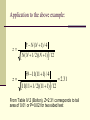Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
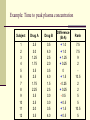
NON-PARAMETRIC STATISTICS Definition Nonparametric satistics, also known as distribution-free statistics, are methods of testing hypotheses when the nature of the distributions are unknown. Some of nonparametric statistics: Sign test, Wilcoxon signed rank test, Wilcoxon rank sum test, Kruskal-Wallis test, Friedman test, Rank correlation Sign Test Sign test is probably the simplest of the nonparametric tests. This test is used for paired data. Step of analysis: - Evaluate the difference between each paired data and take the sign (positive or negative) - Calculate the number of positive signs and negative signs - Take the larger number of sign and compare to the corresponding table (Bolton: Table IV.12). - If the calculated number (larger number) is greater than the critical number in the table, then the difference between two means is significant. Example: Time to peak plasma concentration Subject Drug A Drug B Difference (B-A) Rank 1 2 3 4 5 6 7 8 9 10 11 12 2.5 3.0 1.25 1.75 3.5 2.5 1.75 2.25 3.5 2.5 2.0 3.5 3.5 4.0 2.5 2.0 3.5 4.0 1.5 2.5 3.0 3.0 3.5 4.0 + 1.0 + 1.0 + 1.25 + 0.25 0 + 1.5 - 0.25 + 0.25 - 0.5 + 0.5 + 1.5 + 0.5 7.5 7.5 9 2 10.5 2 2 5 5 10.5 5 Evaluation Number of positive signs: 9 Number of negative sign: 2 No difference: 1 New sample size: 11 Critical value: 10 for 5% level and 11 for 1% level Conclusion: No significant difference Wilcoxon Signed Rank Test In Wilcoxon sign rank test, the magnitude of difference is taken into consideration The differences are then ranked in order of magnitude, disregarding the sign Differences of equal magnitude are given average rank The signs corresponding to the signs of the original differences are reassigned to the ranks Ranks of the same sign are summed Take smaller sum Compared to critical value in corresponding Table (Bolton, Table IV.13) If the smaller rank sum is less than the critical value, then the mean difference is significant. For larger sample size, normal approximation is available to compare two population means using the Wilcoxon signed rank test: z R N ( N 1) / 4 N ( N 1/ 2)( N 1) /12 Application to the above example: z z R N ( N 1) / 4 N ( N 1/ 2)( N 1) /12 59 11(11 1) / 4 11(11 1/ 2)(11 1) /12 2.31 From Table IV.2 (Bolton), Z=2.31 corresponds to tail area of 0.01 or P=0.02 for two sided test Wilcoxon Rank Sum Test (test for differences between two independent groups) In WRST, data are ranked in order of magnitude Ranks of each group are summed For moderate sample size, the statistical test for equality of the distribution means may be approximated using the normal distribution (calculation of z value). This approximation works well if the smaller sample size is equal to or greater than 10. For samples less than size 10, refer to Table IV.16 (Bolton). Calculation of z for WRST z T N1 ( N1 N2 1) / 2 N1 N 2 ( N1 N2 1) /12 T is the sum of ranks for the smaller sample size, N1 is the smaller sample size, N2 is the larger sample size. If z is greater than or equal to 1.96, the twotreatments can be said to be significantly different at the 5% level (two-sided test) Example: Calculation of z 105.5 11(11 12 1) / 2 26.5 z 1.63 (11)(12)(11 12 1) /12 16.25 From Table of cummulative area for normal distribution, value (Table IV.2 Bolton), z=1.63 corresponds to tail area of about 0.052 or P=0.104 (two-sided test). Therefore, these data do not provide sufficient evidence to show that the two different peices of apparatus give different dissolution results (for 5% significance level). The Friedman test is a non-parametric statistical test developed by the U.S. economist Milton Friedman. Similar to the parametric repeated measures ANOVA, it is used to detect differences in treatments across multiple test attempts. The procedure involves ranking each row (or block) together, then considering the values of ranks by columns. Applicable to complete block designs, it is thus a special case of the Durbin test. The Friedman test is used for two-way repeated measures analysis of variance by ranks. In its use of ranks it is similar to the Kruskal-Wallis one-way analysis of variance by ranks. 1. Given data , that is, a tableau with n rows (the blocks), k columns (the treatments) and a single observation at the intersection of each block and treatment, calculate the ranks within each block. If there are tied values, assign to each tied value the average of the ranks that would have been assigned without ties. Replace the data with a new tableau where the entry rij is the rank of xij within block i. The test statistic is given by . Note that the value of Q as computed above does not need to be adjusted for tied values in the data. Finally, when n or k is large (i.e. n > 15 or k > 4), the probability distribution of Q can be approximated by that of a chi-square distribution. In this case the p-value is given by . If n or k is small, the approximation to chi-square becomes poor and the p-value should be obtained from tables of Q specially prepared for the Friedman test. If the p-value is significant, appropriate post-hoc multiple comparisons tests would be performed. In statistics, the Kruskal-Wallis one-way analysis of variance by ranks (named after William Kruskal and W. Allen Wallis) is a non-parametric method for testing equality of population medians among groups. Intuitively, it is identical to a one-way analysis of variance with the data replaced by their ranks. It is an extension of the Mann-Whitney U test to 3 or more groups. Since it is a non-parametric method, the KruskalWallis test does not assume a normal population, unlike the analogous one-way analysis of variance. However, the test does assume an identically-shaped distribution for each group, except for any difference in medians. 1. Rank all data from all groups together; i.e., rank the data from 1 to N ignoring group membership. Assign any tied values the average of the ranks they would have received had they not been tied. 2. The test statistic is given by: ni is the number of observations in group i rij is the rank (among all observations) of observation j from group i N is the total number of observations across all groups 3. A correction for ties can be made by dividing K by where G is the number of groupings of different tied ranks, and ti is the number of tied values within group i that are tied at a particular value. This correction usually makes little difference in the value of K unless there are a large number of ties. Finally, the p-value is approximated by If some ni's are small (i.e., less than 5) the probability distribution of K can be quite different from this chi-square distribution. If a table of the chi-square probability distribution is available, the critical value of chi-square, can be found by entering the table at g − 1 degrees of freedom and looking under the desired significance or alpha level. The null hypothesis of equal population medians would then be rejected if Appropriate multiple comparisons would then be performed on the group medians.