Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
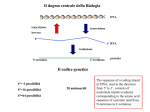
DNA pol
DNA
RNA pol
Transcription
Replication
ARS
tRNA
Ribosome
mRNA
Protein
Translation
A
B
Acceptor stem
T C loop
D-loop
Variable loop
Anticodon
loop
0.8
A
3 box codons
V
0.6
4 box codons
6 box codons
L
A
AG
0.4
AGA
L
0.2
A
A
A A AG
A A
AG
AGG
V V
0.0
Relative tRNA gene copy number
2 box codons
A
0.0
0.1
0.2
0.3
0.4
0.5
Relative codon frequency
0.6
0.7
i
j
c
a
oac
c
c
a
c
= [o1 , . . . , o64 ]
o
o
C
a
Ca
ka
L
A
A1
r̂
C
A
c
a
Ca
ka
oac
L
Fa
fac
rac
a
a
c
a
a
c
a
c
a
oc
gc = !
oc
c∈C
g
oac
gac = ! !
oac
a∈A c∈Ca
oac
fac = !
oac
c∈Ca
f
rac =
ka
1
ka
oac
!
oac
=
oac
oa
c∈Ca
r
wac
wac =
oac
oac
c∈Ca
=
o
=
o
o
"
oc
c∈C
C
C
o
=
o
o
−e
−e
o
o
e
e
e
=
"
a∈A
oa
na
ka
oa
a
oa
a
ka
f
=
"
Fa ( a ,
a
f
)
a∈A
Fa
a
a
a
a
(·)
a
( a,
a
)=
"
c∈Ca
|fac , fac |
B(z|z all )
=
( )
( )
={
=
(
Ec =
fc
b1 b2 b3
c∈C }
,
)
fc
ec
ec =
c
L
L
L
L
wac
wac =
fac
eac
w
fac
eac = b1 b2 b3
bi
i
=(
L
#
i=1
L
1
wc (i)) L =
(
1"
L i=1
wc (i))
wac
=
L
$#
wc (i)
i=1
% L1
L
$1 "
L i=1
=
!L
( L1 i=1
!L
1
=
(L
=
(
i=1
wc (i)
oac (i))
oa,
1 "
oc
o
(i))
wc )
c∈C
wc
=
oc − E[oc ]
E[oc ]
oc
c
E[oc ]
(b1 b2 b3 )
%
=
(
1 "
o
c∈C
wc ) − 1
wc
wc0
&
wc = &
wc+1 wc+2
c
wc
=
fc
fc
fc
fc
c
=
1 "
o
wc
c∈C
w
Wc
c
t
Wc =
"
t
c
(1 − sct )Tct
sct
Tct
t
c
Wc
wac =
Wac
Wac
c∈Ca
Wc
w
n
=
$ 1 "
oc
o
c∈C
wc
%
sct
=
U −U
σU
U
U =−
M( )
o ! # oc
M( ) = '
fc
(oc !)
c∈C
c∈C
oc
fc
o
c
o
=
" Ba
a∈A
oa
o
oa
a
o
Ba
Ba =
" (oc − ec )2
ec
c∈Ca
χ2
oc
c
χ2
χ2
ec
χ2 =
1 " " oac − ka−1
o
ka−1
a∈A c∈C
a
oac
c
a
a
χ2
Za
Za =
oa
!
