
Wavelet transform Ch 13.?
... We can reconstruct the original data vector of length N from its N/2 smooth or s-component and its N/2 detail to d component ...
... We can reconstruct the original data vector of length N from its N/2 smooth or s-component and its N/2 detail to d component ...

June 2014
... a) Define what it means for a matrix G to be a generator matrix, and a matrix H to be a parity check matrix, for a linear code C over a finite field F. b) Let G, H be full rank matrices over F, where G is k × n and H is (n − k) × n. Prove that there exists a code C with generator matrix G and parity ...
... a) Define what it means for a matrix G to be a generator matrix, and a matrix H to be a parity check matrix, for a linear code C over a finite field F. b) Let G, H be full rank matrices over F, where G is k × n and H is (n − k) × n. Prove that there exists a code C with generator matrix G and parity ...

EET 465 LAB #2 - Pui Chor Wong
... based on the generator matrix G given. test your function with a few message as done in class. 2. Create another function using the parity check matrix H to determine the syndrome of the received codeword: function syndrome=syndrome_gen(codeword) % This is my 7,4 linear block code syndrome generator ...
... based on the generator matrix G given. test your function with a few message as done in class. 2. Create another function using the parity check matrix H to determine the syndrome of the received codeword: function syndrome=syndrome_gen(codeword) % This is my 7,4 linear block code syndrome generator ...

slides
... This means that you can substitute dot products with any positive-definite function K (called kernel) and you have an implicit non-linear mapping to a high-dimensional space If you chose your kernel properly, your decision boundary bends to fit the data. ...
... This means that you can substitute dot products with any positive-definite function K (called kernel) and you have an implicit non-linear mapping to a high-dimensional space If you chose your kernel properly, your decision boundary bends to fit the data. ...

Bootstrap algorithms applied for characterization of uncertainty
... frequently used to estimate multiple model parameters. For this reason, there are statistical covariances between some of the model parameters. If not appropriately accounted for, these covariances may lead to excessively wide or narrow confidence intervals, depending on whether the covariances are ...
... frequently used to estimate multiple model parameters. For this reason, there are statistical covariances between some of the model parameters. If not appropriately accounted for, these covariances may lead to excessively wide or narrow confidence intervals, depending on whether the covariances are ...

e - Osmania University
... 1) a) Let n be a fixed positive integer and S be the set of all positive integers which are less than ‘ n ’ and relatively prime to it. What is the sum of all the elements of S . b) If p is a prime and if r ∈ Ν is such that 1 ≤ r < p , then show that p divides pC . ...
... 1) a) Let n be a fixed positive integer and S be the set of all positive integers which are less than ‘ n ’ and relatively prime to it. What is the sum of all the elements of S . b) If p is a prime and if r ∈ Ν is such that 1 ≤ r < p , then show that p divides pC . ...


Projection Operators and the least Squares Method
... Proof of the Theorem. We can prove this as follows. Let {a1 , a2 , · · · ar } be a basis for S. Now let A := (a1 , a2 , · · · ar ). This is an n × r matrix and its null space N (A) = {0} since the columns are linearly independent. The square matrix AT A is nonsingular. To see that it suffices to show ...
... Proof of the Theorem. We can prove this as follows. Let {a1 , a2 , · · · ar } be a basis for S. Now let A := (a1 , a2 , · · · ar ). This is an n × r matrix and its null space N (A) = {0} since the columns are linearly independent. The square matrix AT A is nonsingular. To see that it suffices to show ...

Chapters 5
... A city qualifies for emergency relief if their annual snowfall is in the top 2%. How many inches of snow would need to fall this year for the city to receive relief? On the Z-table, find the Z-score that has a probability of approx. 0.9800. The closest value is p = 0.9798 which has a corresponding Z ...
... A city qualifies for emergency relief if their annual snowfall is in the top 2%. How many inches of snow would need to fall this year for the city to receive relief? On the Z-table, find the Z-score that has a probability of approx. 0.9800. The closest value is p = 0.9798 which has a corresponding Z ...


Condition estimation and scaling
... Furthermore, multiplying by an explicit inverse is almost exactly the same amount of arithmetic work as a pair of triangular solves. So computing and using an explicit inverse is, on balance, more expensive than simply solving linear systems using the LU factorization. To make matters worse, multipl ...
... Furthermore, multiplying by an explicit inverse is almost exactly the same amount of arithmetic work as a pair of triangular solves. So computing and using an explicit inverse is, on balance, more expensive than simply solving linear systems using the LU factorization. To make matters worse, multipl ...

