Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
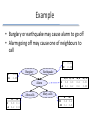
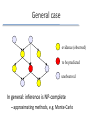
Instance based and Bayesian learning Kurt Driessens with slide ideas from a.o. Hendrik Blockeel, Pedro Domingos, David Page, Tom Dietterich and Eamon Keogh Overview Nearest neighbor methods – Similarity – Problems: • dimensionality of data, efficiency, etc. – Solutions: • weighting, edited NN, kD-trees, etc. Naïve Bayes – Including an introduction to Bayesian ML methods Nearest Neighbor: A very simple idea Imagine the world’s music collection represented in some space When you like a song, other songs residing close to it should also be interesting … Picture from Oracle Nearest Neighbor Algorithm 1. Store all the examples <xi,yi> 2. Classify a new example x by finding the stored example xk that most resembles it and predicts that example’s class yk + + + + + + - - - +? + + - + - - + - - - - - Some properties • Learning is very fast (although we come back to this later) • No information is lost • Hypothesis space – variable size – complexity of the hypothesis rises with the number of stored examples Decision Boundaries + - + + - - Voronoi diagram - + - + - + + + - - Boundaries are not computed! Keeping All Information Advantage: no details lost Disadvantage: "details" may be noise + + + + + + - - - + - + + + - + + + - - + + + + + - - k-Nearest-Neighbor: kNN To improve robustness against noisy learning examples, use a set of nearest neighbors For classification: use voting k-Nearest-Neighbor: kNN (2) For regression: use the mean 1 1 1 4 5 2 4 5 5 4 3 2 4 3 3 Lazy vs Eager Learning kNN doesn’t do anything until it needs to make a prediction = lazy learner – Learning is fast! – Predictions require work and can be slow Eager learners start computing as soon as they receive data Decision tree algorithms, neural networks, … – Learning can be slow – Predictions are usually fast! Similarity measures Distance metrics: measure of dis-similarity E.g. Manhattan, Euclidean or Ln-norm for numerical attributes Hamming distance for nominal attributes n d(x,y) = åd (x , y ) i i i=1 where d (x i, y i ) = 0 if x i = y i d (x i, y i ) = 1 if x i ¹ y i Distance definition = critical! E.g. comparing humans 1. 1.85m, 37yrs 2. 1.83m, 35yrs 3. 1.65m, 37yrs 1. 185cm, 37yrs 2. 183cm, 35yrs 3. 165cm, 37yrs d(1,2) = 2.00…0999975… d(1,3) = 0.2 d(2,3) = 2.00808… d(1,2) = 2.8284… d(1,3) = 20.0997… d(2,3) = 18.1107… Normalize attribute values Rescale all dimensions such that the range is equal, e.g. [-1,1] or [0,1] x i - mi For [0,1] range: x i ' = M i - mi with mi the minimum and Mi the maximum value for attribute i Curse of dimensionality Assume a uniformly distributed set of 5000 examples To capture 5 nearest neighbors we need: – in 1 dim: 0.1% of the range – in 2 dim: 0.1% = 3.1% of the range – in n dim: 0.1%1/n Curse of Dimensionality (2) With 5000 points in 10 dimensions, each ? attribute range must be covered approx. 50% to find 5 neighbors … Curse of Noisy Features Irrelevant features destroy the metric’s meaningfulness Consider a 1dim problem where the query x is at the origin, the nearest neighbor x1 is at 0.1 and the second neighbor x2 at 0.5 (after normalization) Now add a uniformly random feature. What is the probability that x2 becomes the closest neighbor? approx. 15% !! Curse of Noisy Features (2) Location of x1 vs x2 on informative dimension Weighted Distances Solution: Give each attribute a different weight in the distance computation Selecting attribute weights Several options: – Experimentally find out which weights work well (cross-validation) – Other solutions, e.g. (Langley,1996) 1. Normalize attributes (to scale 0-1) 2. Then select weights according to "average attribute similarity within class” for each attribute for each class for each example in that class More distances Strings – Levenshtein distance/edit distance = minimal number of changes needed to change one word into the other Allowed edits/changes: 1. delete character 2. insert character 3. change character (not used by some other edit-distances) Even more distances C Given two time