Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
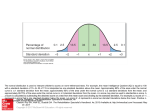
Chapter 6: The standard deviation as a ruler and the normal models A high school cross-country runner competes in two races (on different courses) and wants to know whether she did better in the first or second race. Even though most of the runners competed in both races, the results of the races were quite different (because the courses were different). How can performances be compared?1 Alternatively, race times can be compared by transforming the times to z-scores (also called standardized scores). The transformation of a race time to a z-score has the effect of measuring the difference between the race time and the mean race time using a single scale, the units of which are called standard deviation units. The standardized scores can then be compared without worrying about differences between race courses, weather conditions, and so on. For example, a race time that is one standard deviation larger the mean is not unusually slow; whereas a race time that is three standard deviation below the mean is unusually fast. If the race time is represented by y, then the z-score is defined to be y−y s z= where y and s are the mean and standard deviation of all the runners’ times. Suppose that race I times have a mean of y I = 72.3 minutes with a standard deviation of sI = 13.8 minutes, and the race II times have a mean of y II = 59.0 minutes with a standard deviation of sII = 18.5 minutes. Two examples follow. 1. Times for race I and II times were 82 and 71 minutes, respectively. The better time, relative to the competitors is determined by the computing the z-scores: Race I: z= 82 − 72.3 9.7 = = .70 13.8 13.8 Race II: z= 71 − 59 = .65 18.5 In race I, the time of 82 minutes was .7 standard deviations above the mean and the second race times was .65 standard deviations greater than the race II mean time of 50 minutes. Her performance relative to the other runners was nearly the same because the standardized times are nearly equal (.7 and .65). 1 If the times of all racers were available, then her percentiles could be computed and compared. 36 2. Consider another runner with a time of 50 minutes in race I and a 38 minutes in race II. In which race was his relative performance better based on the z-score measure? Race I: z= 50 − 72.3 −22.3 = = −1.62 13.8 13.8 Race II: z= 38 − 59 = −1.14 18.5 His relative performance was better (faster) in race I. Remarks: • z-scores are unit-less. • Computing the z-score involved subtracting a measure of center (the mean) and dividing by a measure of spread (the standard deviation). Resistant measures of center and spread might be used in place of the mean and standard deviation. However, it’s necessary to use the mean and standard deviation in order to extract accurate information about relative performance. Median and IQR are used for the related purpose of identifying outliers. The IQR outlier rule identifies an observation as an outlier if is larger than Q3 + 1.5IQR or smaller than Q1 − 1.5IQR. • z-scores have a several useful properties provided the data distribution is symmetric, unimodal and without outliers. Example The dotplot to the right shows the record times as of 1984 for n = 35 Scottish hill races.2 Two variables affecting the record times are the distance in miles and the climb (total elevation gained over the route), in feet. To adjust for distance, the pace (time/distance) is shown in the right histogram below. The median pace is M = 6.77 minutes/mile or 6 minutes, 46.3 seconds per mile; in contrast, the mean pace is 7.016 minutes/mile. The median Two Breweries Traprain Seven Hills Scolty N Berwick Law Moffat Chase Meall Ant−Suidhe Lomonds Largo Law Lairig Ghru Knockfarrel Kildcon Hill Half Ben Nevis Greenmantle Goatfell Eildon Two Dollar Criffel Creag Dubh Creag Beag Craig Dunain Cow Hill Cockleroi Carnethy Cairnpapple Cairngorm Cairn Table Burnswark Black Hill Bens of Jura Ben Rha Ben Nevis Ben Lomond Acmony 4 2 6 8 10 12 The Scottish hill races are instances of fell running, also known as mountain running and hill running, Pace (minutes/mile) a sport of running and racing, off road, over upland country where the gradient climbed is a significant component of the difficulty. The name arises from the origins of the English sport on the fells of northern Britain, especially those in the Lake District. Fell races are organized on the premise that contenders possess mountain navigation skills and carry adequate survival equipment as prescribed by the organizer. 