





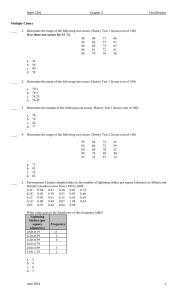






multivariate random variables, correlation, and error propagation
... of thing. Then a single, scalar, rv X is adequate for a probabilistic model. We now generalize this to pairs, triples, ... m-tuples of random variables. We may use such multiple variables either to represent vectorvalued, but still similar, quantities (for example, velocity); or we may use them to m ...
... of thing. Then a single, scalar, rv X is adequate for a probabilistic model. We now generalize this to pairs, triples, ... m-tuples of random variables. We may use such multiple variables either to represent vectorvalued, but still similar, quantities (for example, velocity); or we may use them to m ...






SPSS Regression 17.0
... on only a limited number of values—so that there are several cases at each distinct covariate pattern—the subpopulation approach can produce valid goodness-of-fit tests and informative residuals, while the individual case level approach cannot. Logistic Regression provides the following unique featu ...
... on only a limited number of values—so that there are several cases at each distinct covariate pattern—the subpopulation approach can produce valid goodness-of-fit tests and informative residuals, while the individual case level approach cannot. Logistic Regression provides the following unique featu ...

Chapter 10 - SaigonTech
... between students’ high school grades and college grades. But there probably are many other variables involved, such as IQ, hours of study, influence of parents, motivation, age, and instructors. ...
... between students’ high school grades and college grades. But there probably are many other variables involved, such as IQ, hours of study, influence of parents, motivation, age, and instructors. ...


Bayesian Nonparametric Covariance Regression Emily Fox David Dunson
... Cholesky decomposition of the covariance (or precision) matrix. For example, Pourahmadi [1999] proposes to model elements of chol(Σ(x)−1 ) as a linear function of the predictors. The weights associated with the ith row have a nice interpretation in terms of the conditional distribution of yi given y ...
... Cholesky decomposition of the covariance (or precision) matrix. For example, Pourahmadi [1999] proposes to model elements of chol(Σ(x)−1 ) as a linear function of the predictors. The weights associated with the ith row have a nice interpretation in terms of the conditional distribution of yi given y ...

