Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
The Memory
Hierarchy
In the book: 5.1-5.3, 5.7, 5.10
1
Goals for this Class
•
•
•
Understand how CPUs run programs
•
•
•
•
How do we express the computation the CPU?
How does the CPU execute it?
How does the CPU support other system components (e.g., the OS)?
What techniques and technologies are involved and how do they work?
Understand why CPU performance (and other metrics)
varies
•
•
•
How does CPU design impact performance?
What trade-offs are involved in designing a CPU?
How can we meaningfully measure and compare computer systems?
Understand why program performance varies
•
•
•
How do program characteristics affect performance?
How can we improve a programs performance by considering the CPU
running it?
How do other system components impact program performance?
2
Memory
CPU
Abstraction: Big array of bytes
Memory
memory
3
Main points for today
• What is a memory hierarchy?
• What is the CPU-DRAM gap?
• What is locality? What kinds are there?
• Learn a bunch of caching vocabulary.
4
Processor vs Memory
Performance
• Memory is very slow compared to
Performance vs 1980
processors.
5
SRAM and DRAM
6
Silicon Memories
• Why store things in silicon?
•
•
It’s fast!!!
Compatible with logic devices (mostly)
• The main goal is to be cheap
•
•
•
•
Dense -- The smaller the bits, the less area you
need, and the more bits you can fit on a
chip/wafer/through your fab.
Bit sizes are measured in F2 -- the smallest feature
you can create.
The number of F2 /bit is a function of the memory
technology, not the manufacturing technology.
i.e. an SRAM in todays technology will take the
same number of F2 in tomorrow’s technology
7
Questions
• What physical quantity should represent the
bit?
•
•
•
•
•
Voltage/charge -- SRAMs, DRAMs, Flash memories
Magnetic orientation -- MRAMs
Crystal structure -- phase change memories
The orientation of organic molecules -- various
exotic technologies
All that’s required is that we can sense it and turn
it into a logic one or zero.
• How do we achieve maximum density?
• How do we make them fast?
8
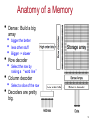
Anatomy of a Memory
•
•
Dense: Build a big
array
•
•
•
bigger the better
less other stuff
Bigger -> slower
Row decoder
•
Select the row by
raising a “word line”
• Column decoder
• Select a slice of the row
• Decoders are pretty
big.
9
The Storage Array
• Density is king.
•
•
Highly engineered, carefully tuned, automatically
generated.
The smaller the devices, the better.
•
•
•
•
Bit/word lines are long (millimeters)
They have large capacitance, so their RC delay is
long
For the row decoder, use large transistors to drive
them hard.
For the bit cells...
• Making them big makes them slow.
•
There are lots of these, so they need to be as small as
possible (but not smaller)
10
Measuring Memory Density
•
•
•
We use a “technology independent” metric to
measure the inherent size of different memory cells.
•
•
•
F == the “feature size” == the smallest dimension a CMOS
process can create (e.g., the width of the narrowest wire).
In a 22nm process technology, F = 22nm.
F2 (F-squared) is the smallest 2D feature we can manufacture.
A single bit of a given type of memory (e.g., SRAM or
DRAM) requires a fixed number of F2
•
•
This number doesn’t change with process technology.
e.g., NAND flash memory is 4F2 in 90nm and in 22nm.
Using this metic is useful because the relative sizes of different
memory technologies don’t change much, although absolute
densities do.
11
Sense Amps
• Sense amplifiers take a difference between
two signals and amplify it
• Two scenarios
•
•
Inputs are initially equal (“precharged”) -- they
each move in opposite directions
One input is a reference -- so only one signal moves
• Frequently used in memories
•
•
Storage cells are small, so the signals they produce
are inherently weak
Sense amps can detect these weak, analog signals
and convert them into a logic one or logic zero.