series: Q = q1…qn C = c1…cn Euclidean DQ, C qi ci n Q 2 i 1 D(Q,C) R Start and end times are critical! D(Q,R) Sequence distances (2) Dynamic Time Warping Fixed Time Axis “Warped” Time Axis Sequences are aligned “one to one”. Nonlinear alignments are possible. Dimensionality reduction Distance-weighted kNN k places arbitrary border on example relevance – Idea: give higher weight to closer instances Can now use all training instances instead of only k (“Shepard’s method”) k fˆ ( xq ) w f (x ) i i 1 i k w i 1 1 with wi d ( xq , xi ) 2 i ! In high-dimensional spaces, a function of d that “goes to zero fast enough” is needed. (Again “curse of dimensionality”.) Fast Learning – Slow Predictions Efficiency – For each prediction, kNN needs to compute the distance (i.e. compare all attributes) for ALL stored examples – Prediction time = linear in the size of the data-set For large training sets and/or complex distances, this can be too slow to be practical (1) Edited k-nearest neighbor Use only part of the training data ✔ Less storage ✗Order dependent ✗Sensitive to noisy data More advanced alternatives exist (= IB3) (2) Pipeline filters Reduce time spent on far-away examples by using more efficient distance-estimates first – Eliminate most examples using rough distance approximations – Compute more precise distances for examples in the neighborhood (3) kD-trees Use a clever data-structure to eliminate the need to compute all distances kD-trees are similar to decision trees except – splits are made on the median/mean value of dimension with highest variance – each node stores one data point, leaves can be empty Example kD-tree Use a form of A* search using the minimum distance to a node as an underestimate of the true closest distance Finds closest neighbor in logarithmic (depth of tree) time kD-trees (cont.) Building a good kD-tree may take some time – Learning time is no longer 0 – Incremental learning is no longer trivial • kD-tree will no longer be balanced • re-building the tree is recommended when the maxdepth becomes larger than 2* the minimal required depth (= log(N) with N training examples) Cover trees are more advanced, more complex, and more efficient!! (4) Using Prototypes The rough decision surfaces of nearest neighbor can sometimes be considered a disadvantage + + - + - + - + + - + -- + + - – Solve two problems at once by using prototypes = Representative for a whole group of instances Prototypes (cont.) Prototypes can be: – Single instance, replacing a group – Other structure (e.g., rectangle, rule, ...) -> in this case: need to define distance + + - + - + - Recommender Systems through instance based learning Movie Alice (1) Bob (2) Carol (3) Dave (4) (romance) (action) Love at last 5 5 0 0 0.9 0 Romance forever 5 ? ? 0 1.0 0.01 Cute puppies of love ? 4 0 ? 0.99 0 Nonstop car chases 0 0 5 4 0.1 1.0 Swords vs. karate 0 0 5 ? 0 0.9 Predict ratings for films users have not yet seen (or rated). Recommender Systems Predict through instance based regression: Some Comments on k-NN Positive Negative • Easy to implement • Good “baseline” algorithm / experimental control • Incremental learning easy • Psychologically plausible model of human memory • Led astray by irrelevant features • No insight into domain (no explicit model) • Choice of distance function is problematic • Doesn’t exploit/notice structure in examples Summary • Generalities of instance based learning – Basic idea, (dis)advantages, Voronoi diagrams, lazy vs. eager learning • Various instantiations – kNN, distance-weighted methods, ... – Rescaling attributes – Use of prototypes Bayesian learning This is going to be very introductory •Describing (results of) learning processes – MAP and ML hypotheses •Developing practical learning algorithms – Naïve Bayes learner • application: learning to classify texts – Learning Bayesian belief networks Bayesian approaches Several roles for probability theory in machine learning: – describing existing learners • e.g. compare them with “optimal” probabilistic learner – developing practical learning algorithms • e.g. “Naïve Bayes” learner Bayes’ theorem plays a central role Basics