Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Pré-processamento,
Transformação e
Limpeza de dados
(baseado nos slides do livro: Data
Mining: C & T)
Front-end applications of DW
Information processing
Querying, basic statistical analysis, reporting using
crosstabs, tables, charts or graphs
Analytical processing
Multidimensional data analysis through basic OLAP
operations (slice/dice, drill-down, roll-up, pivoting, etc)
Data mining
2003/04
Knowledge discovery by finding hidden patterns and
associations, building analytical models, performing
classification and prediction, and presenting results
through visualization tools.
Sistemas de Apoio à Decisão
(LEIC Tagus)
Application context
Construction of a data repository for data
analysis
Migration of data from a source to a target
schema
also called pre-processing (data mining context) or
ETL process (DW context)
querying, reporting, analytical processing, data mining
require quality data
poorly structured to structured data
to support application migration
Enhancement of a single data source
2003/04
Eliminating errors, duplicates, inconsistencies
Sistemas de Apoio à Decisão
(LEIC Tagus)
Application context
Construction of a data repository for data
analysis
Migration of data from a source to a target
schema
also called pre-processing (data mining context) or
ETL process (DW context)
querying, reporting, analytical processing, data mining
require quality data
poorly structured to structured data
to support application migration
Enhancement of a single data source
2003/04
Eliminating errors, duplicates, inconsistencies
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Preprocessing
Why preprocess the data?
Descriptive data summarization
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Example (1)
time
item
time_key
day
day_of_the_week
month
quarter
year
Sales Fact Table
time_key
item_key
branch_key
branch
location_key
branch_key
branch_name
branch_type
units_sold
dollars_sold
avg_sales
Measures
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
item_key
item_name
brand
type
supplier_type
location
location_key
street
city
province_or_street
country
Example (2)
Suppose we want to analyze the
company´s data wrt the sales at a given
branch
Select attributes and dimensions to be
included in the analysis: item,price,
units_sold, etc
May find out that....
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Why Data Preprocessing?
Data in the real world is dirty
incomplete: lacking attribute values, lacking certain
attributes of interest, or containing only aggregate data
noisy: containing errors or outliers (spelling, phonetic
and typing errors, word transpositions, multiple values
in a single free-form field)
e.g., Salary=“-10”
inconsistent: containing discrepancies in codes or
names (synonyms and nicknames, prefix and suffix
variations, abbreviations, truncation and initials)
2003/04
e.g., occupation=“”
e.g., Age=“42” Birthday=“03/07/1997”
e.g., Was rating “1,2,3”, now rating “A, B, C”
e.g., discrepancy between duplicate records
Sistemas de Apoio à Decisão
(LEIC Tagus)
Why Is Data Dirty?
Incomplete data comes from:
non available data value when collected
different criteria between the time when the data was collected
and when it is analyzed.
human/hardware/software problems
Noisy data comes from:
data collection: faulty instruments
data entry: human or computer errors
data transmission
Inconsistent (and redundant) data comes from:
Different data sources, so non uniform naming conventions/data
codes
Functional dependency and/or referential integrity violation
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Why Is Data Preprocessing
Important?
Data warehouse needs consistent integration
of quality data
Data extraction, cleaning, and transformation comprises
the majority of the work of building a data warehouse
No quality data, no quality mining results!
2003/04
Quality decisions must be based on quality data (e.g.,
duplicate or missing data may cause incorrect or even
misleading statistics)
Sistemas de Apoio à Decisão
(LEIC Tagus)
Major Tasks in Data
Preprocessing
Data cleaning
Fill in missing values, smooth noisy data, identify or remove
outliers, and resolve inconsistencies
Data integration
Integration of multiple databases, data cubes, or files
Data transformation
Normalization and aggregation
Data reduction
Obtains reduced representation in volume but produces the same
or similar analytical results
Data discretization
2003/04
Part of data reduction but with particular importance, especially
for numerical data Sistemas de Apoio à Decisão
(LEIC Tagus)
Forms of data preprocessing
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
One methodology for the
ETL process (L. English)
Parsing
Correction: ZIP or postal codes, addresses
(field) Standardization: casing, soundex/phonetic
equivalent, dictionary spelling, column splitting or
merging, filter out stopwords, conversion to a standard
format (e.g. dates)
Matching or record linkage: exact matches, wild card,
soundex, keying fields or combination of fields, text
indexing, edit distance, signatures
Consolidation (enhancement and merging): duplicate
with more information is kept, source priority, most
recent update, most frequently occurring, random
choice, field contents, take an equal number of fields
from each source
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Preprocessing
Why preprocess the data?
