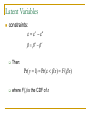Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Categorical Data Analysis
Week 2
Binary Response Models
binary and binomial responses
binary: y assumes values of 0 or 1
binomial: y is number of “successes” in n “trials”
distributions
Pr( y | p) p y (1 p)1 y
Bernoulli:
Binomial:
n y
Pr( y | n, p) p (1 p) n y
y
Transformational Approach
linear probability model
yi
use grouped data (events/trials): pi
ni
“identity” link: pi I (i ) xi
linear predictor: i xi
problems of prediction outside [0,1]
The Logit Model
logit transformation:
pi
logit( pi ) log
1 pi
i xi
inverse logit:
ensures that p is in [0,1] for all values of x
and .
exp(i )
pi
(i )
1 exp(i )
The Logit Model
odds and odds ratios are the key to
understanding and interpreting this model
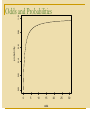
the log odds transformation is a “stretching”
transformation to map probabilities to the real
line
0.6
0.4
0.2
0.0
probability
0.8
1.0
Odds and Probabilities
0
5
10
15
odds
20
25
30
0.6
0.4
0.2
0.0
probability
0.8
1.0
Probabilities and Log Odds
-6
-4
-2
0
log(odds)
2
4
6
The Logit Transformation
0.6
0.8
1.0
properties of logit
linear
0.0
0.2
0.4
p
-6
-4
-2
0
logit
2
4
6
Odds, Odds Ratios, and Relative Risk
p
odds of “success” is the ratio:
1 p
consider two groups with success
probabilities:
p1 and p2
odds ratio (OR) is a measure of the odds of
success in group 1 relative to group 2
1 p1 / (1 p1 )
2 p2 / (1 p2 )
Odds Ratio
0
2 X 2 table:
50 20
ˆ
4.44
15 15
OR is the cross-product
ratio (compare x = 1 group
to x = 0 group)
odds of y = 1 are 4
times higher when x =1
than when x = 0
0
X
1
50
15
Y
1
15
20
Odds Ratio
equivalent interpretation
1 15 15
0.225
ˆ
50 20
odds of y = 1 are 0.225 times higher when x = 0 than
when x = 1
odds of y = 1 are 1-0.225 = .775 times lower when x = 0
than when x = 1
odds of y = 1 are 77.5% lower when x = 0 than when x =
1
Log Odds Ratios
Consider the model:
D is a dummy variable coded 1 if group 1 and 0
otherwise.
group 1: logit(pi ) 0
group 2: logit(pi ) 0
LOR:
logit( pi ) 0 Di
OR: exp( )
Relative Risk
similar to OR, but works with rates
D #Events
r
R Exposure
relative risk or rate ratio (RR) is the rate in
group 1 relative to group 2
r1
RR =
r2
OR RR as p 0 .
Tutorial: odds and odds ratios
consider the following data
Tutorial: odds and odds ratios
read table:
clear
input educ psex f
0 0 873
0 1 1190
1 0 533
1 1 1208
end
label define edlev 0 "HS or less" 1 "Col or more"
label val educ edlev
label var educ education
Tutorial: odds and odds ratios
compute odds:
tabodds psex educ [fw=f]
educ
HS or l~s
Col or ~e
cases
controls
odds
1190
1208
873
533
1.36312
2.26642
Test of homogeneity (equal odds): chi2(1)
Pr>chi2
=
=
55.48
0.0000
Score test for trend of odds:
=
=
55.48
0.0000
verify by hand
chi2(1)
Pr>chi2
[95% Conf. Interval]
1.24911
2.04681
1.48753
2.50959
Tutorial: odds and odds ratios
compute odds ratios:
tabodds psex educ [fw=f], or
educ
Odds Ratio
chi2
P>chi2
HS or l~s
Col or ~e
1.000000
1.662674
.
55.48
.
0.0000
Test of homogeneity (equal odds): chi2(1)
Pr>chi2
=
=
55.48
0.0000
Score test for trend of odds:
=
=
55.48
0.0000
verify by hand
chi2(1)
Pr>chi2
[95% Conf. Interval]
.
1.452370
.
1.903429
Tutorial: odds and odds ratios
stat facts:
variances of functions
use in statistical significance tests and forming
confidence intervals
basic rule for variances of linear transformations
g(x) = a + bx is a linear function of x, then
var[a bx] b2var ( x)
this is a trivial case of the delta method applied to a
single variable
the delta method for the variance of a nonlinear function
g(x) of a single variable is
2
g ( x)
var[ g ( x)]
var( x)
x
Tutorial: odds and odds ratios
stat facts:
variances of odds and odds ratios
we can use the delta method to find the variance in the
odds and the odds ratios
from the asymptotic (large sample theory) perspective it
is best to work with log odds and log odds ratios
the log odds ratio converges to normality at a faster rate
than the odds ratio, so statistical tests may be more
appropriate on log odds ratios (nonlinear functions of p)
2
1
ˆ
var(log )
var( pˆ )
pˆ (1 pˆ )
Tutorial: odds and odds ratios
stat facts:
the log odds ratio is the difference in the log odds for two
groups
groups are independent
variance of a difference is the sum of the variances
var(logˆ) var(log ˆ1 ) var(log ˆ 2 )
Tutorial: odds and odds ratios
data structures: grouped or individual level
note:
use frequency weights to handle grouped data
or we could “expand” this data by the frequency weights
resulting in individual-level data
model results from either data structures are the same
expand the data and verify the following results
expand f
Tutorial: odds and odds ratios
statistical modeling
logit model (glm):
glm psex educ [fw=f], f(b) eform
logit model (logit):
logit psex educ [fw=f], or
Tutorial: odds and odds ratios
statistical modeling (#1)
logit model (glm):
Generalized linear models
Optimization
: ML
Deviance
Pearson
=
=
No. of obs
Residual df
Scale parameter
(1/df) Deviance
(1/df) Pearson
4955.871349
3804
Variance function: V(u) = u*(1-u)
Link function
: g(u) = ln(u/(1-u))
[Bernoulli]
[Logit]
Log likelihood
AIC
BIC
= -2477.935675
psex
Odds Ratio
educ
1.662674
OIM
Std. Err.
