

12 Function Fitting
... this is called parametric fitting, and finding the parameter values themselves may be the goal. For example, an exponential decay constant might be sought to determine a reaction rate. If the form of the function is not known, and so a very flexible function with many free parameters is used, this b ...
... this is called parametric fitting, and finding the parameter values themselves may be the goal. For example, an exponential decay constant might be sought to determine a reaction rate. If the form of the function is not known, and so a very flexible function with many free parameters is used, this b ...

1 (3 hrs.)
... be integrated using Crank-Nicholson method (i.e. trapezoidal rule). Find the condition on the integration step size ’h’in terms of eigenvalues of matrix A so that the approximation error will decay exponentially and approximate solution will approach the true solution. (5 marks). Note: Crank-Nichols ...
... be integrated using Crank-Nicholson method (i.e. trapezoidal rule). Find the condition on the integration step size ’h’in terms of eigenvalues of matrix A so that the approximation error will decay exponentially and approximate solution will approach the true solution. (5 marks). Note: Crank-Nichols ...

Condition Number, LU, Cholesky
... take advantage of many of these (sparse matrices the big exception…) cs542g-term1-2007 ...
... take advantage of many of these (sparse matrices the big exception…) cs542g-term1-2007 ...

Matrices and their Shapes - University of California, Berkeley
... notation system that allows us to avoid almost all of the subscripts, summation signs, and “...” …llers when talking about the properties of the statistics. Linear algebra, with its system of matrix notation, was invented for this purpose; it gives a convenient way to discuss solutions of multiple l ...
... notation system that allows us to avoid almost all of the subscripts, summation signs, and “...” …llers when talking about the properties of the statistics. Linear algebra, with its system of matrix notation, was invented for this purpose; it gives a convenient way to discuss solutions of multiple l ...


Linear Inverse Problem
... • We will work with the linear system Ay = b where (for now) A = n x n matrix, y = n x 1 vector, b = n x 1 vector • The forward problem consists of finding b given a particular y ...
... • We will work with the linear system Ay = b where (for now) A = n x n matrix, y = n x 1 vector, b = n x 1 vector • The forward problem consists of finding b given a particular y ...

Spectrum Estimation in Helioseismology
... linear parameter; and let {κj}j=1n T *. The parameter g(θ) is identifiable iff g = Λ.K for some 1×n matrix Λ. In that case, if E[ε] = 0, then ĝ = Λ.X is unbiased for g. If, in addition, ε has covariance matrix Σ = E[εεT], then the MSE of ĝ is Λ.Σ.ΛT. ...
... linear parameter; and let {κj}j=1n T *. The parameter g(θ) is identifiable iff g = Λ.K for some 1×n matrix Λ. In that case, if E[ε] = 0, then ĝ = Λ.X is unbiased for g. If, in addition, ε has covariance matrix Σ = E[εεT], then the MSE of ĝ is Λ.Σ.ΛT. ...

The product Ax Definition: If A is an m × n matrix, with columns a 1
... ä So: Can write above system as Ax = b with b = ...
... ä So: Can write above system as Ax = b with b = ...

Representing the Simple Linear Regression Model as a Matrix
... the equation Y Xβ ε has no solution! (Why?) When faced with an equation that we cannot solve, we do what mathematicians usually do: we find a related equation that we can solve. First, since we don't know the errors in our observations, we forget about the vector of the errors ε . (Here, it is i ...
... the equation Y Xβ ε has no solution! (Why?) When faced with an equation that we cannot solve, we do what mathematicians usually do: we find a related equation that we can solve. First, since we don't know the errors in our observations, we forget about the vector of the errors ε . (Here, it is i ...

Models for a binary dependent variable
... The expression P (ui < Xi β) denotes the CDF of u evaluated at Xi β. In the probit model this is the normal CDF, Φ(Xi β), and in the logit model it is the logistic CDF, Λ(Xi β) where Λ(x) = 1/(1 + e−x ). We’ll use the symbol F (Xi β) to indicate either of these functions, depending on the context. T ...
... The expression P (ui < Xi β) denotes the CDF of u evaluated at Xi β. In the probit model this is the normal CDF, Φ(Xi β), and in the logit model it is the logistic CDF, Λ(Xi β) where Λ(x) = 1/(1 + e−x ). We’ll use the symbol F (Xi β) to indicate either of these functions, depending on the context. T ...

