Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
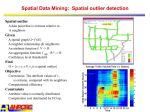
Spatial Data Mining: Spatial outlier detection
Spatial outlier
A data point that is extreme relative to
it neighbors
Given
A spatial graph G={V,E}
A neighbor relationship (K neighbors)
An attribute function f: V -> R
An aggregation function f aggr : R k -> R
Confidence level threshold
Find
O = {vi | vi V, vi is a spatial outlier}
Objective
Correctness: The attribute values of vi
is extreme, compared with its neighbors
Computational efficiency
Constraints
Attribute value is normally distributed
Computation cost dominated by I/O op.
Spatial Data Mining: Spatial outlier detection
Spatial Outlier Detection Test
1. Choice of Spatial Statistic
S(x) = [f(x)–E y N(x)(f(y))]
Theorem: S(x) is normally distributed
if f(x) is normally distributed
2. Test for Outlier Detection
| (S(x) - s) / s | >
Hypothesis
I/O cost determined by clustering efficiency
f(x)
Spatial outlier and its neighbors
S(x)
Spatial Data Mining: Spatial outlier detection
Results
1. CCAM achieves higher
clustering efficiency (CE)
2. CCAM has lower I/O cost
3. Higher CE leads to lower
I/O cost
4. Page size improves CE for
all methods
Cell-Tree
CE value
I/O cost
CCAM
Z-order