Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
W E K A
Waikato Environment for
Knowledge Analysis
Branko Kavšek
MPŠ Jožef Stefan
November 2005
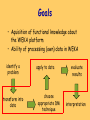
Goals
• Aquisition of functional knowledge about
the WEKA platform
• Ability of processing (own) data in WEKA
identify a
problem
transform into
data
apply to data
choose
appropriate DM
technique
evaluate
results
interpretation
What is WEKA ?
Some basic facts about WEKA:
• WEKA(1) = a flightless bird with an inquisitive nature (found
only on the islands of New Zealand)
• WEKA(2) = a software ‘workbench’ incorporating several
standard ML/DM techniques
• Authors = Ian H. Witten, Eibe Frank (et. al.)
• Programming language = JAVA
• Origin = The University of Waikato, New Zealand
• Literature = Ian H. Witten, Eibe Frank:
Practical Machine Learning Tools with JAVA Implementations,
Morgan Kaufmann, 1999
• Homepage = http://www.cs.waikato.ac.nz/~ml/weka
Objectives of WEKA
• make ML/DM techniques generally available
• apply them to practical problems
(in agriculture)
• develop new ML/DM algorithms
• contribute to the theoretical framework
of the field (ML/DM)
Versions of WEKA
• There are several versions of WEKA:
– WEKA 3.0: “book version” compatible with
description in data mining book
– WEKA 3.2: “first GUI version” adds
graphical user interfaces (book version is
command-line only)
– WEKA 3.5: “development version” with
lots of improvements
• This workshop is based on
WEKA 3.5(.2)
Outline
• WEKA on the WEB
• Transforming data into the “right” format
• Using the “Explorer”
• WEKA from the command-line (Simple CLI)
• Knowledge flow in brief
• Performing the experiments
• Tips & tricks
• The PRO’s and the CON’s of WEKA
WEKA on the WEB
The input to WEKA
ARFF (Attribute-Relation
•
File Format)
example: Play-tennis domain
format - “flat” files:
%this is an example of a knowledge
%domain in ARFF format
@relation weather
@attribute
@attribute
@attribute
@attribute
@attribute
outlook {sunny, overcast, rainy}
temperature real
humidity real
windy {TRUE, FALSE}
play {yes, no}
@data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
. . .
Conversion to the
ARFF format
?
Example:
•
converting from
MS-EXCEL to ARFF
Starting WEKA – the GUI
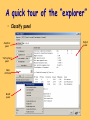
A quick tour of the “explorer”
• Preprocess panel
Filters
panel
Domain info.
panel
Attribute info.
panel
Attributes
panel
Status bar
Attribute
visualization
panel
Log
file
A quick tour of the “explorer”
• Classify panel
Classifier
panel
Test options
panel
Class
attribute
Result
panel
Output
panel
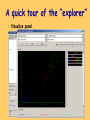
A quick tour of the “explorer”
• Visualize panel
The command line
• example:
C:\Temp>java weka.classifiers.trees.J48
Weka exception: No training file and no object input file given.
General options:
-t <name of training file>
Sets training file.
-T <name of test file>
Sets test file. If missing, a cross-validation will be performed on the training data.
-c <class index>
Sets index of class attribute (default: last).
-x <number of folds>
Sets number of folds for cross-validation (default: 10).
-s <random number seed>
Sets random number seed for cross-validation (default: 1).
-m <name of file with cost matrix> Sets file with cost matrix.
-l <name of input file>
Sets model input file.
-d <name of output file>
Sets model output file.
-v
Outputs no statistics for training data.
-o
Outputs statistics only, not the classifier.
-i
Outputs detailed information-retrieval statistics for each class.
-k
Outputs information-theoretic statistics.
-p
Only outputs predictions for test instances.
-r
Only outputs cumulative margin distribution.
-z <class name>
Only outputs the source representation of the classifier, giving it the supplied name.
-g
Only outputs the graph representation of the classifier.
Options specific to weka.classifiers.j48.J48:
-U
Use unpruned tree.
-C <pruning confidence>
Set confidence threshold for pruning. (default 0.25)
-M <minimum number of instances>
Set minimum number of instances per leaf. (default 2)
-R
Use reduced error pruning.
-N <number of folds>
Set number of folds for reduced error pruning. One fold is used as pruning set. (default 3)
-B
Use binary splits only.
-S
Don't perform subtree raising.
-L
Do not clean up after the tree has been built.
Using the “Simple CLI”
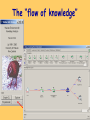
The “flow of knowledge”
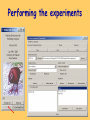
Performing the experiments
Tips & tricks
• More memory:
java -mx100000000 -oss100000000 ...
• Converting to ARFF & verify:
java weka.core.converters.CSVLoader filename.csv
> filename.arff
java weka.core.Instances filename.arff
• Checking available memory:
– rigth-clich on the status bar
GUI vs. command line
GUI (+):
Command line (-):
• visualisation of data
and (some) models
• only textual visualisation
of models
• awkward to use
GUI (-):
Command line (+):
• not all the parameters
can be set (reduced
functionality)
• full functionality
• batch processing
PROs & CONs of WEKA
PROs:
CONs:
• open source (GNU licence)
• relatively slow (JAVA)
• platform-independent
• ‘incomplete’ documentation
(JAVA)
• easy to use
• (relatively) easy to modify
(some GUI features could
be explained better)
• some features available
only from command line
That’s it !!!
Thanks