







Hidden Markov Model - Computer Science
... What is the conditional probability P(V| λ) that the observation sequence V is generated by the model λ? Solution: Forward-backward algorithm (Straight-forward calculation of P(V| λ) would be too ...
... What is the conditional probability P(V| λ) that the observation sequence V is generated by the model λ? Solution: Forward-backward algorithm (Straight-forward calculation of P(V| λ) would be too ...

Simulation of MA(1) Longitudinal Negative Binomial Counts and
... estimating equations and thereafter, they were combined to form a quadratic function in a similar way as the GMM approach. This approach of analyzing longitudinal regression models has so far been tested on normal, Poisson data [3] but has not yet been explored in negative binomial correlated counts ...
... estimating equations and thereafter, they were combined to form a quadratic function in a similar way as the GMM approach. This approach of analyzing longitudinal regression models has so far been tested on normal, Poisson data [3] but has not yet been explored in negative binomial correlated counts ...

Local Machine Learning
... selected local training points to generalize the global decision. The Radial Basis Function assumes density distributions can be found in clusters in the data set, which certain “attractor” points at the center of each cluster. Each cluster is then trained with a local algorithm suitable for the ass ...
... selected local training points to generalize the global decision. The Radial Basis Function assumes density distributions can be found in clusters in the data set, which certain “attractor” points at the center of each cluster. Each cluster is then trained with a local algorithm suitable for the ass ...


PDF
... Whereas K-means clustering is a method often used to partition a data set into k groups. It proceeds by selecting k initial cluster and then iteratively refining them as follows: 1. Initialize the center of the clusters μi= some number ,i=1,...,k 2. Attribute the closest cluster to each data point c ...
... Whereas K-means clustering is a method often used to partition a data set into k groups. It proceeds by selecting k initial cluster and then iteratively refining them as follows: 1. Initialize the center of the clusters μi= some number ,i=1,...,k 2. Attribute the closest cluster to each data point c ...





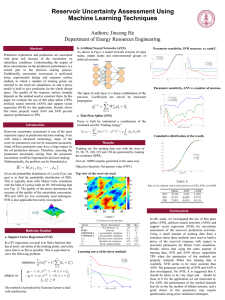
Temporal Process Regression
... paper is different from these earlier works, in that the coefficients are completely unspecified. Nonparametric inference for time-dependent coefficients has been well studied in proportional hazards regression (Zucker and Karr, 1990; Murphy and Sen, 1991; Fahrmeir and Klinger, 1998) and the additiv ...
... paper is different from these earlier works, in that the coefficients are completely unspecified. Nonparametric inference for time-dependent coefficients has been well studied in proportional hazards regression (Zucker and Karr, 1990; Murphy and Sen, 1991; Fahrmeir and Klinger, 1998) and the additiv ...






PRESENTATION NAME
... • Run the SPSA algorithm for different numbers of clusters, K, and calculate the corresponding distortions d K • Select a transformation power, Y • Calculate the “jumps” in transformed distortion J K d ...
... • Run the SPSA algorithm for different numbers of clusters, K, and calculate the corresponding distortions d K • Select a transformation power, Y • Calculate the “jumps” in transformed distortion J K d ...

a comparative study on decision tree and bayes net classifier
... The other task is descretization which is essential for constructing decision tree. The WEKA datamining tool cpuld be used for this purpose. After performing numerical descritization the decision tree could be constructed. WEKA is a very nice tool for implementing the decision tree algorithm [5]. He ...
... The other task is descretization which is essential for constructing decision tree. The WEKA datamining tool cpuld be used for this purpose. After performing numerical descritization the decision tree could be constructed. WEKA is a very nice tool for implementing the decision tree algorithm [5]. He ...
Expectation–maximization algorithm

In statistics, an expectation–maximization (EM) algorithm is an iterative method for finding maximum likelihood or maximum a posteriori (MAP) estimates of parameters in statistical models, where the model depends on unobserved latent variables. The EM iteration alternates between performing an expectation (E) step, which creates a function for the expectation of the log-likelihood evaluated using the current estimate for the parameters, and a maximization (M) step, which computes parameters maximizing the expected log-likelihood found on the E step. These parameter-estimates are then used to determine the distribution of the latent variables in the next E step.