PDF
... • From the examples above, we note several important features of a matrix representation of a linear transformation: 1. the matrix depends on the bases given to the vector spaces 2. the ordering of a basis is important 3. switching the order of a given basis amounts to switching columns and rows of ...
... • From the examples above, we note several important features of a matrix representation of a linear transformation: 1. the matrix depends on the bases given to the vector spaces 2. the ordering of a basis is important 3. switching the order of a given basis amounts to switching columns and rows of ...

Computational Linear Algebra
... To type in a matrix variable, we surround the values with square brackets. The semicolon ";" appears at the end of each row, like a line break. For example, if you type --> A = [1 2 3; 4 5 6] --> B = [1 2; 3 4; 5 6] You will now have a 2x3 matrix A and a 3x2 matrix B. Freemat can now do matrix arith ...
... To type in a matrix variable, we surround the values with square brackets. The semicolon ";" appears at the end of each row, like a line break. For example, if you type --> A = [1 2 3; 4 5 6] --> B = [1 2; 3 4; 5 6] You will now have a 2x3 matrix A and a 3x2 matrix B. Freemat can now do matrix arith ...

Table of Contents
... may feel that they have deficiency in linear algebra and those students who have completed an undergraduate course in linear algebra. Each chapter begins with the learning objectives and pertinent definitions and theorems. All the illustrative examples and answers to the self-assessment quiz are ful ...
... may feel that they have deficiency in linear algebra and those students who have completed an undergraduate course in linear algebra. Each chapter begins with the learning objectives and pertinent definitions and theorems. All the illustrative examples and answers to the self-assessment quiz are ful ...
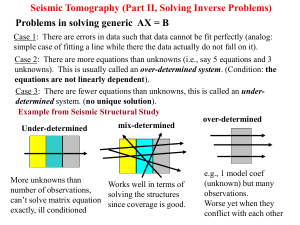
lecture7_2012
... Case 1: There are errors in data such that data cannot be fit perfectly (analog: simple case of fitting a line while there the data actually do not fall on it). Case 2: There are more equations than unknowns (i.e., say 5 equations and 3 unknowns). This is usually called an over-determined system. (C ...
... Case 1: There are errors in data such that data cannot be fit perfectly (analog: simple case of fitting a line while there the data actually do not fall on it). Case 2: There are more equations than unknowns (i.e., say 5 equations and 3 unknowns). This is usually called an over-determined system. (C ...

Probabilistically-constrained estimation of random parameters with
... parameter vector with known (Gaussian) distribution. In this paper, we adopt the main framework of [6], but address a more general case when the distribution of the random signal parameter vector is completely unknown. Mathematically, our problem amounts to the design of a linear estimator that mini ...
... parameter vector with known (Gaussian) distribution. In this paper, we adopt the main framework of [6], but address a more general case when the distribution of the random signal parameter vector is completely unknown. Mathematically, our problem amounts to the design of a linear estimator that mini ...

Probabilistically-constrained estimation of random parameters with
... parameter vector with known (Gaussian) distribution. In this paper, we adopt the main framework of [6], but address a more general case when the distribution of the random signal parameter vector is completely unknown. Mathematically, our problem amounts to the design of a linear estimator that mini ...
... parameter vector with known (Gaussian) distribution. In this paper, we adopt the main framework of [6], but address a more general case when the distribution of the random signal parameter vector is completely unknown. Mathematically, our problem amounts to the design of a linear estimator that mini ...

Self-Organizing maps - UCLA Human Genetics
... variance (the first eigen value represents its magnitude) • The second column is for the second largest variance uncorrelated with the first, and so on. • The first q columns, q < p, of XV are the linear projection of X into q diensions with the largest variance • Let x = ULqVT, where Lq is the diag ...
... variance (the first eigen value represents its magnitude) • The second column is for the second largest variance uncorrelated with the first, and so on. • The first q columns, q < p, of XV are the linear projection of X into q diensions with the largest variance • Let x = ULqVT, where Lq is the diag ...