.1138634
z
7.42
=
=
=
=
=
3804
3802
1
1.303491
1.000526
= 1.303857
= -26387.09
P>|z|
[95% Conf. Interval]
0.000
1.453834
1.901512
Tutorial: odds and odds ratios
statistical modeling (#2)
some ideas from alternative normalizations
gen cons = 1
glm psex cons educ [fw=f], nocons f(b) eform
what parameters will this model produce?
what is the interpretation of the “constant”
Tutorial: odds and odds ratios
statistical modeling (#2)
Generalized linear models
Optimization
: ML
Deviance
Pearson
=
=
No. of obs
Residual df
Scale parameter
(1/df) Deviance
(1/df) Pearson
4955.871349
3804
Variance function: V(u) = u*(1-u)
Link function
: g(u) = ln(u/(1-u))
[Bernoulli]
[Logit]
Log likelihood
AIC
BIC
= -2477.935675
psex
Odds Ratio
cons
educ
1.363116
1.662674
OIM
Std. Err.
.0607438
.1138634
z
6.95
7.42
=
=
=
=
=
3804
3802
1
1.303491
1.000526
= 1.303857
= -26387.09
P>|z|
[95% Conf. Interval]
0.000
0.000
1.249111
1.453834
1.487525
1.901512
Tutorial: odds and odds ratios
statistical modeling (#3)
gen lowed = educ == 0
gen hied = educ == 1
glm psex lowed hied [fw=f], nocons f(b) eform
what parameters does this model produce?
how do you interpret them?
Tutorial: odds and odds ratios
statistical modeling (#3)
Generalized linear models
Optimization
: ML
Deviance
Pearson
=
=
No. of obs
Residual df
Scale parameter
(1/df) Deviance
(1/df) Pearson
4955.871349
3804
Variance function: V(u) = u*(1-u)
Link function
: g(u) = ln(u/(1-u))
[Bernoulli]
[Logit]
Log likelihood
AIC
BIC
= -2477.935675
psex
Odds Ratio
lowed
hied
1.363116
2.266417
OIM
Std. Err.
.0607438
.1178534
are these odds ratios?
z
6.95
15.73
=
=
=
=
=
3804
3802
1
1.303491
1.000526
= 1.303857
= -26387.09
P>|z|
[95% Conf. Interval]
0.000
0.000
1.249111
2.046809
1.487525
2.509586
Tutorial: prediction
fitted probabilities (after most recent model)
predict p, mu
tab educ [fw=f], sum(p) nostandard nofreq
education
Summary of predicted
mean psex
Mean
Obs.
HS or les
Col or mo
.57682985
.69385409
2063
1741
Total
.63038905
3804
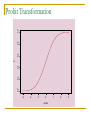
Probit Model
inverse probit is the CDF for a standard
normal variable:
p
1
e
2
1 2
u
2
link function:
probit(pi ) i 1 ( pi )
du
0.0
0.2
0.4
p
0.6
0.8
1.0
Probit Transformation
-3
-2
-1
0
probit
1
2
3
Interpretation
probit coefficients
interpreted as a standard normal variables (no log oddsratio interpretation)
“scaled” versions of logit coefficients
probit
3
logit
probit models
more common in certain disciplines (economics)
analogy with linear regression (normal latent variable)
more easily extended to multivariate distributions
Example: Grouped Data
Swedish mortality data revisited
logit model
y
Coef.
A2
A3
P2
_cons
.1147916
-.8384579
.5271214
-4.017514
OIM
Std. Err.
.21511
.2006439
.120775
.1922715
z
0.53
-4.18
4.36
-20.90
P>|z|
0.594
0.000
0.000
0.000
[95% Conf. Interval]
-.3068163
-1.231713
.2904068
-4.394359
.5363995
-.445203
.763836
-3.640669
probit model
y
Coef.
A2
A3
P2
_cons
.0497241
-.3247921
.2098432
-2.101865
OIM
Std. Err.
.087904
.0807731
.0472825
.0778879
z
0.57
-4.02
4.44
-26.99
P>|z|
0.572
0.000
0.000
0.000
[95% Conf. Interval]
-.1225646
-.4831045
.1171712
-2.254522
.2220128
-.1664797
.3025151
-1.949207
Swedish Historical Mortality Data
predictions
Logit
Probit
P
A
1
2
3
1
19.0
61.0
143.0
sum
P
2
10.0
32.0
60.0
325
A
1
2
3
1
19.1
61.9
141.1
sum
2
9.9
31.6
61.4
325.1
Programming
Stata: generalized linear model (glm)
glm y A2 A3 P2, family(b n) link(probit)
glm y A2 A3 P2, family(b n) link(logit)
idea of glm is to make model linear in the link.
old days: Iteratively Reweighted Least Squares
now: Fisher scoring, Newton-Raphson
both approaches yield MLEs
Generalized Linear Models
applies to a broad class of models
iterative fitting (repeated updating) except for linear model
update parameters, weights W, and predicted values m
( t 1)
1
XW X X(y mt )
t
t
models differ in terms of W and m and assumptions about
the distribution of y
common distributions for y include: normal, binomial, and
Poisson
common links include: identity, logit, probit, and log
Latent Variable Approach
example: insect mortality
suppose a researcher exposes insects to dosage levels (u)
of an insecticide and observes whether the “subject” lives
or dies at that dosage.
the response is expected to depend on the insect’s
tolerance (c) to that dosage level.
the insect dies if u > c and survives if u < c
Pr( yi 1) Pr(ui ci )
tolerance is not observed (survival is observed)
Latent Variables
u and c are continuous latent variables
examples:
women’s employment: u is the market wage and c is the
reservation wage
migration: u is the benefit of moving and c is the cost of
moving.
observed outcome y =1 or y = 0 reveals the
individual’s preference, which is assumed to
maximize a rational individual’s utility function.
Latent Variables
Assume linear utility and criterion functions
u ux u
c cx c
Pr( y 1) Pr(u c) Pr ( ) x
c
u
u
c
over-parameterization = identification problem
we can identify differences in components but not the
separate components
Latent Variables
constraints:
c u
u c
Then:
Pr( y 1) Pr( x) F ( x)
where F(.) is the CDF of ε
Latent Variables and Standardization
Need to standardize the mean and variance of ε
binary dependent variables lack inherent scales
magnitude of β is only in reference to the mean
and variance of ε which are unknown.
redefine ε to a common standard
*
a
b
where a and b are two chosen constants.
