Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Spatial Temporal Data Mining
Wei Wang
Data Mining Lab, UCLA
January 21, 1999
Outline
•
•
•
•
Introduction
Statistical Clustering
User-defined Trigger
Spatial Index Structure for High
Dimensional Point Data
• Temporal Spatial Pattern Detection
– ongoing research
Introduction
• Spatial data mining has been an active research
area during recent years.
– For some well know problem, e.g., clustering, many
existing algorithms are not efficient enough.
• There is still room for improvement.
– There are a lot of interesting problems remaining
uninvestigated.
– We classify a subset of problems and try to solve them
efficiently.
Outline
• STING: a statistical information grid approach
to spatial data mining
• STING+: an approach to active spatial data
mining
• PK-tree: a spatial index structure for high
dimensional point data
• Temporal spatial pattern detection
STING
• Spatial database is usually huge.
– Efficiency of the data mining algorithm is crucial.
• Example: each person is an object
– Query: Find high income area within California
• high income: salary > $50,000
• area > 4 square miles
– Traditional Method
•
•
•
•
Step 1: Select out all person whose salary are high.
Step 2: Do clustering analysis on those persons selected out.
Step 3: Form the region that each cluster occupies.
Step 4: Return those regions larger than 4 square miles.
– If “high income” is defined as: 80% persons have salary > $50,000
• then the previous method can not even answer the query.
• STING was proposed to solve such problem efficiently.
STING
• Region Query Example:
– Select the maximal regions that have at least 100
houses per unit area and at least 70% of the house
prices are above $400K and with total area at least 100
units with 90% confidence.
SELECT REGION
FROM house-map
WHERE DENSITY IN (100, )
AND price RANGE (400000, )
WITH PERCENT (0.7, 1)
AND AREA (100, )
AND WITH CONFIDENCE 0.9
STING
• Objects are represented by points, each of which
has associated spatial attributes, its location, and
non-spatial (numerical) attributes.
• Space is recursively divided into smaller
rectangular cells until certain level is reached.
– A hierarchical structure is employed.
– The average number of objects in a leaf cell is in the
range from several dozens to several thousands.
• Preprocess data
– capture the statistical information
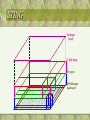
STING
1st layer
(root)
(i-1)th layer
ith layer
(i+1)th layer
(leaf layer)
STING
• For each cell, we have
– attribute-independent parameter
• n: number of objects
– attribute-dependent parameters (for each numerical attribute)
•
•
•
•
•
mean: mean value of the attribute
std: standard deviation of the attribute value
min: the minimum value of the attribute
max: the maximum value of the attribute
distribution: the type of distribution that best fits the attribute value
(can be NONE)
• Bottom-up generation when the data is loaded into the
database.
– Linear compilation time
– Only has to be done once not for each query.
STING
• Take advantage of the statistical information
captured.
• Only go through relevant cells at each level.
– Root is relevant.
– For each relevant cell, we exam its children at next
level by statistical test and label them as relevant or not
relevant.
– Form regions from relevant leaf level cells.
• Do not need to access full database.
– It is very efficient.
STING
Query Answering Time (sec)
• The computational complexity of STING is linearly proportional to
the number of leaf cells.
• We used the SEQUOIA 2000 benchmark as the data set to compare the
performance of STING with other approaches.
3.5
3
DBSCAN
2.5
2
1.5
1
STING
0.5
0
0
2000
4000
6000
8000
10000 12000 14000
Number of points
STING
• STING is a query-independent approach.
– The statistical information exists independently of queries.
• STING has a much smaller response time compared to
other approaches
– The computational complexity is linearly proportional to the
number of leaves.
– I/O cost is low.
• STING can support different resolution of query result.
• Regions returned by STING approach that returned by
DBSCAN when the granularity approaches zero.
• Parameters in the hierarchical structure can be maintained
efficiently by incremental update.
Outline
• STING: a statistical information grid approach to
spatial data mining
• STING+: an approach to active spatial data
mining
• PK-tree: a spatial index structure for high
dimensional point data
• Temporal spatial pattern detection
STING+
• Moreover, since objects evolve, interesting patterns may
emerge or disappear over time.
• Example:
– Trigger: Do bandwidth reallocation when the average call length
is greater than 10 minutes within the region where at least 10
cellular phones are in use per squared mile.
• This can not be supported by traditional database triggers
efficiently
– due to the fact that the class membership of an object is not only
determined by its non-spatial attributes but also by the attributes of
objects in its neighborhood.
• Naïve approach: re-evaluate condition periodically.
– Not efficient.
STING+
• STING+ was an extension of STING to support userdefined trigger.
• In spatial databases, object insertion, deletion, and update
are primitive events.
• Observation: Usually, only the cumulative effect of a set
of primitive events may cause the trigger condition to be
true.
... .................. + +
. .. ... .. ++++
+
+
+
+
• We refer such set of primitive events to as a composite
events.
STING+
• Condition-Action paradigm
– In general, it is difficult or even impossible for user to specify all
possible composite events that may cause the trigger condition to
be true.
