Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Low Pin Count wikipedia , lookup
IEEE 802.1aq wikipedia , lookup
Airborne Networking wikipedia , lookup
Distributed firewall wikipedia , lookup
Zero-configuration networking wikipedia , lookup
Computer network wikipedia , lookup
Recursive InterNetwork Architecture (RINA) wikipedia , lookup
Multiprotocol Label Switching wikipedia , lookup
Asynchronous Transfer Mode wikipedia , lookup
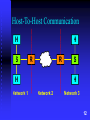
Network tap wikipedia , lookup
Serial digital interface wikipedia , lookup
Point-to-Point Protocol over Ethernet wikipedia , lookup
UniPro protocol stack wikipedia , lookup
Packet switching wikipedia , lookup
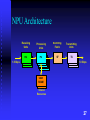
Deep packet inspection wikipedia , lookup
Introduction Linus Svensson D5, [email protected] Åke Östmark D5, [email protected] 1 Why We Are Here The architecture of a Network Processor Unit (NPU) Master’s thesis - a joint operation between Luleå University of Technology and SwitchCore AB 2 Today's Topics Background NPU (Network Processor Unit) Why an NPU? Cons and pros with NPU:s The architecture of our NPU Ethernet and internetworks Switches and routers Design difficulties and design choices The architecture, strengths and weaknesses The big picture From idea to silicon 3 Ethernet Most widespread network technology used in LAN (Local Area Network) 10 Mb/s (Ethernet) 100 Mb/s (Fast Ethernet) 1000 Mb/s (Gigabit Ethernet) Packet switched network Host-to-host delivery on the same network Switches forward packets from one section to another using the datagram paradigm 4 Ethernet Datagram paradigm Packet contains enough information for a switch to forward it correctly I.e. packet contains complete destination address Ethernet packets = frames In Ethernet the packets are referred to as frames 5 Ethernet Frame Format Dest addr Source addr Type Body CRC 8 6 6 2 46-1500 4 Bytes Preamble Preamble 64 bits used for synchronisation Header 48-bit globally unique destination address 48-bit globally unique source address 16-bit type field used for classification 6 Ethernet Frame Format Dest addr Source addr Type Body CRC 8 6 6 2 46-1500 4 Bytes Body Preamble 46-1500 bytes of data CRC 32-bit CRC (Cyclic Redundancy Check) for error detection 7 Internetworks Internetwork Several physical networks combined into one logical internetwork Also called internet (with lowercase “i”) Most famous is the world spanning Internet (with capital “I”) Host-to-host delivery between different networks 8 Internet Protocol (IP) Most widespread protocol used in internetworks Routers forward packets from one network to another using the datagram paradigm 9 IP Packet Format Ver, len etc Source addr Dest addr 12 4 4 Opt Body 0-65515 Bytes 12 bytes of status fields e.g. version, length etc 32-bit globally unique source address 32-bit globally unique destination address Optional fields of variable length Body 10 IP Over Ethernet Preamble Dest addr Source addr Type Ver, len etc Body Source addr Dest addr Opt CRC Body IP packets are encapsulated in Ethernet frames 11 Host-To-Host Communication H S H R R H Network 1 S H Network 2 Network 3 12 Devices SwitchCore A 16-port Gigabit Ethernet Switch-on-a-chip Full 4K VLAN support Includes support of IEEE 802.1p Cisco CXE-2010 1710 Security Access Router Secure Internet, intranet, and extranet access with VPN and firewall Advanced QoS features 13 Features What if we want: Load Balancing distributing client requests across multiple servers Multi-Protocol Label Switching (MPLS) next hop based on a the label 14 Features What if we don’t want QoS Security features The Network Processor Unit (NPU) A programmable CPU chip that is optimized for networking and communications functions Quick adaptation of new standards/features 15 Conditions For the Work 1 GE (1000 Mbit) port 8 FE (100 Mbit) ports Scalable Add more ports Remove ports Feasible to make an ASIC prototype 16 NPU components: Processor Core Embedded software Network Interface Packet buffers Queues Tables Switch fabric 17 Design Choices Processor core RISC based Network specific Network Interface FE