37 distance is 6 miles, and the median climb is 1250 feet. The dotplot show the data. It’s not shown but the Bens of Jura race is 16.0 miles and involves climbing 7500 feet over 7 summits. There is some interest to understand how the record times vary with distance and elevation gain as the times reflect attributes related to human endurance. For example, as humans (and presumably other animals) approach the limits of endurance, there is very little gain in performance per unit effort compared to gain per unit effort when not near the limits of endurance. A closer look at the z-score transformation: Computing z-scores involves shifting and rescaling a datum y. It’s helpful to examine the effects of shifting and re-scaling a set of data values to understand the effect of the the z-score transformation. 1. Shifting: Shifting a set of data means adding or subtracting a constant from every datum. Numerical summaries are shown below and right. 0 2 4 Frequency 6 8 Min 3.87 Q1 5.96 M 6.73 Q3 7.96 Max 12.78 IQR 2.00 y 7.01 s 1.68 4 6 8 10 12 Pace (minutes/mile) Suppose 1 (minute/mile) is added to each datum. How would this affect: • the median?3 • the mean?4 • the IQR?5 • the standard deviation?6 • the 5-number summary?7 3 1 (minute/mile) larger 1 (minute/mile) larger 5 no change 6 no change 7 each value would be 1 (minute/mile) larger. 4 38 2. Scaling: Scaling a data set is carried out by multiplying all values by the same constant8 . Suppose pace is converted to minutes/km. The conversion is accomplished by dividing by .6 or multiplying by 1.667 the values. How would this affect: • the median?9 • the mean?10 • the IQR?11 • the standard deviation?12 • the 5-number summary?13 3. Standardizing: Standardizing data into z-scores shifts the data by the mean y and scales the shifted data by dividing by the standard deviation s. Note that the mean and standard deviation of the resulting z-scores are z = 0 and sz = 1. Normal models: The normal distribution is an idealized model that is often used for distributions that are unimodal and roughly symmetric (sometimes called mound-shaped). Frequency 100 200 • Histograms constructed from a quantitative variable often appear to be bell-shaped. The histogram to the right is an example.14 300 400 500 • Visually, the normal distribution is a bell-shaped curve 0 • A normal model is completely specified by the mean µ and standard deviation σ 15 . You only need to know that the data are 4 6 normal in distribution and the values of µ and σ to know exactly what the distribution looks like. 8 8 10 12 14 16 18 Verbal IQ score Scaling can be carried out by division as well since multiplication by 1/α is division by α. increases by 1.667 10 increases by 1.667 11 increases by 1.667 12 increases by 1.667 13 each value increases by 1.667 14 The data are verbal IQ scores measured on 2287 eighth-grade pupils in the Netherlands. Snijders, T. A. B. and Bosker, R. J. (1999) Multilevel Analysis. An Introduction to Basic and Advanced Multilevel Modelling. London: Sage. 15 Greek letters are used instead of the symbols y and s. The symbols y and s are used only when computed from data whereas µ and σ are not computed from data. 9 39 • The normal model is remarkably useful as it provides a reasonably good approximation in many situations. Examples include the distributions of SAT scores, weights of newborn babies, and heights of adult American women. • Normal models are easy to use for comparing a single value to a large set of values, and for characterizing the distribution of a variable. Examples of questions that can be answered using the normal model include: how does a SAT score of 624 compare to other scores? Have SAT math scores improved in the past 10 years? Why use a model? Why not just use the actual distribution (e.g., histogram)? 1. A model is compact. Saying that SAT math scores are approximately normal with mean µ = 500 and standard deviation σ = 100 (written N (500, 100)) is much more compact than giving the entire set of SAT scores. 2. It’s easier to work with a model than the full data set and it’s often possible to derive simple and useful results. 