Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
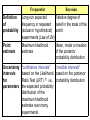
Spatially structured random effects by Daniel A. Griffith Ashbel Smith Professor of Geospatial Information Sciences ABSTRACT Researchers increasingly are employing random effects modeling to analyze data. When data are georeferenced, a random effect term needs to be spatially structured in order to account for spatial autocorrelation. Spatial structuring can be achieved in various ways, including the use of semivariogram, spatial autoregressive, and spatial filter models. SAS implements the semivariogram option for linear mixed models. GeoBUGS implements the spatial autoregressive option for either linear or generalized linear mixed modeling. Recently developed spatial filtering methodology can be used in either case, as well as with the SAS generalized linear mix model procedure, and furnishes one means of estimating space-time mixed models. This presentation summarizes comparisons of these three forms of spatial structuring, illustrating implementations with selected ecological data for the municipalities of Puerto Rico. From Legendre Spatial structures in communities indicate that some process hasbeen at work to create them. Two families of mechanisms cangenerate spatial structures in communities: • Autocorrelation model: the spatial structures are generated by thespecies assemblage themselves (response variables). • Induced spatial dependence model: forcing (explanatory) variablesare responsible for the spatial structures found in the speciesassemblage. They represent environmental or biotic control of thespecies assemblages, or historical dynamics To understand the mechanisms that generate these structures, we needto explicitly incorporate the spatial community structures, at all scales, into the statistical model. Spatial autocorrelation (SA) is technically defined as the dependence, due to geographic proximity, present in the residuals of a [regression-type] model of a response variable y whicht akes into account all deterministic effects due to forcing variables. Spatial autocorrelation can be interpreted in different ways As a spatial process mechanism – the cartoon As a diagnostic tool – the Cliff-Ord Eire example (the model specification should be nonlinear) As a nuisance parameter – eliminating spatial dependency to avoid statistical complications As a spatial spillover effect – georeferencing of pediatric lead poisoning cases in Syracuse, NY As an outcome of areal unit demarcation – the modifiable areal unit problem (MAUP) As redundant information – spatial sampling; map interpolation As map pattern – spatial filtering (to be discussed in this course) As a missing variables indicator/surrogate – a possible implication of spatial filtering As self-correlation – what is discussed next The magic box is a physical model of spatial autocorrelation The permutation perspective The SASIM game http://www.nku.edu/~longa/cgi-bin/cgi-tcl-examples/generic/SA/SA.cgi Measures of spatial autocorrelation MC: Moran Coefficient; GR: Geary Ratio; semivariogram n MC (y n n ij j y) (y i y) 2 i 1 i 1 j1 c ij (y i y j ) 2 i 1 j1 n n c ij i 1 γ(d k ) nk (y i y j ) i 1 n n -1 2 c (y j1 c ij n n y) n i 1 j1 GR i i 1 n n (y i y) 2 2*n k 2 f( d k ), k 1,2,..., K Spherical Exponential Bessel function (1st order, 2nd kind) Georeferenced data scatterplots • The horizontal axis is the measurement scale for some attribute variable • The vertical axis is the measurement scale for neighboring values (topological distance-based) of the same attribute variable OR • The horizontal axis is (usually) Euclidean distance between geocoded locations • The vertical axis is the measurement scale for geographic variability Describing a scatterplot trend positive relationship: High Y with High X & Medium Y with Medium X & Low Y with Low X negative relationship: High Y with Low X & Medium Y with Medium X & Low Y with High X