
Test
... • Can be used in both regression and classification – Is supervised, i.e. training set and test set • KNN is a method for classifying objects based on closest training examples in the feature space. • An object is classified by a majority vote of its neighbors. K is always a positive integer. The ne ...
... • Can be used in both regression and classification – Is supervised, i.e. training set and test set • KNN is a method for classifying objects based on closest training examples in the feature space. • An object is classified by a majority vote of its neighbors. K is always a positive integer. The ne ...

Introduction to data mining - Laboratoire d`Infochimie
... N00: number of instances couple in different clusters for both clustering N11: number of instances couple in same clusters for both clusters N01: number of instances couple in different clusters for the first clustering and in the same clusters for the second N10: number of instances couple in the s ...
... N00: number of instances couple in different clusters for both clustering N11: number of instances couple in same clusters for both clusters N01: number of instances couple in different clusters for the first clustering and in the same clusters for the second N10: number of instances couple in the s ...
Powerpoint
... Do inline URLs point where they say they point? Does the email address you by (your) name? ...
... Do inline URLs point where they say they point? Does the email address you by (your) name? ...

anomaly detection
... LLt ( D ) M t log( 1 ) log PM t ( xi ) At log log PAt ( xi ) N ...
... LLt ( D ) M t log( 1 ) log PM t ( xi ) At log log PAt ( xi ) N ...


CIS526: Homework 7 - Temple University
... b. J48 (decision tree). Note: you will learn about decision tree during your reading assignment. c. NaiveBayes. d. IBk (k-nearest neighbor) e. MultilayerPerc (neural network) f. SMO (support vector machine) g. Bagging of 30 decision trees (meta learning algorithm) Based on the J48 tree result, discu ...
... b. J48 (decision tree). Note: you will learn about decision tree during your reading assignment. c. NaiveBayes. d. IBk (k-nearest neighbor) e. MultilayerPerc (neural network) f. SMO (support vector machine) g. Bagging of 30 decision trees (meta learning algorithm) Based on the J48 tree result, discu ...

Predicting students` final passing results using the Classification and
... knowledge in data in the title of one of his publications [3]. Furthermore, classification is one of the six main tasks of data mining; the others being description, estimation, prediction, clustering and association. Some important points about classification are as follows: ...
... knowledge in data in the title of one of his publications [3]. Furthermore, classification is one of the six main tasks of data mining; the others being description, estimation, prediction, clustering and association. Some important points about classification are as follows: ...

Classification Rules and Genetic Algorithm in Data
... Major Data Mining Tasks and processes include Classification, Clustering, Associations, Visualization, Summarization, Deviation Detection, Estimation, and Link Analysis etc. There are different approaches and techniques used for also known as data mining models and algorithms. Data mining algorithms ...
... Major Data Mining Tasks and processes include Classification, Clustering, Associations, Visualization, Summarization, Deviation Detection, Estimation, and Link Analysis etc. There are different approaches and techniques used for also known as data mining models and algorithms. Data mining algorithms ...


Big Data Infrastructure
... David R. Cheriton School of Computer Science University of Waterloo These slides are available at http://lintool.github.io/bigdata-2016w/ This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States See http://creativecommons.org/licenses/by-nc-sa/3.0/us/ fo ...
... David R. Cheriton School of Computer Science University of Waterloo These slides are available at http://lintool.github.io/bigdata-2016w/ This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States See http://creativecommons.org/licenses/by-nc-sa/3.0/us/ fo ...


comparison of different classification techniques using - e
... unknown, valid patterns and relationships in huge data set. These tools are nothing but the machine learning methods, statistical models and mathematical algorithm. Data mining consists of more than collection and managing the data, it also includes analysis and prediction. Classification technique ...
... unknown, valid patterns and relationships in huge data set. These tools are nothing but the machine learning methods, statistical models and mathematical algorithm. Data mining consists of more than collection and managing the data, it also includes analysis and prediction. Classification technique ...

