strength
1
All .pro files are named using a standard naming convention that indicates some experimental
metadata, such as: task, subject, repetition, direction, target, and cell number. For example,
consider a sample filename ‘aa1x0001’. The first three characters identify the subject (‘a’), task
(‘a’), and experiment repetition (‘1’). The last four digits identify the target (‘0’) and cell number
(‘001’).
2
Trial data refers to the data collected during an experiment. For instance, in this case, signals
such as cell discharge, elbow velocity, elbow torque, etc, are collected during a trial for a particular
task/movement.
CHAPTER 5. ANALYSIS
59
SELECT
(SUM(cellsignal1)/(count(time)*0.005)),data.filenum,data.trialnum
FROM trial_data AS DATA,
(SELECT value AS rtstart, filenum, trialnum
FROM trial_features WHERE METHOD=’State’
AND FEATURE=’RTstart’ AND
filenum IN
(SELECT filekey FROM experiment_header
WHERE cellnum < 47 AND subject=’c’
AND target=0 AND
filekey NOT LIKE ’%%%x%e%%’)
) AS EVENT1,
(SELECT value AS mtstart, filenum, trialnum
FROM trial_features
WHERE METHOD=’State’ AND FEATURE=’MTstart’ AND
filenum IN
(SELECT filekey FROM experiment_header
WHERE cellnum < 47 AND subject=’c’ AND target=0
AND filekey NOT LIKE ’%%%x%e%%’)
) AS EVENT2
WHERE DATA.TIME BETWEEN EVENT1.rtstart AND EVENT2.mtstart AND
EVENT1.filenum=DATA.filenum AND
EVENT2.filenum=DATA.filenum AND
DATA.trialnum=EVENT1.trialnum AND
DATA.trialnum=EVENT2.trialnum
GROUP BY DATA.filenum,DATA.trialnum
ORDER BY DATA.filenum,DATA.trialnum
Figure 5.5: An SQL query that calculates the cell discharge frequency (spikes/second)
between reaction start time and movement onset time.
60
CHAPTER 5. ANALYSIS
Cell Discharge Freq - SQL vs File-based Access
70
60
50
40
Time (secs)
30
SQL - local machine
SQL- client machine
File-based access
20
10
0
50
100
150
200
SQL - local machine
9
16
25
32
SQL- client machine
9
15
25
31
18
33
51
64
File-based access
Number Of Files
Figure 5.6: Results of running trial data query in Figure 5.5 against a file-based access
script. The SQL query time (in seconds) is about half the time taken by
the Matlab script. Also, running the query from a client machine on the
same network does not degrade performance. The result set for this task
is relatively small since each file has anywhere from 5-7 trials. The largest
result set is 1260 rows. However, large number of rows are processed (see
Figure 5.7) to get these results.
61
CHAPTER 5. ANALYSIS
1400000
1200000
1000000
800000
No. Of Data Rows
600000
Rows selected by SQL
Total No. of rows in the
experimental data
400000
200000
0
Rows selected by
SQL
Total No. of rows in
the experimental
data
50
100
150
200
28698
57723
101386
126012
319258
602145 1017906 1254818
Number Of Files
Figure 5.7: This diagram illustrates the differences in the number of rows selected by
the trial data query (Figure 5.5) and the total number of rows in the .pro
data files. As can be seen, the Matlab script has to import significantly
more data rows than SQL.
62
CHAPTER 5. ANALYSIS
of our warehouse model - the ability to slice data horizontally (based on time stamps),
and vertically (based on signal of interest).
The results of this test (see Figure 5.6), shows that the SQL query is still twice
as fast as the Matlab script. Assuming Matlab and SQL are both equally efficient in
the computational task, the speedup can be attributed to SQL’s ability to retrieve
only relevant data into memory as opposed to all data related to the experiment.
Figure 5.7, compares the number of rows processed by SQL versus the total number
of rows that the Matlab script has to bring into memory. In terms of signals, SQL
selects 2 signals as opposed to approximately 32 signals that the Matlab script brings
into memory. In terms of number of data rows, for this task, SQL retrieves and
processes approximately 10% of the total number of data rows.
Another observation is that the running time for the Matlab script for this task
is more or less equal to the running time for the task outlined in metadata query
1 (Figure 5.2). Since the Matlab script corresponding to metadata query 1 simply
opens a file and looks up a value, a comparable execution time indicates that for
simple analysis (such as the trial data query outlined above), the biggest cost for filebased access scripts, is opening and reading relevant data into memory. A runtime
profile of the Matlab script confirms this observation and indicates that on average
87% of time is spent reading .pro files
3
3
The Matlab scripts in all of the above analysis are interpreted and not compiled. Although
compiled programs give better performance, in this case it will have very little impact since the
dominant performance factor is opening/reading the file (I/O).
CHAPTER 5. ANALYSIS
5.3
63
Data Management
The new warehouse managed environment clearly adds value in terms of data management tasks such as backups and ensuring that valid data is made available to end
users. Previously, all such operations were manually driven and enforced by the lab
administrator. Furthermore, the availability of metadata queries allows researchers to
better plan new experiments. For instance, metadata query 2 (shown in Figure 5.3)
allows researchers to make quick decisions on whether more data is needed for a particular analysis or not. With the file-based approach, such queries are still possible
if all files are stored on a single machine. However, the running time and the effort
required in generating such queries is prohibitive. For example, a look at the code
in Appendix A.2 shows a line count of approximately 60 lines (without comments)
and it took an experienced Matlab programmer approximately 2 hours to write and
debug.
Finally, the data warehouse environment reduces data redundancy by creating
a centrally accessible and shared data repository. The results of running metadata
and trial data queries over the local area network indicates that the running time
is within an acceptable range. Also, for computations on extremely large data sets,
stored procedures (discussed below), can be run on the server machine with only
the results transported to the client, thereby avoiding large data transfers over the
network. Compare this to the current environment, where all data files are transferred
to a client machine for every analysis.
CHAPTER 5. ANALYSIS
5.4
64
Data Analysis
The data warehouse system adds value to the data analysis process by enabling faster
and easier access to research data. Furthermore, the data warehouse environment
makes three additional functionalities available to researchers:
1. Built in functions within SQL allow researchers to perform quick analysis on
the entire data set with only results served to the client machine. For example,
common statistical functions such as correlations, linear regressions, etc., are
built into the SQL function library [29]. For instance, the trial data query
outlined in Figure 5.5, which sums a fact table column, could just as easily
apply statistical functions to it.
2. The ability to define functions and stored procedures [3] enables complex data
analysis procedures to be coded, stored, and executed on the data warehouse
system as user-defined functions or procedures. These procedures support better
utilization of resources, and avoid the need to query large data sets over the
network.
3. The availability of user defined procedures and database triggers allows common
analysis and data cleaning tasks to be automated. Database triggers are actions
that are triggered by events such as data updates, deletions, and inserts. For
example, upon data insert, a trigger could run stored procedures that extract
key information such as discharge frequency, movement start time, etc.
Furthermore, these functionalities, combined with a standardized data structure
and access language, are expected to aid data mining processes. For instance, data
CHAPTER 5. ANALYSIS
65
mining algorithms, that analyze data filtered by SQL queries, can be coded as stored
procedures.
Finally, as described earlier, we have also implemented a Java-based Matlab interface that queries the data warehouse and returns the results into a structure similar to
the one currently used in Dr. Scott’s lab (proinfo structure). This is a necessary step
in the short run due to a large number of analysis scripts dependent on the proinfo
structure. The testing done with this interface is described below.
