Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
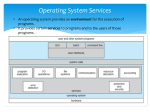
GD4: I/O Systems Group 2: Cezary Bloch Andrew Delaney Venkata Harish Mallipeddi Rickard Henrikson Introduction The two main jobs of a computer are I/O and processing. In many cases, the main job is I/O and the processing is merely incidental. For instance, when we browse a web page or edit a file, our immediate interest is to read or enter some information, and not to compute an answer. The role of the operating system in compute I/O is to manage and control I/O operations and I/O devices. The I/O devices that attach to a computer vary widely in many aspects like speed, functionality (consider a mouse, a hard disk, and a CD-ROM jukebox). Because of all this device variation, the OS has to provide a variety of methods to control the various aspects of the devices. These methods form the I/O subsystem of the kernel of the operating system. Goals of an I/O subsystem to provide the simplest possible interface for accessing the I/O devices, to the rest of the system to optimize I/O for maximum concurrency. I/O hardware Despite the great variety of I/O devices, the underlying concepts governing the working of all these devices are very similar. A device communicates with a computer system by sending signals over a cable or even through air. The device communicates with the machine via a connection point or port, for example, a serial port. If one or more devices use a common set of wires for communication, then this connection is called a bus. A bus is a rigidly defined protocol that specifies a set of messages that can be sent on the wires. Buses are widely used in computer architecture. Examples include the PCI bus, expansion bus, and SCSI bus. A controller is a collection of electronics that can operate a port, a bus, or a device. A controller can be either very simple like a serial-port controller which is a single chip in the computer which controls the signals on the wires of the serial port, or very complex like a SCSI controller which is implemented as a host adapter (a separate circuit board). I/O ports and registers The processor communicates with the controller to accomplish an I/O transfer by reading and writing bit patterns in the registers of the corresponding controller. This communication is done either by special I/O instructions that specify the transfer of a byte or word to an I/O port address, or by memory-mapped I/O (the device control registers are mapped into the processor's address space). An I/O port typically consists of four registers, called the status, control, data-in and data-out registers. Handshaking between a host and a controller: Polling, interrupts, and DMA Handshaking between a host and a controller can be either implemented via polling or by interrupts. In polling, the host repeatedly reads the busy bit in the status register of the controller to see if its free to process the I/O request. Once, it finds the busy bit clear, it proceeds with the rest of the operations to complete the I/O request. This is called busy-waiting or a polling loop. If the controller and device are fast enough, then this method is reasonable. Otherwise, the host should probably switch to another task to increase efficiency. In the interrupt mechanism, unlike polling, the hardware controller notifies the CPU when the device is ready for service by sending an interrupt. For a device that does large transfers, such as a disk drive, the above two mechanisms might seem to be wasteful to use an expensive general-purpose processor to watch status bits and to feed data into a controller register 1 byte at a time. This process is called programmed I/O (PIO). Many computers avoid the burden of PIO on a CPU by offloading some of the work to a special-purpose processor called a Direct Memory-Access (DMA) controller. Application I/O interface In an ideal situation, we want an application to be able to open a file on a disk without knowing what kind of disk it is, or add new disks to the computer without disrupting the operating system. This is achieved by the OS by using interfaces – one for every general kind of I/O devices. A typical kernel I/O structure is shown in the picture below. The purpose of the device-driver layer is to hide the differences among device controllers from the I/O subsystem of the kernel, much as the I/O system calls encapsulate the behaviour of devices in a few generic classes that hide hardware differences from applications. Hardware manufacturers either design new devices to be compatible with an existing host controller interface (such as SCSI-2), or write device drivers to interface the new hardware to popular operating systems. Kernel I/O Subsystems The kernel I/O subsystem improves the efficiency of a computer by providing several services for device drivers that build on the infrastructure of the hardware. Some examples are I/O scheduling and error handling. It then provides the simplest interface possible for the rest of the system when it wants to communicate with the I/O devices. I will only cover I/O scheduling and caching and buffering due to the restriction on the length of the assignment. I/O Scheduling I/O scheduling is a service that handles I/O