Review Sheet
... - What techniques do we have to find these solutions, when they exist (existence)? - When are they unique (uniqueness)? - Homogeneous vs. non-homogeneous - Parametric vector form of a solution Different representations of systems of linear equations - Vector equation - Matrix equation Matrices - Pro ...
... - What techniques do we have to find these solutions, when they exist (existence)? - When are they unique (uniqueness)? - Homogeneous vs. non-homogeneous - Parametric vector form of a solution Different representations of systems of linear equations - Vector equation - Matrix equation Matrices - Pro ...
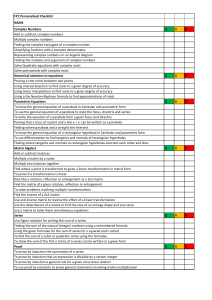
Further-Maths-FP1
... Use the determinant of a matrix to find the area of an enlarge shape and vice versa Use a matrix to solve linear simultaneous equations Series Use Sigma notation for writing the sum of a series Finding the sum of the natural (integer) numbers using a remembered formula Using the given formulae for t ...
... Use the determinant of a matrix to find the area of an enlarge shape and vice versa Use a matrix to solve linear simultaneous equations Series Use Sigma notation for writing the sum of a series Finding the sum of the natural (integer) numbers using a remembered formula Using the given formulae for t ...
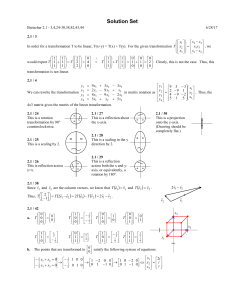
Solution Set - Harvard Math Department
... In proving the above two conditions, we have used a few properties of cross product. Since both conditions are satisfied, the cross product transformation is linear. Using the definition of cross product, we can write: v x v x 0 v3 v2 x1 v x ...
... In proving the above two conditions, we have used a few properties of cross product. Since both conditions are satisfied, the cross product transformation is linear. Using the definition of cross product, we can write: v x v x 0 v3 v2 x1 v x ...

leastsquares
... Quick and Dirty Approach Multiply by AT to get the normal equations: AT A x = AT b For the mountain example the matrix AT A is 3 x 3. The matrix AT A is symmetric . However, sometimes AT A can be nearly singular or singular. Consider the matrix A = 1 1 e 0 0 e The matrix AT A = 1+ e2 ...
... Quick and Dirty Approach Multiply by AT to get the normal equations: AT A x = AT b For the mountain example the matrix AT A is 3 x 3. The matrix AT A is symmetric . However, sometimes AT A can be nearly singular or singular. Consider the matrix A = 1 1 e 0 0 e The matrix AT A = 1+ e2 ...

Sol 2 - D-MATH
... multiple of the other. But if ~v2 were a scalar multiple of ~v1 , it would have to lie along the line going through ~v1 . In the picture, this is clearly not the case, thus the two vectors are linearly independent. However, ~v1 , ~v2 and ~v3 are linearly dependent, as with a correct scaling of ~v1 a ...
... multiple of the other. But if ~v2 were a scalar multiple of ~v1 , it would have to lie along the line going through ~v1 . In the picture, this is clearly not the case, thus the two vectors are linearly independent. However, ~v1 , ~v2 and ~v3 are linearly dependent, as with a correct scaling of ~v1 a ...


Analytic Models and Empirical Search: A Hybrid Approach to Code
... Why is Speed Important? • Adaptation may have to be applied at runtime, where running time is critical. • Adaptation may have to be applied at compile time (e.g., with feedback from a fast simulator) • Library routines can be used as a benchmark to evaluate alternative machine designs. ...
... Why is Speed Important? • Adaptation may have to be applied at runtime, where running time is critical. • Adaptation may have to be applied at compile time (e.g., with feedback from a fast simulator) • Library routines can be used as a benchmark to evaluate alternative machine designs. ...

USE OF LINEAR ALGEBRA I Math 21b, O. Knill
... projections along lines reduces to the solution of the Radon transform. Studied first in 1917, it is today a basic tool in applications like medical diagnosis, tokamak monitoring, in plasma physics or for astrophysical applications. The reconstruction is also called tomography. Mathematical tools de ...
... projections along lines reduces to the solution of the Radon transform. Studied first in 1917, it is today a basic tool in applications like medical diagnosis, tokamak monitoring, in plasma physics or for astrophysical applications. The reconstruction is also called tomography. Mathematical tools de ...