Java-based Matlab Interface
As described earlier, the Java-based Matlab interface retrieves data into a structure
that is similar to the one currently used in Dr. Scott’s lab (proinfo structure). Since
data from all 5 dimension tables is loaded into the structure, it is a very inefficient
use of the data warehouse. Furthermore, the dimension table and fact table queries
(although quite fast) have to be executed for every file matching the user criteria. So
if 200 files match a user criteria, then (200 * 5) dimension table queries and 200 trial
data queries are executed 4 .
Also, the cost of selecting relevant data is not captured when running file-based
access scripts such as readpro.m 5 . For instance, in this case, the required files were
just copied from CD’s to the local hard drive. A simple test that copied 1000 .pro
files to the local hard drive showed that on average 0.2 seconds are added per .pro file
for retrieving relevant data to the hard drive. This is just the time to transfer data to
the local machine, and still does not capture the data selection cost entirely. Thus,
4
One way to avoid this is to add additional logic in the application to query all the dimension
tables and fact table once and then create the structure using trial numbers and file keys, however,
this would require these values to be brought into memory for every data point.
5
This is an existing Matlab script used for reading .pro file data [41]
66
CHAPTER 5. ANALYSIS
250
200
150
Time (secs)
100
File-based - Without copy time
File-based - With Copy Time
Java-based Matlab Interface On local Machine
Java-based Matlab Interface On client machine
50
0
50
100
150
200
File-based Without copy time
18
37
53
70
File-based - With
Copy Time
28
57
83
110
Java-based
Matlab Interface On local Machine
43
86
115
163
Java-based
Matlab Interface On client machine
47
108
163
215
Number of files
Figure 5.8: The results of comparing the Java-based Matlab interface against filebased access scripts. This is a worst case scenario, where data from all
dimension tables and the fact table are queried multiple times to create a
proinfo structure. On average, executing the query through the interface
adds an additional 0.4 seconds compared to the running time for the filebased access script. Also, running the interface over a network client adds
approximately 0.2 seconds to the running time (the same as copying the
files to the local hard drive from CD’s).
CHAPTER 5. ANALYSIS
67
the results below capture the worst case scenario for the data warehouse usage.
The results of testing this interface, shown in Figure 5.8, indicates that on average
the Java-based Matlab interface is twice as slow as the file-based access script, in this
worst case scenario. However, in absolute terms, it is adding only an additional 0.4
seconds per file. For most retrievals (100 to 200 files), this amounts to only 40 to
80 additional seconds. Furthermore, in the long run, the interface will be used in an
efficient manner without the need to construct a proinfo like structure. For instance,
the trial data query, outlined in Figure 5.5, is an example of an efficient use of the
data warehouse. So the Java-based interface can be extended to include methods
that can execute SQL queries based on user parameters and return a result matrix
without constructing a proinfo like structure.
5.5
Operational Aspects
This section focuses on two key operational aspects of a data warehouse system:
parsing (or preparing data for upload) and updating or inserting data. In our case,
the operational aspects are simplified because the warehouse is frequently read but
infrequently updated. This means that parsing and upload step is a one-time process
that is done once every few days and would require the system to be in an off-line
mode. This is a standard procedure for a warehouse system.
In order to test for the mean parse time, we used a sample size of 864 .pro files
randomly chosen across all subjects (appendix B outlines the process by which this
sample size is selected). The time taken to parse 864 files was 442,531 milliseconds.
Thus giving a mean parse time of 512 milliseconds or 0.5 seconds per .pro file. The
same 864 files were uploaded to the database in 2,853 seconds (3.3 seconds per .pro
CHAPTER 5. ANALYSIS
68
file). Thus the entire parsing and upload operation takes approximately 4 seconds per
data file. From an operational point of view this is acceptable given that daily data
recordings generate data files in the order of hundreds at most. Thus, daily updates
can be done within 1-2 hours and are automated.
5.6
Emergent Issues
As the analysis above shows, the data warehouse adds efficiency to the scientific process by introducing query support and automating data management tasks. However,
the file-based approach is advantageous in that it is flexible and scalable. The following subsections discuss how the warehouse system measures up with respect to the
issues of schema evolution and scalability.
5.6.1
Schema Evolution
The hybrid approach outlined in Chapter 4 (where the facts are stored in a regular
table and dimensions are stored in object tables), offers extensibility in two ways.
First, because dimensional data is stored in object tables, it is possible to add and
drop attributes without dropping the tables. Secondly, the fact table can also be
expanded in terms of adding new attributes. However, dropping columns requires the
table to be re-created.
In the file based approach we have maximum flexibility in terms of changing or
reorganizing data formats. However, there is a significant cost in terms of propagating
such changes to scripts that load and analyze the data. For instance, a version change
in .pro data file requires changes in the read pro.m script and all data analysis scripts
CHAPTER 5. ANALYSIS
69
that use the read pro.m script.
In terms of flexibility, as noted in Chapter 2 and 4, the raw data format changes
from experiment to experiment. For example, two experiments for the same task
can collect different signals on different days. It is important for such changes to
be absorbed easily without major modifications to the data cleaning scripts or the
warehouse schema. Again, the file based approach gives maximum flexibility, but at
the cost of creating inefficiencies at the analysis level. In the new environment, the
grammar based parsing script absorbs all such variances and outputs files that can be
uploaded to the data warehouse. Furthermore, the parser is easily extended by adding
parsing rules for new input formats. Although at present the actual data upload is
not incorporated into the parser, this could be done in the future by expanding the
rule set such that the parser not only cleans and re-arranges the raw data but also
uploads it to the warehouse. This would allow the parser to reconcile differences
between the raw data and the warehouse schema.
5.6.2
Scalability
In the file based approach, scalability is not an issue and data retrieval is only limited
by the amount of RAM available. Relational data management systems are scalable [19]. Furthermore, indexing frequently retrieved fields, such as foreign keys in
the dimension tables, ensures that query time will be scalable as the data set increases.
However, there are two issues with maintaining elaborate indexes:
1. Storage cost: with a large data set, the amount of storage consumed by the
indexes can be significant. Due to its relative size, the fact table indexes are significantly larger than the dimensional table indexes. However, with the present
CHAPTER 5. ANALYSIS
70
data set we see that fact table indexes amount to 4% (approximately 965 MB)
of the data set size. Even when doubling of the size of the data set, the index
will need a maximum of 1.9 GB of memory.
2. Update cost: Index maintenance becomes an issue with large uploads of data.
However the testing reported in the previous section shows that insert time is
acceptable and thus index maintenance is not an issue.
Furthermore, mature relational database system, such as DB2, have efficient index
storage and maintenance mechanisms such as storing indexes in B+ trees [19]. Thus
storage and maintenance cost of indexes will not be an issue.
5.7
Summary
Table 5.1 summarizes this chapter in terms of the key requirements identified in
Chapter 4. From the discussion above, we can assert that the data warehouse not
only offers a viable option for managing scientific behavioral data, but also adds value
to the scientific research process. The added value is derived from:
1. Enabling faster and easier access to research data.
2. Automating data management and analysis tasks.
3. Providing shared and concurrent access to research data.
4. Potentially aiding future data mining efforts.
5. Allowing researchers to spend more time on their core scientific activities, due
to the efficiencies above, as opposed to writing code.
71
CHAPTER 5. ANALYSIS
Requirement
File-based
Database managed
Formal query Support
No support, either in terms of
metadata or trial data queries.
Full support for both data management
queries and trial data extraction. This includes ability to filter data based on signals or time epochs (horizontal and vertical slicing of data).
Data management
No automated way of executing
data management tasks such as
backups, recovery, and ensuring
consistency. Also, data source
does not allow concurrent access.
Data management tasks now automated
and done by the database system. Furthermore, the data warehouse allows concurrent access to data and thus eliminates
redundancy.
Analysis
Since data is stored in ASCII
format, it is easily readable by
analysis software such as Matlab. However, lack of query tools
makes it hard to identify data of
interest and also makes data analysis resource intensive.