Description of the Moran scatterplot Positive spatial autocorrelation 2002 population - high values tend to be density surrounded by nearby high values - intermediate values tend to be surrounded by nearby intermediate values - low values tend to be surrounded by nearby low values MC = 0.49 GR = 0.58 Description of the Moran scatterplot Negative spatial autocorrelation competition for space - high values tend to be surrounded by nearby low values - intermediate values tend to be surrounded by nearby intermediate values - low values tend to be surrounded by nearby high values MC = -0.16 sMC = 0.075 GR = 1.04 Graphical portrayals of spatial autocorrelation latent in transformed As data Constructing eigenfunctions for filtering spatial autocorrelation out of georeferenced variables: Moran Coefficient = (n/1T C1)x YT(I – 11T/n)C (I – 11T/n)Y/ YT(I – 11T/n)Y the eigenfunctions come from (I – 11T/n)C (I – 11T/n) Random effects model Y f( Xβ ξ, ε) ξ is a random observation effect (differences among individual observational units) ε is a time-varying residual error (links to change over time) The composite error term is the sum of the two. Random effects model: normally distributed intercept term • ξ ~ N(0, σ ) and uncorrelated with covariates • supports inference beyond the nonrandom sample analyzed • simplest is where intercept is allowed to vary across areal units (repeated observations are individual time series) • The random effect variable is integrated out (with numerical methods) of the likelihood fcn • accounts for missing variables & within unit correlation (commonality across time periods) 2 Spatial structuring of random effects • CAR: conditional autoregressive model • ICAR: improper conditional autoregressive model (spatial autocorrelation set to 1,and a spatially structured and a spatially unstructured variance component is estimated)─should be specified as a convolution prior (spatially structured & unstructured random effects) • SF: spatial filter identified with a frequentist GLM Frequentist Bayesian Definition of probability Long-run expected Relative degree of frequency in repeated belief in the state of the (actual or hypothetical) world experiments (Law of LN) Point estimate Maximum likelihood estimate Uncertainty intervals for parameters “confidence intervals” “credible intervals” based on the Likelihood based on the posterior Ratio Test (LRT) i.e., probability distribution the expected probability distribution of the maximum likelihood estimate over many experiments Mean, mode or median of the posterior probability distribution Uncertainty intervals of nonparameters Based on likelihood profile/LRT, or by resampling from the sampling distribution of the parameter Calculated directly from the distribution of parameters Model selection Discard terms that are not significantly different from a nested (null) model at a previously set confidence level Retain terms in models, on the argument that processes are not absent simply because they are not statistically significant Difficulties Confidence intervals are Subjectivity; need to confusing (range that will specify priors contain the true value in a proportion α of repeated experiments); rejection of model terms for “nonsignificance” Impact of sample size •prior •distribution As the sample size increases, a prior distribution has less and less impact on results; BUT •likelihood •distribution •effective •sample size •for spatially •autocorrelated •data What is BUGS? Bayesian inference Using Gibbs Sampling • is a piece of computer software for the Bayesian analysis of complex statistical models using Markov chain Monte Carlo (MCMC) methods. • It grew from a statistical research project at the MRC BIOSTATISTICAL UNIT in Cambridge, but now is developed jointly with the Imperial College School of Medicine at St Mary’s, London. •Classic BUGS •BUGS •WinBUGS (Windows Version) • GeoBUGS (spatial models) • PKBUGS (pharmokinetic modeling) • The