Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
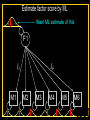
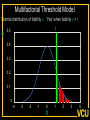
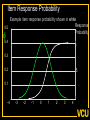
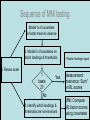
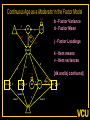
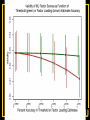
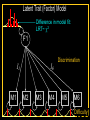
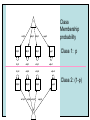
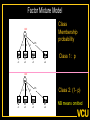
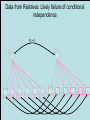
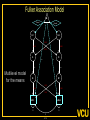
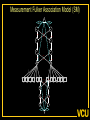
The Measurement and Analysis of Complex Traits Everything you didn’t want to know about measuring behavioral and psychological constructs Leuven Workshop August 2008 Overview • SEM factor model basics • Group differences: - practical • Relative merits of factor scores & sum scores • Test for normal distribution of factor • Alternatives to the factor model • Extensions for multivariate linkage & association Structural Equation Model basics • Two kinds of relationships – Linear regression X -> Y single-headed – Unspecified Covariance X<->Y double-headed • Four kinds of variable – Squares – observed variables – Circles – latent, not observed variables – Triangles – constant (zero variance) for specifying means – Diamonds -- observed variables used as moderators (on paths) Single Factor Model 1.00 F lm l1 l2 l3 S1 S2 S3 Sm e1 e2 e3 e4 Factor Model with Means MF 1.00 1.00 mF2 mF1 F1 F2 lm l1 S1 e1 l2 l3 S2 e2 mS2 mS1 S3 mS3 B8 e3 Sm mSm e4 Factor model essentials • Diagram translates directly to algebraic formulae • Factor typically assumed to be normally distributed: SEM • Error variance is typically assumed to be normal as well • May be applied to binary or ordinal data – Threshold model What is the best way to measure factors? • Use a sum score • Use a factor score • Use neither - model-fit Factor Score Estimation • Formulae for continuous case – Thompson 1951 (Regression method) – C = LL’ + V – f = (I+J)-1L’V-1x – Where J = L’V-1 L Factor Score Estimation • Formulae for continuous case – Bartlett 1938 – C = LL’ + V – fb = J-1L’V-1x – where J = L’V-1 L • Neither is suitable for ordinal data Estimate factor score by ML Want ML estimate of this F1 l1 M1 l6 M2 M3 M4 M5 M6 ML Factor Score Estimation • Marginal approach • • • • L(f&x) = L(f)L(x|f) L(f) = pdf(f) L(x|f) = pdf(x*) x* ~ N(V,Lf) (1) • Maximize (1) with respect to f • Repeat for all subjects in sample – Works for ordinal data too! Multifactorial Threshold Model Normal distribution of liability x. ‘Yes’ when liability x > t t 0.5 0.4 0.3 0.2 0.1 0 -4 -3 -2 -1 0 x 1 2 3 4 Item Response Theory - Factor model equivalence • Normal Ogive IRT Model • Normal Theory Threshold Factor Model • Takane & DeLeeuw (1987 Psychometrika) – Same fit – Can transform parameters from one to the other Item Response Probability Example item response probability shown in white Response 0.5 Probability 0.4 11 0.3 .75 0.2 .5 0.1 .25 .0 -4 -3 -2 -1 0 1 2 3 4 Do groups differ on a measure? • Observed – Function of observed categorical variable (sex) – Function of observed continuous variable (age) • Latent – Function of unobserved variable – Usually categorical – Estimate of class membership probability • Has statistical issues with LRT Practical: Find the Difference(s) 1.00 Variance Mean 1 Mean 1 Factor l1 Item 1 r1 mean1 l2 l3 l1 Item 2 r2 mean2 mean3 1 Factor Item 3 r3 Item 1 r1 mean1 l2 l3 Item 2 r2 mean2 mean3 1 