• In general, evaluating a user-defined trigger T usually
involves two aspects:
– Find a set of composite events E(s) that may cause the trigger
condition CT to become true.
– Each time some composite event in E(s) occurs, check the status
(false or true) of CT (given that CT was false previously).
STING+
• Observation: As a side effect of the occurrence of some composite
event, the set of composite events E(s) that could cause CT to
transition from false to true might also evolve over time.
... .................. + +
. .. ... .. ++++
+
+
+
+
+.+ +++
+
...++.................+++ +
. .. ... .. ++++
+
++
+
• Two set of composite events we need to consider:
– the set of composite events E(s) that can cause CT to become true
• need to re-evaluate CT
– the set of composite events F(s) that can cause a change to E(s)
• need to update E(s)
STING+
• Observation: In spatial databases, the effect of an event is usually
local to its neighborhood.
.. ... .x .
. ... ...
o1
.
. ..
x
o2
• STING+ decomposes the user-defined trigger into a set of subtriggers associated with individual cells in the hierarchical structure.
– These sub-triggers are used to monitor composite events in E(s) and F(s)
and change accordingly when E(s) and F(s) evolves.
.. .... .. .
.. ...
.
. ..
Level 4
.. .... .. .
.. ...
.
. ..
Level 3
STING+
.. .... .. .
.. ...
.
. ..
.. .... .. .
.. ...
.
Level 2
. ..
Level 1
• Updates are suspended at some level in the hierarchy until such time
that the cumulative effect of these updates might cause the trigger
condition to become satisfied.
.. ...+. .
. ... ...
.
. ..
.. ...+. .
. ... ... +
.
Level 1
.. ...+. .
. ... ... +
.
. ..
Level 2
. ..
Level 1
.. ...+. .
. ... ... +
.
. ..
Level 3
STING+
• Example: Trigger bandwidth reallocation when the total
area occupied by those regions in California where at least
10 cellular phones are in use per squared mile and the
average length of phone calls is at least 15 minutes with
total area at least 50 squared miles increases by at least 10
squared miles.
DEFINE TRIGGER example
ON cellular-phone
WHEN SELECT SIZE(REGION) INCREASE RANGE (10, )
WHERE DENSITY IN RANGE (10, )
AND AVERAGE(length) IN RANGE (15, )
AND AREA IN RANGE (50, )
LOCATION California
DO bandwidth-reallocation
STING+
•
Observation: Trigger condition CT is a conjunction of predicates P1 P2
… Pn and can not be true if one predicate is false.
– They can be evaluated in a certain order: the ith predicate is tested when all
previous i -1 predicates are true.
– The evaluation order should be chosen in such a way that the total cost is
minimum.
•
STING+ evaluates CT in the order {location, density condition, attribute
condition}, each of which is evaluated in a different phase.
– Location only needs to be evaluated once and the cost can be regarded as constant
in the trigger evaluation process.
– If the location is fixed, unnecessary sub-triggers set on cells outside the location
can be avoided and hence save the evaluation cost of other predicates.
– Sub-triggers set during an earlier phase will exist longer than those set in a later
phase.
• It is better to first evaluate the predicate that takes less time to handle.
• cost(density) < cost(attribute)
STING+
• Average CPU cycles for handling each type of sub-trigger
Density condition Attribute condition Movement
insertion deletion inside
outside expand shrink
Intermediate 3812
level
Leaf
level
8055
3803
3789
3807
N/A
N/A
5775
11212
8164
2126
2087
STING+
Outline
• STING: a statistical information grid approach to
spatial data mining
• STING+: an approach to active spatial data
mining
• PK-tree: a spatial index structure for high
dimensional point data
• Temporal spatial pattern detection
PK-tree
• As both the number of objects and the number of attributes
are very large, it is essential to organize the set of objects
by some dynamic indexing structure.
• Point index methods
Index Method
PR Quad-tree
K-D-B-tree
SR-tree
X-tree
PK-tree
Overlapping
Siblings
No
No
Yes
Yes
No
Height
Unbounded
Unbounded
log(N)
log(N)
log(N)
Bounded
Node Size
Yes
Yes
Yes
No
Yes
Bounded
Storage
No
No
Yes
Yes
Yes
PK-tree
.
.
.
. .
. .
. . .
. . .
. .
. .
. . .
.
Level 0
.
.
.
. .
. .
. . .
. . .
. .
. .
. . .
.
Level 1
.
.
.
. .
. .
. . .
. . .
. .
. .
. . .
.
Level 2
.
.
.
. .
. .
. . .
. . .
. .
. .
. . .
.
Level 3
Spatial decomposition: Space is recursively divided until a level
LD such that each cell contains at most one point.
PK-tree
Example of a PR Quad-tree: 16 intermediate nodes, height = 3
1
2
3
4
5
6
7
8
.
.
.
. .
. .
1
2
3
4
5
6
7
8
. .
. .
. . .
.
. . .
. . .
. .
. A B . .C .D .
.
. .
E. F
G H
. . .
K. L
. . .
M. .N.
1
2
3
4
5
6
7
8
.
Q.
. .
. .
.
. .S .
