Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
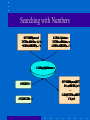
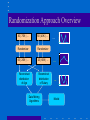
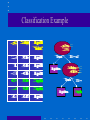
New Directions in Data Mining Ramakrishnan Srikant Directions • Electronic Commerce & Web – Catalog Integration (WWW 2001, with R. Agrawal) – Searching with Numbers (WWW 2002, with R. Agrawal) • Security • Privacy Catalog Integration • B2B electronics portal: 2000 categories, 200K datasheets I C s D S P M e m . L o g i c I C s C a t 2 C a t 1 a b x y c z d e w f Master Catalog New Catalog Catalog Integration (cont.) • After integration: I C s o g i c M e m . L D S P a b x y c d e f z Goal • Use affinity information in new catalog. – Products in same category are similar. • Accuracy boost depends on match between two categorizations. Intuition behind Algorithm Standard Algorithm Enhanced Algorithm C o m p u t e r D i g i t a l P e r i p h e r a l C a m e r a P 1 2 0 % 8 0 % P 2 4 0 % 6 0 % P 3 6 0 % 4 0 % C o m p u t e r D i g i t a l P e r i p h e r a l C a m e r a P 1 1 5 % 8 5 % P 2 3 0 % 7 0 % P 3 4 5 % 5 5 % Problem Statement • Given – master categorization M: categories C1, C2, …, Cn • set of documents in each category – new categorization N: set of categories S1, S2, …, Sn • set of documents in each category • Standard Alg: Compute Pr(Ci | d) • Enhanced Alg: Compute Pr(Ci | d, S) Enhanced Naïve Bayes classifier Pr(Ci | d , S ) Pr(Ci | S ) Pr( d | Ci ) Pr( d | S ) | Ci | (# docs in S predicted to be in Ci ) w Pr(Ci | S ) j (| C j | (# docs in S predicted to be in C j )w ) • Use tuning set to determine w. – Defaults to standard Naïve Bayes if w = 0. • Only affects classification of borderline documents. Yahoo & Google • 5 slices of the hierarchy: Autos, Movies, Outdoors, Photography, Software – Typical match: 69%, 15%, 3%, 3%, 1%, …. • Merging Yahoo into Google – 30% fewer errors (14.1% absolute difference in accuracy) • Merging Google into Yahoo – 26% fewer errors (14.3% absolute difference) • Open Problems: SVM, Decision Tree, ... Directions • Electronic Commerce & Web – Catalog Integration (WWW 2001, with R. Agrawal) – Searching with Numbers (WWW 2002, with R. Agrawal) • Security • Privacy Data Extraction is hard • Synonyms for attribute names and units. – "lb" and "pounds", but no "lbs" or "pound". • Attribute names are often missing. – No "Speed", just "MHz Pentium III" – No "Memory", just "MB SDRAM" • 850 MHz Intel Pentium III • 192 MB RAM • 15 GB Hard Disk • DVD Recorder: Included; • Windows Me • 14.1 inch diplay • 8.0 pounds Searching with Numbers I B M T h i n k p a d 7 5 0 M h z P e n t i u m 3 , 1 9 6 M b R D R A M , . . . D e l l C o m p u t e r 7 0 0 M H z C e l e r o n , 2 5 6 M b S D R A M , . . . C a t a l o g D a t a b a s e 8 0 0 2 0 0 8 0 0 2 0 0 3 l b I B M T h i n k p a d ( 7 5 0 M h z , 1 9 6 M b ) . . . D e l l ( 7 0 0 M h z , 2 5 6 M b ) Why does it work? • Conjecture: If we get a close match on numbers, it is likely that we have correctly matched attribute names. • Non-overlapping attributes: – Memory: 64 - 512 Mb, Disk: 10 - 40 Gb • Correlations: – Memory: 64 - 512 Mb, Disk: 10 - 100 Gb still fine. • Screen Shot Empirical Results 100 R e c o r d sF i e l d s 1 0 80 L C D 1 , 7 0 0 1 2 60 P r o c 1 , 1 0 0 1 2 T r a n s 2 2 , 2 7 3 2 4 A u t o 2 0 5 1 6 C r e d i t 6 6 6 6 G l a s s 2 1 4 1 0 H o u s i n g 5 0 6 1 4 W i n e 1 7 9 1 4 Acuracy D R A M 3 , 8 0 0 40 20 0 1 2 34 5 Q uer y S DRAM T ran G ls as L CD Au Ho to u s P ro Cred cW i in t e Incorporating Hints • Use simple data extraction techniques to get hints, 2 5 6 M B S D R A M m e m o r y U n i t H i n t : A t t r i b u t e H i n t : M B S D R A M , M e m o r y • Names/Units in query matched against Hints. • Open Problem: Rethink data extraction in this context. Other Problems • P. Domingos & M. Richardson, Mining the Network Value of Customers, KDD 2001 • Polling over the Web Directions • Electronic Commerce & Web • Security • Privacy Security " F r e q u e n t