3. Occasionally, there are theoretical reasons why a model should be the correct one. Here, we will use the normal model only when it is justified from our data. The normal distribution function: The normal distribution is a curve that describes the relative frequency of values in a population. The equation describing the curve is equation [ ] 1 (x − µ)2 f (x) = √ exp − , for − ∞ < x < ∞. 2σ 2 σ 2π 0.0 0.000 0.1 0.001 0.2 0.002 0.3 0.003 0.4 0.004 If the graph of a normal distribution is needed, f (x) is plotted against x for a large number of values. We won’t use the distribution function in this class since there are tables and computers that immediately provide f (x). −4 −2 0 2 4 40 200 400 600 800 • Normal curves have the same shape regardless of the values of µ and σ. Two normal distribution curves are shown above. The left figure corresponds to µ = 0 and σ = 1 and the right figure corresponds to µ = 500 and σ = 100 • Suppose that the distribution of some data can be approximated by the N (µ, σ) model and we want to characterize the distribution. A standardization process is used since the standardized values will follow a N (0, 1) (standard normal ) model and it is easy to work N (0, 1) distribution. • Given a realization (value) x from the N (µ, σ) distribution, the standardized score is computed using the formula x−µ z= . (1) σ • For example, if SAT scores are N (500, 100), then the standardized SAT scores will be N (0, 1), as shown above. The transformation of some scores using formula (1) is 800 − 500 100 600 − 500 600 → 1 since 100 400 − 500 400 → −1 since 100 200 − 500 200 → −3 since 100 800 → 3 since = 3 = 1 = −1 = −3 The empirical (68-95-99.7) rule: This rule is used to quickly characterize a normal distribution. It states that 1. 68% of the values fall within 1 standard deviation of µ. 2. 95% of the values fall within 2 standard deviations of µ. 3. 99.7% of the values fall within 3 standard deviations of µ. The following figure shows the empirical rule visually. 41 0.4 0.3 0.2 0.1 68% 13.5% 13.5% 2.35% 0.0 2.35% −4 −2 0 2 4 z Example Suppose that the SAT math scores are approximately N (500, 100) in distribution. 1. According to the empirical rule, about 95% of SAT math scores fall between what two values?16 2. About what percentage of scores are below 400?17 3. About what percentage of scores are above 700?18 4. About what percentage of scores are between 300 and 400?19 . 5. What percentile is 400? What percentile is 700?20 16 300 and 700 because the empirical rule says that 95% falls within 2 standard deviations of the mean. For the SAT scores, 2 standard deviations below the mean is µ − 2σ = 500 − 2 × 100 = 300, and 2 standard deviations above the mean is µ + 2σ = 500 + 2 × 100 = 700. 17 16% because 400 is 1 standard deviation below the mean and about 16% of the distribution is less than 1 standard deviation below the mean. 18 700 is 2 standard deviations above the mean. 2.5% of the distribution is to the right of 2 standard deviations above the mean, so the percentage above 700 is 2.5%. 19 16% are below 400 and 2.5% are below 300. The difference is 13.5%. 20 400 is the 16th percentile because 16% of the scores are less than 400. 700 is the 97.5th percentile since 2.5% of the scores are greater than 700. 42 6. About what percentage of scores is below 650?21 Calculating proportions with the normal distribution It’s necessary to go beyond the empirical rule and the 68, 95, and 99.7 percentages to answer more general questions. As above, the proportion of a set of data between two values correspond to the area under the normal curve. Remember that the area under the entire normal curve is 1. Areas under normal curves are determined using a calculator, software (StatCrunch), or using a table of the standard normal distribution given in Table Z on pages A-110 and A-111 in the back of the text. A similar table can be opened (and saved) by going to the URL http://www.math.umt.edu/steele/STAT451/normal.pdf. Use of the table is illustrated here. Example: Suppose the annual snowfall amounts (inches) in Missoula are accurately modeled by a normal distribution with mean 46 inches and standard deviation 18 inches. 0.020 Question: According to the normal model, what proportion of years have snowfall amounts below 25 inches? 