Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
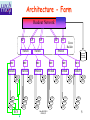
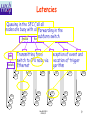
Farm Issues L1&HLT Implementation Review Niko Neufeld, CERN-EP Tuesday, April 29th 1 Overview • Requirements • Architecture • Protocols & Dataflow • Latencies • Implementation Niko NEUFELD CERN, EP 2 Requirements • • • • • • • Scalable up to several thousand CPUs Organised in sub-farms, which perform local load balancing, hide large numbers from RUs Support partitioning (at the subfarm level) Interface to the throttle via Experiment Control System (ECS) Must fit within cooling and space limits in UX8 Low latency for data movement and latency control Allow concurrent, seamless usage for L1 and HLT algorithms, running standard OS, while prioritising L1 traffic wherever possible Niko NEUFELD CERN, EP 3 The Event Filter Farm Level-1 Traffic 125-239 Links 1.1 MHz 8.8-16.9 GB/s Front-end Electronics FE FE FE FE FE FE FE FE FE FE FE FE TRM Switch Switch 77-135 NPs NP NP 77-135 Links 6.4-13.6 GB/s Storage System Readout Network NP NP Level-1 Traffic HLT Traffic Multiplexing Layer L1-Decision 24 NPs Sorter SFC SFC SFC SFC 24 Links 1.5 GB/s TFC System 37-70 NPs Switch 349 Links 40 kHz 2.3 GB/s 30 Switches 73-140 Links 7.9-15.1 GB/s Switch Gb Ethernet NP HLT Traffic NP 50-100 Links 5.5-10 GB/s 50-100 SFCs NP Event Builder Switch SFC SFC Mixed Traffic FarmNiko CPUs ~1200 CPUs NEUFELD CERN, EP 4 Architecture - Farm Readout Network NP NP Switch NP NP Switch NP Event Builder Switch Storage Controller SFC SFC SFC SFC SFC SFC Switch Switch Switch Switch Switch Switch CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU ECS CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU Niko NEUFELD CERN, EP CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU 5 Structure • The (initially) 1200 CPUs are distributed • over several sub-farms To minimise the number of inputs from the event building network, the number of subfarms is chosen such that the average link load into a sub-farm is close to 110 MB/s – For the minimal system (VELO + TT), this yields ~ 50 subfarms – It is also advantageous to minimise the number of sub-farms (while keeping the number of CPUs constant) from the point of view of the local load-balancing (see later) Niko NEUFELD CERN, EP 6 • • • • • Anatomy of a sub-farm Each sub-farm consists of a gateway to the eventbuilder, the Subfarm Controller SFC, and worker CPUs Each subfarm handles an aggregated data-stream of approximately two Gigabits (one in, one out) ( see later) The SFC is connected to the worker CPUs by a switch (Ethernet - Layer 2) A completely separate network connects the SFC and the worker nodes to the ECS The transport protocol is light-weight directly on top of Ethernet (or raw IP if necessary) no TCP Niko NEUFELD CERN, EP 7 • • • • • Dataflow Completely assembled events are sent to the SFC as (several) raw Ethernet frames The SFC keeps a list of idle worker CPU and forwards the event to a node – A node buffers only a single L1 event at anytime (latency!). When no node is free, the event is buffered in the SFC and accumulates extra latency – A node buffers several HLT events (50 to 100). When all buffers are full, events are buffered in the SFC When the high-water marks of the SFC buffer are reached, a throttle signal is issued via the ECS The worker CPU processes the event and always sends an answer (= decision) – In case of a L1 event the answer is only yes or no + a short summary for the L1 sorter – In case of a HLT event the positive answer contains the raw and reconstructed event data as well The SFC forwards L1 decisions to the L1 decision sorter and HLT accepted events to the storage controller Niko NEUFELD CERN, EP 8 Latencies Queuing in the SFC (“all all nodes are busy with a L1 event”) in the Forwarding subfarm switch Switch Switch Switch SFC Switch SFC SFC SFC SFC Transmitting from Reception of eventSFC and switch node viaSwitch invocation of trigger Switchto CPU Switch Switch Switch EthernetCPU algorithm CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU Niko NEUFELD CERN, EP 9 Minimising the Latencies • Transmitting of events (transport time) – use Gigabit Ethernet for the internal subfarm network (although links loaded only to a few %) • Reception of events and invocation of trigger algorithm: – use raw Ethernet/IP and zero-copy sockets, etc… – use real time scheduling, pre-emptive system calls and low context switching latency • Queuing due to statistical fluctuations in the processing time of earlier events – keep number of nodes in the subfarm high keep number of subfarms low Niko NEUFELD CERN, EP 10 Context Switching Latency • What is it? – On a multi-tasking OS, whenever the OS switches from one process to another it needs a certain time to do this • Why do we worry? – Because we run the L1 and the HLT algorithms concurrently on each CPU node • Why do we want this concurrency? – We want to minimise the idle-time of the CPUs – We cannot use double-buffering in the L1 (latency budget would be half-ed!) Niko NEUFELD CERN, EP 11 Scheduling and Latency • • • Using Linux 2.5.55 we have established two facts about the scheduler: – Realtime priorities work: the L1 task will never be interrupted until it finishes – The context switch latency is low: 10.1 ± 0.2 µs Measurements of this have been done on a highend server 2.4 GHz PIV Xeon – 400 MHz FSB – we should have machines at least 2x faster in 2007 Conclusion: the scheme of running both tasks concurrently is sound Niko NEUFELD CERN, EP 12 Latency due to queuing 0.1 % of events have a timeout larger than the 30 ms cut-off Niko NEUFELD CERN, EP Ptolemy simulation: •Processing time distribution from number of clusters •Assuming 9 processors and a shared L1 trigger rate of 9 kHz per subfarm •10^6 L0 accepted events, one of 120 subfarms 13 Beating the statistics of small numbers Only 0.05 % of events have a timeout larger than 30 ms minimise number of sub-farms Niko NEUFELD CERN, EP Subfarm now with 18 nodes and sharing ~ 18 kHz of L1 trigger one of 60 sub farms. Total number of CPUs in the system constant 14 Implementation • • • • SFC is either a high performance (better than 2 Gigabit sustained I/O) PC or a single NP module Farm nodes are disk-less, booted from network, running (most likely) Linux – rack-mounted PCs (1U or blade servers) single or dual CPU The farm will be installed in UX8 – limits in floor/rack space and cooling power Joint studies for rack cooling and physical realisation (optimal cabling, mechanics, etc…) ongoing Niko NEUFELD CERN, EP 15