SQL queries allow easy access to data.
Furthermore, built-in functions within
SQL and the ability to define functions
and procedures adds efficiency to the process. Finally, the custom Matlab interface
allows data to be queried from within the
analysis platform.
Warehouse Operations
Data is stored on CD’s with a redundant copy stored outside the
lab. These CD’s were managed
by the lab administrator. This
is a simple storage scheme, however data management is cumbersome.
Experimental data is parsed by a Perlbased grammar and uploaded to the
database by built-in DB2 functions. This
process takes about 0.5 seconds per data
file. Data is stored on the database server
and is backed up to a tape device on a
regular basis. This process is automated
and managed by the DBMS
Schema Evolution
Maximum flexibility in terms of
changing the data structure, however, hard to propagate changes
to data extraction and analysis
scripts.
The warehouse implementation allows
maximum flexibility in the dimension tables in terms of adding and dropping attributes. In the fact table, adding signals
is possible, but dropping tables requires
the entire table to be recreated.
Scalability
The only limiting factor in terms
of scalability is the amount of
random access memory available
for program execution.
Since key attributes in the fact table and
dimension tables are indexed, query performance should not deteriorate with increased data volumes.
Table 5.1: A summary of the discussion analyzing the new database managed environment against the file managed environment
Chapter 6
Conclusion And Future Works
This chapter concludes the discussion presented so far. The goal of this chapter
is to summarize our discussion, draw out generalize lessons and solutions from the
implementation, and outline future research in the area.
6.1
Thesis Summary
As outlined in Chapter 1, the goal of this thesis is to develop an effective and efficient
data management and analysis system for scientific behavioral data. Specifically, we
propose a data warehousing model for this task. To accomplish this goal, we developed
a proof-of-concept system for Dr. Scott’s research lab that conducts behavioral studies
on limb motor control. As mentioned in Chapter 3, we use the evaluation criteria
outlined by Burstein and Gregor as internal benchmarks for evaluating our work.
Figure 6.1 describes these criteria in detail, and maps them to the current research.
In Summary, this research has made the following contributions:
1. Through a proof-of-concept system, we demonstrated the viability of using a
72
CHAPTER 6. CONCLUSION AND FUTURE WORKS
Burstein’s criteria
Current proposal
Significance:
The significance of the study is more practical
than theoretical. It will contribute towards establishing the viability of using a data warehouse
system based on an object-relational platform in
managing scientific behavioral data. It also contributes to the actual scientific research by delivering a more efficient data storage, retrieval, and
analysis tool.
• Is the study significant theoretically?
• Is the study significant practically?
Internal Validity: refers to the credibility of the
arguments made:
• Does the system work? Does it meet its
stated objectives and requirements?
• Were predictions made in the study
about the system?
73
Although some requirements are inherently subjective, overall the system does meet the requirements outlined in Chapter 4. Different
systems (object-oriented, relational, and objectrelational) have been considered. Also, rival implementation designs have been considered and
evaluated throughout the development process.
• Have rival systems been considered?
External Validity:
1. Are the findings congruent with, connected to, or confirmatory to prior theory?
2. Is the system generic enough to be applied to other settings?
3. Is the transferable theory from the study
made explicit?
Objectivity/Confirmability
• Are the study’s method and procedure
described explicitly and in detail?
While there is no one-size-fits-all theory for managing scientific data, it is generally accepted that
an object-oriented model is more appropriate due
to the complexity of data and the need for a flexible schema. This study demonstrates the viability of using a warehouse system, based on an
object-relational platform, for managing scientific
data. The generality of this study, in terms of directly mapping our system to another problem,
is limited by the fact that scientific applications
have unique data sets and requirements. However, the study is generalizable in terms of the
design principles that can be applied to other
problems in the area. These are discussed in this
chapter.
An appropriate research methodology has been
carefully selected and is outlined in this chapter.
The actual system and the experimentation on
the system is described in Chapter 4 and 5 respectively.
• Can we follow the procedure of how data
was collected?
Reliability/dependability/Auditability:
• Are the research questions clear?
• Are the basic constructs clearly specified?
The research goal as stated previously, is to develop a data management and analysis model
that can store, query, and analyze scientific data
efficiently. Specifically, we propose a data warehouse system based on object-relational DBMS
technology. The constructs in this case would be
the theoretical data models on which this system
is based. These have been described and contrasted in Chapter 3.
Table 6.1: Research evaluation criteria. The left column shows the evaluation criteria
suggested by Burstein, et al [8]. The right column shows how the current
research measures up to these criteria.
CHAPTER 6. CONCLUSION AND FUTURE WORKS
74
data warehouse system, based on an object-relational database platform, to
manage and analyze scientific behavioral data. In doing so, we identified and
articulated key data management and analysis problems faced by researchers
using the KINARM paradigm. These challenges are translated into system
requirements that could be generalized for other behavioral labs. Furthermore,
we deliver a working data management system to behavioral scientists, and
show added value in using this system.
2. We also identify key limitations (outlined in the section below) of the warehouse
system and our proposed solutions. These limitations serve as generalizable
lessons and solutions for future and/or further development of a warehouse
system for behavioral data.
6.2
6.2.1
Key Limitations And Possible Solutions
Arrays To Store Signals
One key limitation of the current data warehouse implementation is that we distribute
temporal data over different rows in the fact table. A better design for storing the
signal data would be to use an array within a column or an object. Figure 6.1
demonstrates how the array structure could be used in the fact table. The use of
array structures within the relational framework would simplify both the fact table
design and the end-user queries. Furthermore, it would allow us to define a coarser
granularity at the relational level (each row contains data related to the entire trial),
while retaining the ability to slice within the trial for specific subsets of data. For
example, Figure 6.2, gives a sample query for the schema shown in Figure 6.1. The
75
CHAPTER 6. CONCLUSION AND FUTURE WORKS
Fact table - current design
...
Time
5
10
15
…
5
10
15
Signal1
0
0
1
...
1
1
0
Signal2
1.5
5
3
...
3
4
3
Trial
T1
T1
T1
...
T2
T2
T2
...
Fact table - with array type in columns
...
Signal1
[0,0,1]
[1,1,0]
Signal2
[1.5,5,3]
[3,4,3]
Trial
T1
T2
...
Figure 6.1: Illustrates how an array-based structure can be used to store behavioral
data signals.
slicing within the trial is based on the signal array index, and not the actual instant
in time of the movement. However, the conversion between an array index and the
corresponding trial time instant is trivial via the sampling rate of the trial (array
index * 1/sampling rate (Hz) = trial time instant).
Although the array data type is part of the SQL3
1
specification, the basic DB2
implementation does not support it. From our experience, it is recommended to
use arrays to encapsulate data from the entire signal. The open source PostgreSQL
1
The extension of the original SQL specification to incorporate object-oriented features in relational systems [19]
CHAPTER 6. CONCLUSION AND FUTURE WORKS
76
SELECT Signal1[1:20], Signal2[21:40] from fact_table WHERE trial =
‘T1’ and ...
Figure 6.2: Sample query to illustrate how an array-based fact table (See Figure 6.1)
could be queried. In this query, the first 20 data points from signal1, and
the next 20 data points from signal2 are retrieved.
data management system supports the array type [38]. Also, extensions for the DB2
system that support such structures are commercially available [26]. Either one of
these technologies should be considered for future implementations.
6.2.2
Source Data Upload
A key implementation challenge in this work was transforming source data that was
file-based and uploading it to the data warehouse system. As outlined in Chapters
2 and 4, there are a lot of variations in the source data from one experiment to
another. Furthermore, the data files were not tagged by a metadata language such as
XML. Combined with large data volumes, the task of uploading historical data to the
warehouse system becomes formidable. This is the likely scenario in other behavioral
laboratories.
