Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Classification
Today: Basic Problem
Decision Trees
Classification Problem
• Given a database D={t1,t2,…,tn} and a set of
classes C={C1,…,Cm}, the Classification
Problem is to define a mapping f:DgC where
each ti is assigned to one class.
• Actually divides D into equivalence classes.
• Prediction is similar, but may be viewed as
having infinite number of classes.
Classification Ex: Grading
x
<90
>=90
• If x >= 90 then grade =A.
• If 80<=x<90 then grade
x
A
=B.
<80
>=80
• If 70<=x<80 then grade
x
B
=C.
• If 60<=x<70 then grade
<70
>=70
x
=D.
C
• If x<50 then grade =F.
<50
>=60
F
D
Classification Techniques
•
Approach:
1. Create specific model by evaluating
training data (or using domain experts’
knowledge).
2. Apply model developed to new data.
• Classes must be predefined
• Most common techniques use DTs, or are
based on distances or statistical methods.
Defining Classes
Distance Based
Partitioning Based
Issues in Classification
• Missing Data
– Ignore
– Replace with assumed value
• Measuring Performance
– Classification accuracy on test data
– Confusion matrix
– OC Curve
Height Example Data
Name
Kristina
Jim
Maggie
Martha
Stephanie
Bob
Kathy
Dave
Worth
Steven
Debbie
Todd
Kim
Amy
Wynette
Gender
F
M
F
F
F
M
F
M
M
M
F
M
F
F
F
Height
1.6m
2m
1.9m
1.88m
1.7m
1.85m
1.6m
1.7m
2.2m
2.1m
1.8m
1.95m
1.9m
1.8m
1.75m
Output1
Short
Tall
Medium
Medium
Short
Medium
Short
Short
Tall
Tall
Medium
Medium
Medium
Medium
Medium
Output2
Medium
Medium
Tall
Tall
Medium
Medium
Medium
Medium
Tall
Tall
Medium
Medium
Tall
Medium
Medium
Classification Performance
True Positive
False Negative
False Positive
True Negative
Confusion Matrix Example
Using height data example with Output1
correct and Output2 actual assignment
Actual
Membership
Short
Medium
Tall
Assignment
Short
Medium
0
4
0
5
0
1
Tall
0
3
2
Operating Characteristic Curve
Classification Using Decision
Trees
• Partitioning based: Divide search space into
rectangular regions.
• Tuple placed into class based on the region within
which it falls.
• DT approaches differ in how the tree is built: DT
Induction
• Internal nodes associated with attribute and arcs
with values for that attribute.
• Algorithms: ID3, C4.5, CART
Decision Tree
Given:
– D = {t1, …, tn} where ti=<ti1, …, tih>
– Database schema contains {A1, A2, …, Ah}
– Classes C={C1, …., Cm}
Decision or Classification Tree is a tree associated with D such
that
– Each internal node is labeled with attribute, Ai
– Each arc is labeled with predicate which can be applied to
attribute at parent
– Each leaf node is labeled with a class, Cj
DT Induction
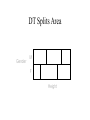
DT Splits Area
Gender
M
F
Height
Comparing DTs
Balanced
Deep
DT Issues
•
•
•
•
•
•
•
Choosing Splitting Attributes
Ordering of Splitting Attributes
Splits
Tree Structure
Stopping Criteria
Training Data
Pruning
Information/Entropy
• Given probabilitites p1, p2, .., ps whose sum is 1,
Entropy is defined as:
• Entropy measures the amount of randomness or
surprise or uncertainty.
• Goal in classification
– no surprise
– entropy = 0
ID3
• Creates tree using information theory concepts and
tries to reduce expected number of comparison..
• ID3 chooses split attribute with the highest
information gain:
ID3
Example
(Output1)
Starting state entropy:
•
4/15 log(15/4) + 8/15 log(15/8) + 3/15 log(15/3) = 0.4384
• Gain using gender:
– Female: 3/9 log(9/3)+6/9 log(9/6)=0.2764
– Male: 1/6 (log 6/1) + 2/6 log(6/2) + 3/6 log(6/3) = 0.4392
– Weighted sum: (9/15)(0.2764) + (6/15)(0.4392) =
0.34152
– Gain: 0.4384 – 0.34152 = 0.09688
• Gain using height:
0.4384 – (2/15)(0.301) = 0.3983
• Choose height as first splitting attribute
•
C4.5
ID3 favors attributes with large number of
divisions
• Improved version of ID3:
–
–
–
–
–
Missing Data
Continuous Data
Pruning
Rules
GainRatio:
CART
• Create Binary Tree
• Uses entropy
• Formula to choose split point, s, for node t:
• PL,PR probability that a tuple in the training set
will be on the left or right side of the tree.
CART Example
• At the start, there are six choices for split
point (right branch on equality):
–
–
–
–
–
–
P(Gender)=2(6/15)(9/15)(2/15 + 4/15 + 3/15)=0.224
P(1.6) = 0
P(1.7) = 2(2/15)(13/15)(0 + 8/15 + 3/15) = 0.169
P(1.8) = 2(5/15)(10/15)(4/15 + 6/15 + 3/15) = 0.385
P(1.9) = 2(9/15)(6/15)(4/15 + 2/15 + 3/15) = 0.256
P(2.0) = 2(12/15)(3/15)(4/15 + 8/15 + 3/15) = 0.32
• Split at 1.8
Problem to Work On:
Training Dataset
This
follows an
example
from
Quinlan’s
ID3
age
<=30
<=30
31…40
>40
>40
>40
31…40
<=30
<=30
>40
<=30
31…40
31…40
>40
income student credit_rating
high
no
fair
high
no
excellent
high
no
fair
medium
no
fair
low
yes fair
low
yes excellent
low
yes excellent
medium
no
fair
low
yes fair
medium
yes fair
medium
yes excellent
medium
no
excellent
high
yes fair
medium
no
excellent
buys_computer
no
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
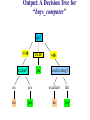
Output: A Decision Tree for
“buys_computer”
age?