Descriptive data summarization
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Descriptive data
summarization
Motivation
To better understand the data: central tendency,
variation and spread
Measures of central tendency
Mean, median, mode, midrange
Measures of data dispersion
Quartiles, inter quartile range, outliers, variance,
etc.
Goal: efficiently compute these measures in
large DBs
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Measuring the Central
Tendency
1 n
Mean (algebraic measure): x xi
n i 1
Weighted arithmetic mean:
x
Trimmed mean: chopping extreme values
Median (holistic measure):
n
Middle value if odd number of values,
median L1 (
w x
i
i 1
n
i
w
i 1
i
n / 2 ( f )l
f median
)c
or average of the middle two values otherwise
Estimated by interpolation (for grouped data)
Mode
mean mode 3 (mean median)
Value that occurs most frequently in the data
Unimodal, bimodal, trimodal
Empirical
2003/04
formula:
Sistemas de Apoio à Decisão
(LEIC Tagus)
Median, mean and mode of
symmetric data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Positively Skewed Data
Mode appears at the point smaller than the median
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Negatively Skewed Data
Mode appears at the point greater than the median
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Negatively skewed data
(example)
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Measuring the Dispersion
of Data (1)
Quartiles, outliers and boxplots
2003/04
Quartiles: Q1 (25th percentile), Q3 (75th percentile)
Inter-quartile range: IQR = Q3 – Q1
Five number summary: min, Q1, M, Q3, max
Boxplot: ends of the box are the quartiles, median is
marked, whiskers, and plot outlier individually
Outlier: usually, a value higher/lower than 1.5 x IQR
Sistemas de Apoio à Decisão
(LEIC Tagus)
Quartiles
Kth percentile of a set of data in numerical order:
value x such that k % of the data entries lie at or
below x
Values at or below the median: 50th percentile
Quartiles: most commonly used percentiles, give
indication of the center, spread and shape of a
distribution
2003/04
Q1: 25th percentile; Q3: 75th percentile
Interquartile range: IQR = Q3 – Q1
Outliers: values 1.5XIQR above Q3 or below Q1
Sistemas de Apoio à Decisão
(LEIC Tagus)
Boxplot Analysis
Five-number summary of a distribution:
Minimum, Q1, M, Q3, Maximum
Boxplot
Data is represented with a box
The ends of the box are at the first and third
quartiles, i.e., the height of the box is IRQ
The median is marked by a line within the box
Whiskers: two lines outside the box extend to
Minimum and Maximum
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Boxplots paralelas
(exemplo)
100
90
80
70
60
Nigerd'I voire
Côte
Uganda
Burund
T
Burkina
anzaniia
Faso
Kenya
Lesotho
50
Namibi awe
Zimbab
Botswa na
Swazila nd
Rwanda
Ethiopi a
Zambia
Kenya
Botswaawe
Zimbab
Namibi
na
Swazila nd
Zambia
Rwanda
Ethiopi a
Malawi
Namibi awe
Zimbab
Botswa na
Rwanda
Ethiopi and
Swazila
Zambia
Malawi
Malawi
40
30
Ambos os sexos 1998
2003/04
Masculino 1998
Feminino 1998
Ambos os sexos 2025
Masculino 2025
Sistemas de Apoio à Decisão
(LEIC Tagus)
Feminino 2025
Visualization of Data Dispersion:
Boxplot Analysis
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Measuring the Dispersion
of Data (2)
Variance and standard deviation
s
2
Variance s2:
n
n
n
1
1
1
2
2
( xi x )
[ xi
( xi ) 2 ]
n 1 i 1
n 1 i 1
n i 1
Standard deviation s is the square root of variance s2
measures spread about the mean
S=0 when there is no apread, i.e., all observations have the same
value
2003/04
Both are algebraic measures, scalable computation
Sistemas de Apoio à Decisão
(LEIC Tagus)
Properties of Normal
Distribution Curve
The normal (distribution) curve
2003/04
From μ–σ to μ+σ: contains about 68% of the
measurements (μ: mean, σ: standard deviation)
From μ–2σ to μ+2σ: contains about 95% of it
From μ–3σ to μ+3σ: contains about 99.7% of it
Sistemas de Apoio à Decisão
(LEIC Tagus)
Graphic Displays of Basic
Statistical Descriptions
Graph displays of basic statistical class descriptions
Boxplot
Histogram
Quantile
plot
Quantile-quantile (q-q) plot
Scatter plot
Loess (local regression) curve
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Histogram Analysis
Frequency histograms
