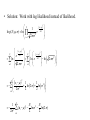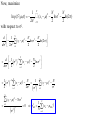Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Unsupervised Learning
Part 2
Topics
• How to determine the K in K-means?
• Hierarchical clustering
• Soft clustering with Gaussian mixture models
• Expectation-Maximization method
• Review for quiz Tuesday
Clustering via finite Gaussian mixture models
•
A “soft”, generative version of K-means clustering
•
Given: Training set S = {x1, ..., xN}, and K.
•
Assumption: Data is generated by sampling from a “mixture” (linear combination)
of K Gaussians.
Mixture of three Gaussians
(one dimensional data)
p(x) = p 1N (x | m1, s 1 ) + p 2N (x | m2 , s 2 ) + p 3N (x | m3, s 3 )
where p 1 + p 2 + p 3 =1
Clustering via finite Gaussian mixture models
•
Clusters: Each cluster will correspond to a single Gaussian. Each point x S will
have some probability distribution over the K clusters.
•
Goal: Given the data, find the Gaussians! (And the coefficients of their sum)
I.e., Find parameters {θK} of these K Gaussians such P(S | {θK}) is maximized.
•
This is called a Maximum Likelihood method.
– S is the data
– {θK} is the “hypothesis” or “model”
– P(S | {θK}) is the “likelihood”.
General form of one-dimensional (univariate)
Gaussian Mixture Model
K
p(x) = å p iN (x | mi , s i )
i=1
K
where å p i = 1
i=1
Simple Case:
Maximum Likelihood for Single Univariate Gaussian
• Assume training set S has N values generated by a univariant
Gaussian distribution:
S = {x1,..., x N }, where
N (x | m,s ) =
1
2ps
2
e
-
(x - m )2
2s 2
• Likelihood function: probability of data given model (or
parameters of model)
N
p(S | m,s ) = Õ N (x i | m,s )
i=1
• How to estimate parameters and from S?
• Maximize the likelihood function with respect to and .
N
Maximize : p(S | m,s ) = ÕN (x i | m,s )
i=1
N
=Õ
i=1
1
2ps
2
e
-
(x i - m )2
2s 2
• Problem: Individual values of N (x i | m,s ) are typically very
small. (Can underflow numerical precision of computer.)
• Solution: Work with log likelihood instead of likelihood.
2
xi -m ) ö
æ N
(
1
2
ç
ln p(S | m, s ) = ln Õ
e 2s ÷
ç i=1 2ps 2
÷
è
ø
æ - ( xi -m )2
N
ç e 2s 2
= å ln ç
2
i=1
ç 2ps
è
ö
2
÷ N æ æ - ( xi -m2) ö
÷ = åç ln çç e 2s ÷÷- ln
÷ i=1 çè è
ø
ø
(
æ ( x - m )2 1
ö
1
i
2
= -åçç
+ ln ( 2p ) + ln (s ) ÷÷
2
2s
2
2
i=1 è
ø
N
=-
1
2s
N
2
(x
m
)
å
i
2
i=1
N
N
ln s 2 - ln(2p )
2
2
2ps 2
)
ö
÷
÷
ø
Now, find maximum likelihood parameters, and σ2.
First, maximize
ln p(S | m,s ) = -
1
2s 2
N
å(x
i=1
2
i - m) -
N
N
lns 2 - ln(2p )
2
2
with respect to .
ù
d é 1 N
N
N
2
2
êå(xi - m ) - 2 ln s - 2 ln(2p )ú
d m ë 2s 2 i=1
û
ù
d é 1 N
2
=
êå(xi - m ) ú
d m ë 2s 2 i=1
û
ù
1 éN
= - 2 êå -2(xi - m )ú
2s ë i=1
û
ù
1 éæ N ö
= 2 êç å xi ÷ - N m ú = 0
s ëè i=1 ø
û
Result:
m ML
1 N
= å xn
N i=n
(ML = “Maximum Likelihood”)
Now, maximize
N
N
N
2
ln p(S | m,s ) = - 2 å (x i - m) - lns - ln(2p )
2s i=1
2
2
with respect to σ2.
1
2
ù
d é 1 N
N
N
2
2
- 2 å (xi - m ) - ln s - ln(2p )ú
2ê
ds ë 2s i=1
2
2
û
ù
d é 1 2 -1 N
N
2
2
=
- (s ) å (xi - m ) - ln s ú
2ê
ds ë 2
2
û
i=1
1 2 -2 N
N
1 N
N
2
2
= (s ) å (xi - m ) - 2 =
(x
m
)
å i
2
2 2
2
2
s
s
s
i=1
( ) i=1
N
å(x - m )
2
i
=
i=1
(s )
- Ns 2
2 2
=0 Þs
2
ML
1 N
= å (xn - m ML )2
N n=1
• The resulting distribution is called a “generative model”
because it can generate new data values.
N (x | m ML , s ML ) =
1
2ps 2
e
( x-m ML )2
2
2s ML
• We say that
q = {mML , s ML }
parameterizes the model.
• In general, θ is used to denote the (learnable) parameters of a
probabilistic model
Finite Gaussian Mixture Models
• Back to finite Gaussian mixture models
• Assumption: Data is generated from mixture of K Gaussians.
Each cluster will correspond to a single Gaussian. Each point
x will have some probability distribution over the K clusters.
Multivariate Gaussian Distribution
Multivariate (D-dimensional):
N ( x | μ, Σ )
1
(2 )
D/2
Σ
1/ 2
e
( x μ )T Σ 1 ( x μ )
2
where μ is a D-dimensiona l mean vecto r, Σ is
a D D covariance matrix, and Σ is the determinan t of Σ.
• Let S be a set of multivariate data points (vectors):
S = {x1, ..., xm}.