<=30
student?
overcast
30..40
yes
>40
credit rating?
no
yes
excellent
fair
no
yes
no
yes
Bayesian Classification: Why?
• Probabilistic learning: Calculate explicit probabilities for
hypothesis, among the most practical approaches to certain types
of learning problems
• Incremental: Each training example can incrementally
increase/decrease the probability that a hypothesis is correct.
Prior knowledge can be combined with observed data.
• Probabilistic prediction: Predict multiple hypotheses, weighted
by their probabilities
• Standard: Even when Bayesian methods are computationally
intractable, they can provide a standard of optimal decision
making against which other methods can be measured
Bayesian Theorem: Basics
• Let X be a data sample whose class label is unknown
• Let H be a hypothesis that X belongs to class C
• For classification problems, determine P(H/X): the
probability that the hypothesis holds given the observed
data sample X
• P(H): prior probability of hypothesis H (i.e. the initial
probability before we observe any data, reflects the
background knowledge)
• P(X): probability that sample data is observed
• P(X|H) : probability of observing the sample X, given that
the hypothesis holds
Bayes Theorem
(Recap)
• Given training data X, posteriori probability of a
hypothesis H, P(H|X) follows the Bayes theorem
P(H | X ) P( X | H )P(H )
P( X )
• MAP (maximum posteriori) hypothesis
h
arg max P(h | D) arg max P(D | h)P(h).
MAP hH
hH
• Practical difficulty: require initial knowledge of
many probabilities, significant computational cost;
insufficient data
Naïve Bayes Classifier
• A simplified assumption: attributes are conditionally
independent:
n
P( X | C i)
P( x k | C i)
k 1
• The product of occurrence of say 2 elements x1 and x2,
given the current class is C, is the product of the
probabilities of each element taken separately, given the
same class P([y1,y2],C) = P(y1,C) * P(y2,C)
• No dependence relation between attributes
• Greatly reduces the computation cost, only count the class
distribution.
• Once the probability P(X|Ci) is known, assign X to the
class with maximum P(X|Ci)*P(Ci)
Training dataset
age
Class:
<=30
C1:buys_computer= <=30
‘yes’
30…40
C2:buys_computer= >40
>40
‘no’
>40
31…40
Data sample
<=30
X =(age<=30,
<=30
Income=medium,
>40
Student=yes
<=30
Credit_rating=
31…40
Fair)
31…40
>40
income student credit_rating
high
no fair
high
no excellent
high
no fair
medium
no fair
low
yes fair
low
yes excellent
low
yes excellent
medium
no fair
low
yes fair
medium
yes fair
medium
yes excellent
medium
no excellent
high
yes fair
medium
no excellent
buys_computer
no
no
yes
yes
yes
no
yes
no
yes
yes
yes
yes
yes
no
Naïve Bayesian Classifier:
Example
Compute P(X/Ci) for each class
P(age=“<30” | buys_computer=“yes”) = 2/9=0.222
P(age=“<30” | buys_computer=“no”) = 3/5 =0.6
P(income=“medium” | buys_computer=“yes”)= 4/9 =0.444
P(income=“medium” | buys_computer=“no”) = 2/5 = 0.4
P(student=“yes” | buys_computer=“yes)= 6/9 =0.667
P(student=“yes” | buys_computer=“no”)= 1/5=0.2
P(credit_rating=“fair” | buys_computer=“yes”)=6/9=0.667
P(credit_rating=“fair” | buys_computer=“no”)=2/5=0.4
X=(age<=30 ,income =medium, student=yes,credit_rating=fair)
P(X|Ci) : P(X|buys_computer=“yes”)= 0.222 x 0.444 x 0.667 x 0.0.667 =0.044
P(X|buys_computer=“no”)= 0.6 x 0.4 x 0.2 x 0.4 =0.019
Multiply by P(Ci)s and we can conclude that
X belongs to class “buys_computer=yes”
Naïve Bayesian Classifier:
Comments
• Advantages :
– Easy to implement
– Good results obtained in most of the cases
• Disadvantages
– Assumption: class conditional independence , therefore loss of accuracy
– Practically, dependencies exist among variables
– E.g., hospitals: patients: Profile: age, family history etc
Symptoms: fever, cough etc., Disease: lung cancer, diabetes etc
– Dependencies among these cannot be modeled by Naïve Bayesian
Classifier
• How to deal with these dependencies?
– Bayesian Belief Networks
Classification Using Distance
• Place items in class to which they are
“closest”.
• Must determine distance between an item
and a class.
• Classes represented by
– Centroid: Central value.
– Medoid: Representative point.
– Individual points
• Algorithm: KNN
K Nearest Neighbor (KNN):
• Training set includes classes.
• Examine K items near item to be classified.
• New item placed in class with the most
number of close items.
• O(q) for each tuple to be classified. (Here q
is the size of the training set.)
KNN
KNN Algorithm