T r a v e l e r " R a t i n g M o d e l E m a i l C r e d i t g e n c i e s D e m o - C r i m i n a l A P h o n eg r a p h i c R e c o r d s S t a t e B i r t hM a r r i a g e L o c a l Some Hard Problems • Past may be a poor predictor of future – Abrupt changes • Reliability and quality of data – Wrong training examples • Simultaneous mining over multiple data types • Richer patterns Directions • Electronic Commerce & Web • Security • Privacy – – – – Motivation Randomization Approach Crytographic Approach Challenges Growing Privacy Concerns • Popular Press: – Economist: The End of Privacy (May 99) – Time: The Death of Privacy (Aug 97) • Govt. directives/commissions: – European directive on privacy protection (Oct 98) – Canadian Personal Information Protection Act (Jan 2001) • Special issue on internet privacy, CACM, Feb 99 • S. Garfinkel, "Database Nation: The Death of Privacy in 21st Century", O' Reilly, Jan 2000 Privacy Concerns (2) • Surveys of web users – 17% privacy fundamentalists, 56% pragmatic majority, 27% marginally concerned (Understanding net users' attitude about online privacy, April 99) – 82% said having privacy policy would matter (Freebies & Privacy: What net users think, July 99) Technical Question • Fear: – "Join" (record overlay) was the original sin. – Data mining: new, powerful adversary? • The primary task in data mining: development of models about aggregated data. • Can we develop accurate models without access to precise information in individual data records? Directions • Electronic Commerce & Web • Security • Privacy – Motivation – Randomization Approach • R. Agrawal and R. Srikant, “Privacy Preserving Data Mining”, SIGMOD 2000. – Crytographic Approach – Challenges Web Demographics • Volvo S40 website targets people in 20s – Are visitors in their 20s or 40s? – Which demographic groups like/dislike the website? Randomization Approach Overview 30 | 70K | ... 50 | 40K | ... Randomizer Randomizer 65 | 20K | ... 25 | 60K | ... Reconstruct distribution of Age Reconstruct distribution of Salary Data Mining Algorithms ... ... ... Model Reconstruction Problem • Original values x1, x2, ..., xn – from probability distribution X (unknown) • To hide these values, we use y1, y2, ..., yn – from probability distribution Y • Given – x1+y1, x2+y2, ..., xn+yn – the probability distribution of Y Estimate the probability distribution of X. Intuition (Reconstruct single point) • Use Bayes' rule for density functions 1 0V A g e 9 0 O r i g i n a l d i s t r i b u t i o n f o r A g e P r o b a b i l i s t i c e s t i m a t e o f o r i g i n a l v a l u e o f V Intuition (Reconstruct single point) • Use Bayes' rule for density functions 1 0V A g e 9 0 O r i g i n a l D i s t r i b u t i o n f o r A g e P r o b a b i l i s t i c e s t i m a t e o f o r i g i n a l v a l u e o f V Reconstructing the Distribution • Combine estimates of where point came from for all the points: – Gives estimate of original distribution. 1 0 A g e 9 0 Reconstruction: Bootstrapping fX0 := Uniform distribution j := 0 // Iteration number repeat j n 1 f (( x y ) a ) f Y i i X (a ) j+1 fX (a) := (Bayes' rule) j n i 1 fY (( xi yi ) a ) f X (a ) j := j+1 until (stopping criterion met) • Converges to maximum likelihood estimate. – D. Agrawal & C.C. Aggarwal, PODS 2001. Seems to work well! Number of People 1200 1000 800 Original Randomized Reconstructed 600 400 200 0 20 60 Age Recap: Why is privacy preserved? • Cannot reconstruct individual values accurately. • Can only reconstruct distributions. Classification • Naïve Bayes – Assumes independence between attributes. • Decision Tree – Correlations are weakened by randomization, not destroyed. Algorithms • “Global” Algorithm – Reconstruct for each attribute once at the beginning • “By Class” Algorithm – For each attribute, first split by class, then reconstruct separately for each class. • Associate each randomized value with a reconstructed interval & run decision-tree classifier. – See SIGMOD 2000 