Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Entity–attribute–value model wikipedia , lookup
Oracle Database wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Concurrency control wikipedia , lookup
Ingres (database) wikipedia , lookup
Functional Database Model wikipedia , lookup
Team Foundation Server wikipedia , lookup
Microsoft Access wikipedia , lookup
Relational model wikipedia , lookup
Microsoft SQL Server wikipedia , lookup
Clusterpoint wikipedia , lookup
Database model wikipedia , lookup
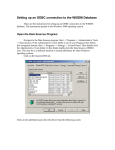
Ryan Stroup Web Programming 11:00 ODBC Intro ODBC stands for Open Database Connectivity. ODBC evolved over many years in the late 1980’s and early 1990’s. ODBC was created through the contributions of many, many groups, as you will read later on in this paper. ODBC is most useful for accessing relational data and not well suited for accessing other types of data. ODBC has been refined over and over and still there are many complaints about it. Background The first version of ODBC was created by the SQL Access Group (SAG) in 1988. The SQL Access group was comprised of 44 database vendors whose goal was to create a unified standard for remote database access. The SAG was focused on two main goals. One was to create a standard that allows any database client to talk to any database server by using common message formats and protocols. The second was an SQL Call Level Interface (CLI) that defines a common Applications Programming Interface (API) set for multi-vendor databases [9]. The SQL Access Group eventually developed SAG CLI that allowed a user to connect to a database through a local driver, prepare SQL requests, execute the requests, retrieve the results, terminate a statement, and terminate a connection. The SAG CLI only supported dynamic SQL [9]. In August 1992, Microsoft released an ODBC Windows API, which was an extended version of the SAG CLI [9]. ODBC uses standard query language (SQL) as the standard for accessing data. Microsoft’s ODBC included functions for accessing the database catalog and for controlling and determining the capabilities of ODBC drivers and their data sources [8]. There have been numerous other ODBC versions released over the years and at present the future of ODBC is uncertain [9]. ODBC was developed for corporate use. Companies needed a way to communicate between applications and SQL databases so ODBC was a huge breakthrough for companies that relied on relational databases. I believe ODBC started as something much more simpler than it is today. With each new release of ODBC, each version became more sophisticated and complex. Overview of ODBC The first release of ODBC was ODBC 1.0. This was very slow and contained many bugs. ODBC 1.0 was limited to the Windows platform and lacked the documentation and code examples required to help educate developers. In 1994 Microsoft released ODBC 2.0 SDK. This new release fixed many of the bugs with the previous device manager [9]. ODBC 3.0 SDK was released in 1996. Microsoft claimed this version offered enhanced performance, extensibility, and alignment with open standards such as X/Open and ISO [5]. This helps show that with each new ODBC version that is released, the versions are becoming more and more sophisticated and user-friendly. It is very interesting the way ODBC works. Once again the goal of ODBC is to make it possible to access any data from any application, regardless of which database management system (DBMS) is handling the data. First of all before anything else, ODBC is very hard to program and implement [2]. The way ODBC works is by inserting a middle layer, called the client driver, between an application and the DBMS. The purpose of the database driver is to translate the applications data queries into commands that the DBMS understands. For this to be successful, both the application and the DBMS need to be ODBC compliant [6]. For an ODBC connection there are five parameters that will then need to be defined. The five parameters are the specific ODBC driver needed, the back-end server name to connect to, the database name to connect to, the user id to be granted access to the database, and the password of the user id [2]. The ODBC interface was coded in the C programming language. The typical ODBC architecture looks like the figure below [4]. As you can see the architecture is composed of four different parts: database application, driver manager, drivers, and the database. The database application calls functions defined in the ODBC API to access a data source. The driver manager implements the ODBC API and provides information to the application. Microsoft’s driver manager is a dynamic link-library file named odbc32.dll [5]. With Unix, the ODBC driver is a shared library [10]. The database contains all the data that an application needs to access [10]. The client drivers are the key part in all of this. The client driver must manage numerous details for everything to communicate together properly. Some details it must manage are the differences in each server’s SQL implementation, the format which the server requires for its requests and the format of the responses, the need to support the server’s protocol, differences in the way that different servers encode data, naming and location, and connection management between the client and server. The drivers are very flexible and can incorporate the services of any client/server framework [1]. ODBC drivers are usually obtained from database and front-end tool vendors [9]. Another characteristic of ODBC is that it contains three conformance levels. The three levels are the Core, Level 1, and Level 2. I will look at these as they appeared in ODBC 2.0. The Core level provided 23 base call