
Data Structures for Midterm 2
... General insert is O(n) due to shifting data O(1) lookup if index is known O(n) find – O(log(n)) if sorted using binary search ...
... General insert is O(n) due to shifting data O(1) lookup if index is known O(n) find – O(log(n)) if sorted using binary search ...

CS2007Ch12C
... All previous searching techniques require a specified amount of time (O(logn) or O(n)) Time usually depends on number of elements (n) stored in the table In some situations searching should be almost instantaneous -- how? ...
... All previous searching techniques require a specified amount of time (O(logn) or O(n)) Time usually depends on number of elements (n) stored in the table In some situations searching should be almost instantaneous -- how? ...


Midterm Solutions
... There are two main approaches. (Note that we excluded 0 and −263 since these are the only two long integers x such that x + −x = 0.) • Hashing. Insert each integer x into a hash table (linear probing or separate chaining). When inserting x, check if −x is already in the hash table. If so, you’ve fou ...
... There are two main approaches. (Note that we excluded 0 and −263 since these are the only two long integers x such that x + −x = 0.) • Hashing. Insert each integer x into a hash table (linear probing or separate chaining). When inserting x, check if −x is already in the hash table. If so, you’ve fou ...

Document
... More on prime table size If TableSize is 60 and… – Lots of data items are multiples of 5, wasting 80% of table – Lots of data items are multiples of 10, wasting 90% of table – Lots of data items are multiples of 2, wasting 50% of table If TableSize is 61… – Collisions can still happen, but 5, 10, 1 ...
... More on prime table size If TableSize is 60 and… – Lots of data items are multiples of 5, wasting 80% of table – Lots of data items are multiples of 10, wasting 90% of table – Lots of data items are multiples of 2, wasting 50% of table If TableSize is 61… – Collisions can still happen, but 5, 10, 1 ...


Oracle`s Business Strategy: Maximizing Your Sales Leverage
... • Trie’s (Text retRieval data structure) can be used deterministically to find the closest match in a dictionary of words. Unsuccessful searches terminate quickly. Searches are usually tolerant and allows ...
... • Trie’s (Text retRieval data structure) can be used deterministically to find the closest match in a dictionary of words. Unsuccessful searches terminate quickly. Searches are usually tolerant and allows ...


Hashing 1
... Open-addressed hash tables are based on 1D-arrays, which are difficult to resize once they have been allocated. Unless you want to implement the table as a dynamic array and rehash all of the keys whenever the size changes. This is an incredibly expensive operation. An alternative is use a separate- ...
... Open-addressed hash tables are based on 1D-arrays, which are difficult to resize once they have been allocated. Unless you want to implement the table as a dynamic array and rehash all of the keys whenever the size changes. This is an incredibly expensive operation. An alternative is use a separate- ...

Hash Tables
... Open-addressed hash tables are based on 1D-arrays, which are difficult to resize once they have been allocated. Unless you want to implement the table as a dynamic array and rehash all of the keys whenever the size changes. This is an incredibly expensive operation. An alternative is use a separate- ...
... Open-addressed hash tables are based on 1D-arrays, which are difficult to resize once they have been allocated. Unless you want to implement the table as a dynamic array and rehash all of the keys whenever the size changes. This is an incredibly expensive operation. An alternative is use a separate- ...

word - Courses
... given input k should always produce the same output h(k ) . Since U m , and in general U is much larger than m, there must be at least two keys that have the same hash value, and therefore avoiding collisions altogether is impossible. Thus, while a well designed random looking hash function can mi ...
... given input k should always produce the same output h(k ) . Since U m , and in general U is much larger than m, there must be at least two keys that have the same hash value, and therefore avoiding collisions altogether is impossible. Thus, while a well designed random looking hash function can mi ...