0.005 0.010 0.015 Answer : Let y = annual snowfall (inches). We want the area to the left of 25. Convert this to a statement about the N (0, 1) distribution by computing the z-score for 25: y−µ 25 − 46 = = −1.17. σ 18 0.000 z= 0 20 40 60 80 Inches 0.000 0.005 0.010 0.015 0.020 The area to the left of y = 25 under the N (46, 18) distribution is the same as the area the left of z = −1.17 under the N (0, 1) distribution. From Table Z, this area is 0.1210. If the normal model is accurate for the distribution of annual snowfall, then about 12.1% of years in Missoula have snowfalls totals that are less than 25 inches. 0 20 40 Inches 21 We’re not ready to answer this question. 43 60 80 Question: According to the normal model, approximately what proportion of years have between 25 and 50 inches of snowfall? Refer to the figure on the bottom of the previous page. Answer : The area is the same as the area between the corresponding z-scores on the N (0, 1) distribution: z= 25 − 46 50 − 46 = −1.17 and z = = .22. 18 18 The area between these two values is the area to the left of .22 minus the area to the left of −1.17. From Table Z, the area to the left of −1.17 is .1210. The proportion is .5871 − .1210 = .4661. Hence, the normal model estimates that about 46.6% of years have snowfall amounts between 25 and 50 inches. This proportion appears consistent with the figure. Approximately what proportion of Missoula annual snowfalls are greater than 50 inches?22 0.005 0.000 Question: According to the normal model, what is the 10th percentile of snowfall amounts? (i.e.: what is the snowfall amount such that only 10% of snowfalls are smaller?) 0.010 0.015 0.020 Reversing the standard normal transformation: Sometimes, instead of wanting to know what proportion of values are in some interval, we want to know what value corresponds to some proportion (the reverse question). Answer : First, sketch the distribution and guess 0 20 40 60 80 roughly where the 10th percentile is. Call it Inches the unknown 10th percentile y. The sketch provides check to see if the answer is reasonable. It should be clear that the 10th percentile here is less than 28 inches. (28 inches is 1 standard deviation below the mean). • First, determine the 10th percentile of the standard normal distribution using Table Z. Look for the value z such that the area to the left of this value is about .10. The closest tabled value is .1003, and it corresponds to z = −1.28. So, the 10th percentile is 1.28 standard deviations below the mean. Find the proportion below 50 and subtract the proportion from 1. This yields 1 − .5871 = .4129 or 41.3%. 22 44 • If the 10th percentile y of the N (46, 18) distribution were standardized, then the z-score would be z = −1.28. Mathematically, y − 46 = −1.28. 18 The 10th percentile is y, and solving for y yields y = 46 − 1.28(18) = 46 − 23.04 = 22.96 inches. Sketching the normal distributions is very helpful for solving these problems. Example: The weight of a certain candy bar is advertised as 8 ounces. The actual weights of these candy bars are not all 8 ounces, but vary. The distribution of actual weights is closely approximated by a normal distribution with mean 8.2 ounces and standard deviation .13 ounces. 0.0 2. According to the normal distribution, what proportion of the candy bars weigh between 7.9 and 8.1 ounces? 0.5 1.0 1.5 2.0 2.5 3.0 1. According to the normal distribution, what proportion of the candy bars weigh less than the advertised weight of 8 ounces? 8 − 8.2 Answer : z = = −1.54, and the .13 area to the left of z = −1.54 is .0618. Thus, the proportion of bars that weigh less is .0618. 7.8 8.1 − 8.2 = −.77. .13 8.2 8.4 8.6 8.4 8.6 Ounces 3.0 Answer : z = 8.0 2.0 2.5 The area to the left of z = −.77 is .2206. Also, 0.5 0.0 and the area to the left of 2.31 is .0104. Finally, the proportion of bars that weigh between 8.1 and 7.9 is .2206 − .0104 = .2102. 1.0 1.5 7.9 − 8.2 = −2.31, .13 7.8 8.0 8.2 Ounces 45 3. According to the normal distribution, what is the weight such that only 1% of candy bars weigh more than this weight? (What percentile is being asking for?) 2.5 x − 8.2 . .13 2.0 Set z = 2.33 = 3.0 Answer : the 99th percentile. The 99th percentile of the N(0,1) distribution is 2.33. 0.0 0.5 1.0 1.5 Solving for x leads to 1.3 × 2.33 + 8.2 = x, and so x = 8.50 ounces is the 99th percentile. 7.8 8.0 8.2 8.4 8.6 Ounces 4. According to the normal model, how unlikely would it be to obtain a chocolate bar that weighed 8.8 ounces? Answer : 8.8 − 8.2 .13 = 4.651. z = The area to the right of 4.651 is less than .0001. Less than 1 in 10, 000 candy bars are at least 8.8 ounces according to the normal model. It’s not impossible, but extremely unlikely. 46