A univariate graphical method
Consists of a set of rectangles that reflect the counts
or frequencies of the classes present in the given data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Histograms (example)
100
100
Ambos os sexos 2025
Ambos os sexos 1998
80
80
60
60
40
40
20
20
0
0
30
2003/04
40
50
60
70
80
90
30
Sistemas de Apoio à Decisão
(LEIC Tagus)
40
50
60
70
80
90
Quantile Plot
Displays all of the data (allowing the user to assess
both the overall behavior and unusual occurrences)
Plots quantile information
For a data xi data sorted in increasing order, fi indicates that
approximately 100 fi% of the data are below or equal to the
value xi
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Quantile Plot (example)
80
50
80
50
0.1
0.3
0.5
0.7
Quantis Ambos os sexos
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
0.9
Quantile-Quantile (Q-Q) Plot
Graphs the quantiles of one univariate
distribution against the corresponding quantiles
of another
Allows the user to view whether there is a shift in
going from one distribution to another
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Q-Q Plot (example)
80
AS2025
70
60
50
40
40
50
60
AS1998
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
70
80
Scatter plot
Provides a first look at bivariate data to see
clusters of points, outliers, etc
Each pair of values is treated as a pair of
coordinates and plotted as points in the plane
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Scatter plot (example)
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Loess Curve
Adds a smooth curve to a scatter plot in order to
provide better perception of the pattern of dependence
Loess curve is fitted by setting two parameters: a
smoothing parameter, and the degree of the
polynomials that are fitted by the regression
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Positively and Negatively
Correlated Data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Not Correlated
Data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Preprocessing
Why preprocess the data?
Descriptive data summarization
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Why Data Preprocessing?
Data in the real world is dirty
incomplete: lacking attribute values, lacking certain
attributes of interest, or containing only aggregate data
noisy: containing errors or outliers (spelling, phonetic
and typing errors, word transpositions, multiple values
in a single free-form field)
e.g., Salary=“-10”
inconsistent: containing discrepancies in codes or
names (synonyms and nicknames, prefix and suffix
variations, abbreviations, truncation and initials)
2003/04
e.g., occupation=“”
e.g., Age=“42” Birthday=“03/07/1997”
e.g., Was rating “1,2,3”, now rating “A, B, C”
e.g., discrepancy between duplicate records
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Cleaning
Importance
“Data cleaning is one of the three biggest problems
in data warehousing”—Ralph Kimball
“Data cleaning is the number one problem in data
warehousing”—DCI survey
Data cleaning tasks
Fill in missing values
Identify outliers and smooth out noisy data
Correct inconsistent data
Resolve redundancy caused by data integration
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Cleaning
Importance
“Data cleaning is one of the three biggest problems
in data warehousing”—Ralph Kimball
“Data cleaning is the number one problem in data
warehousing”—DCI survey
Data cleaning tasks
Fill in missing values
Identify outliers and smooth out noisy data
Correct inconsistent data
Resolve redundancy caused by data integration
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Missing Data
Data is not always available
2003/04
Ex: many tuples have no recorded value for several attributes,
such as customer income in sales data
Missing data may be due to
equipment malfunction
inconsistent with other recorded data and thus deleted
data not entered due to misunderstanding
certain data may not be considered important at the time of
entry
not register history or changes of the data
Missing data may need to be inferred.
Sistemas de Apoio à Decisão
(LEIC Tagus)
How to Handle Missing Data?
Ignore the tuple
not effective when the percentage of missing values per attribute varies
considerably.
