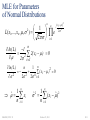Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
II.2 Statistical Inference: Sampling and Estimation A statistical model Μ is a set of distributions (or regression functions), e.g., all uni-modal, smooth distributions. Μ is called a parametric model if it can be completely described by a finite number of parameters, e.g., the family of Normal distributions for a finite number of parameters μ, σ: f X ( x; , ) IR&DM, WS'11/12 1 2 2 e ( x )2 2 2 October 25, 2011 for R, 0 II.1 Statistical Inference Given a parametric model M and a sample X1,...,Xn, how do we infer (learn) the parameters of M? For multivariate models with observed variable X and „outcome (response)“ variable Y, this is called prediction or regression, for a discrete outcome variable this is also called classification. r(x) = E[Y | X=x] is called the regression function. IR&DM, WS'11/12 October 25, 2011 II.2 Idea of Sampling Distribution X Statistical Inference (e.g., a population, objects of interest) What can we say about X based on X1,…,Xn? Distrib. Param. μX X2 N Sample Param. mean variance size Samples X1,…,Xn drawn from X (e.g., people, objects) X S X2 n Example: Suppose we want to estimate the average salary of employees in German companies. Sample 1: Suppose we look at n=200 top-paid CEOs of major banks. Sample 2: Suppose we look at n=100 employees across all kinds of companies. IR&DM, WS'11/12 October 25, 2011 II.3 Basic Types of Statistical Inference Given a set of iid. samples X1,...,Xn ~ X of an unknown distribution X. e.g.: n single-coin-toss experiments X1,...,Xn ~ X: Bernoulli(p) • Parameter Estimation e.g.: - what is the parameter p of X: Bernoulli(p) ? - what is E[X], the cdf FX of X, the pdf fX of X, etc.? • Confidence Intervals e.g.: give me all values C=(a,b) such that P(pC) ≥ 0.95 where a and b are derived from samples X1,...,Xn • Hypothesis Testing e.g.: H0 : p = 1/2 IR&DM, WS'11/12 vs. H1 : p ≠ 1/2 October 25, 2011 II.4 Statistical Estimators A point estimator for a parameter of a prob. distribution X is a random variable ̂n derived from an iid. sample X1,...,Xn. 1 n Examples: X : X i Sample mean: n i 1 n 1 2 ( X X ) Sample variance: S X2 : i n 1 i 1 An estimator ̂n for parameter is unbiased if E[̂n ] = ; otherwise the estimator has bias E[̂n ] – . An estimator on a sample of size n is consistent if lim n P[| ˆn | ] 1 for any 0 Sample mean and sample variance are unbiased and consistent estimators of μX and X2 . IR&DM, WS'11/12 October 25, 2011 II.5 Estimator Error Let ̂n be an estimator for parameter over iid. samples X1, ...,Xn. The distribution of ̂n is called the sampling distribution. The standard error for ̂n is: se(ˆn ) Var[ˆn ] The mean squared error (MSE) for ̂n is: MSE (ˆ ) E[(ˆ )2 ] n n bias 2 ( ˆn ) Var[ ˆn ] Theorem: If bias 0 and se 0 then the estimator is consistent. The estimator ̂n is asymptotically Normal if ( ˆn ) / se converges in distribution to standard Normal N(0,1). IR&DM, WS'11/12 October 25, 2011 II.6 Types of Estimation • Nonparametric Estimation No assumptions about model M nor the parameters θ of the underlying distribution X “Plug-in estimators” (e.g. histograms) to approximate X • Parametric Estimation (Inference) Requires assumptions about model M and the parameters θ of the underlying distribution X Analytical or numerical methods for estimating θ Method-of-Moments estimator Maximum Likelihood estimator and Expectation Maximization (EM) IR&DM, WS'11/12 October 25, 2011 II.7 Nonparametric Estimation The empirical distribution function F̂n is the cdf that puts probability mass 1/n at each data point Xi: 1 n F̂n ( x ) i 1 I( X i x ) n 1 if X i x with I ( X i x) 0 if X i x A statistical functional (“statistics”) T(F) is any function over F, e.g., mean, variance, skewness, median, quantiles, correlation. The plug-in estimator of = T(F) is: ˆn T( Fˆn ) Simply use F̂n instead of F to calculate the statistics T of interest. IR&DM, WS'11/12 October 25, 2011 II.8 Histograms as Density Estimators Instead of the full empirical distribution, often