fac
2
fac
−1
oa − 1
c∈Ca
Na = Za−1
Na
ka
Na
Za
k
K
=
"
nk N a=k
k∈K
N a=k =
1 "
Na
nk
a∈Kk
ka
>
Z
Z k=3 =
)
1( 2
2
1
2
3
(
− 1)−1 + (
− )−1 + (
− )−1
3 Z k=2
3
5
3Z k=4
5Z k=6
=
"
a∈A
χ2
Na
X
x 1 , x 2 , . . . xk
X=
"
I(oc )
c∈Ca
oc
c
a
Ca
I(·)
1
oc ≥ 1
o = [5, 4, 0, 1]
0
xa
px
2k − 1
[p1 , p2 , p1 + p2 , p3 , . . . , p1 + p2 + . . . + pk ]
1
T
i+1
=T
i
n−1
n
= T n−1
n
1
T = QΛQT
Λ
n
= QΛ(n−1) QT
1
n
p1
p1
p1
p2
p2
p2
0
p3
p1+p2
T
0
Compute new state
p1+p2
c1
p3
p3
c2
p1+p3
p1+p3
c3
T
Repeat until end of
p2+p3
vector s
0
D
p2+p3
sequence
0
p1+p2+p3
p1+p2+p3
s1
si+1
sn
2k − 1
D
k
=D
pz (z) = px (x) ⊗ py (y) =
k
k
1
n
"
i∈{k−|y|,...,k}
pz
|x| + |y| − 1
Sum the
state vector
px (i) · py (k − i + 1)
|px | + |py | − 1
x
y
=
n
*
oa > 0
i
i=1
x
=
"
xa
a∈A
x
n
nk
= 1 − P (X ≤ x),
=
"
Fa Ea
a∈A
Fa
Ea
(Ha ) =
Ha
ka
2
Ha
=
(Ha )
Ea =
Ha
2 ka
Ha
a
Ha = −
"
fac
2
fac
c∈Ca
a
Ha = −
n
"
pa (c)pa (c|c# )
ka
i=2
pa (c)
c
c
pa (c|c# ),
c
#
pa (c|c# )
a
(Ha ) =
Ea =
o
−1
.
ka
(Ha ) − Ha
=
(Ha )
=
"
a∈A
2
Fa Ea
ka − Ha
2 ka
pc
c
pc
fc
=
" fc
pc
c∈C
=
o
o
+o
+o
= 1 − 2p
=
o
o
o
1 "
Ma − K
L
=
a∈A
L
Ma
K
Ma
Ma = 2
"
c∈Ca
eac
oac
oac
eac
K
K=
1 "
1
(ka − 1) −
L
2
a∈A
1/2
=
Sk
k
Sa =
1
ka (ka − 1)
"
c∈Ca
(rac − 1)2
rac
ka
a
=
"
Fa Sa
a∈A
Fa
1/18
v(c)
c
v(c) =
9
"
(A(ci ), A(c))
i=1
A(c)
d
βi
i(g)
g
i
Ei (c)
i
c
β1
β3
wac
wac =
oac
oac
oac
oac
=
G
"
2
G(G − 1) i,j∈
{1 −
(
(i) ,
(j) )}
(x − x̄)/sx
0.2
0.4
0.6
0.8
CAI
Fop
CBI
Nc
0.0
Coefficient of variation
0.5
0.0
0.5
1.0
Normalized mean
1.0
CAI
Fop
CBI
Nc
1.0
sx /x̄
0
20
40
60
80
100
0
GC content
40
60
GC content
(x − x̄)/sx
sx /x̄
20
80
100
0.0
1.0
0
100
200
Length
300
400
500
0.0
0.5
0.2
0.4
0.6
0.8
Coefficient of variation
0.5
Normalized mean
1.0
1.0
CAI
Fop
CBI
Nc
CAI
Fop
CBI
Nc
0
100
200
Length
300
400
500
4
0
4
2
0.5
0.0
log CV
2
0.5
CAI
Fop
CBI
Nc
1.0
Normalized mean
1.0
CAI
Fop
CBI
Nc
0.0
0.2
0.4
0.6
0.8
Fraction of 4 & 6 degenerate codons
1.0
0.0
0.2
0.4
0.6
0.8
Fraction of 4 & 6 degenerate codons
d
di−1
i
8
4
2
1
{ 15
, 15
, 15
, 15
}
d = 12
1 0 1 1 1 2 1 3
{( 2 ) , ( 2 ) , ( 2 ) , ( 2 ) }
1.0
2
4
0
4
1
2
0
log CV
2
1
CAI
Fop
CBI
Nc
2
Normalized mean
CAI
Fop
CBI
Nc
0.0
0.2
0.4
0.6
0.8
1.0
0.0
Degree of codon discrepancy
0.2
0.4
0.6
0.8
Degree of codon discrepancy
Y
=
"
a∈A
Fa
Ya
F a Ya
1.0
2
0
log CV
1
1
0
CAI
Fop
CBI
Nc
3
1
4
2
Normalized mean
2
CAI
Fop
CBI
Nc
0.0
0.2
0.4
0.6
0.8
1.0
0.0
Degree of amino acid discrepancy
=
"
a∈Aφ
Aφ
Fa
0.2
0.4
0.6
0.8
Degree of amino acid discrepancy
Fa
1.0
ks
ks
ks
d
dt
] − kd [
= ks [
ks = kd
[
[
].
