Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Operational transformation wikipedia , lookup
Data Protection Act, 2012 wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Data center wikipedia , lookup
Clusterpoint wikipedia , lookup
Data analysis wikipedia , lookup
Forecasting wikipedia , lookup
Information privacy law wikipedia , lookup
3D optical data storage wikipedia , lookup
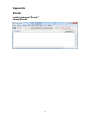
Data vault modeling wikipedia , lookup
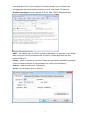
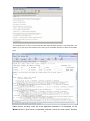
Raffle with PDA KANG Changsung([email protected]) DB2/BigData Competitive Migrations Consultant IM Competitive Migration, SW LAB Service Rattle 1 Any new R user who wishes to data mine, and who did a little research in the R documentation R on-line, would find there is a free Graphical User Interface (GUI) called Rattle that promises to streamline the mining process and reduce the need to write R code. Rattle is available as a separate package in R so we first need to load the required package with the R library command… library(rattle) rattle() R reads, and writes, a broad range of data formats including: Text Data. R tends to refer to this as “Spreadsheet-like data” DBMS. Database Management Systems (typically relational databases) via ODBC or JDBC. DBI. DataBase Interfaces. There are a number of more specific packages which handle specific database types. E.g. ROracle and RMySQL. It is important to note that the DBI functionality is – in effect – a form of what SPSS Modeler calls SQL Pushback. These extend the range of database operations that can be specified within R but which are executed “within” the target database before 2 extracting data into R. So for example it would be possible to join 2 tables and sort/aggregate the results before extracting to an R “data frame” (R data set). Statistical packages; EpiInfo, Minitab, S-PLUS, SAS, SPSS, Stata and Systat ARFF – An adapted type of CSV file containing Metadata. It is particular to the Weka10 data mining tool. As we will discuss later a number of Weka algorithms are now implemented in R. Library – gives us access to one of the R data sets provided by installed R packages (often to support examples of how packages are used in documentation). Corpus – loads documents for Text Mining Script – runs a script to open a .CSV file 3 In the end this required data preparation outside Rattle (in SQL Server and in R code) we will discuss this later in the Data Preparation section. Here is a view of the working dataset that we will use to build the first models. Note that it is actually read as an R Dataset. In other words we prepared it in an R session and launched Rattle from the same session to connect to it … 4 5 Selecting the Interactive option in the Rattle Explore tab launches an interactive editor “Latticist” which combines Lattice graphics and some other R packages (e.g. PlayWith) to give us a neat interface to graphically explore the data… Our first view is a like a data audit view which gives us a clearer picture of some of the relationships between the inputs and the target… 6 We can use this interface to zoom in on specific graphs … or areas of graphs that are then refreshed for the whole lattice. Data Auditing The lattice plots we saw in the last section clearly offer one level of visual data auditing across all the input variables akin to the graphical thumbnails found in the Modeler Data Audit node. We’ve also seen how they can be zoomed for closer examination We’ve also seen how the level of Missing Data is clearly signposted for every variable in the Data tab. 7 The accompanying detail document shows all of this output. On the whole this does add up to a pretty good range of options for the visual exploration of data and automated auditing. The missing step here is the ability to interact with the graphs and tables to generate data selections. Or even balance nodes. Nor is there a direct way to Impute from these outputs. DATA PREPARATION As before we will start with Rattle. The Transform tab looks promising. It does have a number of options though they tend to be more about “canned” variable 8 transformations which are often used in a data mining process. For example here are the Rescale options… This example shows a version of the Customers table being imported through R code generated in the Rattle Log. For part b) we used a similar view of the log from an RODBC read from a version of the Orders table. we first used the RGui to access the Orders table through ODBC. We actually reused the R code that Rattle had already generated by copy pasting it from the Rattle Log And here are the Recode options… 9 This example shows a version of the Customers table being imported through R code generated in the Rattle Log. For part b) we used a similar view of the log from an RODBC read from a version of the Orders table Rattle doesn’t currently make all of the algorithms available in R accessible on the Model tab but it does have a reasonable selection across the main types; Decision 10 Tree, Statistical, Neural and SVM as well as some ensemble capabilities (both boosted and bagged). Modeling and Evaluating in Rattle does share some of the usability of Modeler but without the breadth of model types and without the automated modeling; AutoClassifier, Auto Numeric, Auto Cluster and (Auto)Time Series. TEXT MINING R has a framework – tm - for text mining. The Corpus data type which is available in Rattle utilizes tm. The input data is in an R data set which can potentially be managed and combined into structured data sets to be used in models. 11 Appendix Rcmdr install.packages("Rcmdr") library(Rcmdr) 12