Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
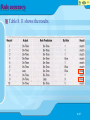
Chapter 8 Decision Tree Algorithms Rule Based Suitable for automatic generation 結束 Contents Presents the concept of decision tree models Discusses the concept rule interestingness Demonstrates decision tree rules on a case Review real applications of decision tree models Shows the application of decision tree models to larger data sets Demonstrates See5 decision tree analysis in the appendix 8-2 結束 Problems Grocery stores has a massive data problem in inventory control, dealt with a high degree by bar-coding. The massive data database of transactions can be mined to monitor customer demand. Decision trees provide a means to obtain productspecific forecasting models in the form of rules (IFTHEN) that are easy to implement. Decision-tree can be used by grocery stores in a number of policy decisions, including ordering inventory replenishment and evaluating alternative promotion campaigns. 8-3 結束 Decision tree Decision tree refers to the tree structure of rules (often association rules). The decision tree modeling process involves collecting those variables that the analyst thinks might bear on the decision at issue, and analyzing these variables for their ability to predict the outcome. The algorithm automatically determines which variables are most important, based on their ability to sort the data into the correct output category. Decision tree has a relative advantage over ANN and GA in that a reusable set of rules are provided, this explaining model conclusions. 8-4 結束 Decision Tree Applications Classifying loan applications, screening potential consumers, and rating job applicants. Decision tree provide a way to implement rule-based system approach. 監督式學習模型 樹型結構 決策樹 (類別型屬性) 關聯模式 規則誘發 迴歸樹 (連續型屬性) CN2 ITRULE CART CART C4.5/C5 ID3 M5 Cubist 8-5 結束 Types of Trees Classification tree Variable values classes Finite conditions Regression tree Variable values continuous numbers Prediction or estimation 8-6 結束 Rule Induction Automatically process data Classification (logical, easier) Regression (estimation, messier) Search through data for patterns & relationships Pure knowledge discovery Assumes no prior hypothesis Disregards human judgment 8-7 結束 Decision trees Logical branching Historical: ID3 – early rule- generating system C4.5 See 5 Branches: Different possible values Nodes: From which branches emanate (spray) 8-8 結束 Decision tree operation A bank may have a database of pass loan applicants for short-term loans. (see table. 4.4) The bank’s policy treats applicants differently by age group, income level, and risk. A tree sorts the possible combinations of these variables. An exhaustive tree enumerates all combinations of variable values in Table. 8.1 8-9 結束 Decision tree operation 8-10 結束 Decision tree operation A rule-based system model would require that bank loan officers who had respected judgment be interviewed to classify the decision for each of these combinations of variables. Some situations can be directly reduced in decision tree. 8-11 結束 Rule interestingness Data, even categorical data can potentially involve many rules. See Table. 8.1, 333=27 combinations. If 10 variables and each with 4 possible values(410=1,048,576), the combinations become over a million. unreasonable Decision tree models identify the most useful rules in terms of predicting outcomes. Rule effectiveness is measured in terms of confidence and support. Confidence is the degree of accuracy of a rule Support is the degree to which the antecedent condition occur in the data. 8-12 結束 Tanagra Example 8-13 結束 Support & Confidence Support for an association rule indicates the proportion of records covered by the set of attributes in the association rules. Example: If there were 10 million book purchases, support for the given rule would be 10/10,000,000, a very small support measure of 0.000001. These concepts are often used in the form of threshold levels in machine learning systems. Minimum confidence levels and support levels can be specified to retain rules identified by decision tree. 8-14 結束 Machine learning Rule-induction algorithms can automatically process categorical data (also can work on continuous data). A clear outcome is needed. Rule induction works by searching through data for patterns and relationships. Machine learning starts with on assumptions, looking only at input data and results. Recursive partitioning algorithms split data (original data) into finer and finer subsets leading to a decision tree. 8-15 結束 Cases 20 past loan application cases in Table 8.3. 8-16 結束 Cases Automatic machine learning begins with identifying those variables that offer the great likelihood of distinguishing between the possible outcomes. For each of the three variables, the outcome probabilities illustrated in Table 8.5 (next slide) Most data mining packages use an entropy measure to gauge the discriminating power of each variable (split data) (Chi-square measures can also be used to select variables) 8-17 結束 Cases Table 8.4 Grouped data Table 8.5 Combination outcomes 8-18 結束 Entropy formula p p n n Inform log 2 log 2 pn pn pn pn Where p is the number of positive examples and n is the number of negative examples in the training set for each value of the attribute. The lower the measure (entropy), the greater the information content Can use to automatically select variable with most productive rule potential 8-19 結束 Entropy formula p p n n Inform log 2 log 2 pn pn pn pn The entropy formula has a problem if either p or n are 0, then the log2 is undefined. Entropy for each Age category generated by the formula is shown in Table 8.6. × + × × Category Young: [-(8/12)(-0.585)-(4/12)(-1.585)](12/20)=0.551 The lower entropy measure, the greater the information content (the greater the agreement probability) Rule: If (Risk=low) then Predict on-time payment Else predict late 8-20 結束 Entropy Young - 8/12 × -0.390 – 4/12 × -0.528 × 12/20: 0.551 Middle - (4/5 × -0.322) – (1/5 x -2.322) × 5/20: 0.180 Old - 3/3 × 0 – 0/3 × 0 × 3/20: SUM Income Risk 0.000 0.731 0.782 0.446 (lowest) By the measures, Risk has the greatest information content. If Risk is low, the data indicates a 1.0 probability that the applicant will pay the loan back on time. 8-21 結束 Evaluation Two type errors may occur: 1. Those applicants rated as low risk actually not pay on time (from the data, the probability of this case is 0.0) 2. Those applicants rated as high or average risk may actually have paid if given a loan. (from the data, the probability of this happening is 0.25. 