]
]
kd =
2/t 12
ks
kd
Transcription
[mRNA]
Translation
[Protein]
ks
mRNA decay
ks
kd
Protein
turnover
kd
(standard deviations)
Bias towards reuse
A
Distance between codons
(number of intervening amino acids)
B
C
D
Frequency
16
A
10
12
8
4
-25 -20 -15 -10 -5 0 5 10 15 20 25
Standard Deviations
<
B
20
8
16
6
12
4
8
2
4
-30 -20
-10
0
10
20
Standard Deviations
30
C
-30
-20 -10
0
10
20
Standard Deviations
30
<
Slow translation (GFP1)
Rapid translation (GFP2)
Rapid translation (GFP2)
Slow translation (GFP1)
Alanine
20
normal autocorrelation
shuffled within gene
shuffled within genome
15
10
15
10
5
5
0
0
Glycine
20
Isoleucine
20
15
15
10
10
5
5
0
0
Leucine
20
Proline
20
15
15
10
10
5
5
0
0
Serine
20
percent deviation
from expected
Arginine
20
Threonine
20
15
15
10
10
5
5
0
0
Valine
20
15
10
5
0
0
10 20 30 40 50
distance between codons
(number of intervening amino acids)
>
All
20
15
10
5
0
0
10
20
30
40
50
S. cerevisiae
15
5
C. glabrata
10
D. melanogaster
10
5
5
0
20
0
0
10
20
30
A. gossypii
10
10
20
30
A. thaliana
15
15
30
H. sapiens
5
5
0
0
10
percent deviation from expected
20
10
5
10
10
20
30
S. pombe
0
10
15
20
30
C. elegans
5
10
5
0
0
10
20
30
distance between codons
(number of intervening amino acids)
10
20
30
10
20
30
ng
gi
ar
ch
N
A
tRNAs
Genetic code
-tR
23-45
AA
ti
m cod
ap on
pi -c
ng od
o
n
mRNA
An
61
20
Amino acids
A
B
Anticodon
Codon
Anticodon
Codon
A(I)
U
A
U
G
C
G
C
U
A
U
A
C
G
C
G
·
π
t
e
E
!
j
eij = 1
E
T
!
j tij
= 1
T
α
β
π = [π1 , π2 ]!
