
Logistic Regression
... Suppose that we have a continuous predictor X , and a binary outcome variable Y that in fact has an underlying normal variable W generating it through a threshold values Wc . Assume that X and W have a bivariate normal distribution, are in standard score form, and have a correlation of ρ. We wish to ...
... Suppose that we have a continuous predictor X , and a binary outcome variable Y that in fact has an underlying normal variable W generating it through a threshold values Wc . Assume that X and W have a bivariate normal distribution, are in standard score form, and have a correlation of ρ. We wish to ...

Logistic Regression
... Standardized logit coefficients, also called standardized effect coefficients or beta weights, correspond to beta (standardized regression) coefficients and like them may be used to compare the relative strength of the independents. Odds ratios are preferred for this purpose however, since when usin ...
... Standardized logit coefficients, also called standardized effect coefficients or beta weights, correspond to beta (standardized regression) coefficients and like them may be used to compare the relative strength of the independents. Odds ratios are preferred for this purpose however, since when usin ...

Multiple Regression - Berkeley Statistics
... You should recognize most of the numbers in this table. Most of them mean what you expect them to. R2 gives the fraction of the variability of %body fat accounted for by the multiple regression model. (With waist alone predicting %body fat, the R2 was 67.8%.) The multiple regression model accounts f ...
... You should recognize most of the numbers in this table. Most of them mean what you expect them to. R2 gives the fraction of the variability of %body fat accounted for by the multiple regression model. (With waist alone predicting %body fat, the R2 was 67.8%.) The multiple regression model accounts f ...

document
... μy|x = α + x • α and are constants and are called the coefficients of the equation • α is the y-intercept and which is the mean value of Y when X=0, which is μy|0 • The slope is the change in the mean value of y that corresponds to a one-unit increase in x • E.g. X=3 vs. X=2 ...
... μy|x = α + x • α and are constants and are called the coefficients of the equation • α is the y-intercept and which is the mean value of Y when X=0, which is μy|0 • The slope is the change in the mean value of y that corresponds to a one-unit increase in x • E.g. X=3 vs. X=2 ...

X - Binus Repository
... • If there is violation of any assumption, use alternative methods (e.g., least absolute deviation regression or least median of squares regression) to least-squares regression or alternative least-squares models (e.g., curvilinear or multiple regression) • If there is no evidence of assumption viol ...
... • If there is violation of any assumption, use alternative methods (e.g., least absolute deviation regression or least median of squares regression) to least-squares regression or alternative least-squares models (e.g., curvilinear or multiple regression) • If there is no evidence of assumption viol ...

PDF Download
... A further approach that has a number of common elements with our proposal and combines penalised regression with greedy algorithms has been put forward by Fan and Lv (2008) and analysed further by Fan and Song (2010) and Fan, Samworth, and Wu (2009), among others. This approach considers marginal co ...
... A further approach that has a number of common elements with our proposal and combines penalised regression with greedy algorithms has been put forward by Fan and Lv (2008) and analysed further by Fan and Song (2010) and Fan, Samworth, and Wu (2009), among others. This approach considers marginal co ...

SPSS Regression 17.0
... on only a limited number of values—so that there are several cases at each distinct covariate pattern—the subpopulation approach can produce valid goodness-of-fit tests and informative residuals, while the individual case level approach cannot. Logistic Regression provides the following unique featu ...
... on only a limited number of values—so that there are several cases at each distinct covariate pattern—the subpopulation approach can produce valid goodness-of-fit tests and informative residuals, while the individual case level approach cannot. Logistic Regression provides the following unique featu ...

IBM SPSS Regression 24
... categorical; if categorical, they should be dummy or indicator coded (there is an option in the procedure to recode categorical variables automatically). Assumptions. Logistic regression does not rely on distributional assumptions in the same sense that discriminant analysis does. However, your solu ...
... categorical; if categorical, they should be dummy or indicator coded (there is an option in the procedure to recode categorical variables automatically). Assumptions. Logistic regression does not rely on distributional assumptions in the same sense that discriminant analysis does. However, your solu ...