Standardization for Logit and Probit Models
standardization implies
xa
Pr( y 1) F *
b
F*() is the cdf of ε*
location a and scale b need to be fixed
setting
and
a
b
F * () () probit model
Standardization for Logit and Probit Models
distribution of ε is standardized
standard normal probit
standard logistic logit
both distributions have a mean of 0
variances differ
probit 2* 1
logit
2
*
2
3
Extending the Latent Variable Approach
observed y is a dichotomous (binary) 0/1 variable
continuous latent variable:
linear predictor + residual
y xi i
*
i
observed outcome
1 if yi* 0
yi
0 otherwise
Notation
conditional means of latent variables obtained from
index function:
E( yi* | xi ) xi
obtain probabilities from inverse link functions
logit model:
(xi ) i
probit model:
(xi ) i
ML
likelihood function
L F (xi ) 1 F (xi )
yi
( ni yi )
i
where ni 1 if data are binary
log-likelihood function
log L yi log F (xi ) (ni yi )log 1 F (xi )
i
Assessing Models
definitions:
L null model (intercept only): L0
L saturated model (a parameter for each cell): L f
L current model: Lc
grouped data (events/trials)
deviance (likelihood ratio statistic)
Lc
G 2log
L
f
2
2 log Lc logL f
Deviance
grouped data:
if cell sizes are reasonably large deviance is
distributed as chi-square
individual-level data: Lf =1 and log Lf =0
deviance is not a “fit” statistic
G 2 2logLc
Deviance
deviance is like a residual sum of squares
larger values indicate poorer models
larger models have smaller deviance
deviance for the more constrained model (Model 1)
G12
deviance for the less constrained model (Model 2)
G22
assume that Model 1 is a constrained version of
Model 2.
Difference in Deviance
evaluate competing “nested” models using a
likelihood ratio statistic
2
2
2
2
G G1 G2 df2 df1
model chi-square is a special case
Model 2 G02 Gc2 2log L0 (2log Lc )
SAS, Stata, R, etc. report different statistics
Other Fit Statistics
BIC & AIC (useful for non-nested models)
basic idea of IC : penalize log L for the number of
parameters (AIC/BIC) and/or the size of the
sample (BIC)
IC 2log L 2( s)(df m )
AIC s=1
BIC s= ½ log n (sample size)
dfm is the number of model parameters
Hypothesis Tests/Inference
single parameter: H0 : 0
MLE are asymptotically normal Z-test
multi-parameter:
H0 : 1 2 0
likelihood ratio tests (after fitting)
Wald tests (test constraints from current model)
Hypothesis Tests/Inference
Wald test (tests a vector of restrictions)
a set of r parameters are all equal to 0
H0 : r 0
a set of r parameters are linearly restricted
H 0 : R r q
restriction matrix
constraint vector
parameter subset
Interpreting Parameters
odds ratios: consider the model where x is a
continuous predictor and d is a dummy
variable
yi* 0 1 xi 2 di i
suppose that d denotes sex and x denotes
income and the problem concerns voting,
where y* is the propensity to vote
results: logit(pi) = -1.92 + 0.012xi + 0.67di
Interpreting Parameters
for d (dummy variable coded 1 for female) the odds ratio is
straightforward
f
exp( ˆ2 ) exp(0.67) 1.95
pm / (1 pm ) m
p f / (1 p f )
holding income constant, women’s odds of voting are
nearly twice those of men
Interpreting Parameters
for x (continuous variable for income in thousands of dollars) the
odds ratio is a multiplicative effect
suppose we increase income by 1 unit ($1,000)
exp[ ˆ1 ( x 1)]
exp[ 1 (1)] 1.01
exp( ˆ1 x)
suppose we increase income by c units (c х $1,000$
exp[ ˆ1 ( x c)]
exp[ 1 (c)]
ˆ
exp( 1 x)
Interpreting Parameters
if income is increased by $10,000, this increases the odds of
voting by about 13%
100.012
(e
1) 100% 12.75%
a note on percent change in odds:
if estimate of β > 0 then percent increase in odds for a unit change in
x is
ˆ
(e 1) 100%
if estimate of β < 0 then percent decrease in odds for a unit change in
x is
ˆ
(1 e ) 100%
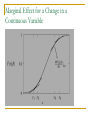
Marginal Effects
marginal effect:
effect of change in x on change in probability
Pr( yi 1| xi ) F ( xi )
f (xi ) k
xik
xik
f (·) pdf
F (·) cdf
often we evaluate f(.) at the mean of x.
Marginal Effect for a Change in a
Continuous Variable
Marginal Effect of a Change in a Dummy Variable
if x is a continuous variable and z is a dummy
variable
F (i )1 0 1 xi 2 zi
marginal effect of change in z from 0 to 1 is the
difference
F ( 0 1 xi 2 ) F ( 0 1 xi )
Example
logit models for high school graduation
odds ratios (constant is baseline odds)
LR Test
Model 3 vs. 2
(1) 2 2(log L2 log L3 )
2(1240.70 ( 1038.39))
2(1038.39 1240.70)
404.64
Wald Test
Test equality of parental education effects
H 0 : mhs fhs
H 0 : mcol fcol
logit hsg blk hsp female nonint inc nsibs mhs mcol fhs fcol wtest
test mhs=fhs
test mcol=fcol
( 1)
mhs - fhs = 0
chi2( 1) =
Prob > chi2 =
0.01
0.9177
. test mcol=fcol
( 1)
mcol - fcol = 0
chi2( 1) =
Prob > chi2 =
1.18
0.2770
cannot reject H of equal parental education effects on HS graduation
Basic Estimation Commands (Stata)
estimation commands
model tests
* model 0 - null model
qui logit hsg
est store m0
* model 1 - race, sex, family structure
qui logit hsg blk hsp female nonint
est store m1
* model 1a - race X family structure interactions
qui xi: logit hsg blk hsp female nonint i.nonint*i.blk i.nonint*i.hsp
est store m1a
lrtest m1 m1a
* model 2 - SES
qui xi: logit hsg blk hsp female nonint inc nsibs mhs mcol fhs fcol
est store m2
* model 3 - Indiv
qui xi: logit hsg blk hsp female nonint inc nsibs mhs mcol fhs fcol wtest
est store m3
lrtest m2 m3
Fit Statistics etc.