λ = {E, T, π}
O
P (O|λ)
P
=
"
i∈
P (Oi |λ),
P (O|λ)
P (λ|O)
P (M )
P (O)
t12
1
t11
tRNAAGC
t21
e14
GCU
e22
GCC
GCA
t
π
e
xi
i
xi =
"
c∈
nc
i
t22
e21
e13
e12
e11
2
tRNAUGC
c,
e23
e24
GCG
nc
r
c
i
rc
nc = ! ,
t rt
c
i
nc = (1/4)/(1/4 + 1/3) = 3/7
xi
i
i
∼ γx2i + (i
γ
(i
Z = (X − E[X])/σX
GCA
GCG
11
tRNA
GCC
58952
35580
47988
18336
tRNA
Codon
GCU
11
1
1
0
0
UGC
5
0
0
1
1
5
AGC
R2 = 0.9995
p = 0.0102
Ala AGC
Ala UGC
47988 + 18336
= 66324
Reading
58952 + 35580
= 94532
∼ γx2 + e
s
X
s=
""
i
Cij
+1
j
Cij Xij ,
i &= j,
−1
Leading codon
Consecutive codon
GCU
GCC
GCA
GCG
GCU
11.0
1.3
-8.7
-6.9
GCC
0.8
6.8
-6.2
-0.8
GCA
-8.2
-6.4
11.5
4.8
GCG
-7.1
-1.4
5.4
5.7
sn = (s −
s)/(
s−
s)
p̂ =
n
r+1
,
n+1
r
Normalized Score
1.0
0.5
0.0
CC
REG
HMM
<
Number of predictions
Diffr. to random +/-
428
-115
HMM
419
+132
REG
205
+26
412
+125
119
-168
CC
a
b
c
d
e
f
!
a
a
a
a
!
a
a
!
!
!
a
a
a
a
a
e
e
e
d
c
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
b
f
!
!
ψ ψ
IGA
GmAA
G A
Thr
Ile
CAUinit
IGC
ncm5UAC
CAC
Ala
Val
IAC
G
His
CAU
CAU
CmCA
C
A
CCG
CUG
GUU
ncm5UGC
G
T
C
GCU
mcm5UCU
mcm5s2UUU
CUU
G
T
mcm5s2UUG
ncm5UGU
Asp
Met
A
Asn
IGU
IAU
A
ncm5UGG
GUG
Gln
UAG
A
ICG
Lys
GAG
Pro
C
Leu
AGG
C
GCA
Trp Stop
CGA
3rd
T
Arg
m5CAA
Ser
ncm5UGA
Stop
ncm5UmAA
CCU
A
G
T
C
GCC
GUC
mcm5s2UUC
Glu
Leu
Ser
T
2nd
G
Cys
A
Arg
Phe
C
CUC
Gly
T
Tyr
2nd
1st
mcm5UCC
CCC
A
G
Anticodon
A
G
U
C
Pyr
Ile
4-box
Gly
Pur
ψ ψ
All
Pairs
All x All
Comparison
Candidate
Pairs
Formation of
Stable Pairs
Stable
Pairs
Verification of
Stable Pairs
Broken
Pairs
>
Verified
Pairs
Clustering of
Orthologs
Orthologous
Groups
Group
Pairs
*
(|a1 |, |a2 |) > * ·
a1
a2
(|s1 |, |s2 |)
s1
*
d ≤d +d
s2
Number of orthologous relations
Fraction of genes with same number of domains
Fraction of genes that pass triangle test
100
99.90
99.80
Domain test [%]
Triangle test [%]
0.3
0.2
95
0.1
90
0.5
0.6
0.7
0.8
Length Tolerance
*
0.9
1
Orthologous relations [106]
100
<*<
*
Score
Distance
No Tolerance
BBH
RSD
Tolerance
RBH
SP
i
∈ ,
d
d
i
j
i
&=
j
−d >k
+
σ 2 (d
−d >k
+
σ 2 (d
d
∈ ,
j
i
j
&=
−d )
−d )
k
σ 2 (d
2
d ) = σ (d
2
) + σ (d ) −
j
k
k
·
(d
,d )
j
j
−
A
y1
x
?