Fill in the missing value manually
tedious + infeasible whith large data sets
Fill in it automatically with
a global constant : e.g., “unknown”; not recommended
the attribute mean
the attribute mean for all samples belonging to the same class: smarter
the most probable value: inference-based such as Bayesian formula or
decision tree
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Noisy Data
Noise: random error or variance in a measured
variable
Incorrect attribute values may due to
faulty data collection instruments
data entry problems
data transmission problems
technology limitation
inconsistency in naming convention
Other data problems which requires data cleaning
2003/04
duplicate records
incomplete data
inconsistent dataSistemas de Apoio à Decisão
(LEIC Tagus)
How to Handle Noisy Data?
Binning
first sort data and partition into (equal-frequency) bins
then one can smooth by bin means, smooth by bin
median, smooth by bin boundaries, etc.
Clustering
detect and remove outliers
Combined computer and human inspection
detect suspicious values and check by human (e.g.,
deal with possible outliers)
Regression
2003/04
smooth by fitting the data into regression functions
Sistemas de Apoio à Decisão
(LEIC Tagus)
Simple Discretization Methods:
Binning
Equal-width (distance) partitioning:
Divides the range into N intervals of equal size:
uniform grid
if A and B are the lowest and highest values of the
attribute, the width of intervals will be: W = (B –A)/N.
The most straightforward, but outliers may dominate
presentation
Skewed data is not handled well.
Equal-depth (frequency) partitioning:
2003/04
Divides the range into N intervals, each containing
approximately the same number of samples
Good data scaling
Sistemas de Apoio à Decisão
Managing categorical
attributes can be tricky.
(LEIC Tagus)
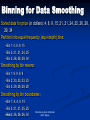
Binning for Data Smoothing
Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28,
29, 34
Partition into equal-frequency (equi-depth) bins:
- Bin 1: 4, 8, 9, 15
- Bin 2: 21, 21, 24, 25
- Bin 3: 26, 28, 29, 34
Smoothing by bin means:
- Bin 1: 9, 9, 9, 9
- Bin 2: 23, 23, 23, 23
- Bin 3: 29, 29, 29, 29
Smoothing by bin boundaries:
- Bin 1: 4, 4, 4, 15
- Bin 2: 21, 21, 25, 25
-2003/04
Bin 3: 26, 26, 26, 34
Sistemas de Apoio à Decisão
(LEIC Tagus)
Cluster Analysis
Similar values are organized into groups
May be used to detect outliers
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Regression
Data can be smoothed by fitting it to a function
Ex: linear regression can be used so that one variable can be
used to predict the other
y
Y1
Y1’
y=x+1
X1
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
x
Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy
generation
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Integration
Data integration: Combines data from multiple sources
into a coherent store
Schema integration: Integrate metadata from different
sources
Entity identification problem: identify real world entities
from multiple data sources, e.g., A.cust-id B.cust-#
Also known as record linkage, duplicate elimination
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Related problems
Detecting and resolving data value conflicts
For the same real world entity, attribute values from different
sources are different
Possible reasons: different representations, different scales,
e.g., metric vs. British units
Redundant data occur often when integrating multiple
databases
Derivable data: One attribute may be a “derived” attribute in
another table, e.g., annual revenue
Redundant attributes may be able to be detected by
correlation analysis
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Correlation analysis
(for numerical data)
Correlation coefficient (also called Pearson’s product
moment coefficient)
rA, B
( A A)( B B ) ( AB) n A B
( n 1)AB
( n 1)AB
where n is the number of tuples, A and B are the respective means of A
and B, σA and σB are the respective standard deviation of A and B, and Σ(AB)
is the sum of the AB cross-product.
If rA,B > 0, A and B are positively correlated (A’s values
increase as B’s). The higher, the stronger correlation.
rA,B = 0: independent; rA,B < 0: negatively correlated
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Positively and Negatively
Correlated Data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Correlation Analysis
(for categorical data)
Χ2 (chi-square) test
2
(
Observed
Expected
)
2
Expected
The larger the Χ2 value, the more likely the variables
are related
The cells that contribute the most to the Χ2 value are
those whose actual count is very different from the
expected count
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Chi-Square: An Example
Play
chess
Not play
chess
Sum
(row)
Like science fiction
250(90)
200(360)
450
Not like science
fiction
50(210)
1000(840)
1050
Sum(col.)
