Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Mass Data Processing Technology on Large Scale
Clusters
Summer, 2007, Tsinghua University
All course material (slides, labs, etc) is licensed under the Creative
Commons Attribution 2.5 License .
Many thanks to Aaron Kimball & Sierra Michels-Slettvet for their
original version
1
Introduction to Distributed Systems
Parallelization & Synchronization
Fundamentals of Networking
Remote Procedure Calls (RPC)
Transaction Processing Systems
2
3
Computer Speedup
Why slow down
here?
Then, How to
improve the
performance?
Moore’s Law: “The density of transistors on a chip doubles every 18 months, for
the same cost” (1965)
Image: Tom’s Hardware
4
Scope of Problems
What can you
do with 1
computer?
What can you
do with 100
computers?
What can you
do with an
entire data
center?
5
Distributed Problems
Rendering multiple
frames of high-quality
animation
Image: DreamWorks Animation
6
Distributed Problems
Simulating several hundred or thousand
characters
Happy Feet © Kingdom Feature Productions; Lord of the Rings © New Line Cinema
7
Distributed Problems
Indexing the web (Google)
Simulating an Internet-sized network for
networking experiments (PlanetLab)
Speeding up content delivery (Akamai)
What is the key attribute that all these examples
have in common?
8
PlanetLab
PlanetLab is a global research network
that supports the development of new
network services.
PlanetLab currently consists of 809 nodes at 401 sites.
9
CDN - Akamai
10
Parallel vs. Distributed
Parallel computing can mean:
Vector processing of data (SIMD)
Multiple CPUs in a single computer
(MIMD)
Distributed computing is multiple
CPUs across many computers (MIMD)
11
A Brief History… 1975-85
Parallel computing was
favored in the early
years
Primarily vector-based
at first
Gradually more threadbased parallelism was
introduced
Cray 2 supercomputer (Wikipedia)
12
A Brief History… 1985-95
“Massively parallel architectures”
start rising in prominence
Message Passing Interface (MPI)
and other libraries developed
Bandwidth was a big problem
13
A Brief History… 1995-Today
Cluster/grid architecture increasingly
dominant
Special node machines eschewed in
favor of COTS technologies
Web-wide cluster software
Companies like Google take this to the
extreme (10,000 node clusters)
14
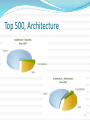
Top 500, Architecture
15
16
Parallelization Idea
Parallelization is “easy” if processing
can be cleanly split into n units:
work
Partition
problem
w1
w2
w3
17
Parallelization Idea (2)
w1
w2
w3
Spawn worker threads:
thread
thread
thread
In a parallel computation, we would like to have as
many threads as we have processors. e.g., a fourprocessor computer would be able to run four
threads at the same time.
18
Parallelization Idea (3)
Workers process data:
thread
w1
thread
w2
thread
w3
19
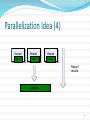
Parallelization Idea (4)
thread
w1
thread
w2
thread
w3
Report
results
results
20
Parallelization Pitfalls
But this model is too simple!
How do we assign work units to worker threads?
What if we have more work units than threads?
How do we aggregate the results at the end?
How do we know all the workers have finished?
What if the work cannot be divided into
completely separate tasks?
What is the common theme of all of these
problems?
21
Parallelization Pitfalls (2)
Each of these problems represents a point at
which multiple threads must communicate
with one another, or access a shared
resource.
Golden rule: Any memory that can be used
by multiple threads must have an associated
synchronization system!
22
What’s Wrong With This?
Thread 1:
void foo() {
x++;
y = x;
}
Thread 2:
void bar() {
y++;
x++;
}
If the initial state is y = 0, x = 6, what happens
after these threads finish running?
23
Multithreaded = Unpredictability
Many things that look like “one step” operations
actually take several steps under the hood:
Thread 1:
void foo() {
eax = mem[x];
inc eax;
mem[x] = eax;
ebx = mem[x];
mem[y] = ebx;
}
Thread 2:
void bar() {
eax = mem[y];
inc eax;
mem[y] = eax;
eax = mem[x];
inc eax;
mem[x] = eax;
}
When we run a multithreaded program, we don’t
know what order threads run in, nor do we know
when they will interrupt one another.
24
Multithreaded = Unpredictability
This applies to more than just integers:
Pulling work units from a queue
Reporting work back to master unit
Telling another thread that it can begin the
“next phase” of processing
… All require synchronization!
25
Synchronization Primitives
A synchronization primitive is a special
shared variable that guarantees that it
can only be accessed atomically.
Hardware support guarantees that
operations on synchronization
primitives only ever take one step
26
Semaphores
Set:
Reset:
A semaphore is a flag
that can be raised or
lowered in one step
Semaphores were flags
that railroad engineers
would use when
entering a shared track
Only one side of the semaphore can ever be red! (Can
both be green?)