that let a user connect to a database, execute SQL statements, fetch results, commit and rollback transactions, handle exceptions, and terminate the connection [9]. Some of the more common core functions are SQLConnect(), SQLCancel(), SQLError(), SQLExecute(), and SQLFetch() [10]. Level 1 provided an addition 19 calls that allowed a user retrieve information from a database catalog, fetch large objects, and deal with driver specific functions [9]. Some Level 1 functions are SQLColumns(), SQLGetData(), SQLTables(), SQLPutData(), and SQLDriverConnect() [10]. Last, Level 2 provided another 19 calls that let a user retrieve data using cursors. Also Level 2 supported forward and backward scrolling [9]. The applications determine the conformance level when they call the driver [2]. A few Level 2 functions are SQLDrivers(), SQLPrimaryKeys(), SQLProcedures(), SQLSetSCrollOptions(), and SQLForeignKeys() [10]. Advantages and Disadvantages There are many advantages and disadvantages about ODBC. Perhaps the biggest advantage is that the ODBC API is available on all major platforms. ODBC has become so accepted that some vendors have developed their DBMS native programming interface based on ODBC. This vast acceptance of the standard was initially propelled by Microsoft’s implementation of ODBC for their products [2]. Microsoft’s platforms also include many enhancements that other platforms do not contain. Another big advantage of ODBC is dynamic data binding. This allows the user or system administrator to easily configure an application to use any ODBC compliant data source. Dynamic binding allows the end-user to pick a data source and use it for all data applications without having to worry about recompiling the application [7]. But like I mentioned ODBC has many drawbacks associated with it as well. The largest drawback is that Microsoft controls the specification and it is constantly evolving. Companies for the most part have to evolve with Microsoft, which is something they obviously like to keep to a minimum. Along with this comes the price of Microsoft’s ODBC. Microsoft has exercised control of ODBC by making companies pay for the ODBC SDK [8]. Another big problem is the future of ODBC is uncertain. Microsoft has shown commitment to OLE/DB. OLE/DB introduces a different programming standard as it leans more to object-based rather than procedural. But Microsoft is promising continuing support to ODBC as well as OLE/DB so this issue will have to wait to the future to be resolved. The drivers for ODBC are also very complicated to build and maintain. The current drivers have different conformance levels, which are not documented very well. The ODBC layers present a lot of overhead and they are not known to be very fast [9]. Also ODBC does not specify the communication framework because it only specifies the application protocol. Thus ODBC inherits the features of the underlying framework. So reliability depends on how the server and the driver implement their request-response protocol. The client performs much of the work to make up the differences between the client and different server systems. This is an obstacle to scaling and also causes servers to not be sufficiently standardized [1]. As a result of this each client maintains its own drivers, naming tables, and macros, which could complicate management at larger sites. Developers even often experience problems getting multiple ODBC drivers to work together on a single client machine [1]. A few more issues with ODBC are its complexity of implementation and its lack of a simple object model [3]. A quote by Richard Frankenstein shows the way a lot of developers feel about ODBC “Use native (direct) APIs whenever possible. Standard APIs like ODBC should be considered as a last resort…not the first” [9]. From my personal use with ODBC, I have found that it is very simple to use. I was able to start using it immediately without having to be taught much about it. I believe this view is shared among most users of ODBC. The one disadvantage that was clearly visible to me was that with a larger DBMS, ODBC could at some points be very slow. Summary ODBC is extremely useful for company’s to manage their relational databases. It is simple to learn and makes it easy to access and update data. But ODBC also has its share of limitations. Overall I think ODBC was and is very important in today’s technological society. REFERENCES 1. Hart, Johnson, and Barry Rosenberg. Client/Server Computing for Technical Professionals. New York: Addison-Wesley Publishing Company, 1995. 2. Hoffer, Jeffrey, Mary Prescott, and Fred McFadden. Modern Database Management. Upper Saddle River, New Jersey: Pearson Education, Inc., 2002. 3. Jerke, Noel, et al. Visual Basic 5 Client/Server How To. Corte Madera, CA: The Waite Group Press, 1997. 4. Lee, Wei-Meng. “The Evolution of Data-Access Technologies.” SQL Server Magazine. Apr. 2002. 24 Oct. 2004. http://www.winnetmag.com/ SQLServer/Article/ArticleID/23988/23988.html 5. Microsoft Announces ODBC Version 3.0 SDK. 12 Nov. 1996. Microsoft Corp. 19 Oct. 2004. <http://www.microsoft.com/presspass/press/1996/nov96/ odbcskpr.asp>. 6. ODBC. 16 Aug. 2004. Webopedia. 18 Oct. 2004 <http://www.webopedia.com/ TERM/O/ODBC.html>. 7. ODBC and the unixODBC project. 20 Sep. 2004. 17 Oct. 2004. < http://www.unixodbc.org/>. 8. Open Database Access and ODBC. 1998. FFE Software, Inc. 14 Oct. 2004. <http://www.firstsql.com/ioodbc.htm>. 9. Orfali, Robert, Dan Harkey, and Jeri Edwards. The Essential Client/Server Survival Guide. New York: John Wiley & Sons, Inc., 1996. 10. Visigenic DriverSet Reference Version 2.0. 1996. Visigenic Software, Inc. 26 Oct. 2004. <http://www.prolificmuse.com/About_Prolific_Muse/ Printed_Documentation/drivset.pdf>.