300
1200
1500
Χ2 (chi-square) calculation (numbers in parenthesis are
expected counts calculated based on the data distribution
in the two categories)
(250 90) 2 (50 210) 2 (200 360) 2 (1000 840) 2
507.93
90
210
360
840
2
It shows that like_science_fiction and play_chess are
correlated in the group
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Transformation
Smoothing: remove noise from data
Aggregation: summarization, data cube construction
Generalization: concept hierarchy climbing
Normalization: scaled to fall within a small, specified
range
min-max normalization
z-score normalization
normalization by decimal scaling
Attribute/feature construction
New attributes constructed from the given ones
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Transformation
Smoothing: remove noise from data
Aggregation: summarization, data cube construction
Generalization: concept hierarchy climbing
Normalization: scaled to fall within a small,
specified range
min-max normalization
z-score normalization
normalization by decimal scaling
Attribute/feature construction
New attributes constructed from the given ones
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Normalization (for
numerical data)
min-max normalization
v minA
v'
(new _ maxA new _ minA) new _ minA
maxA minA
z-score normalization (μ: mean, σ:
standard deviation) v ' v
A
A
normalization by decimal scaling
Where j is the smallest integer such that Max(|ν’|) < 1
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
v
v' j
10
Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy
generation
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Reduction
A data warehouse may store terabytes of
data
Complex data analysis/mining may take a very
long time to run on the complete data set
Data reduction
Obtain a reduced representation of the data set
that is much smaller in volume but yet produce
the same (or almost the same) analytical results
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data reduction strategies
Data cube aggregation
Dimensionality reduction
Data compression
Numerosity reduction
remove unimportant attributes
fit data into models
Discretization and concept hierarchy generation
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Cube Aggregation
Multiple levels of aggregation in data cubes
Further reduce the size of data to deal with
Queries regarding aggregated information should
be answered using the smallest available cuboid
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Example of a Data Cube w/
materialized aggregate data
2Qtr
3Qtr
4Qtr
sum
U.S.A
Canada
Mexico
sum
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Country
TV
PC
VCR
sum
1Qtr
Date
Total annual sales
of TV in U.S.A.
Dimensionality
Reduction
Data sets may contain hundreds of attributes
Some are irrelevant or redundant
Feature selection (i.e., attribute subset selection):
2003/04
Select a minimum set of features such that the
probability distribution of the data classes given the
values for those features is as close as possible to the
original distribution given the values of all features
reduce # of patterns in the patterns, easier to understand
Sistemas de Apoio à Decisão
(LEIC Tagus)
Heuristic Feature
Selection Methods
There are 2d possible sub-features of d features
Several heuristic feature selection methods:
2003/04
Best single features under the feature independence
assumption: choose by statistical significance tests.
Stepwise feature selection
The best single-feature is picked first
Then next best feature condition to the first, ...
Stepwise feature elimination
Repeatedly eliminate the worst feature
Best combined feature selection and elimination
Decision tree induction
Sistemas de Apoio à Decisão
(LEIC Tagus)
Example of Decision Tree
Induction
Initial attribute set:
{A1, A2, A3, A4, A5, A6}
A4 ?
A6?
A1?
Class 1
>
2003/04
Class 2
Class 1
Reduced attribute set: {A1, A4, A6}
Sistemas de Apoio à Decisão
(LEIC Tagus)
Class 2
Data
Compression
Compressed
Data
Original Data
lossless
Original Data
Approximated
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Compression
(examples)
String compression
There are extensive theories and well-tuned algorithms
Typically lossless
But only limited manipulation is possible without
expansion
Audio/video compression
2003/04
Typically lossy compression, with progressive
refinement
Sometimes small fragments of signal can be
reconstructed without reconstructing the whole
Sistemas de Apoio à Decisão
(LEIC Tagus)
Wavelet Transformation (1)
Discrete wavelet transform (DWT): linear signal
processing
Transforms a data vector D into a numerically
different vector D’, with the same length, of
wavelet coefficients
Compressed approximation: store only a small
fraction of the strongest of the wavelet coefficients
Good results on sparse or skewed data and on
data with ordered attributes, can be applied to
multidimensional data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Wavelet
Transformation (2)
Similar to discrete Fourier transform (DFT), but
better lossy compression, localized in space
Method (hierarchical pyramid algo.):
Length, L, must be an integer power of 2 (padding with 0s, when
necessary)
Each transform has 2 functions: smoothing, difference
Applies to pairs of data, resulting in two sets of data of length L/2
Applies two functions recursively, until reaches the desired length
Wavelets coefficients are a selection of
the values obtained
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Haar2
Daubechie4
Principal Component Analysis
Given N data vectors from k-dimensions, find c
<= k orthogonal vectors that can be best used
to represent data
Each data vector is a linear combination of the c
principal component vectors
Works for numeric data only
Used when the number of dimensions is large,
computationally inexpensive, can be applied to
ordered and unordered attributes, can handle
sparse and skewed data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
PCA basic procedure
Input data are normalized
Computes c orthogonal and unit vectors –
principal components
Attributes w/ large domains do not dominate attributes
w/ smaller domains
Input data is a linear combination
Principal components sorted according to
decreasing strength (variance among the data)
Size of data is reduced by eliminating the
weaker components (w/ lower variance)
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Principal Component Analysis
X2
Y1
Y2
X1
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Numerosity Reduction
Parametric methods
Assume the data fits some model, estimate model
parameters, store only the parameters, and discard
the data (except possible outliers)
Non-parametric methods
Do not assume models
Major families: histograms, clustering, sampling
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Regression Models
Linear regression: Data are modeled to fit a straight line
Y=+X
Two parameters , and specify the line and are to be estimated by using
the data at hand.
