Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
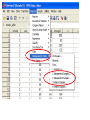
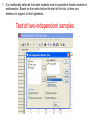
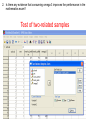
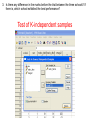
Non-parametric Tests With histograms like these, there really isn’t a need to perform the Shapiro-Wilk tests! Data exploration and Statistical analysis 1. Data checking, identifying problems and characteristics 2. Understanding chance and uncertainty 3. How will the data for one attribute behave, in a theoretical framework? 4. Theoretical framework assumes complete information, need to address uncertainties in real data 5. Testing your beliefs, do the data support what you think is true? 6. What happens when the assumptions of the theoretical framework are not valid Data Data exploration, categorical / numerical outcomes Model each outcome with a theoretical distribution Estimation of parameters, quantifying uncertainty Hypothesis testing Parametric tests (t-tests, ANOVA, test of proportions) Non-parametric tests (Wilcoxon, KruskalWallis, rank test) Non-parametric tests Used when: - assumptions on the distributions of the data are clearly not valid; - a small fraction of the data are considered outliers (either tail), but are not removed as they are experimentally valid (related to first reason above actually) - occasionally when sample sizes are small and it becomes meaningless looking at histograms or even using the ShapiroWilk tests Non-parametric equivalent For most parametric tests, there are non-parametric equivalents: Conceptual difference of non-parametric tests Parametric tests Uses the actual observed values of the outcomes in calculating the test statistics. Non-parametric tests Converts the observed values to ranks, and uses these ranks for comparisons (to calculate the test statistics). Test for one-sample One-sample t-test compares the mean of the sample to the hypothesized mean value under the null hypothesis. For the non-parametric test: One-sample Wilcoxon Signed Rank test It compares the median of the sample to the hypothesized median value under the null hypothesis. Null hypothesis Alternative hypothesis : Median = some value, m : Median m (two-sided hypothesis) Median > m (one-sided hypothesis) Median < m (one-sided hypothesis) Sign test Simple idea: Count the number of observations > m, out of a total number of observations N. If the null hypothesis is true, then on average, we expect about N / 2 observations to be greater than m, and about N / 2 observations to be less than m. So suppose x = number of observations > m. We can actually calculate the Binomial probability of having at least x observations out of N, when the probability that any observation will be > m is 50%. Let X ~ Binomial(N, 0.5) P(observation > m) = 0.5 P(at least x observations out of N > m) = Binomial probability of P(X x) However, this ignores the magnitude of the data, or the distance of each value from m. Wilcoxon Signed rank test 1. Calculate the difference between each value with m. 2. Note the sign of the difference, whether it is +ve or –ve difference. 3. Drop the sign, and rank the unsigned differences, from smallest (assigned a rank of 1) to largest (assigned a rank of N). 4. Restore the sign to the assigned ranks. 5. Sum up the positive ranks (W+), and also the negative ranks (W-, defined without the negative sign). 6. Conceptually, if the median of the data is genuinely closed to m, then W+ will be similar to W-. 7. If W+ >> W-, then this implies that there is evidence that the median of the data is > m. 8. If W- >> W+, then this implies that there is evidence that the median of the data is < m. Test for two independent samples Mann-Whitney U test (a.k.a. Wilcoxon rank-sum test) Again comparing the sum of ranks from two collection of data. Null hypothesis Alternative hypothesis : Distributions of both groups are the same* : Distributions of both groups are different * Formally speaking: Probability of (a randomly chosen observation from one group is > than a randomly chosen observation from the second group) = 0.5. Mann-Whitney U test Conceptually - Combine all the observations from the two groups into a single collection; - Assign ranks to these observations, from smallest as rank 1 to largest as rank N (where N represents the total number of observations when combining both groups) - Return the observations to the two groups they were originally from - Sum up the ranks of the observations in each of the two groups. - Conceptually expect the average ranks from both groups to be similar. The details of the test are actually more complex, and the student is strongly encouraged to find out more from the recommended textbooks (or online). Test for paired samples Sign test Same as the sign test encountered during the 1-sample test. However, here we are comparing the differences between the paired observations (which eventually yields only one set of outcome, and thus a “1-sample” test) Null hypothesis Alternative hypothesis : Probability that the