Although the grammar based parsing approach addresses this problem partly, to
be truly effective, it has to be integrated with the step that uploads data to the warehouse system. For example, at present, each variation in the source file results into a
separate DB2 load/import script for the upload. Thus, future developments need to
integrate the data parsing and upload step. In fact, the parser could be extended to
propagate changes in the source data to the warehouse schema automatically. This
would be a critical step in extending this model to other behavioral labs.
CHAPTER 6. CONCLUSION AND FUTURE WORKS
6.3
77
Future Work
The section above not only identifies key limitations of the current implementation,
but also points to potential future work. In addition to that, we identify the following
key areas for future development, specifically for the warehouse system developed for
Dr. Scott’s lab:
1. Developing a library of functions and procedures for common analytical tasks.
These functions, ideally, should be coded and stored within the database system.
As mentioned in Chapter 5, there are numerous benefits in developing such
database managed procedures, including reducing data transfers across the local
area network, and transferring computationally intensive tasks to a powerful
server machine.
2. Development of front-end data analysis and visualization tools. The current
implementation provides a basic front-end tool, however, it can be enhanced
further for novice end-users. This involves developing a graphical user interface
that not only enables users to query the data, but also to execute analytical
tasks based on pre-coded stored procedures and functions discussed above. For
example, a researcher could choose appropriate data selection criteria such as
task, cell, subject, etc., and then ask a question such as “what is the mean
discharge rate, and the preferred direction for the cell”. This would be translated into a parameterized user-defined procedure that queries the database and
performs the required analysis.
3. As outlined in previous chapters, a data warehouse system could speed up the
data mining processes by providing a structured data source that could be
CHAPTER 6. CONCLUSION AND FUTURE WORKS
78
efficiently queried. This is especially true with data such as Dr. Scott’s, which
is voluminous and complex, and requires temporal analysis. Having created a
well structured data source, future developments should look into building a
data mining module as part of the warehouse system. Again, functionalities
such as database managed procedures and functions are useful in developing
such tools.
4. The data warehouse could also be extended to incorporate the raw experimental data so that a researcher can go between a raw data signal and a
filtered/processed data signal. In our implementation, we have incorporated
processed data, however, the raw data is not warehouse managed.
5. Finally, the data warehouse system could be extended such that experimental
data could be cross-linked to relevant publications, student analysis, and other
documentation. This would extend the functionality of the system so that it
serves as both a data source as well as a knowledge base for the lab.
6.4
Summary
In this thesis, we have demonstrated that data warehousing is a viable model for efficient storage and analysis of scientific behavioral data. We have also demonstrated
how object-relational systems could be used to manage complex scientific data. Furthermore, we have shown the added value of such an approach to the scientific research
process in terms of the efficiencies introduced through the warehouse system. Finally,
through the system development process, we identify limitations of the current design
and generalizable solutions for future development.
Bibliography
[1] K. Aberer. The use of object-oriented data models in biomolecular databases.
In Conf.on Object-Oriented Computing in the Natural Sciences, Heidelberg, Germany, 1994.
[2] M. G. Axel and I. Song. Data warehouse design for pharmaceutical drug discovery
research. In 8th International Conference and Workshop on Database and Expert
Systems Application (DEXA) Workshop, pages 644–650, 1997.
[3] G. Baklarz and B. Wong. DB2 Universal Database v7.1, Database Administration
Certification Guide, chapter 7, page 363. Prentice Hall PTR, 4th edition, 2001.
[4] F. Bancilhon. Object-oriented database systems. In Proceedings of the seventh ACM SIGACT-SIGMOD-SIGART symposium on Principles of database
systems, pages 152–162. ACM Press, 1988.
[5] F. Bancilhon. The o2 object-oriented database system.
21(2):pages 7–7, 1992.
SIGMOD Rec.,
[6] A. Baruffolo and L. Benacchio. Object-relational DBMSs for large astronomical
catalogue management. In Proc. Astronomical Data Analysis Software Systems
conference series, volume 145 of 7, pages 382–385, 1998.
[7] V. R. Basili, R. W. Selby, and D. H. Hutchens. Experimenting in software
engineering. IEEE Transactions on Software Engineering, 12(7):733–743, July
1986.
[8] F. Burstein and S. Gregor. The system development or engineering approach to
research in information systems: An action research perspective. In Proc.10th
Australasian Conference on Information Systems, 1999.
[9] P. Cabena, P. Hadjinian, R. Stadler, J. Verhees, and A. Zanasi. Discovering data
mining: from concept to implementation. Prentice-Hall, Inc., 1998.
[10] R. Cattell. Experience with the odmg standard. StandardView, 3(3):90–95, 1995.
79
BIBLIOGRAPHY
80
[11] Y. Chi, C.R. Mechoso, M. Stonebraker, K. Sklower, R. Troy, R.R. Muntz, and
E. Mesrobian. Esmdis: Earth system model data information system. In Yannis E. Ioannidis and David M. Hansen, editors, Ninth International Conference on Scientific and Statistical Database Management, Proceedings, August
11-13, 1997, Olympia, Washington, USA, pages 116–118. IEEE Computer Society, 1997.
[12] E.F. Codd. A relational model of data for large shared data banks. Communications of the ACM, 13(6):377–387, 1970.
[13] D. Conway. Parse::recdescent - generate recursive-descent parsers. Web, April
2003. http://search.cpan.org/∼dconway/. Current as of April 14, 2004.
[14] Microsoft Corporation. Microsoft sql server. http://www.microsoft.com/sql/
default.asp. Current as of 23 April, 2004.
[15] Nation Instruments Corporation. Labview homepage. Web. http://www.ni.
com/labview/. Current as of April 14, 2004.
[16] Oracle Corporation. Oracle database. http://www.oracle.com/database/.
Current as of 23 April, 2004.
[17] T. Critchlow, G. Madhavan, and R. Musick. Automatic generation of warehouse mediators using an ontology engine. In Proceedings of the 5th Knoweledge
Representation meets Databases (KRDB) Workshop, pages 8.1–8.8, May 1998.
[18] W. Dubitzky, O. Krebs, and R. Eils. Minding, olaping, and mining biological
data: Towards a data warehousing concept in biology. In Proc. Network Tools
and Applications in Biology (NETTAB), CORBA and XML: Towards a Bioinformatics Integrated Network Environment, pages 77–82, Genoa, Italy, 2001.
[19] R. Elmasri and S. B. Navathe. Fundamentals of Database Systems. AddisonWesley, 3rd edition, 2000.
[20] J. Fredriksson, P. Roland, and P. Svensson. Rationale and design of the european computerized human brain database system. In Proc. Eleventh International Conference on Scientific and Statistical Database Management, volume
Aug 1999, pages 148–157.
[21] P. Gray and C. Israel. The data warehouse industry. Web, February 1999. http:
//www.crito.uci.edu/itr/publications/pdf/data warehouse.pdf. Current
as of 14 April, 2004.
BIBLIOGRAPHY
81
[22] P. Gray and H. J. Watson. Present and future directions in data warehousing.
SIGMIS Database, 29(3):83–90, 1998.
[23] R. Grossman, X. Qin, D. Valsamis, and W. Xu. Analyzing high energy physics
data using databases: A case study. In Proc. Seventh International Conference
on Scientific and Statistical Database Management, pages 283–286, 1994.
[24] K.K. Hirji. Exploring data mining implementation. Communications of the
ACM, 44(7):87–93, 2001.
[25] International Business Machines (IBM). Db2 product family. http://www-306.
ibm.com/software/data/db2/. Current as of 23 April, 2004.
[26] International Business Machines (IBM). Informix timeseries datablade module.
http://www-306.ibm.com/software/data/informix/blades/timeseries/.
Current as of 23 April, 2004.