* some 'hand' calculations with saved results
scalar ll = e(ll)
scalar npar = e(df_m)+1
scalar nobs = e(N)
scalar AIC = -2*ll + 2*npar
scalar BIC = -2*ll + log(nobs)*npar
scalar list AIC
scalar list BIC
* or use automated fitstat routine
fitstat
*output as a table
estout1 m0 m1 m2 m3 using modF07, replace star stfmt(%9.2f %9.0f %9.0f) ///
stats(ll N df_m) eform
Analysis of Deviance
. lrtest m0 m1
Likelihood-ratio test
(Assumption: m0 nested in m1)
LR chi2(4) =
Prob > chi2 =
118.45
0.0000
LR chi2(6) =
Prob > chi2 =
283.71
0.0000
LR chi2(1) =
Prob > chi2 =
404.64
0.0000
. lrtest m1 m2
Likelihood-ratio test
(Assumption: m1 nested in m2)
. lrtest m2 m3
Likelihood-ratio test
(Assumption: m2 nested in m3)
BIC and AIC (using fitstat)
Measures of Fit for logit of hsg
Log-Lik Intercept Only:
D(3293):
-1441.781
2076.754
McFadden's R2:
ML (Cox-Snell) R2:
McKelvey & Zavoina's R2:
Variance of y*:
Count R2:
AIC:
BIC:
BIC used by Stata:
0.280
0.217
0.473
6.240
0.857
0.636
-24607.056
2173.993
Log-Lik Full Model:
LR(11):
Prob > LR:
McFadden's Adj R2:
Cragg-Uhler(Nagelkerke) R2:
Efron's R2:
Variance of error:
Adj Count R2:
AIC*n:
BIC':
AIC used by Stata:
-1038.377
806.807
0.000
0.271
0.372
0.252
3.290
0.096
2100.754
-717.672
2100.754
Marginal Effects
0
.2
.4
.6
.8
1
Marginal Effect of Test Score on High School Graduation
Income Quartile 1
-4
-2
0
Test Score
white/intact
black/intact
2
white/nonintact
black/nonintact
4
Marginal Effects
0
.2
.4
.6
.8
1
Marginal Effect of Test Score on High School Graduation
Income Quartile 4
-4
-2
0
Test Score
white/intact
black/intact
2
white/nonintact
black/nonintact
4
Generate Income Quartiles
qui sum adjinc, det
* quartiles for income distribution
gen incQ1 = adjinc < r(p25)
gen incQ2 = adjinc >= r(p25) & adjinc < r(p50)
gen incQ3 = adjinc >= r(p50) & adjinc < r(p75)
gen incQ4 = adjinc >= r(p75)
gen incQ = 1 if incQ1==1
replace incQ = 2 if incQ2==1
replace incQ = 3 if incQ3==1
replace incQ = 4 if incQ4==1
tab incQ
Fit Model for Each Quartile
calculate predictions
* look at marginal effects of test score on graduation by selected groups
* (1) model (income quartiles)
local i = 1
while `i' < 5 {
logit hsg blk female mhs nonint nsibs urban so wtest if incQ ==`i'
margeff
cap drop wm*
cap drop bm*
prgen wtest, x(blk=0 female=0 mhs=1 nonint=0) gen(wmi) from(-3) to(3)
prgen wtest, x(blk=0 female=0 mhs=1 nonint=1) gen(wmn) from(-3) to(3)
label var wmip1 "white/intact"
label var wmnp1 "white/nonintact"
prgen wtest, x(blk=1 female=0 mhs=1 nonint=0) gen(bmi) from(-3) to(3)
prgen wtest, x(blk=1 female=0 mhs=1 nonint=1) gen(bmn) from(-3) to(3)
label var bmip1 "black/intact"
label var bmnp1 "black/nonintact"
Graph
set scheme s2mono
twoway (line wmip1 wmix, sort xtitle("Test Score") ytitle("Pr(y=1)")) ///
(line wmnp1 wmix, sort) (line bmip1 wmix, sort) (line bmnp1 wmix, sort), ///
subtitle("Marginal Effect of Test Score on High School Graduation" ///
"Income Quartile `i'" ) saving(wtgrph`i', replace)
graph export wtgrph`i'.eps, as(eps) replace
local i = `i' + 1
}
Fitted Probabilities
logit hsg blk female mhs nonint inc nsibs urban so wtest
prtab nonint blk female
logit: Predicted probabilities of positive outcome for hsg
female and blk
0
1
nonint
0
1
0
1
0
1
0.9111
0.8329
0.9740
0.9480
0.9258
0.8585
0.9786
0.9569
Fitted Probabilities
predicted values
evaluate fitted probabilities at the sample mean
values of x (or other fixed quantities)
ˆ)
exp(
x
pˆ ( xˆ )
1 exp( xˆ )
averaging fitted probabilities over subgroupspecific models will produce marginal probabilities
1
ˆ
pˆ j (xij j )
nj
nj
y
i 1
j
Observed & Fitted Probabilities
sex
male
race
family type
intact
observed
fitted
n
nonintact
observed
fitted
n
Total
white
black
female
race
white
black
0.90
0.91
776
0.86
0.97
224
0.91
0.93
749
0.89
0.98
234
0.71
0.83
220
996
0.74
0.95
207
431
0.81
0.86
196
945
0.82
0.96
231
465
Alternative Probability Model
complementary log –log (cloglog or CLL)
standard extreme-value distribution for u:
f (u ) exp(u ) exp exp(u )
F (u ) 1 exp exp(u )
cloglog model:
Pr( yi 1) 1 exp exp(xi )
cloglog link function:
log log[1 Pr( yi 1)] xi
Extreme-Value Distribution
properties
mean of u (Euler’s constant): (1) 0.5772
2
variance of u:
6
difference in two independent extreme value
variables yields a logistic variable
u1 u2
logistic(0, 3 )
2
0.0
0.2
0.4
p
0.6
0.8
1.0
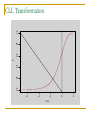
CLL Transformation
-6
-4
-2
CLL
0
2
CLL Model
no “practical” differences from logit and probit
models
often suited for survival data and other applications
interpretation of coefficients:
exp(β) is a relative risk or hazard ratio not an OR
glm: binomial distribution for y with a cloglog link
cloglog: use the cloglog command directly
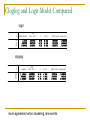
CLL and Logit Model Compared
logit
cloglog
blk
3.658***
1.987***
female
1.218
1.128*
mhs
1.438**
1.161*
nonint
0.487***
0.710***
inc
1.635**
1.236**
nsibs
0.938**
0.965**
urban
0.887
0.942
so
1.269
1.115
wtest
5.151***
2.171***
_cons
6.851***
1.891***
log L
-838.92
-833.96
N
2837
2837
df
9
9
Cloglog and Logit Model Compared
logit
d
Odds Ratio
A2
A3
P2
1.12164
.4323768
1.694049
OIM
Std. Err.