5/20=0.25) Expected error 0.250.5 (the p of being wrong)=0.125 Test the model using another set of data. 8-22 結束 Evaluation The entropy formula for Age, given the risk was not low 0.99, while the same calculation for income is 1. 971. Age has greater discriminating power. If age is middle, the one case did not pay one time. If (Risk is Not low) AND (Age=Middle) Then Predict late Else Predict On-time 8-23 結束 Evaluation For last variable, income, give that Risk was not low, and Age was not Middle, there are nine cases left and shown in Table 8.8. A third rule takes advantage of the case with u’nanimous (agree) outcome is: If (Risk Not low) AND (Age NOT middle) AND (income high) Then predict Late Else Predict on-time See page 141 for more explanations 8-24 結束 Rule accuracy The expected accuracy of the three rules is shown in Table 8.9. The expected error is 8/20=0.375 (1-0.625) An additional rule could be generated. For the case of Risk not low, Age=Young, and Income Not high (four cases with low income (p of on-time) =0.5 and four cases with average income (p of on-time = 0.75) The greater discrimination is provided by average income, resulting in the following rule: If (Risk not low) and (Age not middle) and (income average) Then predict on-time Else predict either 8-25 結束 Rule accuracy There is no added accuracy obtained with this rule, shown in Table 8.10. The expected error is 4/20 times 0.5 = 0.15 the same without the rule. When machine learning methods encounter no improvement, they generally stop. 8-26 結束 Rule accuracy Table 8.11 shows the results. 8-27 結束 Rule accuracy 8-28 結束 Inventory Prediction Groceries Maybe over 100,000 SKUs Barcode data input Data mining to discover patterns Random sample of over 1.6 million records 30 months 95 outlets Test sample 400,000 records Rule induction more workable than regression 28,000 rules Very accurate, up to 27% improvement 8-29 結束 Clinical Database Headache Over 60 possible causes Exclusive reasoning uses negative rules Use when symptom absent Inclusive reasoning uses positive rules Probabilistic rule induction expert system Headache: Training sample over 50,000 cases, 45 classes, 147 attributes Meningitis(腦膜炎): 1200 samples on 41 attributes, 4 outputs 8-30 結束 Clinical Database Used AQ15, C4.5 Average accuracy 82% Expert System Average accuracy 92% Rough Set Rule System Average accuracy 70% Using both positive & negative rules from rough sets Average accuracy over 90% 8-31 結束 Software Development Quality Telecommunications company Goal: find patterns in modules being developed likely to contain faults discovered by customers Typical module several million lines of code Probability of fault averaged 0.074 Apply greater effort for those Specification, testing, inspection 8-32 結束 Software Quality Preprocessed data Reduced data Used CART (Classification & Regression Trees) Could specify prior probabilities First model 9 rules, 6 variables Better at cross-validation But variable values not available until late Second model 4 rules, 2 variables About same accuracy, data available earlier 8-33 結束 Rules and evaluation 8-34 結束 Rules and evaluation The Second models rules Two models were very close in accuracy. The fist model was better at cross validation accuracy, but its variables were available just prior to release. The second model had the advantage of being based on data available at an earlier state and required less extensive data reduction. See also, page .146 for expert system 8-35 結束 Applications of methods to larger data sets Expenditure application to find the characteristics of potential customers for each expenditure category. A simple case is to categorize clothing expenditures (or other expenditures in the data set) per year as a 2-class classification problem. Data preparation data transformation, see page 154 Comparisons of A-prioriC4.5C5.0 8-36 結束 Fuzzy Decision Trees Have assumed distinct (crisp) outcomes Many data points not that clear Fuzzy: Membership function represents belief (between 0 and 1) Fuzzy relationships have been incorporated in decision tree algorithms 8-37 結束 Fuzzy Example Age Young 0.3 Income Low 0.0 Risk Low 0.1 Definitions: Middle 0.9 Average 0.8 Average 0.8 Old 0.2 High 0.3 High 0.3 Sum will not necessarily equal 1.0 If ambiguous, select alternative with larger membership value Aggregate with mean 8-38 結束 Fuzzy Model IF Risk=Low Then OT Membership function: 0.1 IF Risk NOT Low & Age=Middle Then Late Risk MAX(0.8, 0.3) Age 0.9 Membership function: Mean = 0.85 8-39 結束 Fuzzy Model cont. IF Risk NOT Low & Age NOT Middle & Income=High THEN Late Risk MAX(0.8, 0.3) 0.8 Age MAX(0.3, 0.2) 0.3 Income 0.3 Membership function: Mean = 0.433 8-40 結束 Fuzzy Model cont. IF Risk NOT Low & Age NOT Middle & Income NOT High THEN Late Risk MAX(0.8, 0.3) 0.8 Age MAX(0.3, 0.2) 0.3 Income MAX(0.0, 0.8) 0.8 Membership function: Mean = 0.633 8-41 結束 Fuzzy Model cont. Highest membership function is 0.633, for Rule 4 Conclusion: On-time 8-42 結束 Decision Trees Very effective & useful Automatic machine learning Thus unbiased (but omit judgment) Can handle very large data sets Not affected much by missing data Lots of software available 8-43