y2
C
B
z
x
y1 y2
z
x
D
y1
z
x
d>0
y2
d
y1 y2
d
d=
d
+d
+d
+d
− ·d − ·d
>0
k
k
1 2
d
d
d
d
Fraction of SP
passing test [%]
90
89
l = 0.70
l = 0.65
l = 0.60
88
l = 0.55
1.4
1.6
1.8
2.0
2.2
2.4
l = 0.50
SP tolerance
A
B
C
x1
d x1z1
x1 x2 z1 z2 y1 y2
y2
d x1z2 d y2z1
z1
z2
x1
y2
z1
z2
d y2z2
k
97.2
l = 0.61, kSP = 1.81
Fraction of VP
passing test [%]
97.0
96.8
96.6
96.4
96.2
l = 0.72, kSP = 1.67
96.0
95.8
l = 0.58, kSP = 1.96
0.5
1
1.5
VP tolerance
2
2.5
w1
00
0
400
900
50
0
z1
200
700
8
x1
B
30
y2
1000
A
z2
w1
x1
z1 z2
y2
$n%
2
= Paralogs
= Orthologs
AP
CP
SP
VP
GP
Relative Amount [%]
BP = SP minus VP
50
40
30
20
10
CP
SP
VP
GP
Type of Connection
i,j
j
i
Class
105
Number of members
Genomes
All
Bacteria
Firmicutes
Eukaryota
Archaea
Vertebrates
Mammalia
104
550
444
116
72
51
32
25
Orthologs Ave. groupsize
302596
145255
28109
157302
15622
80123
58982
5.52
7.20
7.67
4.11
4.32
5.46
5.75
103
102
10
2
Group Size
Full
Codon 2nd position
T
C
Phe
T
G
Tyr
Cys
Stop
Stop
Trp
Ser
Leu
His
C
Leu
Pro
Arg
Gln
A
Ile
Asn
Ser
Lys
Arg
Thr
Met + Init
Asp
G
Val
Ala
Gly
Glu
= 6 box
= 4 box
= 3 box
= 2 box
T
C
A
G
T
C
A
G
T
C
A
G
T
C
A
G
Codon 3rd position
Codon 1st position
A
= 1 box
C
G
C
G
U
in
e
Glu
tam
ine
Arginin
A U C G A U C
CG
GA
Hi
st
id
A
e
Serin
i ne
lan
yla
en
ine
uc
Le
e
U
e
Ph
Ty
ro
sin
C
G
e
cin
Leu
A
U
A
U
A
U
G
C
U
A
ine
G
C
A Proline
U
C
U
Stop A
U
C
G
Tryptophan G
C
C
G
C
G
U
A
A
G
U Glycine
nine A
o
e
r
h
T
G
C
U
A
C
G
A Gl
U
uta
U
e A
A
U
mi
n
i
ca
C A
G
uc
e
G
C
cid
l
s
G
C
pa
e
Iso
n
A
U
r
i
t
i
n
U
c
A
o
C
ac
GC
hi
id
U A G CU AG
et
M
Sto
p
Arginine
Serine
Lys
ine
ra
g
ne
ne
Alani
As
pa
li
Va
in
e
Cyst
e
Genetic code
1
T
2
3
5
12 13
21 23
1
22 1
F
S
Y
C
T
F
S
Y
C
C
L
$
C
A
$
Q
S
$
$
Q
14 15 16
21 22
1
2
3
4
5
9 10 13
$ W W W W W
Y
Q
14 21
C W W W
A
G
L W
L
L
T
P
H
R
T
L
T
P
H
R
C
L
T
L
T
P
Q
R
A
P
R
G
S
T
S
C
I
T
Q
N
I
T
N
T
K
T
K
I
S
M M M
M M
M
G
S
9
N
N
N
R
$
S
S
G
S
S
A
R
$
S
S
G
S
S
G
V
A
D
G
T
V
A
D
G
C
V
A
E
G
A
V
A
E
G
G
T
C
A
2nd Position
G
2nd Position
1st Position
L
6
H
B
not-G
not-A
S
M
Strong
K
aMino
NH 2
Weak
O
N
Y
W
Keto
NH
Y
pYrimidine
pYrimidine
N
H
N
H
O
C
O
T
Cytosine
Thymine
NH 2
O
N
N
N
R
NH
R
puRine