IBM SPSS Regression 22
... categorical; if categorical, they should be dummy or indicator coded (there is an option in the procedure to recode categorical variables automatically). Assumptions. Logistic regression does not rely on distributional assumptions in the same sense that discriminant analysis does. However, your solu ...
... categorical; if categorical, they should be dummy or indicator coded (there is an option in the procedure to recode categorical variables automatically). Assumptions. Logistic regression does not rely on distributional assumptions in the same sense that discriminant analysis does. However, your solu ...

Introduction to the Use of Regression Models in Epidemiology
... deal with confounding is multiple regression analysis. Other methods are, for example, stratification, the use of instrumental variables, or the application of propensity scores. In this chapter, an overview of the most important multiple regression models is given with a focus on applications in mo ...
... deal with confounding is multiple regression analysis. Other methods are, for example, stratification, the use of instrumental variables, or the application of propensity scores. In this chapter, an overview of the most important multiple regression models is given with a focus on applications in mo ...


Impartial Predictive Modeling: Ensuring Fairness
... Companies will be able to justify the use of partially automated decision making in areas as diverse as loan applications, employment, and college admissions. There will be clear fairness criteria to guide the construction of fair models, thus reducing unintentional discrimination and litigation. A ...
... Companies will be able to justify the use of partially automated decision making in areas as diverse as loan applications, employment, and college admissions. There will be clear fairness criteria to guide the construction of fair models, thus reducing unintentional discrimination and litigation. A ...

Multiple Regression
... The regression weights or regression coefficients (the raw score β s and the standardized Betas) can be interpreted as expressing this unique contribution of a variable: you can say they represent the amount of change in Y that you can expect to occur per unit change in Xi , where X is the ith varia ...
... The regression weights or regression coefficients (the raw score β s and the standardized Betas) can be interpreted as expressing this unique contribution of a variable: you can say they represent the amount of change in Y that you can expect to occur per unit change in Xi , where X is the ith varia ...

Weighted Quantile Regression for Analyzing Health Care Cost Data
... and Yi and He [2] studied quantile regression for modeling longitudinal data with dropouts where the covariates are time invariant (thus are known at all time points) but the response variable may be missing from a certain time point. The weighted estimators in these two papers are defined by weight ...
... and Yi and He [2] studied quantile regression for modeling longitudinal data with dropouts where the covariates are time invariant (thus are known at all time points) but the response variable may be missing from a certain time point. The weighted estimators in these two papers are defined by weight ...

Chapter 9 Simple Linear Regression
... then, from E(Y ) = β0 + β1 x we can see that the population mean of Y is β0 for every x value, which tells us that x has no effect on Y . The alternative is that changes in x are associated with changes in Y (or changes in x cause changes in Y in a randomized experiment). Sometimes it is reasonable ...
... then, from E(Y ) = β0 + β1 x we can see that the population mean of Y is β0 for every x value, which tells us that x has no effect on Y . The alternative is that changes in x are associated with changes in Y (or changes in x cause changes in Y in a randomized experiment). Sometimes it is reasonable ...

Lecture3-Logistic Regression 6-5
... Cytarabine and Etoposide With or Without the Multidrug Resistance Modulator PSC-833 in Previously Untreated Patients 60 Years of Age or Older With Acute Myeloid Leukemia: Results of Cancer and Leukemia Group B Study 9420” Journal of Clinical Oncology, Vol 17, Issue 9 (September), 1999: 283. http://w ...
... Cytarabine and Etoposide With or Without the Multidrug Resistance Modulator PSC-833 in Previously Untreated Patients 60 Years of Age or Older With Acute Myeloid Leukemia: Results of Cancer and Leukemia Group B Study 9420” Journal of Clinical Oncology, Vol 17, Issue 9 (September), 1999: 283. http://w ...
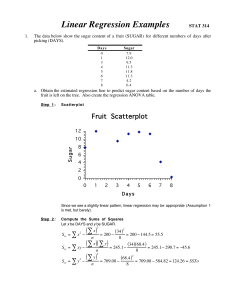
Linear Regression
... An athlete who is 60 inches (5 feet) tall will make only 1.1165 goals on average in 60 seconds. Very little confidence can be assigned to this estimate since it seems foolish…short people will almost definitely make more than 1 goal in 60 seconds. This is an example of why we should not extrapolate ...
... An athlete who is 60 inches (5 feet) tall will make only 1.1165 goals on average in 60 seconds. Very little confidence can be assigned to this estimate since it seems foolish…short people will almost definitely make more than 1 goal in 60 seconds. This is an example of why we should not extrapolate ...

