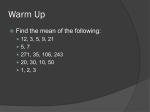
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Concurrency control wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Microsoft SQL Server wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Open Database Connectivity wikipedia , lookup
Relational model wikipedia , lookup
MAD Skills: New Analysis Practices for Big Data Jeffrey Cohen, Brian Dolan, Mark Dunlap Joseph M. Hellerstein, and Caleb Welton VLDB 2009 Presented by: Kristian Torp Overview • Enterprise Data Warehouse (EDW) vs. MAD • • • • • Why MAD now MAD Database Design Overview Stack of Statistical Functions MAD DBMS Conclusion: Comparison EDW vs. MAD Critique Database Specialization Course 2010 2 Data Warehouse Architecture Existing databases and systems (OLTP) New databases and systems (OLAP) Appl. DM DB OLAP Appl. DB Appl. DM Trans. DB DW ”Global” Data Warehouse Appl. Data mining DM DB Visualization Data Marts Appl. DB Thanks to TBP for the figure CaIn iKraft møde 2009-05-19 3 MAD Architecture db1 db2 integrator Analysis me db3 File 1 “Model less, Integrate More” Database Specialization Course 2010 4 MAD Acronym • Magnetic sucks data in (not always carefully cleaned) Multiple formats • Agile Mock-up based Rapid evolution “Shoot-and-forget” • Deep Advanced statistical methods Database Specialization Course 2010 5 Why MAD now? • Storage is cheap Terabytes for a few hundred bucks Cannot be found in the budget • Many new data sources Click-streams, emails, discussion forums, etc • Many understand the value of data analysis Previously mostly for top-level management • Copy-out-and-use scenario Not as efficient as putting query to data Typically fit into main memory Security (Excel hell) Database Specialization Course 2010 6 BI Query 1. What is the sale of milk in Aalborg vs. Copenhagen compared to last year? 2. What is the average drive time on Boulevarden, weekdays between 7.00-7.15 in the north direction on non-rain days, in the summer half-year? • Fairly simple statistics 1. How many female WWF enthusiasts under the age of 30 visited the Toyota community over the last four days and saw a medium rectangle? 2. How are the people similar to those that visited Nissan? • Multi-dimensional statistical analysis MAD Database Design • Agility to the developer Note necessary fully integrated (against EDW idea) • Analysis are early warning system Dirty data New interesting data (and non-interesting data) Have a deeper understanding than business EDW users New insight Analyst New data Database Specialization Course 2010 Developer 8 MAD Database Design, cont. • Staging schema layer Data: Raw data Users: Engineers and some analysts • Production data warehouse layer Data: Aggregated, semi-cleaned, intergraded data Users: Analysts and sophisticated users • Reporting schema layer Data: Aggregated, cleaned, integrated data Users: Reporting tools and casual users • Sandbox layer Data: What ever (avoid Excel copies) Users: Analysts • Not a strictly-layered architecture Cross layer joins possible for some users Database Specialization Course 2010 9 Statistics • General approach: mathematical concepts in SQL Via extensible DBMS technology • Vector arithmetic and higher levels Not supported in relational DBMSs Implemented as stored procedures/new operators Probability density functions New Linear Algebra Vector Arithmetic Existing SQL Functions Database Specialization Course 2010 Level of Abstraction 10 MAD DBMS • Getting data in and out (Loading/unloading) Bulk load a necessity (core and basic functionality) External tables Under OS control and not DBMS control Simple wrapper of for example CSV file Problem is query optimization Parallel access to all data • ETL Must be fast (called ELT instead) Fast prototyping with LIMIT clause • Storage and Partitioning Partitioning for speed up (standard technque) Storage hierarchies Often used data on SSD disk drives/RAM drives Less-used data on SATA disks Database Specialization Course 2010 11 MAD DBMS, cont • Storage engines Heap Append-only Column-store External tables • Programming model Short iterations (agile) Prototyping with small data sets Many different programming languages SQL, Java, Matlab, Perl, Python, R Runs in the DBMS (in stored procedures) Map-Reduce Database Specialization Course 2010 12 Conclusion: EDW vs. MAD • • • • • • • • • • • EDW One repository Waterfall (slow) Fixed Owner: Company Disciplined data integration SQL Basic agg. Functions Expensive hardware Top-down (management) Click-click-click (Excel) Expensive ETL Primary goal • • • • • • • • • • • MAD One repository Agile (fast) Evolving Owner: Department/person Ad-hoc data integration SQL or MapReduce Advanced agg. Functions Whatever you can find Grass roots R, SAS, Python, Java, matlab Human dirty data Secondary goal Database Specialization Course 2010 13 Good • Nice case-study • Okay Greenplum feature discussion (sec. 6.1, 6.2 and 6.3) Not a big commercial for their system • Useful in practice • Good explanation of how used at Fox network • Nice to see Perl, Python, R used with PostgreSQL Pushes the extensibility of a relational DBMS to the limit • Nice support for map-reduce and SQL in same software stack Pick the best tool for the job (what you have used the most) Database Specialization Course 2010 14 Could be improve • • • • • • • • MPI, SVM acronym not introduced Slang: “feeding frenzies”, “vanilla” SQL, “MAD” Better comparison of EDW vs. MAD Section 5: Data Parallel statistics quite hard to follow in several cases All their figure are nice Missing some kind of conclusion Better description on how agile in Fox case study No performance graphs showing that the parallel functions scale This is an unproven claim in the paper Database Specialization Course 2010 15