using the least squares criterion to the known values of Y1, Y2, …, X1, X2,
….
Often uses the least-square method to fit the line
Multiple regression: allows a response variable Y to be modeled as
a linear function of a multidimensional feature vector
Y = b0 + b1 X1 + b2 X2.
Many nonlinear functions can be transformed into the above.
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Histograms (example)
100
100
Ambos os sexos 2025
Ambos os sexos 1998
80
80
60
60
40
40
20
20
0
0
30
2003/04
40
50
60
70
80
90
30
Sistemas de Apoio à Decisão
(LEIC Tagus)
40
50
60
70
80
90
Histograms
A popular data reduction technique, uses binning
to approximate data distributions
Divides data into buckets and stores average
frequency for each bucket
Different partitioning rules: equal-width, equalfrequency, V-optimal, max-diff
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Cluster Analysis
Similar values are organized into groups
May be used to detect outliers
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Clustering
Partition data set into clusters, and one can store
cluster representation only
Cluster quality can be measured by its diameter or the
centroid distance
Can have hierarchical clustering and be stored in
multi-dimensional index tree structures
There are many choices of clustering definitions and
clustering algorithms, further detailed in Chapter 8
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Sampling
Allows a mining algorithm to run in complexity that is
potentially sub-linear to the size of the data
Choose a representative subset of the data
Proportional to the sample size
Simple random sampling may have very poor performance
in the presence of skew
Develop adaptive sampling methods
Stratified sampling:
Approximate the percentage of each class (or
subpopulation of interest) in the overall database
Used in conjunction with skewed data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Sampling
Raw Data
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Sampling
Raw Data
2003/04
Cluster/Stratified Sample
Sistemas de Apoio à Decisão
(LEIC Tagus)
Data Preprocessing
Why preprocess the data?
Data cleaning
Data integration and transformation
Data reduction
Discretization and concept hierarchy generation
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Discretization
Three types of attributes:
Nominal — values from an unordered set
Ordinal — values from an ordered set
Continuous — real numbers
Discretization:
2003/04
Divide the range of a continuous attribute into
intervals
Interval labels used to replace actual values
Some classification algorithms only accept
categorical attributes.
Reduce data sizeSistemas
by discretization
de Apoio à Decisão
(LEIC Tagus)
Discretization and
Concept hierachy
Discretization
reduce the number of values for a given continuous
attribute by dividing the range of the attribute into
intervals.
