Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
From Association Analysis to
Causal Discovery
Prof Jiuyong Li
University of South Australia
Association analysis
• Diapers -> Beer
• Bread & Butter -> Milk
Positive correlation of birth rate to
stork population
• increasing the stork population would increase
the birth rate?
Further evidence for Causality ≠ Associations
Simpson paradox
Recovered
Not recovered Sum
Recover rate
Drug
20
20
40
50%
No Drug
16
24
40
40%
36
44
80
Female
Recovered
Not recovered Sum
Recover rate
Drug
2
8
10
20%
No Drug
9
21
30
30%
11
29
40
Male
Recovered
Not recovered Sum
Recover rate
Drug
18
12
30
60%
No Drug
7
3
10
70%
25
15
40
Association and Causal Relationship
• Two variables X and Y.
• Prob(Y | X) ≠ P(Y), X is associated with Y (association
rules)
• Prob(Y | do X) ≠ Prob(Y | X)
• How does Y vary when X changes?
• The key, How to estimate Prob(Y | do X)?
• In association analysis, the relationship of X and Y
is analysed in isolation.
• However, the relationship between X and Y is
affected by other variables.
5
Causal discovery 1
• Randomised
controlled trials
– Gold standard
method
– Expensive
– Infeasible
• Association =
causation
Causal discovery 2
• Bayesian network based
causal inference
– Do-calculus (Pearl 2000)
– IDA (Maathuis et al.
2009)
– To infer causal effects in
a Bayesian network.
– However
– Constructing a Bayesian
network is NP hard
– Low scalability to large
number of variables
Leaning causal structures
• PC algorithm (Spirtes,
Glymour and Scheines)
– Not (A ╨ B | Z), there is an
edge between A and B.
– The search space
exponentially increases with
the number of variables.
CCC
B
A
ABC, ABC, CAB
• Constraint based search
– CCC (G. F. Cooper, 1997)
– CCU (C. Silverstein et. al.
2000)
– Efficiently removing noncausal relationships.
C
CCU
B
A
C
ABC
Association rules
• Many efficient
algorithms
• Hundreds of
thousands to millions
of rules.
– Many are spurious.
• Interpretability
– Association rules do
not indicate causal
effects.
Causal rules
• Discover causal relationships using partial association
and simulated cohort study.
• Do not rely on Bayesian network structure learning.
The discovery of causal rules also have strong
theoretical support.
• Discover both single cause and combined causes.
• Can be discovered efficiently.
• Z. Jin, J. Li, L. Liu, T. D. Le, B. Sun, and R. Wang,
Discovery of causal rules using partial association.
ICDM, 2012
• J. Li, T. D. Le, L. Liu, J. Liu, Z. Jin, and B. Sun. Mining
causal association rules. In Proceedings of ICDM
Workshop on Causal Discovery (CD), 2013.
Problem
Discover causal rules from large databases of binary variables
A
B
C
D
E
F
Y
#repeats
1
1
1
1
1
1
1
14
1
0
1
1
1
1
1
8
1
1
0
1
0
1
1
15
0
1
1
1
1
1
1
8
0
1
0
0
0
0
0
5
0
0
0
0
1
0
1
6
1
0
0
0
0
1
0
4
1
0
1
1
1
0
0
3
0
1
0
1
1
0
0
3
0
1
0
0
1
0
0
5
AY
CY
BF Y
DE Y
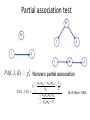
Partial association test
K
K
I
I
J
J
I
K
J
PA(I, J, K) ³ ca2 Nonzero partial association
PA(I, J, K ) =
(| å
k
n11k n00k - n10k n01k 1 2
|- )
n××k
2
n1×k n.1k n0×k n×0k
å n2 (n -1)