Item 3 r3 Sequence of MNI testing 1. Model fx of covariates on factor mean & variance 2. Model fx of covariates on factor loadings & thresholds * If factor loadings equal 3. Revise scale 1 beats 2? No Yes 2. Identify which loadings & thresholds are non-invariant Measurement invariance: Sum* or ML scores MNI: Compute ML factor scores using covariates Continuous Age as a Moderator in the Factor Model 1.00 b - Factor Variance d - Factor Mean d 1 O5 0.00 L5 b Age j - Factor Loadings 1.00 Factor k - Item means v - Item variances l3 l1 l2 j [dk and bj confound] 1.00 Stims r1 Tranq r2 W5 V Age Z4 mean2 k mean1 1 mean3 MJ r3 What is the best way to measure and model variation in my trait? • Behavioral / Psychological characteristics usually Likert – Might use ipsative? • What if Measurement Invariance does not hold? – How do we judge: • Development • GxE interaction • Sex limitation • Start simple: Finding group differences in mean Simulation Study (MK) • • • • • • Generate True factor score f ~ N(0,1) Generate Item Errors ej ~ N(0,1) Obtain vector of j item scores sj = L*fj + ej Repeat N times to obtain sample Compute sum score Estimate factor score by ML Two measures of performance • Reliability QuickTime™ and a TIFF (LZW) decompressor are needed to see this picture. Two measures of performance • Validity QuickTime™ and a TIFF (LZW) decompressor are needed to see this picture. Simulation parameters • 10 binary item scale • Thresholds – [-1.8 -1.35 -0.9 -0.45 0.0 0.45 0.9 1.35 1.8] • Factor Loadings – [.30 .80 .43 .74 .55 .68 .36 .61 .49] Mess up measurement parameters • Randomly reorder thresholds • Randomly reorder factor loadings • Blend reordered estimates with originals 0% 100% ‘doses’ Measurement non-invariance • Which works better: ML or Sum score? • Three tests: – SEM - Likelihood ratio test difference in latent factor mean – ML Factor score t-test – Sum score t-test MNI figures More Factors: Common Pathway Model More Factors: Independent Pathway Model =1 =1 =1 Independent pathway model is submodel of 3 factor common pathway model Example: Fat MZT MZA Results of fitting twin model ML A, C, E or P Factor Scores • Compute joint likelihood of data and factor scores – p(FS,Items) = p(Items|FS)*p(FS) – works for non-normal FS distribution • Step 1: Estimate parameters of (CP/IP) (Moderated) Factor Model • Step 2: Maximize likelihood of factor scores for each (family’s) vector of observed scores – Plug in estimates from Step 1 Business end of FS script The guts of it ! Residuals only Shell script to FS everyone Central Limit Theorem Additive effects of many small factors 1 Gene 2 Genes 3 Genes 4 Genes 3 Genotypes 3 Phenotypes 9 Genotypes 5 Phenotypes 27 Genotypes 7 Phenotypes 81 Genotypes 9 Phenotypes 3 3 2 2 1 1 0 0 7 6 5 4 3 2 1 0 20 15 10 5 0 Measurement artifacts • Few binary items • Most items rarely endorsed (floor effect) • Most items usually endorsed (ceiling effect) • Items more sensitive at some parts of distribution • Non-linear models of item-trait relationship Assessing the distribution of latent trait • Schmitt et al 2006 MBR method • N-variate binary item data have 2N possible patterns • Normal theory factor model predicts pattern frequencies – E.g., high factor loadings but different thresholds – 0000 – 0001 but 0 0 1 0 would be uncommon – 0011 – 0111 – 1111 1 234 item threshold Latent Trait (Factor) Model F1 Use Gaussian quadrature weights to integrate over factor; then