27
Semaphores
set() and reset() can be thought of as lock()
and unlock()
Calls to lock() when the semaphore is
already locked cause the thread to block.
Pitfalls: Must “bind” semaphores to
particular objects; must remember to unlock
correctly
28
The “corrected” example
Thread 1:
Thread 2:
void foo() {
sem.lock();
x++;
y = x;
sem.unlock();
}
void bar() {
sem.lock();
y++;
x++;
sem.unlock();
}
Global var “Semaphore sem = new Semaphore();” guards
access to x & y
29
Condition Variables
A condition variable notifies threads that a
particular condition has been met
Inform another thread that a queue now
contains elements to pull from (or that it’s
empty – request more elements!)
Pitfall: What if nobody’s listening?
30
The Final Example
Thread 1:
Thread 2:
void foo() {
sem.lock();
x++;
y = x;
fooDone = true;
sem.unlock();
fooFinishedCV.notify();
}
void bar() {
sem.lock();
if(!fooDone) fooFinishedCV.wait(sem);
y++;
x++;
sem.unlock();
}
Global vars: Semaphore sem = new Semaphore(); ConditionVar
fooFinishedCV = new ConditionVar(); boolean fooDone = false;
31
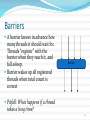
Barriers
A barrier knows in advance how
many threads it should wait for.
Threads “register” with the
barrier when they reach it, and
fall asleep.
Barrier wakes up all registered
threads when total count is
correct
Barrier
Pitfall: What happens if a thread
takes a long time?
32
Too Much Synchronization?
Deadlock
Synchronization becomes even
more complicated when
multiple locks can be used
Can cause entire system to “get
stuck”
Thread A:
semaphore1.lock();
semaphore2.lock();
/* use data guarded by
semaphores */
semaphore1.unlock();
semaphore2.unlock();
Thread B:
semaphore2.lock();
semaphore1.lock();
/* use data guarded by
semaphores */
semaphore1.unlock();
semaphore2.unlock();
(Image: RPI CSCI.4210 Operating Systems notes)
33
The Moral: Be Careful!
Synchronization is hard
Need to consider all possible shared state
Must keep locks organized and use them
consistently and correctly
Knowing there are bugs may be tricky;
fixing them can be even worse!
Keeping shared state to a minimum reduces
total system complexity
34
35
Sockets: The Internet = tubes?
A socket is the basic network interface
Provides a two-way “pipe” abstraction
between two applications
Client creates a socket, and connects to
the server, who receives a socket
representing the other side
36
Ports
Within an IP address, a port is a
sub-address identifying a listening
program
Allows multiple clients to connect
to a server at once
37
Example: Web Server (1/3)
1) Server creates a socket
attached to port 80
80
The server creates a listener socket attached to a specific
port. 80 is the agreed-upon port number for web traffic.
38
Example: Web Server (2/3)
2) Client creates a socket and
connects to host
(anon)
Connect: 66.102.7.99 : 80
80
The client-side socket is still connected to a port, but the
OS chooses a random unused port number
When the client requests a URL (e.g., “www.google.com”),
its OS uses a system called DNS to find its IP address.
39
Example: Web Server (3/3)
3) Server accepts connection,
gets new socket for client
80
(anon)
(anon)
4) Data flows across connected
socket as a “stream”, just like a file
Listener is ready for more incoming connections, while we
process the current connection in parallel
40
Example: Web Server
41
What makes this work?
Underneath the socket layer are several more protocols
Most important are TCP and IP (which are used hand-in-
hand so often, they’re often spoken of as one protocol:
TCP/IP)
IP header
TCP
header
Your data
Even more low-level protocols handle how data is sent over Ethernet
wires, or how bits are sent through the air using 802.11 wireless…
42
IP: The Internet Protocol
Defines the addressing scheme for
computers
Encapsulates internal data in a “packet”
Does not provide reliability
Just includes enough information for the
data to tell routers where to send it
43
TCP: Transmission Control
Protocol
Built on top of IP
Introduces concept of “connection”
Provides reliability and ordering
IP header
TCP
header
Your data
44
Why is This Necessary?
Not actually tube-like “underneath the hood”
Unlike phone system (circuit switched), the
packet switched Internet uses many routes at
once
you
www.google.com
45
Networking Issues
If a party to a socket disconnects, how much
data did they receive?
… Did they crash? Or did a machine in the
middle?
Can someone in the middle
intercept/modify our data?