.2412759
.0867538
.2045987
z
0.53
-4.18
4.36
P>|z|
[95% Conf. Interval]
0.594
0.000
0.000
.7357857
.2917924
1.336971
1.709839
.6406942
2.146494
cloglog
d
exp(b)
A2
A3
P2
1.119414
.4350801
1.684947
OIM
Std. Err.
.2380893
.0864137
.2016957
z
0.53
-4.19
4.36
P>|z|
[95% Conf. Interval]
0.596
0.000
0.000
.7378156
.2947864
1.332581
more agreement when modeling rare events
1.698375
.642142
2.130487
Extensions: Multilevel Data
what is multilevel data?
individuals are “nested” in a larger context:
children in families, kids in schools etc.
context 1
context 2
context 3
Multilevel Data
i.i.d. assumptions?
the outcomes for units in a given context could be
associated
standard model would treat all outcomes
(regardless of context) as independent
multilevel methods account for the within-cluster
dependence
a general problem with binomial responses
we assume that trials are independent
this might not be realistic
non-independence will inflate the variance
(overdispersion)
Multilevel Data
example (in book):
40 universities as units of analysis
for each university we observe the number of graduates
(n) and the number receiving post-doctoral fellowships
(y)
we could compute proportions (MLEs)
some proportions would be “better” estimates as they
would have higher precision or lower variance
example: the data y1/n1 = 2/5 and y2/n2 = 20/50 give
identical estimates of p but variances of 0.048 and
0.0048 respectively
the 2nd estimate is more precise than the 1st
Multilevel Data
multilevel models allow for improved
predictions of individual probabilities
MLE estimate is unaltered if it is precise
MLE estimate moved toward average if it is
imprecise (shrinkage)
multilevel estimate of p would be a weighted average of
the MLE and the average over all MLEs (weight (w) is
based on the variance of each MLE and the variance
over all the MLEs)
pi pˆ i wi p (1 wi )
we are generally less interested in the p’s and more
interested in the model parameters and variance
components
Shrinkage Estimation
primitive approach
pˆ i
assume we have a set of estimates (MLEs)
our best estimate of the variance of each MLE is
pˆ i (1 pˆ i )
var( pˆ i )
ni
this is the within variance (no pooling)
if this is large, then the MLE is a poor estimate
a better estimate might be the average of the MLEs in this
case (pooling the estimates)
we can average the MLEs and estimate the between
variance as
1
var( p ) ( pˆ i p ) 2
N
Shrinkage Estimation
primitive approach
we can then estimate a weight wi
v ar( p )
between-group variance
wi
var( p ) var( pˆ i )
total variance
a revised estimate of pi would take account of the
precision to for a precision-weighted average
precision is a function of ni
more weight is given to more precise MLE’s
pi pˆ i wi p (1 wi )
Shrinkage: a primitive approach
0.6
0.4
0.2
observed and shrunken probabilities
0.8
Observed
Shrunken
0
10
20
university
30
40
Shrinkage
0.6
0.4
0.2
observed and EB probabilities
0.8
Observed
EB Estimate
0
10
20
university
results from full Bayesian (multilevel) Analysis
30
40
Extension: Multilevel Models
assumptions
within-context and between-context variation in
outcomes
individuals within the same context share the
same “random error” specific to that context
models are hierarchical
individuals (level-1)
contexts (level-2)
Multilevel Models: Background
linear mixed model for continuous y
(multilevel, random coefficients, etc.)
level-1 model and level-2 sub-models (hierarchical)
yij 0i 1i zij ij
0i 00 01 xi u0i
1i 10 11 xi u1i
Multilevel Models: Background
linear mixed model assumptions
level-1 and level-2 residuals
~ Normal(0, 2 )
0
u0
u ~ MVN 0 , u
1
where
02 01
u
2
1
01
Multilevel Models: Background
composite form
composite residual
yij 00 01 xi 10 zij 11 xi zij u0i zij u1i ij
fixed effects
cross-level interaction
random effects
(level-2)
Multilevel Models: Background
variance components
total:
var(u0i u1i zij ij )
within group:
var( ij )
between group: var(u0i u1i zij )
Multilevel Models: Background
general form (linear mixed model)
yij xij zij ui ij
variables associated with
fixed coefficients
variables associated with
random coefficients
Multilevel Models: Logit Models
binomial model (random effect)
logit( pij ) xij ui
assumptions
ui ~ Normal(0, u2 )
u increases or decreases the expected response for
individual j in context i independently of x
all individuals in context i share the same value of u
also called a random intercept model
0i 0 ui
Multilevel Models
a hierarchical model:
logit( pij )= 0i 1 zij
and
0i 00 01 xi ui
z is a level-1 variable; x is a level-2 variable
random intercept varies among level-2 units
note: level-1 residual variance is fixed (why?)
Multilevel Models
a general expression
logit( pij ) xij zij ui
x are variables associated with “fixed” coefficients
z are variables associated with “random” coefficients
u is multivariate normal vector of level-2 residuals
mean of u is 0; covariance of u is u
Multilevel Models
random effects vs. random coefficients
variance components
random effects u
random coefficients β + u
interested in level-2 variation in u
prediction
E(y) is not equal to E(y|u)
model based predictions need to consider random
effects
E( yij | ui , xij ) (xij ui )
Multilevel Models: Generalized Linear Mixed Models
(GLMM)
Conditional Expectation
E( yij | ui , xij ) (xij ui )
Marginal Expectation
E( yij | xij ) E[E( yij | ui , xij )]
(xij ui ) g (u )du
u
requires numerical integration or simulation
Data Structure
multilevel data structure
requires a “context” id to identify individuals belonging to
the same context
NLSY sibling data contains a “family id” (constructed by researcher)
data are unbalanced (we do not require clusters to be the
same size)
small clusters will contribute less information to the
estimation of variance components than larger clusters
it is OK to have clusters of size 1
(i.e., an individual is a context unto themselves)
clusters of size 1 contribute to the estimation of fixed
effects but not to the estimation of variance components
Example: clustered data
siblings nested in families
y is 1st premarital birth for NLSY women
select sib-ships of size > 2
null model (random intercept):
xtlogit fpmbir, i(famid)
or
xtmelogit fpmbir || famid:
Example: clustered data
random intercept: xtlogit
Log likelihood
= -228.59345
Prob > chi2
fpmbir
Coef.