requests and determines in which order they should be executed. This is done by making a request queue for every I/O device, and rearranging the order of the requests after a given scheme. It is needed to improve the performance of the system, because if you choose to execute the requests in the same order as the system calls were made, you will most likely get a lot of unnecessary waiting time. Too see an example of that, look at two processes requesting to access the hard drive. If the arm is near the beginning of the disk, and the process who requested the disk first wants information in the end of the disk while the other process wants information that resides in the beginning of the disk, you would get a lot more waiting time if you serve the first process request first. Caching and Buffering Caches and buffers are somewhat similar. A cache copies some data from a slow medium to a faster medium in order to make it available faster. For example, a program resides on disk, but when it is to be executed, it is copied to main memory to be “closer” to the CPU. A buffer, on the other hand, can have the only copy of some data. It is used, for example, when a slow device is communicating with a fast device. The slow device sends data to the buffer, and when that reaches its limit or the data stream ends, the buffer sends all the data in one, fast stream to the faster device. In this way, the faster device is used more efficiently. Another example of where buffers come in use is when two devices are communicating, and they have different data-transfer sizes. For example, the device sending can send data in small chunks to the buffer, and the receiving device can still read the data in large chunks when taken from the buffer. A third use for buffers is when for an example an application has a data buffer and sends a system call to write it to disk, and then modifies it. The system can then provide a kernel buffer that copies the application data on the write() system call to ensure the right data is being written to disk. STREAMS STREAM is a mechanism from UNIX System V. It is a full-duplex communication channel between a process and a device, meaning it is a connection that can send data in either direction simultaneously. It consists of a STREAM head, a driver end, and a number of modules in between (zero is a number!). Each of these has a read- and a write queue, and communication between those queues is done by message passing. The process communicates with the STREAM head, while the driver is communicating with the driver end. The modules may be used by several STREAMS, and hence, several processes may communicate with the same driver and vice versa. Transforming I/O Requests to Hardware Operations In this section, I will try to explain what happens from the moment a process makes an I/O request to the actual execution of the desired operation. I will use as an example a process that tries to read data from a file. The process provides the name of the file to be read, and from that name, the system determines what device that holds the file. In MS-DOS, the letter before the colon tells which device (C:\foo.txt) while UNIX checks the filename in a mount table that determines the device in question. A request is sent to the device driver, which processes the request and communicates with the interrupt handler and the device controller, all according to the picture below. The desired data is read into a buffer and made available for the requesting process, and control is returned to the process. If, however, the desired file has been opened recently, it might still be in the buffer. In that case, the kernel I/O subsystem may deliver the data without involving any further requests to the device driver etc. Performance I/O affects the performance of a system greatly, because it puts a lot of strain on the CPU and the memory bus. The CPU has to handle execution of device-driver code and scheduling, which results in context switching, and the memory bus gets crowded by the data sent between the device controller and the kernel buffer, and between the kernel buffer and the user space allocated to the process. To increase performance, an OS manufacturer must therefore try to reduce the number of context switches and the amount of data being copied. Mass Storage Structure Mass storage plays an important part in the operation of modern computers. As primary storage (RAM) for computers is volatile and quite expensive by comparison, another device must be used for storage when the computer is powered off or for data which exceeds the capacity of primary storage. For this reason secondary storage (such as hard disks) and tertiary storage (removable media such as tape drives) were created. This section concerns these devices. Physical Disk Structure Hard disks are composed of either a single or multiple rotating magnetic platers with a disk head that moves over their surface in order to read the data. The surfaces of the platters are divided into cylinders (a set of track on all the disks platters), tracks (concentric circles radiating in towards the centre of the disk) and sectors (pieces of tracks). These divisions are allocated a reference in an array of what is termed logical blocks (chunks