relax constraints on weights l1 M1 l6 M2 M3 M4 Discrimination M5 M6 Difficulty Latent Trait (Factor) Model Difference in model fit: LRT~ 2 F1 l1 M1 l6 M2 M3 M4 Discrimination M5 M6 Difficulty Chi-squared test for non-normality performs well Detecting latent heterogeneity Scatterplot of 2 classes S1 Mean S1|c2 Mean S1|c1 Mean S2|c1 Mean S2|c2 S2 Scatterplot of 2 classes Closer means S1 Mean S1|c2 Mean S1|c1 Mean S2|c1 Mean S2|c2 S2 Scatterplot of 2 classes Latent heterogeneity: Factors or classes? S1 S2 Latent Profile Model Class Membership probability 1 1 m1|c1 m1|c1 m2|c1 m3|c1 m3|c1 m2|c1 mp|c1 mp|c1 S1|c1 S2|c1 S3|c1 Sp|c1 e1|c1 e2|c1 e3|c1 e4|c1 e1|c2 e2|c2 e3|c2 e4|c2 S1|c2 S2|c2 S3|c2 Sp|c2 m1|c2 m2|c2 m3|c2 1 mp|c2 Class 1: p Class 2: (1-p) Factor Mixture Model Class Membership probability 1.00 F l1 l2 lm l3 S1 S2 S3 Sm e1 e2 e3 e4 Class 1: p 1.00 F l1 l2 Class 2: (1- p) lm l3 S1 S2 S3 Sm e1 e2 e3 e4 NB means omitted Classes or Traits? A Simulation Study • Generate data under: – Latent class models – Latent trait models – Factor mixture models • Fit above 3 models to find best-fitting model – Vary number of factors – Vary number of classes • See Lubke & Neale Multiv Behav Res (2007 & In press) What to do about conditional data • Two things – Different base rates of “Stem” item – Different correlation between Stem and “Probe” items • Use data collected from relatives Data from Relatives: Likely failure of conditional independence R>0 F2 F1 l1 STEM l1 l6 P2 P3 P4 P5 P6 STEM l6 P2 P3 P4 P5 P6 Series of bivariate integrals 0.5 0.4 0.3 m/2 t1i t2i Π ( (x , x ) dx dx )j 1 j=1 t1 2 1 -3 -2 -1 0 1 2 3 23 1 -10 -2 -3 2 t2 i-1 i-1 Can work with p-variate integration, best if p<m “Generalized MML” built into Mx Dependence 1 Did your use of it cause you physical problems or make you depressed or very nervous? Consequence: physical & psychological 1 0.9 0.8 0.7 cannabis cocaine stimulants sedatives opioids hallucinogens 0.6 0.5 0.4 0.3 0.2 0.1 0 -4 -3 -2 -1 0 1 2 3 4 Extensions to More Complex Applications • Endophenotypes • Linkage Analysis • Association Analysis Basic Linkage (QTL) Model = p(IBD=2) + .5 p(IBD=1) 1 1 1 1 E1 F1 Q1 e f P1 q Pihat 1 1 1 Q2 F2 E2 q f e P2 Q: QTL Additive Genetic F: Family Environment E: Random Environment 3 estimated parameters: q, f and e Every sibship may have different model Measurement Linkage (QTL) Model = p(IBD=2) + .5 p(IBD=1) 1 1 1 1 E1 F1 Q1 e f Pihat 1 1 1 Q2 F2 E2 q q P1 l6 M6 M5 M4 M2 e P2 l1 M3 f l1 M1 M1 l6 M2 M3 M4 M5 M6 q f e F1 Q 1 1 1 E 1 1 Q: QTL Additive Genetic F: Family Environment E: Random Environment 3 estimated parameters: q, f and e Every sibship may have different model Fulker Association Model M Geno1 Geno2 G1 G2 0.50 0.50 -0.50 0.50 S D m m b Multilevel model for the means w B W 1.00 1.00 -1.00 1.00 LDL1 LDL2 R R C 0.75 Measurement Fulker Association Model (SM) M Geno1 Geno2 G1 G2 0.50 0.50 0.50 0.50 S D m m b w B W 1.00 1.00 1.00 1.00 F1 M1 M1 w 0. 50 b m D m S 0. 50 0. 50 0. 50 G 2 G 1 Gen o2 Gen o1 M M2 B M3 W M4 1. 00 M5 l1 1. 00 1. 00 M6 l1 1. 00 l6 F2 l6 M2 M3 M4 M5 M6 Multivariate Linkage & Association Analyses • Computationally burdensome • Distribution of test statistics questionable • Permutation testing possible – Even heavier burden • Potential to refine both assessment and genetic models • Lots of long & wide datasets on the way – Dense repeated measures EMA – fMRI – Need to improve software! Open source Mx