××k
××k
k
M. W. Birch, 1964.
Partial association test – an example
A
B
C
D
E
F
Y
G
#repeat
1
1
1
1
1
1
1
0
14
1
0
1
1
1
1
1
0
8
1
1
0
1
0
1
1
0
15
0
1
1
1
1
1
1
0
8
0
1
0
0
0
0
0
0
5
0
0
0
0
1
0
1
0
6
1
0
0
0
0
1
0
0
4
1
0
1
1
1
0
0
0
3
1
1
1
1
0
1
1
1
3
0
1
0
0
1
0
0
0
5
n11k n00k n10k n01k 14 3 0 8
1.68
nk
25
4. Partial association test.
PA( X , Y , K )
(|
k
n11k n00k n10k n01k 1 2
| )
nk
2
n1k n.1k n0k n0 k
k n2 (n 1)
k k
PA( BF , Y , ACDE )
n1k n.1k n0k n0 k 14 22 11 3
0.6776
n2k (nk 1)
252 (25 1)
Fast partial association test
PA(I, J, K ) =
(| å
k
n11k n00 k - n10 k n01k
1
| - )2
n××k
2
n n.1k n0×k n×0 k
å n1×k2 (n
××k
××k -1)
k
• K denotes all possible variable combinations,
the number is very large.
• Counting the frequencies of the combinations
is also time consuming.
• Our solution:
– Sort data and count frequencies of the
equivalence classes.
– Only use the combinations existing in the data set.
Pruning strategies
Definition (Redundant causal rules):
Assume that X⊂ W, if X → Y is a causal rule,
rule W → Y is redundant as it does not provide
new information.
Definition (Condition for testing causal rules):
We only test a combined causal rule XV → Y if
X and Y have a zero association and V and Y
have a zero association (cannot pass the quisquare test in step 3).
A
B
D
E
1
1
1
0
1
1
0
1
1
1
1
1
0
1
0
0
0
0
0
0
0
1
0
0
0
xG
F
Algorithm
Y
#repeats
1
14
1
8
1
15
0
1
8
0
0
0
5
1
0
0
1
6
0
1
0
0
4
0
0
3
1
zero
0
1
1
1 0
association
1
1
1
1 1
1
0
3
0
1
0
0
5
1
C
1
1
1 1 0
positive
1
1
1 1 0
association
0
1
0 1 0
0
0
1
0
Y=1
Y=0
Total
11
12
1.
X=0
n21
n22
n2.
Total
n.1
n.2
n
2
PA
(
X
,
Y
,
K
)
X=1
n
n
n
2
X ,Y
i 2, j 2
i 1, j 1
(nij E (nij ))
E (nij )
2
1. Prune the variable set (support)
2. Create the contingency table
for each variable X
X2 , Y
3. Calculate the
• If X2 , Y 2 go to next step
2
2
• If X , Y move X to a set N
4. Partial association test.
• If PA(X, Y, K) is nonzero
then XY is a causal rule.
5. Repeat 1-4 for each variable
which is the combination of
variables in set N
Experimental evaluations
• We use the Arrhythmia data set in UCI machine learning
repository.
– We need to classify the presence and absence of cardiac arrhythmia.
The data set contains 452 records and each record obtains 279 data
attributes and one class attribute
• Our results are quite consistent with the results from CCC
method.
• Some rules in CCC are removed by our method as they cannot
pass the partial association test.
• Our method can discover the combined rules. CCC and CCU
methods are not set to discover these rules.
Comparison with CCC and CCU
Experimental evaluations
Figure 1: Extraction Time Comparison (20K Records)
Figure 1: Extraction Time Comparison (100K Records)
Summary 1
• Simpson paradox
– Associations might be inconsistent in subsets
• Partial association test
– Test the persistency of associations in all possible
partitions.
– Statistically sound.
– Efficiency in sparse data.
• What else?
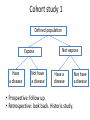
Cohort study 1
Defined population
Expose
Have
a disease
Not have
a disease
Not expose
Have a
disease
• Prospective: follow up.
• Retrospective: look back. Historic study.
Not have
a disease
Cohort study 2
• Cohorts: share common characteristics but
exposed or not exposed.
• Determine how the exposure causes an
outcome.
• Measure: odds ratio = (a/b) / (c/d)
Diseased Healthy
Exposed
a
b
Not exposed
c
d
Limitations of cohort study
• Need to know a hypothesis beforehand
• Domain experts determine the control
variables.
• Collect data and test the hypothesis.
• Not for data exploration.
• We need
– Given a data set without any hypotheses.
– An automatic method to find and validate
hypotheses.
– For data exploration.
Control variables
Outcome
Cause
Other factors
• If we do not control covariates (especially those
correlated to the outcome), we could not
determine the true cause.
