Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
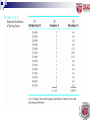
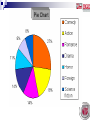
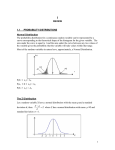
Dapat memahami jenis analisis statistik dalam penyelidikan. Dapat menggunakan jenis statistik yang sesuai dalam penyelidikan pendidikan. Analisis Statistik Data merupakan skor mentah yang tidak memberi sebarang maklumat yang berguna kecuali dianalisis dengan menggunakan kaedah tertentu seperti kaedah berstatistik. Data perlu diproses untuk mendapatkan maklumat yang berguna dan bermakna daripada data. Pemprosesan data merupakan teknik untuk pengumpulan, pengolahan, penganalisisan, penyimpanan dan pengeluaran data. Analisis Statistik Matlamat pemprosesan data ialah untuk mendapatkan maklumat yang berguna dan bermakna daripada data. Analisis statistik berasaskan:Objektif penyelidikan Aras ukuran pembolehubah Maklumat populasi atau sampel Populasi – parameter (keyakinan 100%) Sampel – statistik (keyakinan < 100%) Nominal, Ordinal, Sela, Nisbah Dua jenis statistik: - Statistik keperihalan atau deskriptif Statistik Inferensi atau pentakbiran Perbezaan Statistik Deskriptif dan Inferensi STATISTIK FUNGSI DESKRIPTIF INFERENSI UJIAN Menghuraikan ciri-ciri pemboleh ubah. Ia digunakan untuk membuat kesimpulan mengenai data numerikal. Tidak membuat generalisasi daripada sampel kajian kepada populasi di mana sampel diambil. Frekuensi, min, mod, medium, sela, sisihan piawai, varians, peratusan, kadar, nisbah, taburan normal, skor z dan sebagainya. Menghurai perhubungan antara pemboleh ubah. Menghuraikan ciri-ciri sampel yang dipilih daripada populasi. Membuat generalisasi ciriciri sampel mengenai populasinya. Ujian-t, unjian ANOVA, Ujian Khi-Kuasa Dua, ujian korelasi Pearson dan sebagainya. For example, we use the Greek letter mu (i.e., µ) to symbolize the population mean and the Roman/English letter X with a bar over it, (called X bar), to symbolize the sample mean. Statistik Deskriptif Merupakan statistik yang digunakan untuk menghuraikan ciri-ciri pembolehubah. Statistik deskriptif menggunakan petunjuk seperti min, sisihan piawai, medium, mod, taburan normal dan skor z untuk menyatakan ciri-ciri sesuatu pembolehubah. Matlamat dan Kegunaan untuk meringkaskan data agar ia mudah difahami (menyediakan ringkasan data dan maklumat dalam bentuk yang jelas dan mudah) untuk memerihal sesuatu peristiwa (contoh: memerihal taburan bilangan pelajar mengikut jantina) Teknik untuk menerangkan data atau maklumat dengan cara meringkaskan beberapa set data atau maklumat seperti markah ujian, umur, tempat tinggal, jantina dll. Langkah-Langkah : 1. 2. 3. Mengenal pasti pembolehubah Menyusun dan meringkaskan data Menggunakan teknik-teknik statistik yang sesuai untuk memerihal data (guna sukatan kecenderungan memusat seperti min, mod, penengah dan sukatan serakan seperti julat, varians dan sisihan piawai). PENGUKURAN KECENDERUNGAN MEMUSAT Dilakukan dengan menggunakan satu nilai untuk mewakili satu set data. Measures of central tendency provide descriptive information about the single numerical value that is considered to be the most typical of the values of a quantitative variable. Three common measures of central tendency are the mode, the median, and the mean. Istilah-istilah penting Min atau purata – purata arithmetik dan didapati dengan menjumlahkan skor-skor di dalam taburan skor dan dibahagikan dengan jumlah bilangan skor Mod – skor yang mempunyai kekerapan terbanyak Median atau penengah – skor yang membahagi duakan taburan skor supaya jumlah bilangan skor adalah sama di kedua-dua pihak. Nila yang terletak di tengah-tengah setelah disusun mengikut ranking. Sisihan piawai – pengukuran jarak daripada purata arithmetik Julat – jarak antara skor terbesar dengan terkecil Varian – bagaimana skor-skor diperbezakan daripada purata arithmetik The mode is simply the most frequently occurring number. (e.g., 2.5 is the median for the numbers 1, 2, 3, 7). The median is the center point in a set of numbers The mean is the arithmetic average (e.g., the average of the numbers 2, 3, 3, and 4, is equal to 3). (e.g., three is the median for the numbers 1, 1, 3, 4, 9). Taburan Normal Merupakan satu graf yang menunjukkan bilangan skor