difference is greater than 0 = 0.5 : Probability that the difference is greater than 0 0.5 Probability that the difference is greater than 0 > 0.5 Probability that the difference is greater than 0 < 0.5 Caveat: As before, the sign test only looks at the sign of the difference, but not the magnitude of the difference. So there is actually additional information that can be used. Remember! Statistics is about understanding and minimizing uncertainty, while trying to maximizing information! (or to make use of as much data as possible) Test for paired samples Wilcoxon signed rank test Again similar as the procedure introduced for 1-sample testing. But the focus here is on the differences between the paired observations. Null hypothesis Alternative hypothesis : Median of differences = 0 : Median of differences 0 Median of differences > 0 Median of differences < 0 Test for 2 independent samples Kruskal-Wallis test Compares the medians of all the groups to see whether they are equal. Null hypothesis Alternative hypothesis : Medians of all the groups are identical : At least one group has a different median Compare this with the hypotheses for ANOVA: Null hypothesis : Means of all the groups are identical Alternative hypothesis : At least one group has a different mean Test statistic Ri = sum of ranks in group i ni = number of observations in group i Which follows a chi-square distribution with k – 1 degrees of freedom. Kruskal-Wallis test As with ANOVA: - Tests a global hypothesis of no difference between any of the groups - Need to identify which groups are different in the event of a significant p-value (post-hoc tests of every possible pairwise comparisons with Mann-Whitney U test) - Post-hoc tests incur problem of multiple testing, standard Bonferroni correction required. Non-parametric equivalent For most parametric tests, there are non-parametric equivalents: Non-parametric versus parametric Question: If non-parametric tests are robust to issues pertaining to outliers, sample sizes and distributional assumptions, then why are they not the default tests to use? Answer: Parametric tests use the actual values for the comparisons, whereas non-parametric tests use only the ranks. This means the magnitude of the differences between the observations are not used, and a difference of 1 or a 100 may be reduced to just a difference in rank of 1. This actually reduces the power of the non-parametric test, relative to the parametric equivalent. Non-parametric tests in SPSS Consider the mathematics.xls dataset again. 1. It is traditionally believed that male students tend to outperform female students in mathematics. Based on the marks before the start of the trial, is there any evidence in support of this hypothesis. 2. Is there any evidence that consuming omega 3 improves the performance in the mathematics exam? 3. Is there any difference in the marks before the trial between the three schools? If there is, which school exhibited the best performance? 4. Is there any difference in the omega 3 consumption between male and female students? Let’s approach all these questions from the non-parametric perspective! 1. It is traditionally believed that male students tend to outperform female students in mathematics. Based on the marks before the start of the trial, is there any evidence in support of this hypothesis. Test of two-independent samples Mann-Whitney U test H0: Distributions of both groups are the same H1: Mean ranks for females < mean ranks for males 2. Is there any evidence that consuming omega 3 improves the performance in the mathematics exam? Test of two-related samples Sign test H0: Probability that the difference is greater than 0 = 0.5 H1: Probability that the difference is greater than 0 > 0.5 Wilcoxon Signed Rank Test H0: Median of differences = 0 H1: Median of differences > 0 Again to derive one tailed p-value, we need to half the p-value. 3. Is there any difference in the marks before the trial between the three schools? If there is, which school exhibited the best performance? Test of K-independent samples Kruskal-Wallis test Remember the need to perform separate 2-independent samples tests to identify the schools that are different – should the Kruskal Wallis test yields a significant result. H0: Medians of all the groups are identical H1: At least one group has a different median 4. Is there any difference in the omega 3 consumption between male and female students? Test of 2-independent samples Mann-Whitney U test Based on the outcome of this analysis, there is no evidence to suggest that there is a difference in omega 3 consumption between male and female students. Students should be able to • understand the difference between a parametric and nonparametric test • know when a parametric test should be used and when a nonparametric test should be used instead • know the relative advantages and disadvantages of a nonparametric test • know which non-parametric test should be used under the specific scenario • perform the appropriate analyses in SPSS and RExcel