Estimation of structured transition matrices in high dimensions
... This talk considers the estimation of the transition matrices of a (possibly approximating) VAR model in a high-dimensional regime, wherein the time series dimension is relatively large compared to the sample size. Estimation in this setting requires some extra structure. The recent literature has g ...
... This talk considers the estimation of the transition matrices of a (possibly approximating) VAR model in a high-dimensional regime, wherein the time series dimension is relatively large compared to the sample size. Estimation in this setting requires some extra structure. The recent literature has g ...

23 Least squares approximation
... more important role once the dot product has been introduced. If A is an m×n matrix, then as you know, it can be regarded as a linear transformation from Rn to Rm . Its transpose, At then gives a linear transformation from Rm to Rn , since it’s n × m. Note that there is no implication here that At = ...
... more important role once the dot product has been introduced. If A is an m×n matrix, then as you know, it can be regarded as a linear transformation from Rn to Rm . Its transpose, At then gives a linear transformation from Rm to Rn , since it’s n × m. Note that there is no implication here that At = ...

hw4.pdf
... in the particular case k = 3. For example 0.3 + 0.7AB is a probability distribution on G. Two formal linear combinations can be added, so the set of formal linear combinations is a vector space. They can also be multiplied like polynomials, so they have additional algebraic structure. Denote by P(G) ...
... in the particular case k = 3. For example 0.3 + 0.7AB is a probability distribution on G. Two formal linear combinations can be added, so the set of formal linear combinations is a vector space. They can also be multiplied like polynomials, so they have additional algebraic structure. Denote by P(G) ...

2.3 Characterizations of Invertible Matrices Theorem 8 (The
... 2.3 Characterizations of Invertible Matrices Theorem 8 (The Invertible Matrix Theorem) Let A be a square n × n matrix. The the following statements are equivalent (i.e., for a given A, they are either all true or all false). a. A is an invertible matrix. b. A is row equivalent to I n . c. A has n pi ...
... 2.3 Characterizations of Invertible Matrices Theorem 8 (The Invertible Matrix Theorem) Let A be a square n × n matrix. The the following statements are equivalent (i.e., for a given A, they are either all true or all false). a. A is an invertible matrix. b. A is row equivalent to I n . c. A has n pi ...

2.3 Characterizations of Invertible Matrices
... 2.3 Characterizations of Invertible Matrices Theorem 8 (The Invertible Matrix Theorem) Let A be a square n × n matrix. The the following statements are equivalent (i.e., for a given A, they are either all true or all false). a. A is an invertible matrix. b. A is row equivalent to I n . c. A has n pi ...
... 2.3 Characterizations of Invertible Matrices Theorem 8 (The Invertible Matrix Theorem) Let A be a square n × n matrix. The the following statements are equivalent (i.e., for a given A, they are either all true or all false). a. A is an invertible matrix. b. A is row equivalent to I n . c. A has n pi ...

Research Journal of Mathematics and Statistics 6(1): 6-11, 2014
... or two derivative, w.r.t., unknown parameter. According to general theory all these estimators in regular (smooth) case are consistent and asymptotically normal (Kutoyants, 1998). Moreover, the first two estimators are asymptotically efficient in usual sense. In non regular case, when, say intensity ...
... or two derivative, w.r.t., unknown parameter. According to general theory all these estimators in regular (smooth) case are consistent and asymptotically normal (Kutoyants, 1998). Moreover, the first two estimators are asymptotically efficient in usual sense. In non regular case, when, say intensity ...
Ordinary least squares

In statistics, ordinary least squares (OLS) or linear least squares is a method for estimating the unknown parameters in a linear regression model, with the goal of minimizing the differences between the observed responses in some arbitrary dataset and the responses predicted by the linear approximation of the data (visually this is seen as the sum of the vertical distances between each data point in the set and the corresponding point on the regression line - the smaller the differences, the better the model fits the data). The resulting estimator can be expressed by a simple formula, especially in the case of a single regressor on the right-hand side.The OLS estimator is consistent when the regressors are exogenous and there is no perfect multicollinearity, and optimal in the class of linear unbiased estimators when the errors are homoscedastic and serially uncorrelated. Under these conditions, the method of OLS provides minimum-variance mean-unbiased estimation when the errors have finite variances. Under the additional assumption that the errors be normally distributed, OLS is the maximum likelihood estimator. OLS is used in economics (econometrics), political science and electrical engineering (control theory and signal processing), among many areas of application. The Multi-fractional order estimator is an expanded version of OLS.