Std. Err.
_cons
-2.888895
.3318566
/lnsig2u
1.083066
sigma_u
rho
1.71864
.4730808
z
-8.71
P>|z|
.
[95% Conf. Interval]
-3.539322
-2.238468
.3992351
.30058
1.865553
.3430707
.0995195
1.162171
.2910546
2.541556
.662556
Likelihood-ratio test of rho=0: chibar2(01) =
0.000
=
20.58 Prob >= chibar2 = 0.000
Example: clustered data
random intercept: xtmelogit
Integration points =
7
Log likelihood = -228.51781
fpmbir
Coef.
_cons
-2.917541
Random-effects Parameters
Wald chi2(0)
Prob > chi2
Std. Err.
.3479598
z
-8.38
=
=
.
.
P>|z|
[95% Conf. Interval]
0.000
-3.59953
-2.235552
Estimate
Std. Err.
[95% Conf. Interval]
1.752456
.3601534
1.171423
famid: Identity
sd(_cons)
LR test vs. logistic regression: chibar2(01) =
2.621685
20.73 Prob>=chibar2 = 0.0000
Variance Component
add predictors (mostly level-2)
Integration points =
7
Log likelihood = -215.39646
fpmbir
Odds Ratio
nonint
nsibs
medu
inc
consprot
weekly
3.356608
1.112501
.8050785
.8848917
1.614657
.885648
Random-effects Parameters
Wald chi2(6)
Prob > chi2
Std. Err.
1.435222
.1032876
.060073
.2858459
.6110603
.296273
z
2.83
1.15
-2.91
-0.38
1.27
-0.36
=
=
22.48
0.0010
P>|z|
[95% Conf. Interval]
0.005
0.251
0.004
0.705
0.206
0.717
1.451921
.9274119
.6955425
.4698153
.7690355
.4597391
7.759938
1.33453
.9318647
1.666683
3.390111
1.706125
Estimate
Std. Err.
[95% Conf. Interval]
1.451511
.3515003
.9030084
famid: Identity
sd(_cons)
2.333182
Variance Component
conditional variance in u is 2.107
proportionate reduction in error (PRE)
3.062 2.107
PRE
0.312
2
u
3.062
2
ur
2
uc
r
a 31% reduction in level-2 variance when level-2
predictors are accounted for
Random Effects
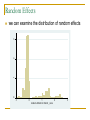
we can examine the distribution of random effects
0
1
Density
2
3
-1
0
1
2
random effects for famid: _cons
3
Random Effects
we can examine the distribution of random effects
. sum u, detail
random effects for famid: _cons
1%
5%
10%
25%
Percentiles
-.7111417
-.5100672
-.388522
-.2422871
50%
-.1484184
75%
90%
95%
99%
-.0689377
1.337971
1.523062
2.405483
Smallest
-.9210778
-.9210778
-.8339383
-.8339383
Largest
2.431446
2.431446
2.583755
2.583755
Obs
Sum of Wgt.
653
653
Mean
Std. Dev.
.1132598
.7006756
Variance
Skewness
Kurtosis
.4909462
1.688026
4.818971
Random Effects Distribution
90th percentile u90 = 1.338
10th percentile u10 = 0.388
the risk for family at 90th percentile is
exp(1.338 – 0.388) = 2.586
times higher than for a family at the 10th percentile
even if families are compositionally identical on
covariates, we can assess the hypothetical
differential in risks
Growth Curve Models
growth models
individuals are level-2 units
repeated measures over time on individuals
(level-1)
models imply that logits vary across individuals
intercept (conditional average logit) varies
slope (conditional average effect of time) varies
change is usually assumed to be linear
use GLMM
complications due to dimensionality
intercept and slope may co-vary (necessitating a more
complex model) and more
Growth Curve Models
multilevel logit model for change over time
logit( pij ) 0i 1iTij
T is time (strictly increasing)
fixed and random coefficients (with covariates)
logit( pij ) 0i 1iTij
0i 00 01 X i u0i
1i 10 11 X i u1i
assume that u0 and u1 are bivariate normal
Multilevel Logit Models for Change
Example: Log odds of employment of black
men in the U.S. 1982-1988 (NLSY)
(consider 5 years in this period)
time is coded 0, 1, 3, 4, 6
dependent variable is: not-working, not-in-school
unconditional growth (no covariates except T)
conditional growth (add covariates)
note: cross-level interactions implied by composite
model
logit( pij ) 00 01 X 10Tij 11Tij X i u0i u1iTij
Fitting Multilevel Model for Change
programming
Stata (unconditional growth)
xtmelogit y year || id: year, var cov(un)
Stata (conditional growth)
xtmelogit y year south unem unemyr inc hs ||id: year, var cov(un)
Fitting Multilevel Model for Change
Mixed-effects logistic regression
Group variable: id
Number of obs
Number of groups
Integration points =
7
Log likelihood = -1916.0409
y
Coef.
year
_cons
-.1467877
-.8742502
=
=
3430
686
Obs per group: min =
avg =
max =
5
5.0
5
Wald chi2(1)
Prob > chi2
Std. Err.
.0293921
.0972809
Random-effects Parameters
z
P>|z|
-4.99
-8.99
Estimate
0.000
0.000
=
=
24.94
0.0000
[95% Conf. Interval]
-.2043952
-1.064917
-.0891801
-.6835831
Std. Err.
[95% Conf. Interval]
.0241599
.4330881
.0789636
.0234654
1.120075
-.206505
id: Unstructured
var(year)
var(_cons)
cov(year,_cons)
LR test vs. logistic regression:
.0552714
1.796561
-.0517392
chi2(3) =
250.61
.1301886
2.881622
.1030266
Prob > chi2 = 0.0000
Fitting Multilevel Logit Model for Change
Mixed-effects logistic regression
Group variable: id
Number of obs
Number of groups
Integration points =
7
Log likelihood = -1868.0104
y
Coef.
year
south
unem
unemyr
inc
hs
_cons
-.0921512
-.6523682
1.014915
-.1120936
-.5732738
-.785545
-.0612559
=
=
3430
686
Obs per group: min =
avg =
max =
5
5.0
5
Wald chi2(6)
Prob > chi2
Std. Err.