of probability • P(A): probability that A happens • P(A|B): probability that A happens, given that B happens (“conditional probability”) • Some rules: – complement: P(not A) = 1 - P(A) – disjunction: P(A or B) = P(A)+P(B)-P(A and B) – conjunction: P(A and B) = P(A) P(B|A) = P(A) P(B) if A and B independent – total probability:P(A) = i P(A|Bi) P(Bi) With each Bi mutually exclusive Bayes’ Theorem P(A|B) = P(B|A) P(A) / P(B) Mainly 2 ways of using Bayes’ theorem: – Applied to learning a hypothesis h from data D: P(h|D) = P(D|h) P(h) / P(D) ~ P(D|h)P(h) – – – – P(h): a priori probability that h is correct P(h|D): a posteriori probability that h is correct P(D): probability of obtaining data D P(D|h): probability of obtaining data D if h is correct – Applied to classification of a single example e: P(class|e) = P(e|class)P(class)/P(e) Bayes’ theorem: Example Example: – assume some lab test for a disease has 98% chance of giving positive result if disease is present, and 97% chance of giving negative result if disease is absent – assume furthermore 0.8% of population has this disease – given a positive result, what is the probability that the disease is present? P(Dis|Pos) = P(Pos|Dis)P(Dis) / P(Pos) = 0.98*0.008 / (0.98*0.008 + 0.03*0.992) MAP and ML hypotheses Task: Given the current data D and some hypothesis space H, return the hypothesis h in H that is most likely to be correct. Note: this h is optimal in a certain sense – no method can exist that finds with higher probability the correct h MAP hypothesis Given some data D and a hypothesis space H, find the hypothesis hH that has the highest probability of being correct; i.e., P(h|D) is maximal This hypothesis is called the maximal a posteriori hypothesis hMAP : hMAP = argmaxhH P(h|D) = argmaxhH P(D|h)P(h)/P(D) = argmaxhH P(D|h)P(h) • last equality holds because P(D) is constant So : we need P(D|h) and P(h) for all hH to compute hMAP ML hypothesis P(h): a priori probability that h is correct What if no preferences for one h over another? •Then assume P(h) = P(h’) for all h, h’H •Under this assumption hMAP is called the maximum likelihood hypothesis hML hML = argmaxhH P(D|h) (because P(h) constant) •How to find hMAP or hML ? – brute force method: compute P(D|h), P(h) for all hH – usually not feasible Naïve Bayes classifier Simple & popular classification method •Based on Bayes’ rule + assumption of conditional independence – assumption often violated in practice – even then, it usually works well Example application: classification of text documents Classification using Bayes rule Given attribute values, what is most probable value of target variable? vMAP arg max P(v j | a1 , a2 ,..., an ) v j V arg max v j V P(a1 , a2 ,..., an | v j ) P(v j ) P(a1 , a2 ,..., an ) arg max P(a1 , a2 ,..., an | v j ) P(v j ) v j V Problem: too much data needed to estimate P(a1…an|vj) The Naïve Bayes classifier Naïve Bayes assumption: attributes are independent, given the class P(a1,…,an|vj) = P(a1|vj)P(a2|vj)…P(an|vj) –also called conditional independence (given the class) •Under that assumption, vMAP becomes vNB arg max P(v j ) P(ai | v j ) v j V i Learning a Naïve Bayes classifier To learn such a classifier: just estimate P(vj), P(ai|vj) from data vNB arg max Pˆ (v j ) Pˆ (ai | v j ) v j V i How to estimate? – simplest: standard estimate from statistics • estimate probability from sample proportion • e.g., estimate P(A|B) as count(A and B) / count(B) – in practice, something more complicated needed… Estimating probabilities Problem: – What if attribute value ai never observed for class vj? – Estimate P(ai|vj)=0 because count(ai and vj) = 0 ? • Effect is too strong: this 0 makes the whole product 0! Solution: use m-estimate – interpolates between observed value nc/n and a priori estimate p -> estimate may get close to 0 but never 0 • m is weight given to a priori estimate nc mp ˆ P(ai | v j ) nm Learning to classify text Example application: – given text of newsgroup article, guess which newsgroup it is taken from – Naïve bayes turns out to work well on this application – How to apply NB? – Key issue : how do we represent examples? what