compact data synopses may be used, such as histograms where X1, ...,Xn are grouped into m cells (buckets) c1, ..., cm with bucket boundaries lb(ci) and ub(ci) s.t. lb(c1) = , ub(cm ) = , ub(ci ) = lb(ci+1 ) for 1 i<m, and 1 n ˆ freqf (ci ) = f n ( x) v 1 I (lb (ci ) X v ub(ci )) n 1 n freqF (ci ) = Fˆn ( x) I ( X v ub(ci )) n v 1 Example: X1 = 1 X2 = 1 X3 = 2 X4 = 2 X5 = 2 X6 = 3 … X20=7 2 3 5 2 3 20 20 20 4 3 2 1 4 5 6 7 20 20 20 20 3.65 ˆ n 1 fX(x) 5/20 4/20 3/20 3/20 2/20 2/20 1 2 3 4 5 6 1/20 7 x Histograms provide a (discontinuous) density estimator. IR&DM, WS'11/12 October 25, 2011 II.9 Parametric Inference (1): Method of Moments Suppose parameter θ = (θ1,…,θk ) has k components. j j Compute j-th moment: j j ( ) E [ X ] x f X ( x) dx 1 n j j-th sample moment: ̂ j i 1 X i for 1 ≤ j ≤ k n Estimate parameter by method-of-moments estimator ̂n s.t. 1 (ˆn ) ˆ1 and (ˆ ) ˆ … and 2 n 2 … k (ˆn ) ˆ k (for the first k moments) Solve equation system with k equations and k unknowns. Method-of-moments estimators are usually consistent and asymptotically Normal, but may be biased. IR&DM, WS'11/12 October 25, 2011 II.10 Parametric Inference (2): Maximum Likelihood Estimators (MLE) Let X1,...,Xn be iid. with pdf f(x;θ). Estimate parameter of a postulated distribution f(x;) such that the likelihood that the sample values x1,...,xn are generated by this distribution is maximized. Maximum likelihood estimation: Maximize L(x1,...,xn; ) ≈ P[x1, ...,xn originate from f(x; )] Usually formulated as Ln() = ∏i f(Xi; ) Or (alternatively) Maximize ln() = log Ln() The value ̂n that maximizes Ln() is the MLE of . If analytically untractable use numerical iteration methods IR&DM, WS'11/12 October 25, 2011 II.11 Simple Example for Maximum Likelihood Estimator Given: • Coin toss experiment (Bernoulli distribution) with unknown parameter p for seeing heads, 1-p for tails • Sample (data): h times head with n coin tosses Want: Maximum likelihood estimation of p n n i 1 i 1 Let L(h, n, p) f ( X i ; p) p X i (1 p)1 X i p h (1 p) n h with h = ∑i Xi Maximize log-likelihood function: log L (h, n, p) h log( p) (n h) log( 1 p) h ln L h n h 0 p n p p 1 p IR&DM, WS'11/12 October 25, 2011 II.12 MLE for Parameters of Normal Distributions 1 2 L( x1 ,..., xn , , ) 2 n n e ( xi ) 2 2 2 i 1 ln( L ) 1 n 2( x ) 0 i 2 2 i 1 ln( L ) 2 n 2 2 1 n ̂ xi n i 1 IR&DM, WS'11/12 1 n ( xi )2 0 2 4 i 1 n 1 ˆ 2 ( xi ˆ ) 2 n i 1 October 25, 2011 II.13 MLE Properties Maximum Likelihood estimators are consistent, asymptotically Normal, and asymptotically optimal (i.e., efficient) in the following sense: Consider two estimators U and T which are asymptotically Normal. Let u2 and t2 denote the variances of the two Normal distributions to which U and T converge in probability. The asymptotic relative efficiency of U to T is ARE(U,T) := t2/u2 . Theorem: For an MLE ̂n and any other estimatorn the following inequality holds: ARE( ,ˆ ) 1 n n That is, among all estimators MLE has the smallest variance. IR&DM, WS'11/12 October 25, 2011 II.14 Bayesian Viewpoint of Parameter Estimation • Assume prior distribution g() of parameter • Choose statistical model (generative model) f (x | ) that reflects our beliefs about RV X • Given RVs X1,...,Xn for the observed data, the posterior distribution is h ( | x1,...,xn ) For X1= x1, ... ,Xn= xn the likelihood is L( x1...xn , ) i 1 f ( xi | ) i 1 n n h( | xi ) ' f ( xi | ' ) g ( ' ) g ( ) which implies h( | x1...xn ) ~ L( x1...xn , ) g ( ) (posterior is proportional to likelihood times prior) MAP estimator (maximum a posteriori): Compute that maximizes h( | x1, …, xn ) given a prior for . IR&DM, WS'11/12 October 25, 2011 II.15 Analytically Non-tractable MLE for parameters of Multivariate Normal Mixture Consider samples from a k-mixture of m-dimensional Normal distributions with the density (e.g. height and weight of males and females): f ( x, 1 ,..., k , 1 ,..., k , 1 ,..., k ) k j n( x, j , j ) j k j 1 j 1 1 (2 ) m j e 1 ( x j )T j 1 ( x j ) 2 with expectation values j and invertible, positive definite, symmetric mm covariance