.0281795
.1283314
.2408795
.0641975
.1872211
.1242026
.1285939
Random-effects Parameters
z
P>|z|
-3.27
-5.08
4.21
-1.75
-3.06
-6.32
-0.48
Estimate
0.001
0.000
0.000
0.081
0.002
0.000
0.634
Std. Err.
=
=
123.80
0.0000
[95% Conf. Interval]
-.1473819
-.9038931
.5428002
-.2379184
-.9402205
-1.028978
-.3132954
-.0369205
-.4008434
1.48703
.0137313
-.2063271
-.5421124
.1907836
[95% Conf. Interval]
id: Unstructured
var(year)
var(_cons)
cov(year,_cons)
LR test vs. logistic regression:
.0433477
1.304833
-.0622441
.0219905
.3648705
.0708861
chi2(3) =
140.20
.016038
.7542816
-.2011783
.1171612
2.257233
.07669
Prob > chi2 = 0.0000
Logits: Observed, Conditional, and Marginal
the log odds of idleness decreases with time and shows variation in level and change
Composite Residuals in a Growth Model
composite residual
rij u0i u1iTij ij
composite residual variance
var(rij ) 02 T j2 12 2T j 01
2
3
covariance of composite residual
cov(rij , rij ) 02 T jT j 12 (T j T j ) 01
Model
covariance term is 0 (from either model)
results in simplified interpretation
easier estimation via variance components (default option)
significant variation in slopes and initial levels
other results:
log odds of idleness decrease over time (negative slope)
other covariates except county unemployment have significant
effects on the odds of idleness
the main effects are interpreted as effects on initial logits at time 1
or t = 0 or the 1982 baseline)
interaction of time and unemployment rate captures the effect of
county unemployment rate in 1982 on the change log odds of
idleness
the positive effect implies that higher county unemployment tends
to dampen change in odds
IRT Models
IRT models
Item Response Theory
models account for an individual-level random effect on
a set of items (i.e., ability)
items are assumed to tap a single latent construct
(aptitude on a specific subject)
item difficulty
test items are assumed to be ordered on a difficulty scale
easier harder
expected patterns emerge whereby if a more difficult
item is answered correctly the easier items are likely to
have been answered correctly
IRT Models
IRT models
1-parameter logistic (Rasch) model
logit( pij ) i b j
pij individual i’s probability of a correct response on the jth
item
θ individual i’s ability
b item j’s difficulty
properties
an individual’s ability parameter is invariant with respect to the
item
the difficulty parameter is invariant with respect to individual’s
ability
higher ability or lower item difficulty lead to a higher probability
of a correct response
both ability and difficulty are measured on the same scale
ICC
item characteristics curve (item response curve)
depicts the probability of a correct response as a function
of an examinee’s ability or trait level
curves are shifted rightward with increasing item difficulty
assume that item 3 is more difficult than item 2 and item 2
is more difficult than item 1
probability of a correct response decreases as the
threshold θ = bj is crossed, reflecting increasing item
difficulty
IRT Models: ICC (3 Items)
bj
slopes of item characteristics curves are equal when
ability = item difficulty
Estimation as GLMM
specification:
logit( pij ) j ui
xij ui
set up a person-item data structure
define x as a set of dummy variables
change signs on β to reflect “difficulty”
fit model without intercept to estimate all item difficulties
normalization is common
J
j 0
j 1
and
u2 1.0
PL1 Estimation
Stata (data set up )
clear
set memory 128m
infile junk y1-y5 f using LSAT.dat
drop if junk==11 | junk==13
expand f
drop f junk
gen cons = 1
collapse (sum) wt2=cons, by(y1-y5)
gen id = _n
sort id
reshape long y, i(id) j(item)
PL1 Estimation
Stata (model set up )
gen i1 = 0
gen i2 = 0
gen i3 = 0
gen i4 = 0
gen i5 = 0
replace i1 = 1 if item == 1
replace i2 = 1 if item == 2
replace i3 = 1 if item == 3
replace i4 = 1 if item == 4
replace i5 = 1 if item == 5
*
* 1PL
* constrain sd=1
cons 1 [id1]_cons = 1
gllamm y i1-i5, i(id) weight(wt) nocons family(binom) cons(1) link(logit) adapt
PL1 Estimation
Stata (output )
number of level 1 units = 5000
number of level 2 units = 1000
Condition Number = 1.8420141
gllamm model with constraints:
( 1) [id1]_cons = 1
log likelihood = -2473.054321704064
Coef.
i1
i2
i3
i4
i5
2.871972
1.063026
.2576052
1.388057
2.218779
Std. Err.