• Too many control variables result too few
matched cases in data.
– How many people with the same race, gender, blood
type, hair colour, eye colour, education level, ….
• Irrelevant variables should not be controlled.
– Eye colour may not relevant to the study.
Matches
• Exact matching
– Exact matches on all covariates. Infeasible.
• Limited exact matching
– Exact matches on a few key covariates.
• Nearest neighbour matching
– Find the closest neighbours
• Propensity score matching
– Based on the predicted effect of a treatment of
covariates.
Method1
Discover causal association rules from large databases of
binary variables
AY
A
B
C
D
E
F
Y
1
1
1
1
1
1
1
A
B
C
D
E
F
Y
1
0
1
1
1
1
1
1
1
1
1
1
1
1
1
1
0
1
0
1
1
1
0
1
0
1
1
1
0
1
1
1
1
1
1
1
1
0
1
0
1
0
0
1
0
0
0
0
0
1
0
1
0
1
0
0
0
0
0
0
1
0
1
1
0
0
0
0
1
0
0
1
1
1
1
1
0
1
0
1
1
1
0
0
0
0
1
0
1
1
0
0
1
0
1
1
0
0
0
1
0
1
0
1
1
0
1
0
0
1
0
0
0
0
1
0
1
0
1
Fair dataset
Methods
• A: Exposure variable
Fair dataset
A B C D E F Y
1
1
1
1
1
1
1
1
0
1
0
1
1
1
1
1
0
1
0
1
0
1
0
1
0
1
0 0
• {B,C,D,E,F}: controlled variable set.
• Rows with the same color for the
controlled variable set are called
matched record pairs.
A=0
0
1
1
1
1
1
0
0
0
1
0
1
1
0
0
1
0
1
0
1
1
0
0
1
0
1
0
1
A=1
Y=1
Y=0
Y=1
n11
n12
Y=0
n21
n22
n12
OddsRatioD f (A ® Y ) =
n21
• An association rule A Y is a causal association rule if:
OddsRatioD f ( A Y ) 1
Algorithm
A
B
C
D
E
xF
1
1
1
1
1
1
…
…
1
1
x
G
Y
0
1
A
B
C
D
E
Y
1
1
1
1
1
1
…
…
0
1
…
…
0
1
0
1
0
1
…
1
1
1
0
…
1. Remove irrelevant variables (support, local support, association)
For each association rule (e. g. A Y)
2. Find the exclusive variables of the exposure variable
(support, association), i.e. G, F.
The controlled variable set = {B, C, D, E}.
3. Find the fair dataset. Search for all matched record pairs
4. Calculate the odds-ratio to identify if the testing rule is causal
5. Repeat 2-4 for each variable which is the combination of
28
variables. Only consider combination
of non-causal factors.
Experimental evaluations
Experimental evaluations
CAR
Figure 1: Extraction Time Comparison (20K Records)
CCC
CCU
Experimental evaluations
Causality – Judea Pearl
X1
X2
5.2
…
Xn-1
Xn
7.5
6.5
5.2
5.6
7.2
6.6
5.3
…
…
…
…
5.4
7.1
7.1
5.7
5.7
6.9
6.9
5.8
…
+1
+0.8
Judea Pearl. Causality: Models, Reasoning, and Inference. Cambridge University Press, 2000.
32
Methods
• IDA
– Maathuis, H. M.,
Colombo, D., Kalisch,
M., and Buhlmann, P.
(2010). Predicting
causal effects in largescale systems from
observational data.
Nature Methods, 7(4),
247–249.
33
Conclusions
• Association analysis has been widely used in data mining,
but associations do not indicate causal relationships.
• Association rule mining can be adapted for causal
relationship discovery by combining some statistical
methods.
– Partial association test
– Cohort study
• They are efficient alternatives for causal Bayesian
network based methods.
• They are capable of finding combined causal factors.
Discussions
• Causality and classification
– Estimate prob (Y| do X) instead of prob (Y|X).
• Feature section versus controlled variable
selection.
• Evaluation of causes.
– Not classification accuracy
– Bayesian networks??
Research Collaborators
•
•
•
•
•
Jixue Liu
Lin Liu
Thuc Le
Jin Zhou
Bin-yu Sun
Thank you for listening
Questions please ??