of the disk that are of equal data capacity) in a process known as a low level format. When the computer addresses data on the disk, it addresses it via its logical block number. Disk File System Structure Before an operating system is able to use a disk, its data capacity must be broken up into one or more partitions (pieces of disk allocated to become a drive or volume within the operating system). After this process is completed, the disk must be formatted in accordance with the rules of the file system that is to be implemented on it. File systems provide a logical method of storing and retrieving data and help to prevent it from being misused. Different file systems provide different services to the computer; a basic file system may only provide a method of addressing, reading from and writing to files on the disk while a more complicated one may provide services such as security. Swap Space and Virtual Memory Modern operating systems utilize a system of “virtual memory” to store data that is too large to fit in the computer’s physical RAM. This virtual memory exists on a secondary storage device attached to the computer, usually a hard disk. The space on the disk allocated to virtual memory is known as swap space. Management of swap space requires different approaches than management of a disk-based file system in order to ensure maximum efficiency. At its simplest, swap space exists as a file on a hard disk. This implementation means that it can be managed through methods identical to those of managing any other file. However, it is more efficient to utilize a separate disk partition for swap space that obeys different rules to the standard file system. This is due to the fact that data stored in swap space is not usually present for a long period of time and may be accessed much more frequently than a standard file. Hence, swap space management algorithms are usually optimized towards maximum performance whereas a file system algorithm is usually optimized towards efficient use of the disk. The swap space algorithm found in modern UNIX operating systems such as Sun Solaris make further efficiency improvements by not storing any program code in swap space (as it would be more efficient to read it again from the file system than from swap space should it have to be paged out of memory). They also allocate swap space as it is required rather than when a program is started. RAID - Redundant Array of Independent Disks RAID is a method of improving the performance and/or reliability of fixed disk storage. It functions by using the features of multiple disk devices in tandem – either through reading/writing to multiple disks at once (improves performance) or through writing redundant data to additional disks making it possible to recover from hardware failures. RAID has a number of modes, the most common of which are 0, 1 and 5 (which is similar to modes 3 and 4). The modes operate as follows: RAID 0: Data is striped across multiple disks improving read and write performance. No redundancy data is created – if any one disk fails, all the data is lost. RAID 0 requires at least 2 disks to operate. RAID 1: Data is written to one disk and mirrored onto another (i.e. the same data is written twice with identical copies on each disk). Should one disk fail the system will continue to operate with the redundant copy but the RAID set should be restored by replacing the failed disk. RAID 1 requires at least 2 disks to operate. RAID 3 - 5: Combining the benefits of RAID 0 and 1, RAID modes 3 through 5 stripes data across all disks but one in the set. The final disk is reserved for the storage of parity data. Parity is an algorithm that allows the recovery of lost data provided that no more than one disk in the set is lost. It works by creating a sum of two or more data bits and adding an extra bit to make the sum either odd or even (which of these is determined beforehand). For example: For odd parity: 1 + 1 = 2 so a parity bit of 1 is added to make the sum odd (=3). 1 + 0 = 1 so a parity bit of 0 is added keeping the sum odd (=1). For even parity: 1 + 1 = 2 so a parity bit of 0 is added keeping the sum even (=2). 1 + 0 = 1 so a parity bit of 1 is added to make the sum even (=2). Should one of the bits be lost, the data can be recovered as follows (the example assumes even parity): 1 + x + 1 where x may only be 0 or 1 allows that the only even result will be x = 0 0 + x + 1 where x may only be 0 or 1 allows that the only even result will be x = 1 If one disk fails in a RAID set that utilizes parity, the set continues to operate but the faulty disk must be replaced as soon as possible and the lost data regenerated for if a further disk fails all the data will be lost. RAID modes 3 through 5 require at least 3 disks to operate. The difference between the three modes is the distribution of data and parity information amongst the disks. In RAID 3, data bits involved in a write are spread evenly amongst disks and a single parity disk is used to ensure that this data can be recovered should a bit be lost. RAID 4 improves performance where multiple concurrent reads are required by striping with blocks of data rather than single bits, thus allowing multiple reads to occur at once. RAID 5 improves