12
Static Random Access Memory (SRAM)
• Storage
•
•
Voltage on a pair of crosscoupled inverters
Durable in presence of
power
1
0
1
0
• To read
•
•
•
Pre-charge two bit lines to
Vcc/2
Turn on the “word line”
Read the output of the
sense-amp
1
13
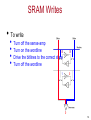
SRAM Writes
• To write
•
•
•
•
Turn off the sense-amp
Turn on the wordline
01
Drive the bitlines to the correct state
Turn off the wordline
01
1
0
0
14
Building SRAM
• This is “6T SRAM”
• 6 transistors is pretty
big
• SRAMs are not
dense
15
SRAM Density
• At 65nm: 0.52um
• 123-140 F
• [ITRS 2008]
2
2
65nm TSMC 6T SRAM
16
SRAM Ports
•
•
•
•
Add word and bit lines
Read/write multiple things at once
Density decreases quadratically
Bandwidth increase linearly
17
SRAM Performance
• Read and write times
• 10s-100s of ps
• Bandwidth
•
•
Registers -- 324GB/s
L1 cache -- 128GB/s
18
DRAM
19
Dynamic Random Access Memory (DRAM)
•
•
Storage
•
•
•
•
Charge on a capacitor
Decays over time (us-scale)
This is the “dynamic” part.
About 6F2: 20x better than
SRAM
Reading
•
•
•
•
Precharge
Assert word line
Sense output
Refresh data
Only one bit line is read at a time.
The other bit line serves as a reference.
The bit cells attached to Wordline 1 are not shown.
20
DRAM: Write and Refresh
• Writing
•
•
Turn on the wordline
Override the sense amp.
•
•
•
Every few milli-seconds,
read and re-write every bit.
Consumes power
Takes time
• Refresh
21
DRAM Lithography:
How do you get a big capacitor?
C ~ Area/dielectric-thickness
Stacked Capacitors
22
DRAM Lithography
Trench Capacitors
23
Accessing DRAM
•
•
Apply the row address
“opens a page”
Slow (~12ns read +
24 ns precharge)
Contents in a “row
buffer”
Apply one or more
column addrs
fast (~3ns)
Reads and/or writes
•
•
•
One DD3
DRAM bank
16k Rows
•
•
24
DRAM Devices
•
•
There are many banks per die (16 at left)
•
•
•
Multiple pages can be open at once.
Can keep pages open longer
Parallelism
Example
•
•
•
•
•
•
open bank 1, row 4
open bank 2, row 7
open bank 3, row 10
read bank 1, column 8
read bank 2, column 32
...
Micron 78nm 1Gb DDR3
25
DRAM: Micron MT47H512M4
26
DRAM: Micron MT47H512M4
27
DRAM Variants
• The basic DRAM technology has been
wrapped in several different interfaces.
• SDRAM (synchronous)
• DDR SDRAM (double data-rate)
•
Data clocked on rising and falling edge of the
clock.
• DDR2 -- faster, lower voltage DDR
• DDR3 -- even faster, even lower-voltage
• GDDR2-5 -- For graphics cards.
28
Current State-of-the-art: DDR3 SDRAM
•
•
•
•
DIMM data path is 64bits (72
with ECC)
Data rate: up to 1066Mhz DDR
(2133Mhz effective)
Bandwidth per DIMM GTNE:
16GB/s
•
guaranteed not to exceed
Multiple DIMMs can attach to a
bus
•
Reduces bandwidth/GB (a good idea?)
Each chip provides one
8-bit slice.
The chips are all
synchronized and
received the same
commands
29
DRAM Scaling
•
•
•
•
•
•
Long term need for performance has driven DRAM hard
•
•
•
complex interface.
High performance
High power.
DRAM used to be the main driver for process scaling, now
it’s flash.
Power is now a major concern.
Scaling is expected to match CMOS tech scaling
F2 cell size will probably not decrease
Historical foot note: Intel got its start as a DRAM
company, but got out of it when it became a commodity.
30
A Typical Hierarchy: Costs and Speeds
Cost
Access time
???
< 1ns
???
< 2-3ns
???
< 10ns
main memory
GBs
0.009 $/MB
60ns
SSDs
GB
0.0006 $/MB
On-chip L1 cache
SRAM
KBs
On-chip L2 cache
SRAM
KBs
On-chip L3 cache
SRAM
MBs
Disk
TBs
20,000ns
0.00004 $/MB 10,000,000ns
31
How far away is the data?