. . .
. .
.R .
. . .
.
T
a b c d e f g h
a b c d e f g h
a b c d e f g h
Level 3 (LD)
Level 2
Level 1
root
Q
A
B
R
E F
C
G
S
B
G
M
T
N
K
L
a2 d1 d2 b4 c3 e1 e2 f3 g2 h2 g3 a7 b7 b8 d7 c8 d8 e5 f5 f6 g5
PK-tree
Example of a PK-tree of rank 3: 5 intermediate nodes, height = 2
1
2
3
4
5
6
7
8
.
.
.
. .
. .
. . .
. . .
. .
. .
. . .
.
1
2
3
4
5
6
7
8
.
.
.
. .
. .
. . .
M. .N.
. .
. .
. . .
K.
1
2
3
4
5
6
7
8
.
Q.
. .
. .
.
. . .
M. .N.
. .
.R .
. . .
K.
a b c d e f g h
a b c d e f g h
a b c d e f g h
Level 3 (LD)
Level 2
Level 1
root
Q
R
M
N
K
a2 d1 d2 b4 c3 e1 e2 f3 g2 h2 g3 a7 b7 b8 d7 c8 d8 e5 f5 f6 g5
PK-tree
• PK-tree employs a concept of K-instantiable cell to
eliminate unnecessary nodes.
– Point cell: a non-empty cell at level LD
– A cell C is K-instantiable iff
• C is a point cell, or
• there does not exist (K-1) or less K-instantiable sub-cells to cover all
non-empty space in C
– Only K-instantiable cells serve as nodes in the PK-tree (expect the
root).
– The parent-child relationship follows naturally from the cellsubcell relationship.
PK-tree
• Properties:
– Bounds on node’s outdegree
• allows allocating one node to a page
– Bounded storage space
– Existence and Uniqueness
• enables us to analyze the behavior of a PK-tree easier.
– Expected height
• log(N) under some general condition
• guarantees efficiency of retrieval and update.
– No overlapping among sibling nodes
• efficient retrieval
• Empirical studies shown that the PK-tree outperforms SRtree and X-tree by a wide margin.
PK-tree
Height of generated trees on 100,000 points
Dimension
2
4
8
16
32
64
PK-tree (u)
4
4
5
6
7
9
PK-tree (c1)
5
7
7
6
7
8
PK-tree (c2)
7
7
6
7
8
9
X-tree
4
4
4
4
5
6
SR-tree
4
4
5
5
6
7
Size of index in MB
Dimension
2
4
8
16
u
c1
c2
u
c1
c2
u
c1
c2
u
c1
c2
PK-tree
1.8
1.9
1.9
2.8
2.8
2.8
4.9
4.8
4.9
9.4
9.3
9.4
X-tree
1.8
1.8
1.8
3.0
3.0
3.0
5.6
5.5
5.6
10.7
10.4
10.6
SR-tree
69
70
70
74
73
74
74
74
75
90
91
92
PK-tree
KNN query on clustered data distribution
PK-tree
• Real data set: NASA Sky Telescope Data
– 200,000 two-dimensional points (they are the coordinates of crater
locations on the surface of Mars)
height size
PK-tree 5
3.7MB
KNN
CPU
4ms
X-tree
5.7MB
90ms
4
10ms
4
120MB 28ms
8
14ms
6
4
SR-tree 5
KNN RAN
I/O
CPU
4
3ms
RAN
I/O
4
Outline
• STING: a statistical information grid approach to
spatial data mining
• STING+: an approach to active spatial data
mining
• PK-tree: a spatial index structure for high
dimensional point data
• Temporal spatial pattern detection
Temporal Spatial Pattern Detection
• When the number of attributes is large and/or the value of
attributes evolve frequently, the complexity of patterns and
the number of potential patterns increase.
– It is not desirable or even feasible to ask the user specify
interesting patterns.
– E.g., the user wants to know any possible patterns involving
certain attributes such as salary, rent, cellular phone usage, etc.
– Existing association rule algorithm can not be applied.
• Continuous attribute domain
• Temporal evolution
• Prior knowledge about relationships among attributes and objects
Temporal Spatial Pattern Detection
• Object represented by point
– primitive attributes
• spatial attributes, i.e., coordinates of its position
• non-spatial attributes, e.g., name, weight, height, salary, rent
– derived attributes derived from primitive attribute(s)
• environment attributes, e.g., distance to a hospital, average income in the
neighborhood area
• Consider a sequence of snapshots S1, S2, …, Sn
• Temporal Spatial Pattern
– describes a possible relationship among evolution of attributes
• E.g., if the user want to know patterns involving salary and distance to big
city, then one interesting pattern would be “people receiving a raise tends to
move further away from the big city from 1987 to 1993.”.
Temporal Spatial Pattern Detection
• More complicated patterns
– Patterns on clustering evolution
– Patterns of high order
– Patterns whose cause and consequence do not happen together
• There is a delay for the consequence to show up.
– Patterns involving relationships among objects
• e.g., people who live far away from any doctor tend to move to a
place closer to some doctor.
– Environment variables evolve independently over time.