[27] MathWorks Inc. MATLAB, The Language of Technical Computing. MathWorks
Inc, 3 Apple Hill Drive, Natickm MA 01760-2098, 6th edition, August 2002.
[28] W. H. Inmon. Building the Data Warehouse. Wiley Computer Publishing, 2nd
ed edition, 1996.
[29] International Business Machines (IBM) Corporation. SQL Reference Guide.
Web. http://webdocs.caspur.it/ibm/web/udb-6.1/db2s0/index.htm. Current as of 14 April, 2004.
[30] R. R. Johnson. Elementary Statistics. PWS-KENT Publishing Company, 6th
edition, 1992.
[31] R. Kimball, L. Reeves, M. Ross, and W. Thornthwaite. The Data Warehouse
Lifecycle Toolkit. John Wiley & Sons, Inc., 1998.
[32] M. Krippendorf and I. Song. The translation of star schema into entityrelationship diagrams. In 8th International Conference and Workshop on
Database and Expert Systems Application (DEXA) Workshop, pages 390–395,
1997.
[33] D. Maier and D. M. Hansen. Bambi meets godzilla: Object databases for scientific computing. In Proc. Seventh International Conference on Scientific and
Statistical Database Management, pages 176–184, 1994.
[34] S. McClure. Object database vs. object-relational databases. Web, August 1997.
http://www.ca.com/products/jasmine/analyst/idc/14821E.
htm#BKMTOC22. Current as of 14 April, 2004.
BIBLIOGRAPHY
82
[35] J.F. Nunamaker, M. Chen, and T.D.M. Purdin. System development in information systems research. Journal of Management Information Systems, 7(3):89–
106, Winter 1990-1991.
[36] T. Pedersen. Aspects of Data Modelling and Query Processing For Complex
Multidimensional Data. PhD thesis, Faculty of Engineering and Science, Aalborg
University, Denmark, 2000.
[37] Plexon Inc.
User’s Guide, Version 2.0, Data Recording Software,
Plexon Recorder.
Web, June 2003.
http://www.plexoninc.com/pdf/
RecorderV2Manual.pdf. Current as of April 14, 2004.
[38] The PostgreSQL Global Development Group. PostgreSQL 7.4.2 Documentation.
http://www.postgresql.org/docs/7.4/static/index.html. Current as of 23
April, 2004.
[39] A. Rauf and S.M. Shah-Nawaz. An integrated database system at the national
level for water resource engineers and planners of bangladesh. In Proc. 12th. International Conference on Scientific and Statistical Database Management, pages
247–249, 1997.
[40] R. Rew, G. Davis, S. Emmerson, and H. Davies. Netcdf user’s guide for c.
Web, June 1997. http://www.unidata.ucar.edu/packages/netcdf/cguide.
pdf. Current as of April 14, 2004.
[41] S. H. Scott, P. Cisek, S. Dorrepaal, J. Swaine, and S. Kong. Brainstorm - Technical Document Version 1. Laboratory of Dr. Steven Scott, Queen’s University,
Dept. of Anatomy and Cell Biology, Botterell Hall, Rm. 459.
[42] S.H. Scott. Role of motor cortex in coordinating multi-joint movements: Is it
time for a new paradigm? Canadian Journal of Physiology and Pharmacology,
78:923–933, 2000.
[43] S.H. Scott. Neural activity in Primary Motor Cortex Related to Mechanical
Loads Applied to the Shoulder and Elbow During a Postural Task. The American
Physiological Society, June 2001.
[44] J. P. Shim, M. Warkentin, J. F. Courtney, D. J. Power, R. Sharda, and C. Carlsson.
[45] M. Stiber, G.A. Jacobs, and D. Swanberg. Logos: a computational framework for
neuroinformatics research. In Proc. Ninth International Conference on Scientific
and Statistical Database Management, volume 11-13, pages 212–222, 1997.
BIBLIOGRAPHY
83
[46] R. Weber. Toward a theory of artifacts: A paradigmatic base for information
systems research. Journal of Information Systems, 1, Issue 2:3–17, Spring 1987.
[47] R. Williams, P. Messina, F. Gagliardi, J. Darlington, and G. Aloisio. European
union united states joint workshop on large scientific databases. Web, 1999.
www.cacr.caltech.edu/euus. Current as of April 14th 2004.
[48] H. Wu, B. Norum, J. Newmark, B. Salzberg, C.M. Warner, C. DiMarzio, and
D. Kaeli. The censsis image database. In 15th International Conference on
Scientific and Statistical Database Management, Proceedings, 9-11 July, 2003,
pages 117–126. IEEE Computer Society, 2003.
Appendix A
Matlab Scripts
A.1
Metadata query 1
function MTstart = extract_MTstart(limit, options)
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
EXTRACT_MTSTART
This function will collect data from ’limit’ number of files
(where limit is an integer parameter inputted by the user), and extract the
MTstart values for all trials in one direction for all files.
The user can also specify the task and the monkeys to be used.
Parameters:
1.
2.
limit - The number of files to get.
options - A cell array of options.
a) ’task’ - A character representing the task to be examined
(optional - ’a’ is default).
b) ’monkeys’ - A cell string array representing the monkeys to
be considered (optional - ’use all’ is default).
Author:
Title:
Dept:
Date:
Jon Swaine
Computer Programmer
Department of Cell Biology and Anatomy
March 15, 2004
Written for use in Stephen Scott’s Data Analysis laboratory in
Botterell Hall, Queen’s University, Kingston, Ontario, Canada.
% Intialize variables
pro_files = []; file_counter = 0;
% Default task is ’a’, unloaded reaching
task = ’a’;
% Default is to run all of the monkeys.
monkeys = {’A’ ’B’ ’C’ ’D’};
% Check the options parameter to see what parameters have been included
if nargin == 2
for x = 1:length(options)
% If the user does not specify the task, then the default is unloaded
% reaching (the ’a’ task).
84
APPENDIX A. MATLAB SCRIPTS
if strcmp(options{x}{1}, ’task’)
task = options{x}{2};
% If the user doesn’t specify the subject(s), analyze all of them (’A’,
% ’B’, ’C’, and ’D’)
elseif strcmp(options{x}{1}, ’monkeys’)
monkeys = options{x}{2};
end
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% GET THE FILES NEEDED FOR COMPARISON
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for x = 1:length(monkeys)
% The directory containing the folders with cell data.
input_dir = [’c:\data\PVector_Data\Monkey’, monkeys{x}, ’\’];
% Enter directory where folders are located
eval([’cd ’, input_dir]);
% Collect all files in temporary variable
temp = dir;
% Collect only the names of the files (folders) in a cell array
folders = {temp.name};
clear temp;
% Go through the names, looking for folders that have the word ’cell’ in them
for y = 1:length(folders);
% If the name has ’cell’ in it, assume it’s a folder containing
% cell data
if ~isempty(findstr(’cell’, folders{y}))
% Enter the folder
eval([’cd ’, input_dir, folders{y}]);
% Collect all of the files and then extract the names to a
% variable called ’files’
temp2 = dir;
files = {temp2.name};
clear temp2;
% Go through the file names and replace the 5th character with a ’1’,
% indicating that we only want data for target 1.
for z = 1:length(files)
files{z}(5) = ’1’;
end
% Get rid of any duplicate file names.
unique_files = unique(files);
clear files;
% Go through each unique file name and ...
for z = 1:length(unique_files)
% ... if the file name has a ’.pro’ extension and if the task
% matches the one we’re looking for, add the filename to
% the list of files to be analyzed.