Linear Algebra Exam 1 Spring 2007
... 6. [15 − 3each] True or False: Justify each answer by citing an appropriate definition or theorem. If the statement is false and you can provide a counterexample to demonstrate this then do so. If the statement is false and be can slightly modified so as to make it true then indicate how this may b ...
... 6. [15 − 3each] True or False: Justify each answer by citing an appropriate definition or theorem. If the statement is false and you can provide a counterexample to demonstrate this then do so. If the statement is false and be can slightly modified so as to make it true then indicate how this may b ...

july 22
... (d) Do the columns of A form a linearly independent set? (e) Is the set {~a3 , ~a4 , ~a5 } a linearly independent set? If linear transformation T (~x) = A~x, (f) What is the domain of T ? the codomain of T ? (g) Is the linear transformation T (~x) = A~x onto its codomain? one-to-one ? (h) What is th ...
... (d) Do the columns of A form a linearly independent set? (e) Is the set {~a3 , ~a4 , ~a5 } a linearly independent set? If linear transformation T (~x) = A~x, (f) What is the domain of T ? the codomain of T ? (g) Is the linear transformation T (~x) = A~x onto its codomain? one-to-one ? (h) What is th ...

Multivariable Linear Systems and Row Operations
... The algorithm used to transform a system of linear equations into an equivalent system in row-echelon form is called Gaussian elimination. The operations used to produce equivalent systems are given below. ...
... The algorithm used to transform a system of linear equations into an equivalent system in row-echelon form is called Gaussian elimination. The operations used to produce equivalent systems are given below. ...

1 The Chain Rule - McGill Math Department
... are two transformations such that (x1 , x2 , · · · , xn ) = G(F (x1 , x2 , · · · , xn )) then the Jacobian matrices DF and DG are inverse to one another. This is because, if I(x1 , x2 , · · · , xn ) = (x1 , x2 , · · · , xn ) then DI is the identity matrix n × n matrix In . Hence, In = D(I) = D(F ◦ G ...
... are two transformations such that (x1 , x2 , · · · , xn ) = G(F (x1 , x2 , · · · , xn )) then the Jacobian matrices DF and DG are inverse to one another. This is because, if I(x1 , x2 , · · · , xn ) = (x1 , x2 , · · · , xn ) then DI is the identity matrix n × n matrix In . Hence, In = D(I) = D(F ◦ G ...

Testing Time Reversibility of Markov Processes
... Using a central limit theorem for strongly mixing sequences of random variables and Slutsky's Theorem it can be shown that, under some appropriate conditions, L(Tn) ) 2p as M; n ! 1 provided M=n ! 0. Here L(X ) denotes the law of a random variable X and ` )0 weak convergence. Apart from this asymp ...
... Using a central limit theorem for strongly mixing sequences of random variables and Slutsky's Theorem it can be shown that, under some appropriate conditions, L(Tn) ) 2p as M; n ! 1 provided M=n ! 0. Here L(X ) denotes the law of a random variable X and ` )0 weak convergence. Apart from this asymp ...
Ordinary least squares

In statistics, ordinary least squares (OLS) or linear least squares is a method for estimating the unknown parameters in a linear regression model, with the goal of minimizing the differences between the observed responses in some arbitrary dataset and the responses predicted by the linear approximation of the data (visually this is seen as the sum of the vertical distances between each data point in the set and the corresponding point on the regression line - the smaller the differences, the better the model fits the data). The resulting estimator can be expressed by a simple formula, especially in the case of a single regressor on the right-hand side.The OLS estimator is consistent when the regressors are exogenous and there is no perfect multicollinearity, and optimal in the class of linear unbiased estimators when the errors are homoscedastic and serially uncorrelated. Under these conditions, the method of OLS provides minimum-variance mean-unbiased estimation when the errors have finite variances. Under the additional assumption that the errors be normally distributed, OLS is the maximum likelihood estimator. OLS is used in economics (econometrics), political science and electrical engineering (control theory and signal processing), among many areas of application. The Multi-fractional order estimator is an expanded version of OLS.