.1287498
.0821146
.0765907
.086496
.104828
z
22.31
12.95
3.36
16.05
21.17
P>|z|
[95% Conf. Interval]
0.000
0.000
0.001
0.000
0.000
2.619627
.902084
.1074903
1.218528
2.01332
3.124317
1.223967
.4077202
1.557586
2.424238
Variances and covariances of random effects
-----------------------------------------------------------------------------***level 2 (id)
var(1): 1 (0)
------------------------------------------------------------------------------
PL1 Estimation
Stata (parameter normalization)
* normalized solution
*[1 -- standard 1PL]
*[2 -- coefs sum to 0] [var = 1]
mata
bALL = st_matrix("e(b)")
b = -bALL[1,1..5]
mb = mean(b')
bs = b:-mb
("MML Estimates", "IRT parameters", "B-A Normalization")
(-b', b', bs')
end
PL1 Estimation
Stata (normalized solution)
param
MML
Estimates IRT
Normalized
1
2
2.87
1.06
-2.87
-1.06
-1.31
0.50
3
4
0.26
1.39
-0.26
-1.39
1.30
0.17
5
2.22
-2.22
-0.66
IRT: Extensions
2-parameter logistic (2PL) model
logit( pij ) a j (i b j )
item discrimination
parameters
j j ui
xij xij ui
j
bj
j
j is a factor loading on the random effect
b
j
j
0
and
a
j
j
1 (normalization)
IRT: Extensions
2-parameter logistic (2PL) model
item discrimination parameters
reveal differences in item’s utility to distinguish different
ability levels among examinees
high values denote items that are more useful in terms of
separating examinees into different ability levels
low values denote items that are less useful in
distinguishing examinees in terms of ability
ICCs corresponding to this model can intersect as they
differ in location and slope
steeper slope of the ICC is associated with a better
discriminating item
IRT: Extensions
2-parameter logistic (2PL) model
IRT: Extensions
2-parameter logistic (2PL) model
Stata (estimation)
eq id: i1 i2 i3 i4 i5
cons 1 [id1_1]i1 = 1
gllamm y i1-i5, i(id) weight(wt) nocons family(binom) link(logit) frload(1) eqs(id) cons(1) adapt
matrix list e(b)
*normalized solutions
*1 standard 2PL)
mata
bALL = st_matrix("e(b)")
b = bALL[1,1..5]
c = bALL[1,6..10]
a = -b:/c
("MML Estimates-Dif", "IRT Parameters")
(b', a')
("MML Discrimination Parameters")
(c')
end
IRT: Extensions
2-parameter logistic (2PL) model
Stata (estimation)
* Bock and Aitkin Normalization (p. 164 corrected)
mata
bALL = st_matrix("e(b)")
b = -bALL[1,1..5]
c = bALL[1,6..10]
lc = ln(c)
mb = mean(b')
mc = mean(lc')
bs = b:-mb
cs = exp(lc:-mc)
("B-A Normalization DIFFICULTY", "B-A Normalization DISCRIMINATION")
(bs', cs')
end
IRT: 2PL (1)
log likelihood = -2466.653343760672
Coef.
i1
i2
i3
i4
i5
2.773234
.9901996
.24915
1.284755
2.053265
Std. Err.
.205743
.0900182
.0762746
.0990363
.1353574
z
13.48
11.00
3.27
12.97
15.17
P>|z|
[95% Conf. Interval]
0.000
0.000
0.001
0.000
0.000
2.369985
.8137672
.0996546
1.090647
1.78797
3.176483
1.166632
.3986454
1.478862
2.318561
Variances and covariances of random effects
-----------------------------------------------------------------------------***level 2 (id)
var(1): 1 (0)
loadings for random effect 1
i1: .82565942 (.25811315)
i2: .72273928 (.18667773)
i3: .890914 (.2328178)
i4: .68836241 (.18513868)
i5: .65684452 (.20990788)
IRT: 2PL (2) Bock-Aitkin Normalization
item
1
2
3
4
5
check
B-A Normalization
Item Difficulty
Discrimination
Parameter
Parameter
-1.30
1.10
0.48
0.96
1.22
1.18
0.19
0.92
-0.58
0.87
0
1
item 3 has highest difficulty and greatest discrimination
1PL and 2PL
1PL and 2PL
Binary Response Models for Event Occurrence
discrete-time event-history models
purpose:
model the probability of an event occurring at some
point in time
Pr(event at t | event has not yet occurred by t)
life table
events & trials
observe the number of events occurring to those who
are at remain at risk as time passes
takes account of the changing composition of the sample
as time passes
Life Table
Life Table
observe
Rj number at risk in time interval j (R0 = n), where the
number at risk in interval j is adjusted over time
R j R j 1 D j 1 W j 1
Dj events in time interval j (D0 = 0)
Wj removed from risk (censored) in time interval j (W0 = 0)
(removed from risk due to other unrelated causes)
Life Table
other key quantities
discrete-time hazard (event probability in interval j)
pˆ j
Dj
Rj
surviving fraction (survivor function in interval j)
j
Sˆ j (1 pˆ k )
k 1
Discrete-Time Hazard Models
statistical concepts
discrete random variable Ti (individual’s event or
censoring time)
pdf of T (probability that individual i experiences event in
period j)
f (tij ) Pr(Ti j )
cdf of T (probability that individual i experiences event in
j
period j or earlier)
F (tij ) Pr(Ti j ) f (tik )
k 1
survivor function (probability that individual i survives
past period j)
S (tij ) Pr(Ti j ) 1 F (tij )
Discrete-Time Hazard Models
statistical concepts
discrete hazard
pij Pr(Ti j | Ti j )
the conditional probability of event occurrence in interval
j for individual i given that an event has not already
occurred to that individual by interval j
Discrete-Time Hazard Models
equivalent expression using binary data
binary data dij = 1 if individual i experiences an event in
interval j, 0 otherwise
use the sequence of binary values at each interval to
form a history of the process for individual i up to the
time the event occurs
discrete hazard
pij Pr(dij 1| dij 1 0, dij 2 0,, di1 0)
Discrete-Time Hazard Models
modeling (logit link)
exp( j xij )
pij
1 exp( j xij )
modeling (complementary log –log link)
pij 1 exp exp( j xij )
non-proportional effects
logit( pij ) j xij j
Data Structure
person-level data person-period form
Data Structure
binary sequences
Estimation
contributions to likelihood
Pr(Ti j ) f (tij ) if dij 1,
Li
Pr(Ti j ) S (tij ) if dij 0.
contribution to log L for individual with event in period j
j 1
log Li dij log pij log(1 pik )
k 1
contribution to log L for individual censored in period j
j
log Li log(1 pik )
combine
k 1
n
j
log L dik log pik (1 dik ) log(1 pik )
i 1 k 1
Example:
dropping out of Ph.D. programs (large US university)
data: 6,964 individual histories spanning 20 years
dropout cannot be distinguished from other types of
leaving (transfer to other program etc.)
model the logit hazard of leaving the originally-entered
program as a function of the following:
time in program (the time-dependent) baseline hazard)
female and percent female in program
race/ethnicity (black, Hispanic, Asian)
marital status
GRE score
also add a program-specific random effect (multilevel)
Example:
Example:
Example:
clear
set memory 512m
infile CID devnt I1-I5 female pctfem black hisp asian married gre using DT28432.dat
logit devnt I1-I5, nocons or
est store m1
logit devnt I1-I5 female pctfem, nocons or
est store m2
logit devnt I1-I5 female pctfem black hisp asian , nocons or
est store m3
logit devnt I1-I5 female pctfem black hisp asian married, nocons or
est store m4
logit devnt I1-I5 female pctfem black hisp asian married gre , nocons or