if unique_files{z}(2) == task & strcmp(unique_files{z}(9:12), ’.pro’)
file_counter = file_counter + 1;
pro_files{file_counter} = unique_files{z};
break;
end
% If we have collected ’limit’ number of files, then stop
% collecting files
if file_counter == limit
break;
end
end
clear unique_files;
85
APPENDIX A. MATLAB SCRIPTS
end
% If we have collected ’limit’ number of files, then stop
% collecting files
if file_counter == limit
break;
end
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% END - GET THE FILES NEEDED FOR COMPARISON
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Go through the pro files to be analyzed, read the pro file into a
% struct and get the MTstart value.
for x = 1:length(pro_files)
% Enter proper directory
input_dir = [’c:\data\PVector_Data\Monkey’, upper(pro_files{x}(1)), ’\’];
eval([’cd ’, input_dir, ’cell’, pro_files{x}(6:8)]);
% Read the pro file into a structure
pro = read_pro(pro_files{x});
% Look in the features field and extract the MTstart value (at index 3)
% for each trial.
for y = 1:size(pro.features, 2)
MTstart(x, y) = str2num(pro.features(3, y).value);
% Report error if 0 value found
if ~MTstart(x,y)
disp(’Zero value detected.’);
end
end
end
A.2
Metadata query 2
function a_pre_b_list = find_files_with_tasks_a_and_b(limit,
options)
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
FIND_FILES_WITH_TASKS_A_AND_B
This function will find ’limit’ number of cells (where limit
is an integer parameter inputted by the user), where there is
data for both the ’a’ and the ’b’ task.
Parameters:
1.
2.
limit - The number of files to get.
options - A cell array of options.
a) ’task’ - A character representing the task to be examined
(optional - ’a’ is default).
b) ’monkeys’ - A cell string array representing the monkeys to
be considered (optional - ’use all’ is default).
Author:
Title:
Dept:
Date:
Jon Swaine
Computer Programmer
Department of Cell Biology and Anatomy
March 15, 2004
Written for use in Stephen Scott’s Data Analysis laboratory in
86
APPENDIX A. MATLAB SCRIPTS
%
Botterell Hall, Queen’s University, Kingston, Ontario, Canada.
b_pro_files = [];
% Default value for tasks is ’a’ and ’b’
tasks = {’a’, ’b’};
% Default value for monkey is C
monkeys = {’C’};
% Check the options parameter to see what parameters have been included
if nargin == 2
for x = 1:length(options)
% If the user doesn’t specify the subject(s), analyze monkey C
if strcmp(options{x}{1}, ’monkeys’)
monkeys = options{x}{2};
end
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% GET THE FILES NEEDED FOR COMPARISON
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
file_counter = 0; for x = 1:length(monkeys)
% Enter the proper directory
input_dir = [’c:\data\PVector_Data\Monkey’ upper(monkeys{x}), ’\’];
eval([’cd ’, input_dir]);
% Save all files within the folder (should be more folders) in a
% temporary variable
temp = dir;
folders = {temp.name};
clear temp;
% Go through the folders and when you find that the folder contains
% cell data, see what’s in it
for y = 1:length(folders)
% Is it cell?
if ~isempty(findstr(’cell’, folders{y}))
% Enter directory
eval([’cd ’, input_dir, folders{y}]);
temp = dir;
% Collect names
files = {temp.name};
clear temp;
% Go through the files and if you find any with a ’b’ for task
% and a ’.pro’ extension, add the filename to a list.
for z = 3 : length(files)
if files{z}(2) == ’b’ & files{z}(9:12) == ’.pro’
file_counter = file_counter + 1;
b_pro_files{file_counter} = files{z};
% Once enough files have been collected, exit the ’for z’ loop
if file_counter == limit
break;
end
end
end
clear files;
end
% Once enough files have been collected, exit the ’for y’ loop
if file_counter == limit
break;
end
end
% Once enough files have been collected, exit the ’for x’ loop
87
APPENDIX A. MATLAB SCRIPTS
if file_counter == limit
break;
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% END - GET THE FILES NEEDED FOR COMPARISON
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
counter = 1;
% Go through and read the b and a data. Then compare the timestamps on
% them to see if ’a’ was collected before ’b’.
for x = 1:length(b_pro_files)
input_dir = [’c:\data\PVector_Data\Monkey’ upper(b_pro_files{x}(1)), ’\’];
eval([’cd ’, input_dir, ’cell’, b_pro_files{x}(6:8)]);
% Read the ’b’ file
b_pro = read_pro(b_pro_files{x});
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Read the corresponding ’a’ file
% Construct the corresponding ’a’ file name.
a_file = [b_pro_files{x}(1), ’a’, b_pro_files{x}(3:12)];
% If the set number for the ’b’ file is 2 and there is no ’a2’ file,
% Check to see if there is an ’a1’ file instead.
if isempty(dir(a_file)) & b_pro_files{x}(3) == ’2’
a_file = [b_pro_files{x}(1), ’a1’, b_pro_files{x}(4:12)];
% If the set number for the ’b’ file is 1 and there is no ’a1’ file,
% Check to see if there is an ’a2’ file instead.
elseif isempty(dir(a_file)) & b_pro_files{x}(3) == ’1’
a_file = [b_pro_files{x}(1), ’a2’, b_pro_files{x}(4:12)];
% If there is still no ’a’ file, continue with the for loop
elseif isempty(dir(a_file))
disp(’No ’’a’’ file available.’);
continue;
end
% Read the ’a’ file into a_pro
a_pro = read_pro(a_file);
% End reading of a_file
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% If ’a’ was recorded before ’b’, add the filename to the list.
% Check dates first, and if they are the same, then check the
% times.
% If the ’a’ date is found to be earlier than the ’b’ date
if datenum(a_pro.date) < datenum(b_pro.date)
% Add to list
a_pre_b_list{counter} = b_pro_files{x};
% Increase counter
counter = counter + 1;
% If the dates are the same ...
elseif datenum(a_pro.date) == datenum(b_pro.date)
% ... see if the ’a’ time is prior to the ’b’ time
if datenum(a_pro.time) < datenum(b_pro.time)
88
APPENDIX A. MATLAB SCRIPTS
% Add to list
a_pre_b_list{counter} = b_pro_files{x};
% Increase counter
counter = counter + 1;
end
end
end
% Display some results
disp([’Number of files collected with a and b tasks - ’
num2str(length(b_pro_files))]); disp([’Number of files where a was
collected prior to b - ’ num2str(length(a_pre_b_list))]);
A.3
Trial data query
function cell_spike_rate =
find_cell_spike_rate_between_RT_MT(limit, task, monkeys)
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
FIND_CELL_SPIKE_RATE_BETWEEN_RT_MT
This function will collect data from ’limit’ number of files
(where limit is an integer parameter inputted by the user), and extract the
MTstart and RTstart values. It will then find the total number of cell
spikes between those two times and calculate the cell spike firing rate.
Parameters:
1.
2.
limit - The number of files to get.
options - A cell array of options.
a) ’task’ - A character representing the task to be examined
(optional - ’a’ is default).
b) ’monkeys’ - A cell string array representing the monkeys to
be considered (optional - ’use all’ is default).
Author:
Title:
Dept:
Date:
Jon Swaine
Computer Programmer
Department of Cell Biology and Anatomy
March 15, 2004
Written for use in Stephen Scott’s Data Analysis laboratory in
Botterell Hall, Queen’s University, Kingston, Ontario, Canada.