on RAID 4 by distributing parity information amongst the disks, thus preventing overuse of the parity disk. Disk Attachment At our computer at homes, usually disks, CD-ROMs, DVDs are connected directly to our computer – this is called host-attached storage. It is also possible to access discs via network, which is called network-attached storage. I think that it can be found on computers at MIC which don’t have their own discs, but probably share the big one. Host-Attached Storage This kind of storage is accessed by I/O ports. Most popular in home use is IDE. On one tape (bus) we can connect only 2 drives, so without additional controller it gives maximum 4 disks in computer. In servers other architectures are used, such as SCSI or FC (fibre channel). SCSI enables us to connect up to 16 devices on the bus (in fact 15 cause controller is one of them). That gives us nice possibility to make use of RAID at home. FC is the fastest of mentioned architectures. It is expected to dominate soon and be the basis for SANs (described later). Communication can be set by optical cable, known from it high speed and small size. Network-Attached Storage (NAS) and Storage-Area Network (SAN) NAS is accesses by network. Usually traffic is carried by the same network as used for other purposes, like email, www. For obvious reasons it’s good to implement NAS as RAID. Those of us who has ever used it know that it slows down the other network traffic. We can separate the network traffic from storage one using storage protocols instead of network protocols as in NAS. Stable – Storage Implementation Stable Storage by definition can never fail. Data from this medium cannot be lost. To design such a device (Set of devices) we need several storage devices, which usually are disks. When we want to update data on such a device we have to schedule writing on disks in such a way that if a failure occurs we will not have all copies damaged. Writing to disk may result in three states: 1. Successful completion – everything went OK 2. Partial Failure – data which were written when failure occurred can be damaged 3. Total Failure – Error occurred before writing started System has to detect failure if it occurs and call special recovery procedure to bring back consistent state. Do achieve it we need two blocks and do writing in that order: 1. Write data to first block 2. When writing to first block was successful write to the second block 3. Return successful status if operations one and two went correct When recovering from a failure we compare each pair of blocks. The following cases ensures either success in writing or no change in stored data: 1. Blocks are the same and there is no detectable error – Do anything. 2. One block has detectable error – replace it with content of another. 3. There is no detectable error but blocks are different – replace first block with content of second Adding more disks will of course increase reliability but usually only two are used. Tertiary – Storage Structure Tertiary storage is build with removable media such as diskettes and CD-ROMs. So tertiary storage devices are floppy disk drives, CD, DVD drives. We all know basically how those devices work, so what is worth mentioning is the technologies of future in this are, especially holographic storage. It uses laser light but in a different way that today’s CDs, DVDs, so that in one flash of light extremely great amount of data can be written to special media. Removable media is mostly handles similarly to non-removable. When it is inserted it needs to be formatted, and file system is generated. It is different with tape drives, where system presents it as raw medium. Program does not open files on tape, it opens whole device. Tape drives are usually reserved for only one application at time because of its long seek time. It may also be a problem to read data from tape since program making backup of system manages files in its own way. Other program may do it differently and it will not be able to read this backup. Also updating backup on tape is problematic since writing something in the middle of tape will make all data after this point unreadable! Lessons learned Harish: After starting to write my part of the deliverable, I found that it is very difficult to express all the concepts and my viewpoints in such a concise manner (to fit the page limit which we overshoot last time too), and to do this without losing much detail, it’s even more a tough job to do! Anyway, I've tried my best to explain as much as I can within the page limit recommended. Hope you'll like it Anna :) Andrew: I think that the new system of having things done well before deadline has worked well...I felt much less stressed not having to be up all night doing assignments and was pleased to have it done by midnight Rickard: I have also had big problems describing the subjects without exceeding the length limit. I think that the quality of my work is not what it could have been, because I could not get the core of the subject covered and still explain how it works. I also got a bit disappointed on the book, because I think that it didn’t cover some essential parts enough, like the usage of STREAMS. Like Andrew, I am pleased we started off earlier this time.