Los Angeles
© 2004 Jim Gray, Microsoft Corporation
32
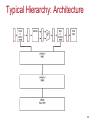
Typical Hierarchy: Architecture
33
The Principle of Locality
• “Locality” is the tendency of data access to
be predictable. There are two kinds:
•
•
Spatial locality: The program is likely to access data
that is close to data it has accessed recently
Temporal locality: The program is likely to access
the same data repeatedly.
34
Memory’s impact
M = % mem ops
Mlat (cycles) = average memory latency
BCPI = base CPI with single-cycle data memory
CPI =
35
Memory’s impact
M = % mem ops
Mlat (cycles) = average memory latency
TotalCPI = BaseCPI + M*Mlat
Example:
BaseCPI = 1; M = 0.2; Mlat = 240 cycles
TotalCPI = 49
Speedup = 1/49 = 0.02 => 98% drop in performance
Remember!: Amdahl’s law does not bound the slowdown.
Poor memory performance can make your program
arbitrarily slow.
36
Why should we expect caching to work?
• Why did branch prediction work?
37
Why should we expect caching to work?
• Why did branch prediction work?
• Where is memory access predictable
•
•
Predictably accessing the same data
•
•
In loops: for(i = 0; i < 10; i++) {s += foo[i];}
foo = bar[4 + configuration_parameter];
Predictably accessing different data
•
•
•
In linked lists: while(l != NULL) {l = l->next;}
In arrays: for(i = 0; i < 10000; i++) {s += data[i];}
structure access: foo(some_struct.a, some_struct.b);
38
The Principle of Locality
• “Locality” is the tendency of data access to
be predictable. There are two kinds:
•
•
Spatial locality: The program is likely to access data
that is close to data it has accessed recently
Temporal locality: The program is likely to access
the same data repeatedly.
39
Locality in Action
• Label each access
with whether it has
temporal or spatial
locality or neither
•
•
•
•
•
•
•
•
1
2
3
10
4
1800
11
30
•
•
•
•
•
•
•
•
•
•
•
•
1
2
3
4
10
190
11
30
12
13
182
1004
40
Locality in Action
• Label each access
with whether it has
temporal or spatial
locality or neither
•
•
•
•
•
•
•
•
1 n
2 s
3 s
10 n
4 s
1800 n
11 s
30 n
•
•
•
•
•
•
•
•
•
•
•
•
1t
2 s, t
3 s,t
4 s,t
10 s,t
190 n
11 s,t
30 s
12 s
13 s
182 n?
1004 n
There is no hard and fast rule here. In practice, locality
exists for an access if the cache performs well.
41
Cache Vocabulary
•
•
•
•
•
•
•
•
•
Hit - The data was found in the cache
Miss - The data was not found in the cache
Hit rate - hits/total accesses
Miss rate = 1- Hit rate
Locality - see previous slides
Cache line - the basic unit of data in a cache.
generally several words.
Tag - the high order address bits stored along with the
data to identify the actual address of the cache line.
Hit time -- time to service a hit
Miss time -- time to service a miss (this is a function of
the lower level caches.)
42
Cache Vocabulary
•
•
•
•
There can be many caches stacked on top of each
other
if you miss in one you try in the “lower level
cache” Lower level, mean higher number
There can also be separate caches for data and
instructions. Or the cache can be “unified”
In the 5-stage MIPS pipeline
•
•
•
•
the L1 data cache (d-cache) is the one nearest processor. It
corresponds to the “data memory” block in our pipeline
diagrams
the L1 instruction cache (i-cache) corresponds to the
“instruction memory” block in our pipeline diagrams.
The L2 sits underneath the L1s.
There is often an L3 in modern systems.
43
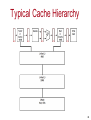
Typical Cache Hierarchy
44
Data vs Instruction Caches
• Why have different I and D caches?
45
Data vs Instruction Caches
•
Why have different I and D caches?
•
•
•
•
•
Different areas of memory
Different access patterns
•
•
•
I-cache accesses have lots of spatial locality. Mostly sequential
accesses.
I-cache accesses are also predictable to the extent that branches
are predictable
D-cache accesses are typically less predictable
Not just different, but often across purposes.
•
•
Sequential I-cache accesses may interfere with the data the Dcache has collected.
This is “interference” just as we saw with branch predictors
At the L1 level it avoids a structural hazard in the pipeline
Writes to the I cache by the program are rare enough that
they can be slow (i.e., self modifying code)
46