puRine
N
H
N
H
N
A
W
NH 2
G
Adenine
Weak
N
Guanine
M
K
aMino
Keto
V
S
Strong
D
not-T
not-C
N
aNy
Electricaly charged side chains
Positive
Arginine
Histidine
Negative
Lysine
Polar uncharged side chains
Serine
Threonine
Aspartic acid
Glutamic acid
Special cases
Asparagine
Glutamine
Cysteine Selenocysteine Glycine
Proline
Pyrrolysine
Hydrophobic side chains
Alanine
Valine
Leucine
Isoleucine
Methionine
Phenylalanine
Tyrosine
Tryptophan
ψ
≈
◦
◦
Probability
TPI = L - R
L
(L + R = 1)
R
Changes
4 Valine
AAARMRRAVCVVCVAR
Count the number of changes
4 Arginine
5 Alanine
Calculate the distribution of changes
A
B
C
P2 GFP2 GFP1
P2
P2
GF
GF
GFP
200
FP
2G
GFP2GFP1
GFP2GFP2
Velocity ratio
2GFP
150
P
GF
100
50
100
200
300
1
1
1.5
1.0
0.5
GFP1 GFP1’ GFP1”
GFP2 GFP2’ GFP2”
Position on gel
TPI construct
correlated vs. anti-correlated
GF
P1
GF
Intensity (arbitrary units)
P1
GF
All
TPI construct
2
2
Amino acid sequence
Subsequence of consecutive
synonymous codons
Observable output sequence
MGCANLVSRLENNSRLLNRDLIAVTIGAIVYKDPHAGALRS ...
GCA GCT
GCA
1, 1, 4, 3, 2, ...
1
Count matrix of consecutive codon
1
1
1
GCG GCC ...
95000
Codon frequency
6
4
2
12
10
8
6
15
tRNA gene copy number
4
100000
6
4
tRNA gene copy number
CCA
2
10
R squared = 0.9997
p val= 0.0073
8
10
Proline
R squared = 0.7774
AAG
p val= 0.2165
12
14
140000
CCT
6
75000
90000
130000
40000
Codon frequency
60000
100000
Codon frequency
ACG
2e+04
14
12
GTT
6
8
10
R squared = 0.9978
p val= 7e 04
4
8
6
4
ACA
0
TCG
tRNA gene copy number
AGC
Valine
ACT
2
tRNA gene copy number
6
4
TCA
R squared = 0.9963
p val= 0.0013
10
TCT
80000
Codon frequency
Threonine
R squared = 0.9581
p val= 0.0024
60000
110000
2
65000
8
10
ATT
Codon frequency
AAA
CTC
2
60000
8
tRNA gene copy number
10
8
6
4
CTA
2
0
tRNA gene copy number
TTA
80000
ATA
8e+04
Lysine
TTG
60000
R squared = 1
p val= 0.0016
Codon frequency
Serine
tRNA gene copy number
GGA
4e+04
Codon frequency
0
GGC
10
0e+00
Leucine
R squared = 0.9179
p val= 0.0066
20000
40000
Codon frequency
5
tRNA gene copy number
14
12
10
8
6
4
GGG
140000
Codon frequency
55000
CAG
Isoleucine
R squared = 0.9238
p val= 0.0257
2
tRNA gene copy number
GAA
100000
60000
Glycine