matrices j Maximize log-likelihood function: n n k log L( x1 ,..., xn , ) : log P[ xi | ] log j n( xi , j , j ) i 1 j 1 i 1 IR&DM, WS'11/12 October 25, 2011 II.16 Expectation-Maximization Method (EM) Key idea: When L(X1,...,Xn, θ) (where the Xi and are possibly multivariate) is analytically intractable then • introduce latent (i.e., hidden, invisible, missing) random variable(s) Z such that • the joint distribution J(X1,...,Xn, Z, ) of the “complete” data is tractable (often with Z actually being multivariate: Z1,...,Zm) • iteratively derive the expected complete-data likelihood by integrating J and find best : ˆ arg max z J [ X 1... X n , | Z z ]P[ Z z ] EZ|X,[J(X1,…,Xn, Z, )] IR&DM, WS'11/12 October 25, 2011 II.17 EM Procedure Initialization: choose start estimate for (0) (e.g., using Method-of-Moments estimator) Iterate (t=0, 1, …) until convergence: E step (expectation): estimate posterior probability of Z: P[Z | X1,…,Xn, (t)] assuming were known and equal to previous estimate (t), and compute EZ|X,θ(t) [log J(X1,…,Xn, Z, (t))] by integrating over values for Z M step (maximization, MLE step): Estimate (t+1) by maximizing (t+1) = arg maxθ EZ|X,θ[log J(X1,…,Xn, Z, )] Convergence is guaranteed (because the E step computes a lower bound of the true L function, and the M step yields monotonically non-decreasing likelihood), but may result in local maximum of (log-)likelihood function IR&DM, WS'11/12 October 25, 2011 II.18 EM Example for Multivariate Normal Mixture Expectation step (E step): P[ xi | n j ( ( t ) ) ] hij : P[ Zij 1| xi , ( t ) ] k (t) P[ x | n ( )] i l l 1 Maximization step (M step): Zij = 1 if ith data point Xi was generated by jth component, 0 otherwise EZ | X , [log J ( X 1 ,..., X n , Z , )] i log j n j ( xi , | Z ij 1) P[ Z ij 1] n hij xi j : i n1 hij i 1 hij ( xi j )( xi j )T j : i 1 n hij i 1 ( t 1 ) IR&DM, WS'11/12 n n October 25, 2011 j : hij i 1 k n hij n hij i 1 n j 1i 1 See L. Wasserman, p.121 ff. for k=2, m=1 II.19 Confidence Intervals Estimator T for an interval for parameter such that P[ T a T a ] 1 [T-a, T+a] is the confidence interval and 1– is the confidence level. For the distribution of random variable X, a value x (0< <1) with P[ X x ] P[ X x ] 1 is called a -quantile; the 0.5-quantile is called the median. For the Normal distribution N(0,1) the -quantile is denoted . For a given a or α, find a value z of N(0,1) that denotes the [T-a, T+a] conf. interval or a corresponding -quantile for 1– . IR&DM, WS'11/12 October 25, 2011 II.20 Confidence Intervals for Expectations (1) Let x1, ..., xn be a sample from a distribution with unknown expectation and known variance 2. For sufficiently large n, the sample mean X is N(,2/n) distributed and ( X ) n is N(0,1) distributed: ( X ) n P[ z z ] ( z ) ( z ) ( z ) (1 ( z )) 2( z ) 1 P[ X z z X ] n n 1 / 2 1 / 2 P[ X X ] 1 n n For confidence interval [ X a, X a] or confidence level 1- set a n z : ( 1 ) quantile of N ( 0,1 ) z : 2 z then a : then look up (z) to find 1–α n IR&DM, WS'11/12 October 25, 2011 II.21 Confidence Intervals for Expectations (2) Let X1, ..., Xn be an iid. sample from a distribution X with unknown expectation and unknown variance 2 and known sample variance S2. For sufficiently large n, the random variable (X ) n T : S n 1 1 2 has a t distribution (Student fT ,n (t ) n 1 distribution) with n-1 degrees n 2 2 t of freedom: n 1 2 n ( x) e t t x 1 dt for x 0 with the Gamma function: 0 ( with the properties ( 1 ) 1 and ( x 1 ) x ( x ) ) P[ X t n1,1 / 2 S X t n1,1 / 2 S n IR&DM, WS'11/12 ] 1 n October 25, 2011 II.22 Summary of Section II.2 • Quality measures for statistical estimators • Nonparametric vs. parametric estimation • Histograms as generic (nonparametric) plug-in estimators • Method-of-Moments estimator good initial guess but may be biased • Maximum-Likelihood estimator & Expectation Maximization • Confidence intervals for parameters IR&DM, WS'11/12 October 25, 2011 II.23 Normal Distribution Table IR&DM, WS'11/12 October 25, 2011 II.24 Student‘s t Distribution Table IR&DM, WS'11/12 October 25, 2011 II.25