MII (Media Independent Interface) RMII (Reduced MII) GE GMII (Gigabit MII) RGMII (Reduced GMII) 18 Design Choices Queues Tables A packet ready for transmission Data structure for IP & MAC addresses Switch fabric The internal interconnect architecture. How to transport from in-port to out-port? 19 Design Choices Packet buffers Internal and/or external How many times do we need to access a (buffer) memory? Write when receive from network Read packet for processing Write modified packet for transmission Reading the packet when transmitting For N ports the memory needs to run at 4N the port speed 20 Design Choices 8 FE ports 1 GE port Inter-arrival time: 1.5*106 + 8*1.55 = 2.7*106 packets/s -> New packet every 370 ns Cycle budget example: 100 MHz -> 37 cycles to process every packet 200 MHz -> 74 cycles to process every packet 21 Design Choices Model of operation Route processing Packet forwarding ~200 cycles Special services Target technology ~150 MHz 22 Design Decisions Parallel Processor Architecture 2 FE ports 125 MHz 1 Integer Unit 1 GE port 125 MHz 5 Integer Units -> Cycle budget of 420 for each packet Interactive voice can tolerate somewhere between 100 and 200 milliseconds of end-to-end delay without people noticing it. 420 cycles -> 0.00336 ms 23 Design Decisions Tables MAC Address lookup, fixed length: CAM (Content Addressable Memory) Pros: Fast Cons: Expensive Like a cache IP Address lookup, longest match: Possibly large table External SRAM 24 Internal packet buffers: Pros: Fast, less pin count Cons: Limited size of memory 2 FE ports / 1 buffer Pros: Reduce contention, reduce 4N problem Cons: Less effective use of memory Input MAC Packet buffer MAC Shared memory Packet buffer MAC Packet buffer MAC 25 Virtual output queues: Pros: Cons: Expensive in hardware Input No Head Of Line (HOL) blocking, Possible to select any packet from buffer memory Virtual Output Queues MAC Packet buffer MAC 1 2 3 4 Output MAC MAC Virtual Output Queues MAC Packet buffer MAC 1 2 3 4 MAC MAC 26 NPU Architecture Receiving Units Processing Units Switching Fabric Transmitting Units RU PU SF TU 1.8 Gbps 1.8 Gbps CAM SRAM Shared Resources 27 3 accesses / 40 cycles (not counting accesses from IU) 8kB SRAM 128 128 (from RU) Frame Engine 420 cycles / min size packet 128 Transmitter 32 (to SF) 1 transmit / 20 cycles (FE) or 1 transmitt / 4 cycles (GE) MIPS IU 32 Shared SRAM I/O 32 CAM I/O 24 Arb MemCtrl MemCtrl (Instr) (Data) 32 32 1kB 1kB SRAM SRAM PU with 1xIU 28 1 accesses / 32 cycles (not counting accesses from IUs) 512 (from RU) 32kB SRAM 512 Frame Engine 420 cycles / min size packet 512 32 (to SF) 1 transmit / 5 cycles Arb Arb MIPS IU Arb Transmitter 32 Shared SRAM I/O 32 CAM I/O 24 Arb MemCtrl MemCtrl (Instr) (Data) 32 32 1kB 1kB SRAM SRAM PU with 5xIU 29 Performance 250 200 Cycles 150 100 50 IP in shared SRAM IP in internal SRAM MAC in shared CAM 0 50 100 Frames 150 200 30 Strengths in the Architecture More bandwidth More RU and TU New types of RU and TU More processing power More PU per RU/TU More IU per PU New types of PU New types of IU 31 Strengths in the Architecture New functionality New types of shared resources Semaphores Multipurpose CPU New software All IU:s can run different software 32 Weaknesses in the Architecture Not everything scales well Shared resources No. of IU:s in a PU 33 From Idea to Silicon Design Specification Design Entry ASIC design flow Postlayout simulation Circuit exctraction VHDL/Verilog Logic Synthesis Transfer to target technology (TSMC 0.18) Floorplanning Arrange blocks on chip Placement Decide location of cells in a block Routing Make connections between cells and blocks Finished 34 Layout ALU : process(alu_RegA, alu_RegB, In_Ctrl_Ex) begin case In_Ctrl_Ex.OP is when ALU_ADD => alu_Result <= alu_RegA + alu_RegB; when ALU_SUB => alu_Result <= alu_RegA - alu_RegB; when ALU_AND => alu_Result <= alu_RegA and alu_RegB; when ALU_OR => alu_Result <= alu_RegA or alu_RegB; when ALU_XOR => alu_Result <= alu_RegA xor alu_RegB; when ALU_NOR => alu_Result <= alu_RegA nor alu_RegB; when others => alu_Result <= (others => '-'); end case; end process; 2.6 x 2.6 mm 35