• General expression for finite Gaussian mixture model:
K
p(x) = åp k N (x | mk , Sk )
k=1
• That is, x has probability of “membership” in multiple
clusters/classes.
More Complicated Case:
Maximum Likelihood for Gaussian Mixture Model
• Goal: Given S = {x1, ..., xN}, and given K, find the Gaussian mixture
model (with K Gaussians) for which S has maximum log-likelihood.
• Log likelihood function:
• Given S, we can maximize this function to find
{π,μ,Σ}ML
• But no closed form solution (unlike simple case in previous slides)
• In this multivariate case, can most efficiently maximize this function using
the “Expectation / Maximization” (EM) algorithm.
Expectation-Maximization (EM) algorithm
•
General idea:
– Choose random initial values for means, covariances and mixing coefficients.
(Analogous to choosing random initial cluster centers in K-means.)
– Alternate between E (expectation) and M (maximization) step:
• E step: use current values for parameters to evaluate posterior
probabilities, or “responsibilities”, for each data point. (Analogous to
determining which cluster a point belongs to, in K-means.)
• M step: Use these probabilities to re-estimate means, covariances, and
mixing coefficients. (Analogous to moving the cluster centers to the
means of their members, in K-means.)
Repeat until the log-likelihood or the parameters θ do not change significantly.
More detailed version of EM algorithm
1. Let X be the set of training data. Initialize the means k,
covariances k, and mixing coefficients k, and evaluate
initial value of log likelihood.
K
ln p( X | π,μ,Σ) ln k N (x n | μ k ,Σ k )
n 1
k 1
N
2. E step. Evaluate the “responsibilities” using the current
parameter values
where rn,k denotes the
“responsibilities” of the kth
cluster for the nth data point.
3. M step. Re-estimate the parameters θ using the current
responsibilities.
4. Evaluate the log likelihood with the new parameters
K
ln p( X | π,μ,Σ) ln k N (x n | μ k ,Σ k )
n 1
k 1
N
and check for convergence of either the parameters or the log
likelihood. If not converged, return to step 2.
• EM much more computationally expensive than k-means
• Common practice: Use k-means to set initial parameters,
then improve with EM.
•
– Initial means: Means of clusters found by k-means
– Initial covariances: Sample covariances of the clusters
found by k-means algorithm.
– Initial mixture coefficients: Fractions of data points
assigned to the respective clusters.
• Can prove that EM finds local maxima of log-likelihood
function.
• EM is very general technique for finding maximum-likelihood
solutions for probabilistic models
Text classification from labeled and unlabeled
documents using EM
K. Nigam et al., Machine Learning, 2000
• Big problem with text classification: need labeled data.
• What we have: lots of unlabeled data.
• Question of this paper: Can unlabeled data be used to increase
classification accuracy?
• I.e.: Any information implicit in unlabeled data? Any way to
take advantage of this implicit information?
General idea: A version of EM algorithm
• Train a classifier with small set of available labeled
documents.
• Use this classifier to assign probabilisitically-weighted class
labels to unlabeled documents by calculating expectation of
missing class labels.
• Then train a new classifier using all the documents, both
originally labeled and formerly unlabeled.
• Iterate.
Probabilistic framework
• Assumes data are generated with Gaussian mixture model
• Assumes one-to-one correspondence between mixture
components and classes.
• “These assumptions rarely hold in real-world text data”
Probabilistic framework
Let C = {c1, ..., cK} be the classes / mixture components
Let = {1, ..., K} {1, ..., K} {1, ..., K} be the
mixture parameters.
Assumptions: A document di is created by first selecting a
mixture component according to the mixture weights j, then
having this selected mixture component generate a document
according to its own parameters, with distribution
p(di | cj; ).
• Likelihood of document di :
k
p ( d i | ) k p ( d i | c j ; )
j 1
• Now, we will apply EM to a Naive Bayes Classifier
Recall Naive Bayes classifier: Assume each feature is
conditionally independent, given cj.
p(c j | x) = p(c j )Õ p( fi | c j ), i =1,..., N; j =1,..., K
i
To “train” naive Bayes from labeled data, estimate
p(c j ) and p( fi | c j ), j =1,..., K; i =1,..., N
These values are estimates of the parameters in . Call
these values ˆ .
Note that Naive Bayes can be thought of as a generative
mixture model.
Document di is represented as a vector of word frequencies
( w1, ..., w|V| ), where V is the vocabulary (all known words).
The probability distribution over words associated with each
class is parameterized by .
We need to estimate ˆ to determine what probability
distribution document di = ( w1, ..., w|V| )is most likely to
come from.
Applying EM to Naive Bayes
• We have a small number of labeled documents Slabeled, and a
large number of unlabeled documents, Sunlabeled.
• The initial parameters ˆ are estimated from the labeled
documents Slabeled.
• Expectation step: The resulting classifier is used to assign
probabilistically-weighted class labels p(c j | x) to each
unlabeled document x Sunlabeled.
• Maximization step: Re-estimate ˆ using p(c j | x) values
for x Sunlabeled Sunlabeled
• Repeat until p(c j | x) or ˆ has converged.
Augmenting EM
What if basic assumptions (each document generated by one
component; one-to-one mapping between components and
classes) do not hold?
They tried two things to deal with this:
(1) Weighting unlabeled data less than labeled data
(2) Allow multiple mixture components per class:
A document may be comprised of several different sub-topics,
each best captured with a different word distribution.
Data
• 20 UseNet newsgroups
• Web pages (WebKB)
• Newswire articles (Reuters)
Gaussian Mixture Models as Generative Models
General format of GMM:
K
p(x) = åp k N (x | mk , Sk )
k=1
How would you use this to generate a new data point x?