atau nilai bagi sekumpulan responden. Kebanyakan populasi adalah bersifat taburan normal (graf berbentuk loceng). Kebanyakan subjek berada dalam lengkungan sederhana. Min Penengah Mod A Comparison of the Mean, Median, and Mode The mean, median, and mode are affected by what is called skewness (i.e., lack of symmetry) in the data. Figure showed a normal curve, a negatively skewed curve, and a positively skewed curve No skew (normal) - a variable is normally distributed, the mean, median, and mode are the same number. When the variable is skewed to the left (i.e., negatively skewed), the mean shifts to the left the most, the median shifts to the left the second most, and the mode the least affected by the presence of skew in the data when the data are negatively skewed, this happens: mean < median < mode. When the variable is skewed to the right (i.e., positively skewed), the mean is shifted to the right the most, the median is shifted to the right the second most, and the mode the least affected. when the data are positively skewed, this happens: mean > median > mode. Measures of variability tell you how "spread out" or how much variability is present in a set of numbers. They tell you how different your numbers tend to be. Note that measures of variability should be reported along with measures of central tendency because they provide very different but complementary and important information. Digunakan untuk menghurai keserakan pembolehubah iaitu sama ada nilai-nilai dalam satu kumpulan data berjauhan atau berdekatan antara satu sama lain. Tiga cara yang biasa digunakan ialah: • Sela • Sisihan piawai • varians Sisihan piawai Petunjuk pengukuran yang utama dalam penyelidikan untuk menyatakan keserakan skor-skor dalam sesuatu taburan. Ia digunakan pada data skala sela dan nisbah. Sisihan piawai menunjukkan jumlah purata sesuatu nilai atau skor individu tersisih daripada skor min dalam sesuatu taburan. Varians Varians juga digunakan untuk mengenal pasti keserakan skor-skor dalam satu taburan. Varians merupakan kuasa dua bagi nilai sisihan piawai. To fully interpret one (e.g., a mean), it is helpful to know about the other (e.g., a standard deviation). An easy way to get the idea of variability is to look at two sets of data, one that is highly variable and one that is not very variable. For example, which of these two sets of numbers appears to be the most spread out, Set A or Set B? • Set A. 93, 96, 98, 99, 99, 99, 100 • Set B. 10, 29, 52, 69, 87, 92, 100 If you said Set B is more spread out, then you are right! The numbers in set B are more "spread out"; that is, they are more variability. All of the measures of variability should give us an indication of the amount of variability in a set of data. We will discuss three indices of variability: the range, the variance, and the standard deviation. Range (Sela/Julat) A relatively crude indicator of variability is the range (i.e., which is the difference between the highest and lowest numbers). Maximum score – Minimum score For example the range in Set A shown above is 7, and the range in Set B shown above is 90. • Set A. 93, 96, 98, 99, 99, 99, 100 • Set B. 10, 29, 52, 69, 87, 92, 100 Variance and Standard Deviation Two commonly used indicators of variability are the variance and the standard deviation. The standard deviation tells you (approximately) how far the numbers tend to vary from the mean. (If the standard deviation is 7, then the numbers tend to be about 7 units from the mean. If the standard deviation is 1500, then the numbers tend to be about 1500 units from the mean.) • Zero stands for no variability at all (e.g., for the data 3, 3, 3, 3, 3, 3, the variance and standard deviation will equal zero). When you have no variability, the numbers are a constant (i.e., the same number). • Higher values for both of these indicators (variance and SD) indicate a larger amount of variability than do lower numbers Contoh Mata Pelajaran Pelajar 1 Pelajar 2 Pelajar 3 KH 54 64 70 BM 62 25 71 BI 86 88 74 Sains 74 72 74 Mat 65 95 72 Sej 82 65 78 PJK 84 98 68 Jumlah 507 507 507 72.42 72.42 72.42 Skor Min Contoh Bil mata pelajaran Minimu m Maksimum Jumlah Skor Min SP Pelajar 1 7 54 86 507 72.42 11.43 Pelajar 2 7 25 98 507 