Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
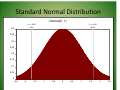
Statistical Distributions and Uncertainty Analysis 2010 CAMRA QMRA Summer Institute Mark H. Weir and Patrick Gurian Probability • Probability – An event will occur or has occurred • There is some level of certainty to this statement • Probability density function – A function f(x) – Within some range, defined as B P[ A < x < B] = ∫ f ( x)dx A Parameters • A model or function has parameters and likely constants • These constants can be ‘tuned’ to fit different applications • Example 1 ( x − µ )2 – Model parameters f ( x) = exp 2 2 σ σ (2π ) – Normal distribution – µ and σ define a normal PDF • Notation for this: X ∼ N(µ, σ2) Standard Normal Distribution Normal(0, 1) X <= -1.650 4.9% 0.4 X <= 1.645 95.0% 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 CDF • Cumulative distribution function (CDF) – Not ranging from A to B x F ( x) = ∫ f ( x)dx −∞ • Can still determine the range from A to B P[A < x < B ] = F ( B ) − F ( A) Normal CDF Normal(0, 1) X <= -1.650 4.9% 1 X <= 1.645 95.0% 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 Short cut to Normal F(X) x • F ( x) = ∫−∞ f ( x)dx requires numerical integration • Define Z = ( X − µ )σ – Thus Z∼N(µ, σ) • σ > 0 alows a monotonic transformation • The largest X corresponds to the largest Z – As well as for the 95th percentiles • Z is tabulated for ease of use Example • Car repairs are ∼ N(300, 1002) • What is P[repair > 450]? • Z = (X - µ)/σ • Z = (450-300)/100 = 1.5 • F(Z) = F(1.5) = 0.933 – See table of Z values http://www.stat.psu.edu/~babu/418/norm-tables.pdf • 0.933 = P[Z<1.5] = P[repair < 450] • P[repair > 450] = 1 – 0.933 = 0.067 Standard Normal Distribution in Excel • Set up a vector in one column – Cell A2 = -0.25 Cell A3: 0.25 + 0.025 • Copy until 0.25 is encountered • In next column = normdist(x, mean, std dev, FALSE) For cumulative distribution = normdist(x, mean, std dev, TRUE) • Return x based on p(x) = norminv(p, mean, std dev) norminv is always cumulative by its definition Variability • Changes in outcome in time, space or different trials • Concentration of microbes in water samples • Amount of water consumed – Knowing about the entire system, there is still variability in how much water individuals drink Uncertainty • Uncertainty is a lack of knowledge • Risk presented by low doses of toxins or pathogens • Sensitivity of the climate system to a doubling of pre-industrial carbon dioxide – There is only one value, we just don’t know it Variable and Uncertain • A limited amount of information is available on the concentration of Cryptosporidium in drinking water • Based on N=20, mean = 3/100 liter, variance = 3/100 liter • The number in any given sample is variable with a Poisson distribution describing this variability • The true mean is uncertain – It was just estimated based on limited information Probability Distributions as Models • Probability was originally developed for describing variability • It is now widely applied to describe uncertainty Bayesian Framework • Describe variability in observations with a probability distribution • Stage 1: oocysts ∼ Poisson(λ) • Describe uncertainty in this parameter with a probability distribution • Stage 2: ln(λ) ∼ N(µ, σ) Fitting Distributions • We often need to find probability distributions to describe variability and uncertainty in risk assessments • Often start with a general class of model and then adjust it to match the specific case Statistical Model Estimation • Statistical model all contain parameters • Parameters are constants that can be ‘tuned’ to make a general class of models applicable to a specific dataset Example: Normal Distribution 1 ( x − µ )2 f ( x) = exp 2 2 σ σ (2π ) PDF is: µ and σ are constants that define a particular normal distribution We want to pick values which match a given dataset One simple way is method of moments, where: x = µ and s = σ But there are other ways Maximum Likelihood Estimation • Assume a probability model • Calculate the probability (likelihood) or obtain the observed data • Now adjust parameter values until you find the values that maximize the probability of obtaining or observing data Likelihood Function • • • • Observe data x, a vector of values Assume some pdf f(x|θ) Where θ is a vector of model parameters Probability of any particular value is f(xi| θ) where i is an index indicating a particular observation in the data Likelihood of the data • Generally assume data is independent and identically distributed • Same f(x) for all data • For independent data: • prob [Event A ∩ Event B] = prob[A] Prob[B] • So multiple probability of individual observations to get joint probability of data • L=π f(xi| θ) • Now find θ that maximizes L MLE Example • A team plays 3 games: W L L • Binomial model: what is p? • L=(3:1)p(1-p)2 • Suppose we know sequence of wins and losses then we can say • L=p(1-p)2 MLE Example Continued • Suppose p = 0.5 • L = 0.52 * 0.5 = 0.125 MLE Example Continued • Now suppose p = 0.3 • What is the likelihood of the data? • Do we prefer p = 0.5 or p = 0.3? Answer • L=0.3*0.7*0.7=0.147 • Likelihood of data is greater with p=0.3 than with p=0.5 • We prefer p=0.3 as a parameter estimate to 0.5 Example: Maximizing the Likelihood • • • • • • dL/dp= 3(1-p)2 - 6p(1-p) Find maximum at dL/dp=0 0=3(1-p)2 - 6p(1-p) 0=1-p -2p 3p=1 p=1/3 MLE Example: Conclusion • Can verify that this is a maxima by looking at second derivative • Note that method of moments would give us p=x/n=1/3 • So we get the same