Machine Learning ICS 273A
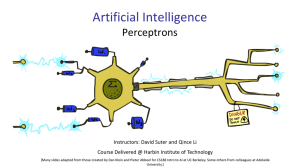
... 5: Neural networks: perceptron, logistic regression, multi-layer networks, backpropagation. ...
... 5: Neural networks: perceptron, logistic regression, multi-layer networks, backpropagation. ...



P( i | )
... Probabilistic P b bili ti llearning: i Calculate C l l t explicit li it probabilities b biliti ffor hypothesis, among the most practical approaches to certain types yp of learning gp problems Incremental: Each training example can incrementally increase/decrease the probability that a hypothesis ...
... Probabilistic P b bili ti llearning: i Calculate C l l t explicit li it probabilities b biliti ffor hypothesis, among the most practical approaches to certain types yp of learning gp problems Incremental: Each training example can incrementally increase/decrease the probability that a hypothesis ...


Lecture Note 7 for MBG 404 Data mining
... The abstract strategy in classification as depicted in Figure 1 depends on a good dataset which has data associated with known class membership (Here class Yes or No). This dataset is used to establish rules that describe, given the data in the attributes, the class membership; the row (tuple) refer ...
... The abstract strategy in classification as depicted in Figure 1 depends on a good dataset which has data associated with known class membership (Here class Yes or No). This dataset is used to establish rules that describe, given the data in the attributes, the class membership; the row (tuple) refer ...




Sliding
... Jakob Verbeek: The EM algorithm, and Fisher vector image representation Cordelia Schmid: Bag-of-features models for category-level classification Student presentation 2: Beyond bags of features: spatial pyramid matching for recognizing natural scene categories, Lazebnik, Schmid and Ponce, CVPR 2006. ...
... Jakob Verbeek: The EM algorithm, and Fisher vector image representation Cordelia Schmid: Bag-of-features models for category-level classification Student presentation 2: Beyond bags of features: spatial pyramid matching for recognizing natural scene categories, Lazebnik, Schmid and Ponce, CVPR 2006. ...

CliDaPa: A new approach for enriching genes expressions using
... CliDaPa approach improved results on disease classification. However, if we analyze the data used, we appreciate that the only data that is not easily understandable for expert biologists is gene expression data. If we obtain new knowledge from gene information, probably we could use it as new infor ...
... CliDaPa approach improved results on disease classification. However, if we analyze the data used, we appreciate that the only data that is not easily understandable for expert biologists is gene expression data. If we obtain new knowledge from gene information, probably we could use it as new infor ...

aaaaaaaaaaaaaaaaaaaaaaaa ´aaaaaaaaaaaaaaaaaaaaaaaa art
... as the output class space. Therefore, pattern classification can be regarded as a function d : X → Y , which assigns an output class label yk c to each ...
... as the output class space. Therefore, pattern classification can be regarded as a function d : X → Y , which assigns an output class label yk c to each ...

K-nearest neighbors algorithm

In pattern recognition, the k-Nearest Neighbors algorithm (or k-NN for short) is a non-parametric method used for classification and regression. In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-NN is used for classification or regression: In k-NN classification, the output is a class membership. An object is classified by a majority vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor. In k-NN regression, the output is the property value for the object. This value is the average of the values of its k nearest neighbors.k-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until classification. The k-NN algorithm is among the simplest of all machine learning algorithms.Both for classification and regression, it can be useful to assign weight to the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones. For example, a common weighting scheme consists in giving each neighbor a weight of 1/d, where d is the distance to the neighbor.The neighbors are taken from a set of objects for which the class (for k-NN classification) or the object property value (for k-NN regression) is known. This can be thought of as the training set for the algorithm, though no explicit training step is required.A shortcoming of the k-NN algorithm is that it is sensitive to the local structure of the data. The algorithm has nothing to do with and is not to be confused with k-means, another popular machine learning technique.