


TM-LDA: Efficient Online Modeling of the Latent Topic Transitions in
... not be static, but change over time. In other words, users tend to tweet about different topics instead of simply repeat previous tweets. This very fact implies that to better model the dynamic semantics of tweet streams, we need a temporal-sensitive model that can capture the changing pattern among ...
... not be static, but change over time. In other words, users tend to tweet about different topics instead of simply repeat previous tweets. This very fact implies that to better model the dynamic semantics of tweet streams, we need a temporal-sensitive model that can capture the changing pattern among ...



Cyclic Repeated Patterns in Sequential Pattern Mining
... Based on the above procedure of FCM the input data is clustered. After the FCM process, we obtain the number of cluster set such asC1, C2, C3,….,Cn.. Total number of data considered in our proposed work is 345. Here, we have fixed the cluster size as two; cluster one contains 114 datasets and second ...
... Based on the above procedure of FCM the input data is clustered. After the FCM process, we obtain the number of cluster set such asC1, C2, C3,….,Cn.. Total number of data considered in our proposed work is 345. Here, we have fixed the cluster size as two; cluster one contains 114 datasets and second ...

Pachinko Allocation: DAG-Structured Mixture Models of Topic
... is that it has one additional layer of super-topics modeled with Dirichlet distributions, which is the key component capturing topic correlations here. We present the corresponding graphical models for LDA and PAM in Figure 2. 2.2. Inference and Parameter Estimation The hidden variables in PAM inclu ...
... is that it has one additional layer of super-topics modeled with Dirichlet distributions, which is the key component capturing topic correlations here. We present the corresponding graphical models for LDA and PAM in Figure 2. 2.2. Inference and Parameter Estimation The hidden variables in PAM inclu ...

"Approximate Kernel k-means: solution to Large Scale Kernel Clustering"
... A number of methods have been developed to efficiently cluster large data sets. Incremental clustering [5, 6] and divide-and-conquer based clustering algorithms [3, 18] were designed to operate in a single pass over the data points, thereby reducing the time required for clustering. Sampling based m ...
... A number of methods have been developed to efficiently cluster large data sets. Incremental clustering [5, 6] and divide-and-conquer based clustering algorithms [3, 18] were designed to operate in a single pass over the data points, thereby reducing the time required for clustering. Sampling based m ...
Linear Regression
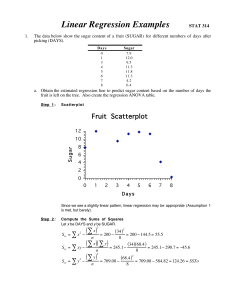
... An athlete who is 60 inches (5 feet) tall will make only 1.1165 goals on average in 60 seconds. Very little confidence can be assigned to this estimate since it seems foolish…short people will almost definitely make more than 1 goal in 60 seconds. This is an example of why we should not extrapolate ...
... An athlete who is 60 inches (5 feet) tall will make only 1.1165 goals on average in 60 seconds. Very little confidence can be assigned to this estimate since it seems foolish…short people will almost definitely make more than 1 goal in 60 seconds. This is an example of why we should not extrapolate ...


DenGraph-HO: A Density-based Hierarchical Graph Clustering
... scribed in Algorithm 1. It uses a stack in order A node u ∈ V is considered as core node if it to process the graph nodes. In a first step, all has an ε-neighborhood of at least η neighbor nodes V are marked as noise. Afterwards, each nodes (|Nε (u)| ≥ η). Nodes which are in the ε- so far unprocesse ...
... scribed in Algorithm 1. It uses a stack in order A node u ∈ V is considered as core node if it to process the graph nodes. In a first step, all has an ε-neighborhood of at least η neighbor nodes V are marked as noise. Afterwards, each nodes (|Nε (u)| ≥ η). Nodes which are in the ε- so far unprocesse ...



Efficient Classification and Prediction Algorithms for Biomedical
... one can store and process large amounts of data quickly and accurately, as well as to access this data from physically distant locations using networks. A large amount of raw data is always stored in a digital format. For example, the supermarket that has hundreds of branches all over a country and ...
... one can store and process large amounts of data quickly and accurately, as well as to access this data from physically distant locations using networks. A large amount of raw data is always stored in a digital format. For example, the supermarket that has hundreds of branches all over a country and ...

The LOGISTIC Procedure
... The LOGISTIC procedure fits linear logistic regression models for binary or ordinal response data by the method of maximum likelihood. The maximum likelihood estimation is carried out with either the Fisher-scoring algorithm or the Newton-Raphson algorithm. You can specify starting values for the pa ...
... The LOGISTIC procedure fits linear logistic regression models for binary or ordinal response data by the method of maximum likelihood. The maximum likelihood estimation is carried out with either the Fisher-scoring algorithm or the Newton-Raphson algorithm. You can specify starting values for the pa ...

pdf
... correspond either to a physical disk or to a partition. We further assume that all VMs v ∈ V are uniform, i.e., they require the same amount of storage resources (one disk or partition at the hosting site and at a remote site) and computing resources (one CPU). This is a rather strong assumption, bu ...
... correspond either to a physical disk or to a partition. We further assume that all VMs v ∈ V are uniform, i.e., they require the same amount of storage resources (one disk or partition at the hosting site and at a remote site) and computing resources (one CPU). This is a rather strong assumption, bu ...

Scalable Density-Based Distributed Clustering
... global site to be analyzed centrally there. On the other hand, it is possible to analyze the data locally where it has been generated and stored. Aggregated information of this locally analyzed data can then be sent to a central site where the information of different local sites are combined and an ...
... global site to be analyzed centrally there. On the other hand, it is possible to analyze the data locally where it has been generated and stored. Aggregated information of this locally analyzed data can then be sent to a central site where the information of different local sites are combined and an ...



Symmetry Based Automatic Evolution of Clusters
... along principal axes. The symmetry based clustering techniques also seek for clusters which are symmetric with respective to their centers. Thus, these techniques will fail if the clusters do not have this property. The objective of this paper is twofold. First, it aims at the automatic determinatio ...
... along principal axes. The symmetry based clustering techniques also seek for clusters which are symmetric with respective to their centers. Thus, these techniques will fail if the clusters do not have this property. The objective of this paper is twofold. First, it aims at the automatic determinatio ...




An efficient approach for finding the MPE in belief networks
... Having found the first MPE, we know the instantiated value of each variable and the associated instantiations of the other variables in the distribution in which the variable was reduced. It is obvious that the instanti ated value is the largest value of all instantiations of the variable with the ...
... Having found the first MPE, we know the instantiated value of each variable and the associated instantiations of the other variables in the distribution in which the variable was reduced. It is obvious that the instanti ated value is the largest value of all instantiations of the variable with the ...
Expectation–maximization algorithm

In statistics, an expectation–maximization (EM) algorithm is an iterative method for finding maximum likelihood or maximum a posteriori (MAP) estimates of parameters in statistical models, where the model depends on unobserved latent variables. The EM iteration alternates between performing an expectation (E) step, which creates a function for the expectation of the log-likelihood evaluated using the current estimate for the parameters, and a maximization (M) step, which computes parameters maximizing the expected log-likelihood found on the E step. These parameter-estimates are then used to determine the distribution of the latent variables in the next E step.