72.42 29.20 Pelajar 3 7 68 78 507 72.42 3.02 Jika dibandingkan nilai sisihan piawai bagi ketiga-tiga pelajar, pelajar 2 mempunyai nilai paling besar iaitu 29.20, diikuti pelajar 1 (11.43) dan pelajar 3 (3.02). Ini bererti taburan skor pelajar 2 adalah terserak lebih jauh daripada nilai skor min dalam taburannya berbanding dengan taburan skor pelajar 1 dan 3. Peratusan Dengan menggunakan peratusan, penyelidik dapat menyatakan peratusan setiap jenis data untuk menyatakan perhubungan antara pembolehubah. Analisis peratusan biasanya dinyatakan bersama dengan nilai frekuensi. Perubahan peratusan Perubahan peratusan biasanya digunakan untuk membandingkan frekuensi dalam peratusan bagi aktiviti yang berlaku dalam satu masa yang tertentu dengan satu masa lain (digunakan dalam kajian longitudinal) Contoh Kes salah laku tahun 2008 dan 2009 Salah laku 2008 2009 Perbezaan % Merokok 16 25 56.25 Kes tumbuk 12 18 50.00 Mengugut 3 5 66.67 Inferential Statistics • Inferential statistics is defined as the branch of statistics that is used to make inferences about the characteristics of a populations based on sample data. • The goal is to go beyond the data at hand and make inferences about population parameters. • In order to use inferential statistics, it is assumed that either random selection or random assignment was carried out (i.e., some form of randomization must is assumed). Inferential Statistics Digunakan untuk membuat generalisasi keputusan kajian yang diperoleh daripada sampel kajian kepada populasi kajian. Dengan data yang dikumpulkan daripada sampel, penyelidik menggunakan statistik inferensi untuk membuat kesimpulan tentang ciri-ciri populasi berdasarkan ciri-ciri sampel. Statistik inferensi menggunakan ujian-ujian berikut bagi menyatakan perhubungan antara dua pembolehubah Bertujuan… Menganalisis maklumat sampel sebagai anggaran kepada maklumat populasi. Menguji sejauh mana maklumat sampel (statistik) diyakini menganggar dengan tepat maklumat populasi (parameter). Ujian Statistik Berkaitan 1. 2. 3. 4. 5. Khi kuasa dua (chi-square) Ujian Korelasi Pearson Analisis pemfaktoran (factor analysis) Ujian-t Analisis varians (ANOVA) Sampling Distributions One of the most important concepts in inferential statistics is that of the sampling distribution. That's because the use of a sampling distributions is what allows us to make "probability" statements in inferential statistics. • A sampling distribution is defined as "The theoretical probability distribution of the values of a statistic that results when all possible random samples of a particular size are drawn from a population." (For simplicity you can view the idea of "all possible samples" as taking a million random samples. That is, just view it as taking a whole lot of samples!) Hypothesis Testing Hypothesis testing is the branch of inferential statistics that is concerned with how well the sample data support a null hypothesis and when the We use hypothesis testing when we expect a relationship to be present; in other words, we usually hope to “nullify” the null hypothesis and tentatively accept the alternative hypothesis null hypothesis can be rejected in favor of the alternative hypothesis. The null hypothesis is usually the prediction that there is no relationship in the population. The alternative hypothesis is the logical opposite of the null hypothesis and says there is a relationship in the population. Note that it is the null hypothesis that is directly tested in hypothesis testing (not the alternative hypothesis). Probability Value The probability value is a number that is obtained from the SPSS computer printout. It is based on your empirical data, and it tells you the probability of your result or a more extreme result when it is assumed that there is no relationship in the population (i.e., when you are assuming that the null hypothesis is true which is what we do in hypothesis testing and in jurisprudence). Significance Level [] Aras Signifikan • Satu darjah yang boleh diterima oleh penyelidik untuk membuat keputusan sama ada menolak atau menerima hipotesis nol. • The significance level is just that point at which you would consider a result to be "rare." You are the one who decides on the significance