Variable Selection and Decision Trees: The DiVaS
... selection in the linear model and bring these methods to bear on the problem of explicit covariate selection in decision tree models. We also provide theoretical guidelines, including a theorem, which gives necessary and sufficient conditions for consistency of decision trees in infinite dimensional ...
... selection in the linear model and bring these methods to bear on the problem of explicit covariate selection in decision tree models. We also provide theoretical guidelines, including a theorem, which gives necessary and sufficient conditions for consistency of decision trees in infinite dimensional ...

GRADIENT-BASED STRUCTURAL CHANGE DETECTION FOR
... There is a large amount of work in testing structural stability of parameters for general M-estimation and special cases such as least squares and quantile regressions. It is impossible to gather a complete list here and we shall only mention some representative works. For least squares regression, ...
... There is a large amount of work in testing structural stability of parameters for general M-estimation and special cases such as least squares and quantile regressions. It is impossible to gather a complete list here and we shall only mention some representative works. For least squares regression, ...

Ridge Regression
... generally be biased because we can be certain that it is unbiased only when the model that is being used is the correct model. Since we cannot expect this to be true, we similarly cannot expect the OLS estimator to be unbiased. Therefore, although the choice between OLS and a ridge estimator is ofte ...
... generally be biased because we can be certain that it is unbiased only when the model that is being used is the correct model. Since we cannot expect this to be true, we similarly cannot expect the OLS estimator to be unbiased. Therefore, although the choice between OLS and a ridge estimator is ofte ...

Active Learning Based Survival Regression for Censored Data
... support vector machine [13] based approaches have been applied to deal with censored data. These methods in particular can handle non linear relations between the covariates in censored data. Survival regression methods such as Cox proportional hazards [8] and Accelerated failure time (AFT) [26] mod ...
... support vector machine [13] based approaches have been applied to deal with censored data. These methods in particular can handle non linear relations between the covariates in censored data. Survival regression methods such as Cox proportional hazards [8] and Accelerated failure time (AFT) [26] mod ...

15Regdemo - The University of Texas at Dallas
... prediction error. The latter is the difference between the observed value and the predicted value that uses only exogenous variables, rather than treating the spatial lag Wy as observed. (Documentation for 905i, page 53) Prediction error (xxx_PRDERR): calculated without including spatial term. Resid ...
... prediction error. The latter is the difference between the observed value and the predicted value that uses only exogenous variables, rather than treating the spatial lag Wy as observed. (Documentation for 905i, page 53) Prediction error (xxx_PRDERR): calculated without including spatial term. Resid ...

Simple Linear Regression
... relationship between a dependent variable (usually called y) and an independent variable (usually called x). The dependent variable is the variable for which we want to make a prediction. While various non-linear forms may be used, simple linear regression models are the most common. ...
... relationship between a dependent variable (usually called y) and an independent variable (usually called x). The dependent variable is the variable for which we want to make a prediction. While various non-linear forms may be used, simple linear regression models are the most common. ...

Simple Linear Regression
... relationship between a dependent variable (usually called y) and an independent variable (usually called x). The dependent variable is the variable for which we want to make a prediction. While various non-linear forms may be used, simple linear regression models are the most common. ...
... relationship between a dependent variable (usually called y) and an independent variable (usually called x). The dependent variable is the variable for which we want to make a prediction. While various non-linear forms may be used, simple linear regression models are the most common. ...

Logistic Regression
... where ŷ is the probability of a 1, e is the base of the natural logarithm (about 2.718) and b are the parameters of the model. The value of a yields ŷ when X is zero, and b adjusts how quickly the probability changes with changing X a single unit (we can have standardized and unstandardized b in l ...
... where ŷ is the probability of a 1, e is the base of the natural logarithm (about 2.718) and b are the parameters of the model. The value of a yields ŷ when X is zero, and b adjusts how quickly the probability changes with changing X a single unit (we can have standardized and unstandardized b in l ...