Concept hierarchies
2003/04
reduce the data by collecting and replacing low level
concepts (such as numeric values for the attribute
age) by higher level concepts (such as young,
middle-aged, or senior)
Sistemas de Apoio à Decisão
(LEIC Tagus)
Discretization techniques
Supervised/unsupervised: if discretization process
explores class information
Top-down (splitting): finds one or a few points to
split the entire range of the attribute and then
does it recursively
Bottom-up (merging): starts at all the continuous
values, merges neighborhood values into
intervals and performs recursive merges
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Discretization and Concept
Hierarchy Generation for
Numeric Data
Binning
Histogram analysis
Clustering analysis
Entropy-based discretization
Segmentation by natural partitioning
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Entropy-Based
Discretization (1)
Given a set of samples S, if S is partitioned into
two intervals S1 and S2 using boundary T, the
information gain after partitioning is
I (S , T )
| S1 |
|S |
Entropy( S1) 2 Entropy( S 2)
|S|
|S|
Entropy is calculated based on class distribution of
the samples in the set. Given m classes, the
entropy of S1 is
m
Entropy( S1 ) pi log 2 ( pi )
i 1
where pi is the probability of class i in S1
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Entropy-Based
Discretization (2)
The boundary that minimizes the entropy function
over all possible boundaries is selected as a binary
discretization
The process is recursively applied to partitions
obtained until some stopping criterion is met
Such a boundary may reduce data size and
improve classification accuracy
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Interval Merge by
2
Analysis
Merging-based (bottom-up)
Finds the best neighboring intervals and merge
them to form larger intervals recursively
ChiMerge
Initially, each distinct value of a numerical attribute A is
considered to be one interval
2 tests are performed for every pair of adjacent intervals
Adjacent intervals with the least 2 values are merged
together
This merge process proceeds recursively until a
predefined stopping criterion is met (such as significance
level, max-interval,Sistemas
maxdeinconsistency,
etc.)
Apoio à Decisão
2003/04
(LEIC Tagus)
Segmentation by
Natural Partitioning
A simply 3-4-5 rule can be used to segment numeric
data into relatively uniform, “natural” intervals
If an interval covers 3, 6, 7 or 9 distinct values at the most
significant digit, partition the range into 3 equi-width
intervals
If it covers 2, 4, or 8 distinct values at the most significant
digit, partition the range into 4 intervals
If it covers 1, 5, or 10 distinct values at the most significant
digit, partition the range into 5 intervals
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Example of 3-4-5 Rule
count
Step 1:
Step 2:
-$351
-$159
profit
Min
Low (i.e, 5%-tile)
Max
msd=1,000
Low=-$1,000 High=$2,000
(-$1,000 - 0)
(-$400 - 0)
(0 - $1,000)
(0 -
(-$200 -$100)
(-$100 2003/04
0)
High(i.e, 95%-0 tile)
(0 -$ 1,000)
($1,000 - $2,000)
(-$4000 -$5,000)
Step 4:
(-$300 -$200)
$4,700
(-$1,000 - $2,000)
Step 3:
(-$400 -$300)
$1,838
$200
($200 ) $400)
($400 $600)
($600 $800)
($1,000 - $2, 000)
($1,00
0($1,200 $1,200
$1,400)
) ($1,400 $1,600)
($1,600 ($1,800 ($800 $1,800)
$2,000)
$1,000) Sistemas de Apoio à Decisão
(LEIC Tagus)
($2,000 - $5, 000)
($2,000 $3,000)
($3,000 $4,000)
($4,000
$5,000)
Concept Hierarchy Generation
for Categorical Data
Specification of a partial ordering of attributes
explicitly at the schema level by users or experts
street<city<state<country
Specification of a portion of a hierarchy by explicit
data grouping
{Urbana, Champaign, Chicago}<Illinois
Specification of a set of attributes
System automatically generates partial ordering by
analysis of the number of distinct values
E.g., street < city <state < country
Specification of only a partial set of attributes
E.g., only street < city, not others
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)
Automatic Concept
Hierarchy Generation
Some concept hierarchies can be automatically
generated based on the analysis of the number of
distinct values per attribute in the given data set
The attribute with the most distinct values is placed at the
lowest level of the hierarchy
Note: Exception—weekday, month, quarter, year
15 distinct values
country
2003/04
province_or_ state
65 distinct values
city
3567 distinct values
street
674,339 distinct values
Sistemas de Apoio à Decisão
(LEIC Tagus)
Bibliografia
(Livro) Data Mining: Concepts and
Techniques, J. Han & M. Kamber, Morgan
Kaufmann, 2001 (Capítulo 3 – livro 2001,
Capítulo 2 – draft)
(Relatório) Expectativa de vida ao nascer, por
Região, País e Sexo: 1998 e 2025, Lurdes
Jesus, FCUL, 2003
2003/04
Sistemas de Apoio à Decisão
(LEIC Tagus)