Traffic congestion makes switch/router
topology important for efficient throughput
46
47
How RPC Doesn’t Work
Regular client-server protocols involve sending
data back and forth according to a shared state
Client:
Server:
HTTP/1.0 index.html GET
200 OK
Length: 2400
(file data)
HTTP/1.0 hello.gif GET
200 OK
Length: 81494
…
48
Remote Procedure Call
RPC servers will call arbitrary functions in dll, exe,
with arguments passed over the network, and return
values back over network
Client:
Server:
foo.dll,bar(4, 10, “hello”)
“returned_string”
foo.dll,baz(42)
err: no such function
…
49
Possible Interfaces
RPC can be used with two basic interfaces:
synchronous and asynchronous
Synchronous RPC is a “remote function call”
– client blocks and waits for return val
Asynchronous RPC is a “remote thread
spawn”
50
Synchronous RPC
client
server
s = RPC(server_name, “foo.dll”,
get_hello, arg, arg, arg…)
RPC dispatcher
time
foo.dll:
String get_hello(a, b, c)
{
…
return “some hello str!”;
}
print(s);
...
51
Asynchronous RPC
client
server
h = Spawn(server_name,
“foo.dll”, long_runner, x, y…)
RPC dispatcher
...
keeps running…)
time
(More code
foo.dll:
String long_runner(x, y)
{
…
return new GiantObject();
}
GiantObject myObj = Sync(h);
52
Asynchronous RPC 2: Callbacks
client
server
h = Spawn(server_name, “foo.dll”,
callback, long_runner, x, y…)
RPC dispatcher
time
(More code
...
Thread spawns:
runs…)
foo.dll:
String long_runner(x, y)
{
…
return new Result();
}
void callback(o)
{
Uses Result
}
53
Wrapper Functions
Writing rpc_call(foo.dll, bar, arg0, arg1..) is
poor form
Confusing code
Breaks abstraction
Wrapper function makes code cleaner
bar(arg0, arg1); //just write this; calls “stub”
54
More Design Considerations
Who can call RPC functions? Anybody?
How do you handle multiple versions
of a function?
Need to marshal objects
How do you handle error conditions?
Numerous protocols: DCOM, CORBA,
JRMI…
55
56
TPS: Definition
A system that handles transactions
coming from several sources
concurrently
Transactions are “events that generate
and modify data stored in an
information system for later retrieval”*
* http://en.wikipedia.org/wiki/Transaction_Processing_System
57
Key Features of TPS: ACID
“ACID” is the acronym for the features a TPS must
support:
Atomicity – A set of changes must all succeed or all
fail
Consistency – Changes to data must leave the data in
a valid state when the full change set is applied
Isolation – The effects of a transaction must not be
visible until the entire transaction is complete
Durability – After a transaction has been committed
successfully, the state change must be permanent.
58
Atomicity & Durability
What happens if we write half of a
transaction to disk and the power
goes out?
59
Logging: The Undo Buffer
Database writes to log the current values
of all cells it is going to overwrite
2. Database overwrites cells with new values
3. Database marks log entry as committed
1.
If db crashes during (2), we use the log to
roll back the tables to prior state
60
Consistency: Data Types
Data entered in databases have rigorous
data types associated with them, and
explicit ranges
Does not protect against all errors (entering
a date in the past is still a valid date, etc),
but eliminates tedious programmer
concerns
61
Consistency: Foreign Keys
Purchase_id
Purchaser_name
Item_purchased FOREIGN
Item_id
Item_name
Cost
Database designers declare that fields are indices
into the keys of another table
Database ensures that target key exists before
allowing value in source field
62
Isolation
Using mutual-exclusion locks, we can
prevent other processes from reading data
we are in the process of writing
When a database is prepared to commit a set
of changes, it locks any records it is going to
update before making the changes
63
Faulty Locking
Locking alone does
not ensure isolation!
Lock (A)
Write to table A
Unlock (A)
time
Lock (B)
Lock (A)
Read from A
Unlock (A)
Write to table B
Changes to table A
are visible before
changes to table B –
this is not an
isolated transaction
Unlock (B)
64
Two-Phase Locking
After a transaction has
released any locks, it may
not acquire any new locks
Lock (B)
Write to table A
Write to table B
Unlock (A)
Unlock (B)
time
Effect: The lock set
owned by a transaction
has a “growing” phase
and a “shrinking” phase
Lock (A)
Lock (A)
Read from A
Unlock (A)
65
Relationship to Distributed
Comp
At the heart of a TPS is usually a large
database server
Several distributed clients may connect to
this server at points in time
Database may be spread across multiple
servers, but must still maintain ACID
66
Conclusions
We’ve seen 3 layers that make up a
distributed system
Designing a large distributed system
involves engineering tradeoffs at each of
these levels
Appreciating subtle concerns at each level
requires diving past the abstractions, but
abstractions are still useful in general
67
Discussion
Distributed System Design
68
Questions and Answers !!!
69