result by both methods Ln Likelihood • Product of many numbers each <1 is quite small • Often easiest to work with ln (L) • Since ln is a monotonic transformation of L, the largest ln (L) will correspond to the largest L value Ln L=ln π f(xi| θ) Applying log laws Ln L=Σ ln f(xi| θ) Uncertainty Uncertainty • Lack of certainty • Unable to exactly describe each possible state or outcome • Different types • Data uncertainty • Parameter uncertainty • Uncertainty in fitting Uncertainty and Parameter Estimates • Generally statistical methods quantify sample variability AND ONLY sample variability • The properties of the specific sample that I took will vary from the long run population properties • But as my sample becomes large its properties approach those of the population • Statistical methods quantify how much I know about the population given a particular sample Standard Errors • Standard error is the variance of the parameter estimate • For simple cases formulae exist for standard errors of parameter estimates • Arithmetic mean ~ N(μ, σ2/n) • Standard error is σ2/n • Formulae are not always available Bootstrapping • A general approach to generating confidence intervals for any statistic • Assume your sample is a discrete distribution, PMF for population • Sample from this PMF with replacement and get observed distribution of statistics of interest • Generate a new sample set of same size as original sample size since you usually want confidence interval for this size of sample • Calculate statistic of interest • Repeat (many times) and characterize distribution of statistic of interest Basis of Bootstrap • Because you sample with replacement you get a randomly varying different sample • Makes sense intuitively • Developed and used and then later justified by theory Bootstrap Advantages • Bootstrap will give you not just upper bound but also uncertainty range for this upper bound • Generally applicable • No distributional assumptions • Other method, Monte Carlo • Distributional assumptions of fitting required • Typically more computationaly intensive Monte Carlo and Crystal ® Ball Monte Carlo? • Gaming and resort area – Monaco • Also good for CAMRA • Simulation method Enrico Fermi Nicholas Metropolis – Random sampling – Model iterations • Refining of estimates • Los Alamos NL – Radiation Shielding Stanislaw Ulam John von Neumann Monte Carlo Simplified • Think of a die – Only two or four on each side – Throw twice – Throw 1,000 times – Throw 10,000 times • Random samples – Set of constrained possibilities • Multiple iterations inform the uncertainties Iterations • Throws of the die • The more throws – More accurate the description – Higher chances • Correct solution • Understanding the uncertainty • Limits – Originally: when your hand got sore – Now: computational capability, time Monte Carlo • Deterministic model • Uncertain variables – Range of possibilities • No defined point • Randomly sample – From uncertain variables – Evaluate deterministic model y = m( x ) + b Randomly Sample Something Unknown? • Probability distribution • More random in sampling • Can consider extreme situations while only knowing the averages or light deviation. – Flood frequency analysis, landslides Iterations • Throws of the die • The more throws – More accurate the description – Higher chances • Correct solution • Understanding the uncertainty • Limits – Originally: when your hand got sore – Now: computational capability, time Crystal Ball® • Solver – More powerful – Fancier • Multiple iterations • Random sampling • Multiple forecast models (deterministic models) Crystal Ball • www.oracle.com/crystalball – Will redirect you • Bottom window (in bold print: ORACLE CRYSTAL BALL) – Click on Oracle Crystal Ball • Right hand side of Screen – Downloads • Oracle Crystal Ball Free Trial – Follow instructions to download and install Tuberculosis on Airliner Example • Mycobacterium tuberculosis • Data distributions and background – Report written by CAMRA • Infected person • You • Others on the airplane We Will Not… • Handle the airflows • Handle the filtration – HEPA – On vs. off • Movement – Passengers and crew • Direct inclusion of breathing rate • Further complications… We Will Consider • Frequency of cough • Infectious particles in a cough • Will source it in your row? We Will Consider • Will source sit in your row? • Uncertain variable • In simplest terms – 1:399 that you will sit next to source – Large flight ~ 400 seats – 399 possible values No less than 0% chance 1:399 No more than 100% chance We Will Consider • Number of coughs – CAMRA TB analysis • a.k.a. expert elicitation We Will Consider • How Many infectious particles in a cough/sneeze – Expert elicitation: CAMRA TB analysis We Will Consider • Infectious particles sizes – Expert Elicitation: CAMRA TB analysis Now Into the Models • Dose – Simplest form for what we know Dose = • • • • * * Number of particles Proper particle size Source sat next to you Source coughing frequency * Models continued • Probability of infection: – Exponential dose response for infection − k ⋅dose – Known k parameter P( Inf ) = 1 − e Dose = * * * Example • Make the assumption cells – The uncertain variables • • • • Probability distributions Triangular: min: 0.00 max: 1.00 likeliest: 1/399 Cough λ: log Normal: mean: 7.80 σ: 4.10 Particles in cough: Weibull: Scale = 35.2 Shape:0.521 • Particle Size: log Normal: mean: 0.64 σ: 0.32 • Make the forecast cells – The model Example Results Demo of Defining Cells and Running a Simulation Extras which may be helpful