level to use in your research study. It is the level that you set so that you will know what probability value will be small enough for you to reject the null hypothesis. • The significance level that is usually used in education is .05. • If your probability value is less than or equal to the significance level (e.g., .05) then you will reject the null hypothesis and tentatively accept the alternative hypothesis. If not (i.e., if it is > .05) then you will fail to reject the null. You just compare your probability value with your significance level. Aras Signifikan [] : Satu darjah yang boleh diterima oleh penyelidik untuk membuat keputusan sama ada menolak atau menerima Ho. Digunakan sebagai asas untuk menolak Ho . Merupakan risiko Ralat Jenis I yang penyelidik rela tanggung yakni menolak Ho yang benar atau paras keyakinan penyelidik dalam membuat keputusan menerima atau menolak Ho . contoh: = .05 menunjukkan paras keyakinan .95 / 95% untuk menerima Ho benar. Aras Signifikan [] : • The significance level is just that point at which you would consider a result to be "rare." You are the one who decides on the significance level to use in your research study. It is the level that you set so that you will know what probability value will be small enough for you to reject the null hypothesis. • The significance level that is usually used in education is .05. You may be wondering, when do you actually reject the null hypothesis and make the decision to tentatively accept the alternative hypothesis? • You reject the null hypothesis when the probability of your result assuming a true null is very small. That is, you reject the null when the evidence would be unlikely under the assumption of the null. • In particular, you set a significance level (also called the alpha level) to use in your research study, which is the point at which you would consider a result to be very unlikely. Then, if your probability value is less than or equal to your significance level, you reject the null hypothesis. • It is essential that you understand the difference between the probability value (also called the p-value) and the significance level (also called the alpha level). Aras Signifikan [] : Keputusan berasaskan Aras signifikan: = .01 – sangat benar (ujian makmal) = .05 – lazim digunakan (penyelidikan sains sosial) = .10 – dibenarkan Aras Signifikan [] : If your probability value is less than or equal to the significance level (e.g., .05) then you will reject the null hypothesis and tentatively accept the alternative hypothesis. If not (i.e., if it is > .05) then you will fail to reject the null. You just compare your probability value with your significance level. Aras Signifikan Tidak Perlu Semua subjek dalam populasi adalah dijadikan responden. Prosedur persampelan bukan kebarangkalian digunakan. Parametric Test A statistical test that involves making assumptions about estimates of population characteristics, or parameters. Non Parametric Test A statistical test that does not involves the use of any population parameters, µ and σ are not needed, and underlying distribution does not have to be normal. Non-parametric tests are most often used to analyze ordinal and nominal data are referred to as non-parametric tests. Steps in hypothesis testing… 1. 2. 3. 4. State the null and alternative hypothesis State the significance level before the research study (most educational research use .05 as the significance level, is also called alpha level, or more simply, alpha). Obtain the probability value using a computer program such as SPSS. Compare the probability value to the significance level and make the statistical decision. Rule 1: If Probability value ≤ significance level (i.e. p ≤ α) Then Reject the null hypothesis And Conclude that the research finding is statistically significant Rule 2: If Probability value > significance level (i.e. p > α) Then Fail to reject the null hypothesis And Conclude that the research finding is not statistically significant Ralat Jenis l dan ll Ralat Jenis l Menolak hipotesis nol bila ia harus diterima. Ralat ini timbul apabila penyelidik menolak hipotesis nol yang benar. Penyelidik membuat keputusan bahawa terdapat perbezaan yang signifikan apabila ianya