% Intialize variables
pro_files = []; file_counter = 0; task = ’a’; monkeys = {’A’ ’B’
’C’ ’D’}; sampling_rate = 200;
% Check the options parameter to see what parameters have been included
if nargin == 2
for x = 1:length(options)
% If the user does not specify the task, then the default is unloaded
% reaching (the ’a’ task).
if strcmp(options{x}{1}, ’task’)
task = options{x}{2};
% If the user doesn’t specify the subject(s), analyze all of them (’A’,
% ’B’, ’C’, and ’D’)
elseif strcmp(options{x}{1}, ’monkeys’)
monkeys = options{x}{2};
end
89
APPENDIX A. MATLAB SCRIPTS
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% GET THE FILES NEEDED FOR COMPARISON
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for x = 1:length(monkeys)
% The directory containing the folders with cell data.
input_dir = [’c:\data\PVector_Data\Monkey’, monkeys{x}, ’\’];
% Enter directory where folders are located
eval([’cd ’, input_dir]);
% Collect all files in temporary variable
temp = dir;
% Collect only the names of the files (folders) in a cell array
folders = {temp.name};
clear temp;
% Go through the names, looking for folders that have the word ’cell’ in them
for y = 1:length(folders);
% If the name has ’cell’ in it, assume it’s a folder containing
% cell data
if ~isempty(findstr(’cell’, folders{y}))
% Enter the folder
eval([’cd ’, input_dir, folders{y}]);
% Collect all of the files and then extract the names to a
% variable called ’files’
temp2 = dir;
files = {temp2.name};
clear temp2;
% Go through the file names and replace the 5th character with a ’1’,
% indicating that we only want data for target 1.
for z = 1:length(files)
files{z}(5) = ’1’;
end
% Get rid of any duplicate file names.
unique_files = unique(files);
clear files;
% Go through each unique file name and ...
for z = 1:length(unique_files)
% ... if the file name has a ’.pro’ extension and if the task
% matches the one we’re looking for, add the filename to
% the list of files to be analyzed.
if unique_files{z}(2) == task & strcmp(unique_files{z}(9:12), ’.pro’)
file_counter = file_counter + 1;
pro_files{file_counter} = unique_files{z};
break;
end
% If we have collected ’limit’ number of files, then stop
% collecting files
if file_counter == limit
break;
end
end
clear unique_files;
end
% If we have collected ’limit’ number of files, then stop
% collecting files
if file_counter == limit
break;
end
end
90
APPENDIX A. MATLAB SCRIPTS
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% END - GET THE FILES NEEDED FOR COMPARISON
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Steps:
%
For all selected files
%
1. Generate the pro structure from the pro file
%
2. Find RT and MT start.
%
3. Then find the number of spikes between the times at
%
which RT and MT start occur.
%
4. Calculate the rate of cell spike firing.
for x = 1:length(pro_files)
% Go into proper directory
input_dir = [’c:\data\PVector_Data\Monkey’, upper(pro_files{x}(1)), ’\’];
eval([’cd ’, input_dir, ’cell’, pro_files{x}(6:8)]);
% Read pro file
pro = read_pro(pro_files{x});
for y = 1:size(pro.features, 2)
% Get RTstart (index 1) and MTstart (index 3)
RTstart = str2num(pro.features(1, y).value);
MTstart = str2num(pro.features(3, y).value);
% Get RT and MT indices from the time column (column 1)
RTind = min(find(RTstart <= pro.data{y}(:, 1)));
MTind = min(find(MTstart <= pro.data{y}(:, 1)));
% Get cell spikes between those indices (column 8 is cell spike
% column)
cellspikes = sum(pro.data{y}(RTind : MTind, 8));
% Calculate the rate
cell_spike_rate(x, y) = cellspikes / ((MTind - RTind) * (1 / sampling_rate));
end
end
91
Appendix B
Statistical Formulae
In Chapter 5, we used a sample of 864 .pro files to determine the mean data parse and
upload time. The central limit theorem equation outlined below (equation B.1) was
used to determine this sample size [30]. The equation allows us to make a statistical
inference on the sample size necessary to determine mean parse time and data upload
time for .pro files.
We assume that the size of the .pro file is proportional to the number of data
points in the file, which is proportional to the time it takes to parse/upload the file.
Thus we estimate the sample size necessary to determine the mean size of a .pro file
at 95% confidence ((1 - α) in the equation) and with error of estimate of 10KB (E in
the equation). We then use a sample size to determine the mean parse/upload time.
One problem with this analysis is estimating the population standard deviation in
file sizes. In this case, the population consists of over 20,000 files scattered across 200
CD’s. This makes it hard to find the population statistics, and thus a large random
sample is used to estimate the population standard deviation.
92
APPENDIX B. STATISTICAL FORMULAE
z( α2 ) ∗ SD 2
)
n=(
E
93
(B.1)
SD = Standard Deviation = 150KB. The standard deviation in .pro file sizes is determined from a sample of 4750 files.
E = Maximum error of estimate = 10KB
α = 0.005. Confidence level of 95%, thus α = (1 - 0.005).
z( α2 ) = 1.96. This value was determined from a statistical table showing z values for
areas of the standard normal distribution.
Appendix C
A sample .pro file
94
APPENDIX C. A SAMPLE .PRO FILE
Monkey Arm
HemisphereMass ArmLen ForearmLenChamber PenNum PenX PenY Rate Mot1 Mot2 Date Time Proto
sthapatya RIGHT LEFT
9.2
154
230
1
26
-5
-2
200
1
1 8/29/2003 10:32 AM b1
ver1.0
STATE CONDITIONS
State LightOn LightOff TarPos Motor PosLim TimeLim TimeVar
1
0
0
0
0
7 2000
0
2
0
1
0
0
8 1250
250
2
1
0
0
0
8
150
0
3
1
0
0
0
8
750
0
4
1
0
1
0
13
200
0
1
1
0
1
0
13
200
0
2
1
1
1
0
13 1250
250
0
-1
0
1
0
0
0
0
CHANNEL CONFIG
Channel Time HandXPos HandYPos ShoAng ElbAng ShoVel ElbVel Cell1 HandXAcc HandYAcc ShoTor ElbTor ShoAcc ElbAcc Mot1Tor Mot2Tor TanAcc TanVel
Min
4.5 11.1533 279.69 0.518 1.282 -0.544778 -0.759
0 -0.136418 -1.25166 0.033736 0.129944 -8.07119 -16.7932 -0.015945 -0.008763 0.000734 8.38E-06
Max
4729.25 75.877 303.756 0.626 1.542 0.325 0.318
2 0.178256 -1.03677 0.079059 0.17446 12.4825 12.8872 0.012368 0.024688 1.94156 0.25464
Filter (none) (none) (none) (none) (none) butter6-0.05butter6-0.05(none) butter6-0.05butter6-0.05butter6-0.05butter6-0.05(none) (none) (none) (none) (none) (none)
FILE PRODUCTION INFO
Source files:db1x0157.sam
TRIAL HEADER
TargetNumStartXPos StartYPos TarXPos TarYPos Scans
0
18
286
73
309
712
STATE TRANSITIONS
4.75
259 1761.25 1912.5 2234.25 2435.75 2567.75 3818.25
TRIAL FEATURES
Feature Method Value
RTstart State
1761.25
MTstart TanAcc 2044.75
MTstart State
2234.25
THTstart State
2567.75
RTdur TanAcc
283.5
MTdur TanAcc
523
Time HandXPos HandYPos ShoAng ElbAng ShoVel ElbVel Cell1
259.75 11.1533 286.279 0.604 1.49367 0.217548 -0.436975
264.75 11.244 286.477 0.6044 1.4922 0.204091 -0.408788
269.75 11.381 286.774 0.606 1.489 0.190539 -0.38052
274.75 11.466 286.96 0.607 1.488 0.176833 -0.352126
279.75 11.501 287.116 0.607 1.48633 0.162951 -0.323621
284.75 11.603 287.31 0.608 1.48522 0.148916 -0.295101
0
0
0
0
0
0
HandXAcc HandYAcc ShoTor ElbTor ShoAcc ElbAcc Mot1Tor Mot2Tor TanAcc TanVel
0.558528 0.266653 -0.013822 0.010019 3.62699 -2.29854 -0.011313 0.010065 0.618916 0.058386
0.517531 0.272408 -0.014224 0.011433 3.36072 -2.00993 -0.010703 0.009173 0.584846 0.054516
0.478301 0.276816 -0.014991 0.012712 3.1059 -1.74274 -0.010152 0.008327 0.55263 0.050604
0.441849 0.279512 -0.015978 0.013886 2.86918 -1.496 -0.009694 0.007545 0.522836 0.046749
0.40893 0.280295 -0.017068 0.014764 2.6554 -1.28245 -0.009358 0.00684 0.495771 0.042882
0.379982 0.279113 -0.018101 0.015273 2.46742 -1.10269 -0.009164 0.006219 0.471477 0.039046
95
Appendix D
Regular Expressions For Parsing
Grammer
# GRAMMAR # @Author Baiju Devani # Dec 9th 2003
# Comments: To add a rule to the grammar, one needs to to do the
following: # 1) Name the rule with a token. For example ruleNew #
2) Add the rule in the startrule sequence. Or it can be embedded
within one # of the the subrules # 3) Add the rule token defintion
in terms of the regex and the action to # perform when the rule is
found (if any). For example: # ruleNew: /regex_for_things_to_find/
{ do something; item[1] } # Parse::RecDescent is used to parse the
grammar. This is a powerful # #tool and can do much more. Full
documentation can be found on CPAN.