GAG
60000
40000
Codon frequency
Glutamic acid
R squared = 0.9962
p val= 0.0277
8
AGG
20000
0
CGG
0
CAA
2
85000
tRNA gene copy number
10
8
6
4
0
4
75000
R squared = 0.9755
p val= 0.0706
AGA
CGT
GCA
65000
Glutamine
R squared = 0.9303
p val= 0.0052
2
tRNA gene copy number
6
7
8
9
10
Arginine
GCT
5
tRNA gene copy number
11
Alanine
R squared = 0.9993
p val= 0.0118
GTG GTA
6e+04
Codon frequency
1e+05
4e+04
6e+04
8e+04
Codon frequency
1e+05
GCT
Alanine
GCC GCA
GCG
Arginine
CGA CGG
CGT
CGC
AGA
AGG
13.4
2.5
-2.5
-3.7
-1.7
-6.8
3.4
8.5
2.1
9
-8.4
-0.1
-3.3
4.6
9.3
7.5
-7.1
2
4.9
8.7
-7.1
1.5
GCT
11
0.8
-8.2
-7
GCC
1.3
6.8
-6.4
-1.4
GCA
-8.7
-6.3
11.6
5.4
CGT
CGC
CGA
5.8
CGG
-0.7
5.3
AGA
-3.5
-8.8
-7
-8
12
-0.9
AGG
-5.5
1.4
3.6
1.8
-3
5.1
GCG
-6.9
-0.9
4.8
GGT
Glycine
GGC GGA
GGG
GGT
26.8
-11.8
-17.6
-9.2
CCT
3.7
0.2
-2.8
-1
GGC
-11.1
7.8
5.2
3.9
CCC
1.3
6.7
-7
2.8
CCT
Proline
CCC CCA
CCG
GGA
-17.2
6.2
14
5.2
CCA
-4.5
-7.1
11
-3.9
GGG
-10.5
3.8
7.3
5.3
CCG
0.5
4.7
-6.4
5.3
CTT
CTC
Leucine
CTA CTG
TTA
TTG
TCT
TCC
CTT
7.9
4.6
-1.6
-4.1
0.6
-4.5
TCT
12.6
CTC
4.3
10.6
-1.4
4.4
-5.1
-4.6
TCC
Serine
TCA TCG
AGT
6
-0.5
-2.8
-9.7
-11
5.4
7.3
-4
-1.7
-3.7
-5.2
AGC
CTA
-0.2
-0.3
4
0.8
0.9
-4
TCA
-4.3
-3.5
9.4
2.3
-0.3
-4
CTG
1
3.1
1.8
9.7
-6
-3.6
TCG
-4.8
0.4
1.2
6.9
-2.9
2.3
TTA
-0.3
-3.1
1.9
-3.5
7.4
-4.8
AGT
-7.1
-5.8
-1.8
-2.4
10.5
9.7
TTG
-7.7
-6.9
-4.3
-2.5
-2.1
15.5
AGC
-6.3
-6.3
-6.4
-0.5
9.7
14.5
ACT
Threonine
ACC ACA
ACG
GTT
Valine
GTC GTA
ACT
6.1
4.9
-6.7
-5.6
GTT
9
2.1
-6.5
-7.5
ACC
3.6
7.1
-6.5
-4.6
GTC
2
7.5
-6.8
-3.2
ACA
-5.5
-8
8.6
5.6
GTA
-6.5
-6.6
10.9
4.1
ACG
-5.8
-4.4
5.6
6.1
GTG
-7.3
-3.6
4.3
9.2
GTG
HMM
REG
CC
1.0
1.0
1.0
CC
0.8
0.8
0.8
REG
0.0
0.0
0.0
0.2
0.2
0.2
0.4
0.4
0.4
0.6
0.6
0.6
0.8
0.8
0.8
1.0
1.0
1.0
CC
0.6
0.6
0.6
HMM
REG
0.0
0.0
0.0
0.2
0.2
0.2
0.4
0.4
0.4
0.6
0.6
0.6
0.8
0.8
0.8
1.0
1.0
1.0
CC
0.4
0.4
0.4
HMM
REG
0.2
0.2
0.2
HMM
0.0
0.0
0.0
0.0
0.0
0.0
0.2
0.2
0.2
0.4
0.4
0.4
0.6
0.6
0.6
0.8
0.8
0.8
1.0
1.0
1.0
Alanine
Arginine
HMM
Glutamic acid
HMM
Leucine
HMM
Serine
HMM
REG
REG
REG
REG
Glutamine
CC
CC
HMM
Glycine
CC
HMM
Lysine
CC
HMM
Threonine
HMM
REG
REG
REG
REG
CC
Isoleucine
CC
Proline
CC
Valine
CC
ψ ψ
ψ