sebenar tidak ada. Ralat Jenis ll Tidak menolak hipotesis nol bila ia sebenarnya harus ditolak. Ralat ini timbul apabila penyelidik membuat keputusan bahawa tiada perbezaan, sedangkan wujud perbezaan. Menentukan paras signifikan () untuk membuat keputusan menerima atau menolak Ho dan sejauh mana kesanggupan penyelidikan menerima risiko rentetan RJ I & RJ II. Aturan Keputusan. Menentukan kawasan penolakan iaitu nilai statistik bertentangan dengan nilai Ho yang mengakibatkan Ho ditolak. Kawasan penolakan bergantung kepada aras signifikan. More explanation.. • When the null hypothesis is true you can make the correct decision (i.e., fail to reject the null) or you can make the incorrect decision (rejecting the true null). The incorrect decision is called a Type I error or a "false positive" because you have erroneously concluded that there is an effect or relationship in the population. • When the null hypothesis is false you can also make the correct decision (i.e., rejecting the false null) or you can make the incorrect decision (failure to reject the false null). The incorrect decision is called a Type II error or a "false negative" because you have erroneously concluded that there is no effect or relationship in the population. Membandingkan frekuensi Khi kuasa dua Ujian bukan parametrik yang banyak digunakan dalam penyelidikan sains sosial, terutamanya dalam kajian yang menggunakan skala Likert sebagai skala pengukuran kajian. Tujuan ujian ini adalah untuk membandingkan frekuensi yang diperhatikan dalam sampel dengan frekuensi yang dijangka yang sepatutnya wujud secara teori. Skala pengukuran nominal atau ordinal dan data yang dikumpul adalah dalam bentuk frekuensi. Khi kuasa dua Persampelan rawak dan populasi dalam taburan normal. Untuk menjawab soalan mengenai data yang wujud dalam bentuk frekuensi. Contoh: Kita ingin mengetahui sama ada wujud perbezaan yang signifikan antara pelajar daripada taraf sosio ekonomi tinggi atau rendah yang melanjutkan pelajaran atau keciciran. Kita memilih sampel daripada dua populasi (SES rendah dan tinggi), tentukan sama ada mereka melanjutkan pelajaran selepas SPM dan gunakan ujian khi kuasa dua. Membandingkan dua atau lebih daripada dua kumpulan data sela atau nisbah Ujian-T Statistik inferensi yang digunakan untuk membandingkan dua atau lebih daripada dua kumpulan data sela atau nisbah. Persampelan rawak. Populasi bertaburan normal. Digunakan untuk menentukan sama ada satu set atau set-set skor adalah berasal daripada populasi yang sama. Ujian-T Ujian-t digunakan dalam kes-kes berikut; Saiz sampel kecil, iaitu 10 subjek dan ke atas. 2. Pembolehubah bersandar diukur dalam skala sela atau nisbah. 3. Kajian dilakukan untuk menentukan sama ada terdapat perbezaan yang signifikan secara statistik antara dua kumpulan data. 1. Ujian-T Tiga jenis ujian-t iaitu; 1. 2. 3. Ujian- t untuk sampel bebas (Independent-Samples T Test) Ujian-t untuk pengukuran berulangan (Paired-Samples T Test) Ujian-t untuk satu sampel (Onesample T Test) Ujian-t Untuk Sampel Bebas Contoh- mengukur kreativiti antara dua kumpulan pelajar iaitu kumpulan Matematik dan Sains. Dua kumpulan pelajar ini adalah berbeza dan berasingan. Ujian-t Untuk Pengukuran Berulangan Digunakan apabila individu dalam sampel diukur dua kali dan kedua-dua data pengukuran digunakan untuk membuat perbandingan. Contoh: untuk melihat perbezaan min terhadap pencapaian markah Matematik sebelum dan selepas mengikuti bengkel motivasi. Ujian-t Untuk Satu Sampel Digunakan untuk membandingkan skor min sampel dengan skor min populasi. Ujian ini digunakan apabila data yang dikumpul memenuhi semua syarat ujian-t, iaitu data sela atau nisbah, taburan populasi normal (biasanya berlaku apabila N sama atau melebihi 50). Contoh; Seorang petani ingin menguji baja jenama baru untuk pokok jagung. Sebanyak 15 pokok jagung dipilih secara rawak daripada ladangnya dan diberikan baja jenama baru. Purata pertumbuhan jagung di ladangnya untuk tempoh dua minggu ialah 45cm. Selepas dua minggu, dia mengukur pertumbuhan 15 pokok jagung yang diberikan baja baru. Ujian-t dilakukan untuk melihat sama ada baja baru itu berkesan atau tidak. Membandingkan lebih daripada dua kumpulan data sela atau nisbah ANOVA ANOVA atau