paper for details. Experimental Methodology • Compare accuracy against – Original: unperturbed data without randomization. – Randomized: perturbed data but without making any corrections for randomization. • Test data not randomized. • Synthetic data benchmark from [AGI+92]. • Training set of 100,000 records, split equally between the two classes. Synthetic Data Functions • F3 ((age < 40) and (((elevel in [0..1]) and (25K <= salary <= 75K)) or ((elevel in [2..3]) and (50K <= salary <= 100K))) or ((40 <= age < 60) and ... • F4 (0.67 x (salary+commission) - 0.2 x loan - 10K) > 0 Quantifying Privacy • Add a random value between -30 and +30 to age. • If randomized value is 60 – know with 90% confidence that age is between 33 and 87. • Interval width amount of privacy. – Example: (Interval Width : 54) / (Range of Age: 100) 54% randomization level @ 90% confidence Acceptable loss in accuracy 100% Randomization Level 100 Accuracy 90 Original Randomized ByClass Global 80 70 60 50 40 Fn 1 Fn 2 Fn 3 Fn 4 Fn 5 Accuracy vs. Randomization Level Accuracy Fn 3 100 90 80 70 60 50 40 Original Randomized ByClass 10 20 40 60 80 100 Randomization Level 150 200 Directions • Electronic Commerce & Web • Security • Privacy – Motivation – Randomization Approach – Crytographic Approach • Y. Lindell and B. Pinkas, “Privacy Preserving Data Mining”, Crypto 2000. – Challenges Inter-Enterprise Data Mining • Problem: Two parties owning confidential databases wish to build a decision-tree classifier on the union of their databases, without revealing any unnecessary information. • Horizontally partitioned. – Records (users) split across companies. – Example: Credit card fraud detection model. • Vertically partitioned. – Attributes split across companies. – Example: Associations across websites. Cryptographic Adversaries • Malicious adversary: can alter its input, e.g., define input to be the empty database. • Semi-honest (or passive) adversary: Correctly follows the protocol specification, yet attempts to learn additional information by analyzing the messages. Yao's two-party protocol • • • • Party 1 with input x Party 2 with input y Wish to compute f(x,y) without revealing x,y. Yao, “How to generate and exchange secrets”, FOCS 1986. Private Distributed ID3 • Key problem: find attribute with highest information gain. • We can then split on this attribute and recurse. – Assumption: Numeric values are discretized, with n-way split. Information Gain • Let – T = set of records (dataset), – T(ci) = set of records in class i, – T(ci,aj) = set of records in class i with value(A) = aj. – Entropy(T) = i | T (ci ) | | T ( ci ) | log |T | |T | | T (aj ) | Entropy(T( aj)) – Gain(T,A) = Entropy(T) - j |T | • Need to compute – Sj Si |T(aj, ci)| log |T(aj, ci)| – Sj |T(aj)| log |T(aj)|. Selecting the Split Attribute • Given v1 known to party 1 and v2 known to party 2, compute (v1 + v2) log (v1 + v2) and output random shares. – Party 1 gets Answer - d – Party 2 gets d, where d is a random number • Given random shares for each attribute, use Yao's protocol to compute information gain. Summary (Cryptographic Approach) • Solves different problem (vs. randomization) – Efficient with semi-honest adversary and small number of parties. – Gives the same solution as the non-privacy-preserving computation (unlike randomization). – Will not scale to individual user data. • Can we extend the approach to other data mining problems? – J. Vaidya and C.W. Clifton, “Privacy Preserving Association Rule Mining in Vertically Partitioned Data”, KDD 2002 Directions • Electronic Commerce • Security • Privacy – – – – Motivation Randomization Approach Crytographic Approach Challenges Challenges • Application: Privacy-Sensitive Security Profiling • Privacy Breaches • Clustering & Associations Privacy-sensitive Security Profiling • Heterogeneous, distributed data. • New domains: text, graph " F r e q u e n t T r a v e l e r " R a t i n g M o d e l E m a i l C r e d i t g e n c i e s D e m o - C r i