Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
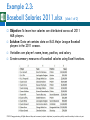
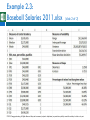
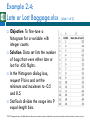
Chapter 2 © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. BUSINESS ANALYTICS: DATA ANALYSIS AND DECISION MAKING Describing the Distribution of a Single Variable Introduction (slide 1 of 2) The goal is to present data in a form that makes sense to people. Tools that are used to do this include: Graphs: bar charts, pie charts, histograms, scatterplots, time series graphs Numerical summary measures: counts, percentages, averages, measures of variability Tables of summary measures: totals, averages, counts, grouped by categories It is a challenge to summarize data so that the important information stands out clearly. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Introduction (slide 2 of 2) There are four steps in data analysis: 1. 2. 3. 4. Recognize a problem that needs to be solved. Gather data to help understand and then solve the problem. Analyze the data. Act on this analysis. It is up to you to ask good questions—and then take advantage of the most appropriate tools to answer them. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Populations and Samples A population includes all of the entities of interest in a study (people, households, machines, etc.) Examples: All potential voters in a presidential election All subscribers to cable television All invoices submitted for Medicare reimbursement by nursing homes A sample is a subset of the population, often randomly chosen and preferably representative of the population as a whole. Examples: Gallup, Harris, other polls today © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Data Sets, Variables, and Observations A data set is usually a rectangular array of data, with variables in columns and observations in rows. A variable (or field or attribute) is a characteristic of members of a population, such as height, gender, or salary. An observation (or case or record) is a list of all variable values for a single member of a population. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.1: Questionnaire Data.xlsx Objective: To illustrate variables and observations in a typical data set. Solution: Data set includes observations on 30 people who responded to a questionnaire on the president’s environmental policies. Variables include: age, gender, state, children, salary, opinion. Include a row that lists variable names. Include a column that shows an index of the observation. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Types of Data (slide 1 of 5) A variable is numerical if meaningful arithmetic can be performed on it. Otherwise, the variable is categorical. There is also a third data type, a date variable. Excel® stores dates as numbers, but dates are treated differently from typical numbers. A categorical variable is ordinal if there is a natural ordering of its possible values. If there is no natural ordering, it is nominal. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Types of Data (slide 2 of 5) Categorical variables can be coded numerically or left uncoded. A dummy variable is a 0–1 coded variable for a specific category. It is coded as 1 for all observations in that category and 0 for all observations not in that category. Categorizing a numerical variable by putting the data into discrete categories (called bins) is called binning or discretizing. A variable that has been categorized in this way is called a binned or discretized variable. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Environmental Data Using a Different Coding (slide 3 of 5) © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Types of Data (slide 4 of 5) A numerical variable is discrete if it results from a count, such as the number of children. A continuous variable is the result of an essentially continuous measurement, such as weight or height. Cross-sectional data are data on a cross section of a population at a distinct point in time. Time series data are data collected over time. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Typical Time Series Data Set (slide 5 of 5) © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Descriptive Measures for Categorical Variables There are only a few possibilities for describing a categorical variable, all based on counting: Count the number of categories. Give the categories names. Count the number of observations in each category (referred to as the count of categories). Once you have the counts, you can display them graphically, usually in a column chart or a pie chart. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.2: Supermarket Transactions.xlsx (slide 1 of 3) Objective: To summarize categorical variables in a large data set. Solution: Data set contains transactions made by supermarket customers over a two-year period. Children, Units Sold, and Revenue are numerical. Purchase Date is a date variable. Transaction and Customer ID are used only to identify. All of the other variables are categorical. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.2: Supermarket Transactions.xlsx (slide 2 of 3) To get the counts in column S, use Excel’s COUNTIF function. To get the percentages in column T, divide each count by the total number of observations. When creating charts, be careful to use appropriate scales. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.2: Supermarket Transactions.xlsx (slide 3 of 3) Another efficient way to find counts for a categorical variable is to use dummy (0–1) variables. Recode each variable so that one category is replaced by 1 and all others by 0. This can be done using a simple IF formula. Find the count of that category by summing the 0s and 1s. Find the percentage of that category by averaging the 0s and 1s. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Descriptive Measures for Numerical Variables There are many ways to summarize numerical variables, both with numerical summary measures and with charts. To learn how the values of a variable are distributed, ask: What are the most “typical” values? How spread out are the values? What are the “extreme” values on either end? Is the chart of the values symmetric about some middle value, or is it skewed in some direction? Does it have any other peculiar features besides possible skewness? © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.3: Baseball Salaries 2011.xlsx (slide 1 of 2) Objective: To learn how salaries are distributed across all 2011 MLB players. Solution: Data set contains data on 843 Major League Baseball players in the 2011 season. Variables are player’s name, team, position, and salary. Create summary measures of baseball salaries using Excel functions. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.3: Baseball Salaries 2011.xlsx (slide 2 of 2) © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Measures of Central Tendency (slide 1 of 3) The mean is the average of all values. If the data set represents a sample from some larger population, this measure is called the sample mean and is denoted by X. If the data set represents the entire population, it is called the population mean and is denoted by μ. In Excel, the mean can be calculated with the AVERAGE function. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Measures of Central Tendency (slide 2 of 3) The median is the middle observation when the data are sorted from smallest to largest. If the number of observations is odd, the median is literally the middle observation. If the number of observations is even, the median is usually defined as the average of the two middle observations. In Excel, the median can be calculated with the MEDIAN function. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Measures of Central Tendency (slide 3 of 3) The mode is the value that appears most often. In most cases where a variable is essentially continuous, the mode is not very interesting because it is often the result of a few lucky ties. However, it is not always a result of luck and may reveal interesting information. In Excel, the mode can be calculated with the MODE function. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Minimum, Maximum, Percentiles, and Quartiles For any percentage p, the pth percentile is the value such that a percentage p of all values are less than it. The quartiles divide the data into four groups, each with (approximately) a quarter of all observations. The first, second and third quartiles are the percentiles corresponding to p = 25%, p = 50%, and p = 75%. By definition, the second quartile (p = 50%) is equal to the median. The minimum and maximum values can be calculated with Excel’s MIN and MAX functions, and the percentiles and quartiles with Excel’s PERCENTILE and QUARTILE functions. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Measures of Variability (slide 1 of 3) The range is the maximum value minus the minimum value. The interquartile range (IQR) is the third quartile minus the first quartile. Thus, it is the range of the middle 50% of the data. It is less sensitive to extreme values than the range. The variance is essentially the average of the squared deviations from the mean. If Xi is a typical observation, its squared deviation from the mean is (Xi – mean)2. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Measures of Variability (slide 2 of 3) sample variance is denoted by s2, and the population variance by σ2. The If all observations are close to the mean, their squared deviations from the mean—and the variance—will be relatively small. If at least a few of the observations are far from the mean, their squared deviations from the mean—and the variance— will be large. In Excel, use the VAR function to obtain the sample variance and the VARP function to obtain the population variance. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Measures of Variability (slide 3 of 3) A fundamental problem with variance is that it is in squared units (e.g., $ $2). A more natural measure is the standard deviation, which is the square root of variance. The sample standard deviation, denoted by s, is the square root of the sample variance. The population standard deviation, denoted by σ, is the square root of the population variance. In Excel, use the STDEV function to find the sample standard deviation or the STDEVP function to find the population standard deviation. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Calculating Variance and Standard Deviation © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Empirical Rules for Interpreting Standard Deviation (slide 1 of 3) The interpretation of the standard deviation can be stated as three empirical rules. If the values of a variable are approximately normally distributed (symmetric and bell-shaped), then the following rules hold: Approximately 68% of the observations are within one standard deviation of the mean. Approximately 95% of the observations are within two standard deviations of the mean. Approximately 99.7% of the observations are within three standard deviations of the mean. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Empirical Rules for Baseball Salaries (slide 2 of 3) The empirical rules should be applied with caution, especially when the data are clearly skewed, as illustrated by the calculations for baseball salaries below. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Empirical Rules for Interpreting Standard Deviation (slide 3 of 3) The mean absolute deviation (MAD) is the average of the absolute deviations. In Excel, use the AVEDEV function to calculate MAD. There is another empirical rule for MAD: For many variables, the standard deviation is approximately 25% larger than MAD. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Measures of Shape (slide 1 of 2) Skewness occurs when there is a lack of symmetry. A variable can be skewed to the right (or positively skewed) because of some really large values (e.g., really large baseball salaries). Or it can be skewed to the left (or negatively skewed) because of some really small values (e.g., temperature lows in Antarctica). In Excel, a measure of skewness can be calculated with the SKEW function. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Measures of Shape (slide 2 of 2) Kurtosis has to do with the “fatness” of the tails of the distribution relative to the tails of a normal distribution. A distribution with high kurtosis has many more extreme observations. In Excel, kurtosis can be calculated with the KURT function. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Numerical Summary Measures in the Status Bar and with StatTools If you select multiple cells, summary measures appear for the selected cells in the status bar at the bottom of the Excel window. You can choose the summary measures that appear by right-clicking the status bar and selecting your favorites. Although Excel’s built-in functions can be used to calculate a number of summary measures, a much quicker way is to use the StatTools add-in. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.3 (Continued): Baseball Salaries 2011.xlsx Objective: To learn the fundamentals of StatTools and use it to generate summary measures of baseball salaries. Solution: First, define a StatTools data set, by selecting any cell in the data set and clicking the Data Set Manager button. Then generate summary measures for the Salary variable, by selecting OneVariable Summary from the Summary Statistics dropdown list and filling in the dialog box that appears. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Charts for Numerical Variables There are many graphical ways to indicate the distribution of a numerical variable. For cross-sectional variables: Histograms Box For plots time series variables: Time series graphs © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Histograms A histogram is the most common type of chart for showing the distribution of a numerical variable. It is based on binning the variable—that is, dividing it up into discrete categories. It is a column chart of the counts in the various categories (with no gaps between the vertical bars). A histogram is great for showing the shape of a distribution—whether the distribution is symmetric or skewed in one direction. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.3 (Continued): Baseball Salaries 2011.xlsx (slide 1 of 2) Objective: To see the shape of the salary distribution through a histogram. Solution: It is possible to create a histogram with Excel tools only—but it is a tedious process. The resulting table of counts is usually called a frequency table. The counts are called frequencies. It is much easier to create a histogram with StatTools. First, designate a StatTools data set. Next, select Histogram from the Summary Graphs dropdown list. In the dialog box, select the Salary variable and click OK. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.3 (Continued): Baseball Salaries 2011.xlsx (slide 2 of 2) © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.4: Late or Lost Baggage.xlsx (slide 1 of 2) Objective: To fine-tune a histogram for a variable with integer counts. Solution: Data set lists the number of bags that were either late or lost for 456 flights. In the Histogram dialog box, request 9 bins and set the minimum and maximum to -0.5 and 8.5. StatTools divides the range into 9 equal-length bins. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.4: Late or Lost Baggage.xlsx (slide 2 of 2) © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Box Plots A box plot (or box-whisker plot) is an alternative type of chart for showing the distribution of a variable. The elements of a generic box plot are shown below: © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.3 (Continued): Baseball Salaries 2011.xlsx Objective: To illustrate the features of a box plot, particularly how it indicates skewness. Solution: In StatTools, select Box-Whisker Plot from the Summary Graphs dropdown list and fill in the dialog box. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Time Series Data Our main interest in time series variables is how they change over time, and this information is lost in traditional summary measures and in histograms or box plots. For time series data, a time series graph is used. This is a graph of the values of one or more time series, using time on the horizontal axis. This is always the place to start a time series analysis. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.5: Crime in US.xlsx (slide 1 of 3) Objective: To see how time series graphs help to detect trends in crime data. Solution: Data set contains annual data on violent and property crimes for the years 1960 to 2010. In StatTools, designate a StatTools data set. Then select Times Series Graph from the Time Series and Forecasting dropdown list and fill in the resulting dialog box. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.5: Crime in US.xlsx (slide 2 of 3) Total Violent and Property Crimes Population Totals © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.5: Crime in US.xlsx (slide 3 of 3) Violent and Property Crime Rates © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.6: DJIA Monthly Close.xlsx (slide 1 of 2) Objective: To find useful ways to summarize the monthly Dow data. Solution: Data set contains monthly values of the Dow from 1950 through 2011. Create summary measures and time series graphs for monthly values and percentage changes of the Dow. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.6: DJIA Monthly Close.xlsx (slide 2 of 2) © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Outliers An outlier is a value or an entire observation (row) that lies well outside of the norm. Some statisticians define an outlier as any value more than three standard deviations from the mean, but this is only a rule of thumb. Even if values are not unusual by themselves, there still might be unusual combinations of values. When dealing with outliers, it is best to run the analyses two ways: with the outliers and without them. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Missing Values Most real data sets have gaps in the data. There are two issues: how to detect these missing values and what to do about them. The more important issue is what to do about them: One option is to simply ignore them. Then you will have to be aware of how the software deals with missing values. Another option is to fill in missing values with the average of nonmissing values, but this isn’t usually a very good option. A third option is to examine the nonmissing values in the row of a missing value; these values might provide clues on what the missing value should be. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Excel Tables for Filtering, Sorting, and Summarizing Tables are a tool introduced in Excel 2007. You now have the ability to designate a rectangular data set as a table and then employ a number of powerful tools for analyzing tables. These tools include: Filtering Sorting Summarizing © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.7: Catalog Marketing.xlsx (slide 1 of 2) Objective: To illustrate Excel tables for analyzing the HyTex data. Solution: Data set contains data on 1000 customers of HyTex, a fictional direct marketing company. Designate the data set as a table by selecting any cell in the data set and clicking the Table button on the Insert ribbon. Use the dropdown arrows next to the variable names to filter in many different ways. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.7: Catalog Marketing.xlsx (slide 2 of 2) © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Filtering Finding records that match particular criteria is called filtering. One way to filter is to create an Excel table, which automatically provides dropdown arrows next to the field names that allow you to filter. There are also three ways to filter on any rectangular data set with variable names: 1. 2. 3. Use the Filter button from the Sort & Filter dropdown list on the Home ribbon. Use the Filter button from the Sort & Filter group on the Data ribbon. Right-click any cell in the data set and select Filter. You get several options, the most popular of which is Filter by Selected Cell’s Value. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.7 (Continued): Catalog Marketing.xlsx (slide 1 of 2) Objective: To investigate the types of filters that can be applied to the HyTex data. Solution: There is almost no limit to the filters you can apply, but here are a few possibilities: Filter on one or more values in a field. Filter on more than one field. Filter on a continuous numerical field. Top 10 and Above/Below Average filters. Filter on a text field. Filter on a date field. Filter on color or icon. Use a custom filter. © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part. Example 2.7 (Continued): Catalog Marketing.xlsx (slide 2 of 2) Results from a Typical Filter © 2015 Cengage Learning. All Rights Reserved. May not be scanned, copied or duplicated, or posted to a publicly accessible website, in whole or in part.