analisis varians digunakan untuk membanding min apabila terdapat lebih daripada dua kumpulan perbandingan. Regression Analysis Regression analysis is a set of statistical procedures used to explain or predict the values of a quantitative dependent variable based on the values of one or more independent variables. • In simple regression, there is one quantitative dependent variable and one independent variable. • In multiple regression, there is one quantitative dependent variable and two or more independent variables. Perhubungan antara pemboleh ubah bersandar dengan pemboleh ubah bebas Ujian Korelasi Pemboleh ubah bebas mengakibatkan kesan kepada pemboleh ubah bersandar. Pemboleh ubah bersandar menerima kesan akibat pemboleh ubah bebas. Perhubungan antara pemboleh ubah ini dinamakan sebagai korelasi. Ujian Korelasi Beberapa jenis pekali ujian korelasi; 1. 2. 3. 4. 5. 6. Pekali Pearson product-moment (atau Pearson) Pekali Phi Pekali Point-biserial Pekali Spearman Rho Pekali Cramer dan Lambda dll Jenis ujian ini bergantung kepada jenis skala pengukuran dan bilangan pembolehubah yang terlibat dalam korelasi. Kekuatan sesuatu korelasi diwakili oleh pekali dalam ujian korelasi. Ujian Korelasi Dua persoalan Apakah persamaan yang mewakili perhubungan antara pemboleh ubah-pemboleh ubah? 2. Apakah kekuatan perhubungan antara pemboleh ubah-pemboleh ubah tersebut? 1. Ujian Korelasi Nilai pekali korelasi (r) ialah nilai pengukuran kekuatan perhubungan antara dua pembolehubah. Nilai r ini mempunyai sela antara +1.00 dan 1.00. Nilai pekali dilaporkan dalam nilai perpuluhan seperti r = .65 atau r = - .41 Ujian Korelasi Pekali korelasi positif Y X Ujian Korelasi Pekali korelasi negatif Y X Ujian Korelasi Contoh: Seorang penyelidik ingin mengetahui perhubungan antara IQ dengan prestasi ujian Matematik. Skor IQ dan prestasi ujian Matematik bagi 10 orang pelajar dikumpulkan dan disenaraikan. Berdasarkan pengiraan, nilai korelasi ialah 0.72. Nilai varians ialah 0.517. Ini bererti bahawa korelasi antara IQ dan prestasi ujian Matematik adalah kuat. 51.7% prestasi ujian matematik disebabkan oleh IQ sementara 48.3% lagi disebabkan oleh faktor lain. link Kekuatan nilai pekali korelasi Saiz pekali korelasi (r) .91 hingga 1.00 atau -.91 hingga -1.00 Kekuatan korelasi Sangat kuat .71 hingga .90 atau -.71 hingga -.90 Kuat .51 hingga .70 atau -.51 hingga -.70 Sederhana .31 hingga .50 atau -.31 hingga -.50 Lemah .01 hingga .30 atau -.01 hingga -.30 Sangat lemah 00 Tiada korelasi Maksud Nilai Pekali Sempurna Nilai pekali 1.00 a perfect positive correlation: changes in one variable are accompanied by equivalent changes in the same direction in the other variable, without exception. Nilai pekali .00 no correlation: changes in one variable have no relationship, or are randomly related, to changes in the other variable. Nilai pekali – 1.00 a perfect negative correlation: changes in one variable are accompanied by equivalent changes in the opposite direction in the other variable, without exception. Graphic Representations of Data Another excellent way to describe your data (especially for visually oriented learners) is to construct graphical representations of the data (i.e., pictorial representations of the data in two-dimensional space). • Some common graphical representations are bar graphs, histograms, line graphs, and scatterplots. Pie Chart Bar Graphs A bar graph uses vertical bars to represent the data. The height of the bars usually represent the frequencies for the categories that sit on the X axis. The X axis is the horizontal axis and the Y axis is the vertical axis. Bar graphs are typically used for categorical variables. Histograms A histogram is a graphic that shows the frequencies and shape that characterize a quantitative variable. Line Graphs A line graph uses one or more lines to depict information about one or more variables. • A simple line graph might be used to show a trend over time Scatterplots A scatterplot is used to depict the relationship between two quantitative variables. • Typically, the independent or predictor variable is represented by the X axis (i.e., on the horizontal axis) and the dependent variable is represented by the Y axis (i.e., on the vertical axis).