m i n a l A P h o n eg r a p h i c R e c o r d s S t a t e B i r t hM a r r i a g e L o c a l Potential Privacy Breaches • Distribution is a spike. – Example: Everyone is of age 40. • Some randomized values are only possible from a given range. – Example: Add U[-50,+50] to age and get 125 True age is 75. – Not an issue with Gaussian. Potential Privacy Breaches (2) • Most randomized values in a given interval come from a given interval. – Example: 60% of the people whose randomized value is in [120,130] have their true age in [70,80]. – Implication: Higher levels of randomization will be required. • Correlations can make previous effect worse. – Example: 80% of the people whose randomized value of age is in [120,130] and whose randomized value of income is [...] have their true age in [70,80]. • Challenge: How do you limit privacy breaches? Clustering • Classification: ByClass partitioned the data by class & then reconstructed attributes. – Assumption: Attributes independent given class attribute. • Clustering: Don’t know the class label. – Assumption: Attributes independent. • Global (latter assumption) does much worse than ByClass. • Can we reconstruct a set of attributes together? – Amount of data needed increases exponentially with number of attributes. Associations • Very strong correlations Privacy breaches major issue. • Strawman Algorithm: Replace 80% of the items with other randomly selected items. – 10 million transactions, 3 items/transaction, 1000 items – <a, b, c> has 1% support = 100,000 transactions – <a, b>, <b, c>, <a, c> each have 2% support • 3% combined support excluding <a, b, c> – Probability of retaining pattern = 0.23 = 0.8% • 800 occurrences of <a, b, c> retained. – Probability of generating pattern = 0.8 * 0.001 = 0.08% • 240 occurrences of <a, b, c> generated by replacing one item. – Estimate with 75% confidence that pattern was originally present! • Ack: Alexandre Evfimievski Associations (cont.) • "Where does a wise man hide a leaf? In the forest. But what does he do if there is no forest?" ... "He grows a forest to hide it in." -- G.K. Chesterton • A. Evfimievski, R. Srikant, R. Agrawal, J. Gehrke, “Privacy Preserving Mining of Association Rules”, KDD 2002. • S. Rizvi, J. Haritsa, “Privacy-Preserving Association Rule Mining”, VLDB 2002. Summary (Privacy) • Have your cake and mine it too! – Preserve privacy at the individual level, but still build accurate models. • Challenges – Privacy Breaches, Security Applications, Clustering & Associations • Opportunities – Web Demographics, Inter-Enterprise Data Mining, Security Applications Slides available from ... www.almaden.ibm.com/cs/people/srikant/talks.html Backup Classification Example A g e S a l a r y R e p e a t V i s i t o r ? 2 35 0 K R e p e a t 1 73 0 K R e p e a t 4 34 0 K R e p e a t 6 85 0 K S i n g l e 3 27 0 K S i n g l e 2 02 0 K R e p e a t A g e < 2 5 N o Y e s R e p e a t S a l a r y < 5 0 K Y e s N o R e p e a t S i n g l e Work in Statistical Databases • Provide statistical information without compromising sensitive information about individuals (surveys: AW89, Sho82) • Techniques – Query Restriction – Data Perturbation • Negative Results: cannot give high quality statistics and simultaneously prevent partial disclosure of individual information [AW89] Statistical Databases: Techniques • Query Restriction – restrict the size of query result (e.g. FEL72, DDS79) – control overlap among successive queries (e.g. DJL79) – suppress small data cells (e.g. CO82) • Output Perturbation – sample result of query (e.g. Den80) – add noise to query result (e.g. Bec80) • Data Perturbation – replace db with sample (e.g. LST83, LCL85, Rei84) – swap values between records (e.g. Den82) – add noise to values (e.g. TYW84, War65) Statistical Databases: Comparison • We do not assume original data is aggregated into a single database. • Concept of reconstructing original distribution. – Adding noise to data values problematic without such reconstruction.