startrule: Mdef Ver(?) State <commit> Channel FileInfo Repeat(s)
{
@::Monkeydef = split /\n/, $item{Mdef};
#$item{Ver} =~ /^ver(\d\.\d)/;
# Since this grammar is for monkey data, version is hardcoded
96
APPENDIX D. REGULAR EXPRESSIONS FOR PARSING GRAMMER
$::version = "1.0";
main::write_to_File("mdef",\@::Monkeydef,1);
@::StateCond = split /\n/, $item{State};
main::write_to_File("StateCond",\@::StateCond,2);
1;
}
Repeat: Trial StateTrans TrialFeatures Data
{
# Increase trial num for every trial encountered
$::trial_num++;
@::TrialHeader = split /\n/, $item{Trial};
main::write_to_File("TrialHeaders",\@::TrialHeader,2);
@::StateTrans = split /\n/, $item{StateTrans};
main::write_to_File("StateTrans",\@::StateTrans,1);
@::TrialFeatures = split /\n/, $item{TrialFeatures};
main::write_to_File("TrialFeatures",\@::TrialFeatures,2);
@::Data = split /\n/, $item{Data};
main::write_to_File("Data",\@::Data,1);
}
Data: Data1|Data2|Data3|Data4|DataEmg
97
APPENDIX D. REGULAR EXPRESSIONS FOR PARSING GRAMMER
Mdef: /^Monkey\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)
\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(Proto)\n((.+)\n)/m
Ver: /^ver\d\.\d/
State: /STATE CONDITIONS\nState(.+)TimeVar\n((.+)\n)*/m
Channel: /CHANNEL CONFIG\nChannel.+\n((.+)\n)*/m
FileInfo: /FILE PRODUCTION INFO\n((.+)\n)*/m
Trial: /TRIAL HEADER\n((.+)\n)*/m
StateTrans: /STATE TRANSITIONS\n((.+)\n)*/m
TrialFeatures: /TRIAL FEATURES\n((.+)\n)*/m
Data1: /(Time)\t(HandXPos)\t(HandYPos)\t(ShoAng)\t(ElbAng)\t(ShoVel)\t(ElbVel)\t
(Cell1)\t(HandXAcc)\t(HandYAcc)\t(ShoTor)\t(ElbTor)\t(ShoAcc)\t(ElbAcc)\t
(Mot1Tor)\t(Mot2Tor)\t(TanAcc)\t(TanVel)\t\n((.+)\n)*/m
{
$::grammar_type = 1;
# Need to do this so that outer rule of the grammar can refer to item{Data}
$item[1];
}
Data2: /(Time)\t(HandXPos)\t(HandYPos)\t(ShoAng)\t(ElbAng)\t(ShoVel)\t(
ElbVel)\t(Cell1)\t(HandXAcc)\t(HandYAcc)\t(ShoTor)\t(ElbTor)\t
(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(ShoAcc)\t
(ElbAcc)\t(Mot1Tor)\t(Mot2Tor)\t(TanAcc)\t(TanVel)\t\n((.+)\n)*/m
{
$::grammar_type = 2;
$item[1];
}
Data3: /(Time)\t(HandXPos)\t(HandYPos)\t(ShoAng)\t(ElbAng)\t(ShoVel)\t(ElbVel)\t
(Cell1)\t(Cell2)\t(HandXAcc)\t(HandYAcc)\t(ShoTor)\t(ElbTor)\t(ShoAcc)\t(ElbAcc)\t
(Mot1Tor)\t(Mot2Tor)\t(TanAcc)\t(TanVel)\t\n((.+)\n)*/m
{
98
APPENDIX D. REGULAR EXPRESSIONS FOR PARSING GRAMMER
$::grammar_type = 3;
$item[1];
}
Data4: /(Time)\t(HandXPos)\t(HandYPos)\t(ShoAng)\t(ElbAng)\t(ShoVel)\t(ElbVel)\t(Cell1)\t
(Cell2)\t(HandXAcc)\t(HandYAcc)\t(ShoTor)\t(ElbTor)\t(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t
(.+)\t(.+)\t(.+)\t(.+)\t(.+)\t(ShoAcc)\t(ElbAcc)\t(Mot1Tor)\t(Mot2Tor)\t(TanAcc)\t
(TanVel)\t\n((.+)\n)*/m
{
$::grammar_type = 4;
$item[1];
}
DataEmg: /(Time)\t(HandXPos)\t(HandYPos)\t(ShoAng)\t(ElbAng)\t(ShoVel)\t(ElbVel)\t
(HandXAcc)\t(HandYAcc)\t(ShoTor)\t(ElbTor)\t((EMG.+)\t)+(ShoAcc)\t(ElbAcc)\t
(Mot1Tor)\t(Mot2Tor)\t(TanAcc)\t(TanVel)\t\n((.+)\n)*/m
{
$::grammar_type = 5;
$item[1];
}
DataEmg: /(Time)\t(HandXPos)\t(HandYPos)\t(ShoAng)\t(ElbAng)\t(ShoVel)\t(ElbVel)\t(Cell1)\t
(HandXAcc)\t(HandYAcc)\t(ShoTor)\t(ElbTor)\t((EMG.+)\t)+(ShoAcc)\t(ElbAcc)\t
(Mot1Tor)\t(Mot2Tor)\t(TanAcc)\t(TanVel)\t\n((.+)\n)*/m
{
$::grammar_type = 6;
$item[1];
}
99
Glossary
KINARM Kinesiological Instrument for Altered And Reaching Movements. A
device/paradigm used for behavioral studies on upper limb movement and
coordination. Page 6.
OLAP
Online Analytical Processing. A database workload characterized by adhoc queries (on large amounts of data) and infrequent updates. Page 21.
OLTP
Online Transactional Processing. A database workload characterised by
a large number of data transactions(inserts, updates, retrieval) in short
periods of time. Usually such systems are used concurrently for inserts
and updates by a large of users. Page 20.
OODBMs Object-Oriented Database Management System. A data management
system based on object-oriented contructs. Data is defined in terms of
objects which have attriutes and methods and functions to manipulate
data. Page 16.
ORDBMs Object-Relational Database Management System. A relational data
management system that allows use of object-oriented features within the
relational database model (see RDBMs and OODBMs). Page 19.
RDMs
Relational Database Management System. A data management system in
which the primary constructs are tables (relations), columns (attributes),
and rows (tuples). Relationships between tables is established by keys
that are common across the tables. Page 14.
SQL
Structured Query Language. A standardized data definition, query, and
update language for relational database management systems. Page 16.
100