Lecture Note 10
... – Find record/empty slot starting at index = h(key) (use resolution policy if necessary) ...
... – Find record/empty slot starting at index = h(key) (use resolution policy if necessary) ...

y-fast Trees
... So our expected space is about 2n. More specifically, the probability P r[space > 4n] < 12 . If we clobber an element, we pick some other hash function for that bucket. We will need to choose new hash functions only an expected constant number of times per bucket, because we have a constant probabil ...
... So our expected space is about 2n. More specifically, the probability P r[space > 4n] < 12 . If we clobber an element, we pick some other hash function for that bucket. We will need to choose new hash functions only an expected constant number of times per bucket, because we have a constant probabil ...
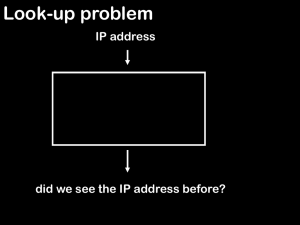

CS 3114 Data Structures and Algorithms Homework 3: Hashing 1
... The home slot of a record depends only on the key, the hash function, and the size of the table. The collision resolution strategy does not come into play in selecting the home slot. Therefore the number of primary collisions will be same no matter what collision resolution strategy is used. b) [10 ...
... The home slot of a record depends only on the key, the hash function, and the size of the table. The collision resolution strategy does not come into play in selecting the home slot. Therefore the number of primary collisions will be same no matter what collision resolution strategy is used. b) [10 ...

hash function
... if the table becomes three-quarters full, then must resize create new table at least twice as big just copy over table entries to same locations??? NO! when you resize, you have to rehash existing entries new table size new hash function (+ different wraparound) ...
... if the table becomes three-quarters full, then must resize create new table at least twice as big just copy over table entries to same locations??? NO! when you resize, you have to rehash existing entries new table size new hash function (+ different wraparound) ...


The Pigeonhole Principle and Hashing
... the key to index into an array of frequencies (the values). In this case, note that our array of frequencies will have size 256: one for each of the 256 different ASCII characters. It may well be that not all of these 256 different characters are in a given file, and so we are potentially wasting me ...
... the key to index into an array of frequencies (the values). In this case, note that our array of frequencies will have size 256: one for each of the 256 different ASCII characters. It may well be that not all of these 256 different characters are in a given file, and so we are potentially wasting me ...

notes
... • Constant time per operation (on average) • Worst case time proportional to the size of the set for each operation (just like array and chain/list implementation) ...
... • Constant time per operation (on average) • Worst case time proportional to the size of the set for each operation (just like array and chain/list implementation) ...


hash function
... recall: TreeSet & TreeMap use an underlying binary search tree (actually, a red-black tree) to store values as a result, add/put, contains/get, and remove are O(log N) operations iteration over the Set/Map can be done in O(N) ...
... recall: TreeSet & TreeMap use an underlying binary search tree (actually, a red-black tree) to store values as a result, add/put, contains/get, and remove are O(log N) operations iteration over the Set/Map can be done in O(N) ...

DSLec(Hashing). - CSE246DataStructures
... key that hashes into an even integer rehashes into successive even integers even then list is empty in odd locations and same with odd integers. ...
... key that hashes into an even integer rehashes into successive even integers even then list is empty in odd locations and same with odd integers. ...
Document
... 4.)* Download the Graph Theory Demo and implement a minimum spanning tree algorithm by Kruskal (the algorithm is easy but you will need to understand the original code written in lectures). Test it with a sufficiently large Graph. 5.)* Implement a simple Hash-Table, using the LinkedList method for c ...
... 4.)* Download the Graph Theory Demo and implement a minimum spanning tree algorithm by Kruskal (the algorithm is easy but you will need to understand the original code written in lectures). Test it with a sufficiently large Graph. 5.)* Implement a simple Hash-Table, using the LinkedList method for c ...

Notes 33 Royden
... •Index functions are not always simple functions that compute an integer value from integer inputs. ...
... •Index functions are not always simple functions that compute an integer value from integer inputs. ...

Hash table

In computing, a hash table (hash map) is a data structure used to implement an associative array, a structure that can map keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.Ideally, the hash function will assign each key to a unique bucket, but it is possible that two keys will generate an identical hash causing both keys to point to the same bucket. Instead, most hash table designs assume that hash collisions—different keys that are assigned by the hash function to the same bucket—will occur and must be accommodated in some way.In a well-dimensioned hash table, the average cost (number of instructions) for each lookup is independent of the number of elements stored in the table. Many hash table designs also allow arbitrary insertions and deletions of key-value pairs, at (amortized) constant average cost per operation.In many situations, hash tables turn out to be more efficient than search trees or any other table lookup structure. For this reason, they are widely used in many kinds of computer software, particularly for associative arrays, database indexing, caches, and sets.