are the attributes? Representation Binary classification (+/-) or multiple classes possible Attributes = word frequencies – Vocabulary = all words that occur in learning task – # attributes = size of vocabulary – Attribute value = word count or frequency in the text (using m-estimate) = “Bag of Words” representation Algorithm procedure learn_naïve_bayes_text(E: set of articles, V: set of classes) Voc = all words and tokens occurring in E estimate P(vj) and P(wk|vj) for all wk in E and vj in V: Nj = number of articles of class j N = number of articles P(vj) = Nj/N nkj = number of times word wk occurs in text of class j nj = number of words in class j (counting doubles) P(wk|vj) = (nkj+1)/(nj+|Voc|) procedure classify_naïve_bayes_text(A: article) remove from A all words/tokens that are not in Voc return argmaxvjV P(vj) i P(ai|vj) Some (old) experimental results: – 1000 articles taken from 20 newsgroups – guess correct newsgroup for unseen documents – 89% classification accuracy with previous approach •Note: more recent approaches based on SVMs, … have been reported to work better – But Naïve Bayes still used in practice, e.g., for spam detection Bayesian Belief Networks Consider two extremes of spectrum: – guessing joint probability distribution • would yield optimal classifier • but infeasible in practice (too much data needed) – Naïve Bayes • much more feasible • but strong assumptions of conditional independence •Is there something in between? – make some independence assumptions, but only where reasonable Bayesian belief networks Bayesian belief network consists of 1: graph • intuitively: indicates which variables “directly influence” which other variables – arrow from A to B: A has direct effect on B – parents(X) = set of all nodes directly influencing X • formally: each node is conditionally independent of each of its non-descendants, given its parents – conditional independence: cf. Naïve Bayes – X conditionally independent of Y given Z iff P(X|Y,Z) = P(X|Z) 2: conditional probability tables • for each node X : P(X|parents(X)) is given Example • Burglary or earthquake may cause alarm to go off • Alarm going off may cause one of neighbours to call E -E B -B 0.05 0.95 Burglary Earthquake B,E B,-E A 0.9 0.8 -A 0.1 0.2 Alarm John calls J -J A -A 0.8 0.1 0.2 0.9 0.01 0.99 Mary calls M -M A -A 0.9 0.2 0.1 0.8 -B,E 0.4 0.6 -B,-E 0.01 0.99 Network topology usually reflects direct causal influences – other structure also possible – but may render network more complex Mary calls Earthquake Burglary John calls Alarm Alarm John calls Mary calls Burglary Earthquake Graph + conditional probability tables allow to construct joint probability distribution of all variables – P(X1,X2,…,Xn) = i P(Xi|parents(Xi)) – In other words: bayesian belief network carries full information on joint probability distribution Inference Given values for certain nodes, infer probability distribution for values of other nodes • General algorithm quite complicated – See, e.g., Russel & Norvig, 1995: Artificial Intelligence, a Modern Approach General case evidence (observed) to be predicted unobserved In general: inference is NP-complete – approximating methods, e.g. Monte-Carlo Learning bayesian networks • Assume structure of network given: – only conditional probability tables to be learnt – training examples may include values for all variables, or just for some of them – when all variables observable: • estimating probabilities as easy as for Naïve Bayes • e.g. estimate P(A|B,C) as count(A,B,C)/count(B,C) – when not all variables observable: • methods based on gradient descent or EM • When structure of network not given: – search for structure + tables • e.g. propose structure, learn tables • propose change to structure, relearn, see whether better results – active research topic To remember • Importance of Bayes’ theorem • MAP, ML, MDL – definitions, characterising learners from this perspective, relationship MDL-MAP • Bayes optimal classifier, Gibbs classifier • Naïve Bayes: how it works, assumptions made, application to text classification • Bayesian networks: representation, inference, learning