Classic BUGS program uses textbased model description and a commandline interface, and versions are available for major computer platforms (e.g., Sparc, Dos). However, it is not being further developed. What is WinBUGS? • WinBUGS, a windows program with an option of a graphical user interface, the standard ‘pointand-click’ windows interface, and on-line monitoring and convergence diagnostics. It also supports Batch-mode running (version 1.4). • GeoBUGS, an add-on to WinBUGS that fits spatial models and produces a range of maps as output. • PKBUGS, an efficient and user-friendly interface for specifying complex population pharmacokinetic and pharmacodynamic (PK/PD) models within the WinBUGS software. What is GeoBUGS? • Available via http://www.mrc-bsu.cam.ac.uk/ bugs/winbugs/geobugs.shtml • Bayesian inference is used to spatially smooth the standardized incidence ratios using Markov chain Monte Carlo (MCMC) methods. GeoBUGS implements models for data that are collected within discrete regions (not at the individual level), and smoothing is done based on Markov random field models for the neighborhood structure of the regions relative to each other. What is MCMC? MCMC is used to simulate from some distribution p known only up to a constant factor, C: pi = Cqi where qi is known but C is unknown and too horrible to calculate. MCMC begins with conditional (marginal) distributions, and MCMC sampling outputs a sample of parameters drawn from their posterior (joint) distribution. The geographic distribution of elevation across the island of Puerto Rico From a USGS DEM containing 87,358,136 points. Darkness of gray scale is directly proportional to elevation. SAS PROC MIXED summary results for a quadratic gradient LMM: LN( elev + 17.5) Semivariogram model none spherical exponential Gaussian power Bessel --- 0.0331 0.2151 0.2210 0.2514 0.2450 Variance (nugget) Spatial correlation Residual b0 --- < 0.0001 0.7643 0.5730 0.2702 0.6089 0.217 6.080*** 0.169 6.080*** < 0.0001 6.157*** 0.0253 6.201*** < 0.0001 6.157*** 0.0057 6.202*** bu2 -0.349*** -0.349*** -0.463*** -0.486*** -0.463*** -0.486*** buv -0.263*** -0.263*** -0.254** -0.255** -0.254** -0.257** bv -0.270*** -0.270*** -0.114 -0.168 -0.114 -0.168 bv2 -0.527*** -0.527*** -0.529*** -0.561*** -0.529*** -0.569*** The average random effects term example MCMC chain from a WinBUGS run ICAR spatial filter (SF) WinBUGS: geographic distributions of unstructured (left) and spatially structured (right) random effects spatial filter (SF) WinBUGS: ICAR Comparative parameter estimates for a LMM quadratic gradient description of LN( elev + 17.5) Param- SAS semivariogram eter (Bessel) model estimate b0 bu2 buv bv2 var varure varssre 6.1906 -0.5048 -0.2229 -0.5314 0.0055 0.2856 0.7205 se SAS SF estimate se 0.287 6.1101 0.055 0.122 -0.3881 0.031 0.123 -0.2939 0.030 0.125 -0.5193 0.032 0.019 0 --0.091 0.0001 --0.221 0.0282 --- GeoBUGS-ICAR WinBUGS-SF (100 weeded replications) estimate se estimate se 6.5175 -0.7507 -0.2031 -0.5683 0.0049 0.0047 0.4854 0.168 6.1101 0.061 0.153 -0.3878 0.035 0.101 -0.2920 0.030 0.061 -0.5190 0.037 0.007 0.0305 0.024 0.007 0.0318 0.025 0.093 0.0301 --- varure denotes the variance of the unstructured random effects varssre denotes the variance of the spatially structured random effects binomial GLMM random effects SAS SF WinBUGS SF WinBUGS ICAR SF GLMM statistic b0 belevelev b E1 b E4 μ̂ ξ σ̂ ξ2 σ̂ ξ2SS P(S-W) MCss GRss MC ξ̂ GR ξ̂ MC ξ̂ SS GR ξ̂ SS r ξ̂,elev r ξ̂,E 1 r ξ̂,E 4 SAS NLMIXED (SF) estimate se WinBUGS (100 weeded replications) SF ICAR estimate se estimate se -1.2867 -0.0111 3.0646 3.2182 0.0015 0.7045 0.9787 <0.0001 0.967 0.158 0.119 1.045 0.356 0.739 0.001 -0.001 0.001 -1.3114 -0.0110 3.0600 3.0116 0.0054 0.7144 0.9783 < 0.0001 0.975 0.154 0.132 1.000 0.357 0.739 0.001 -0.009 0.022 0.2624 0.0013 1.1559 1.3433 0.2852 0.0014 1.3632 1.4256 -1.5340 -0.0100 *** *** 0.0066 0.3727 0.9583 < 0.0001 0.787 0.177 0.036 1.129 0.388 0.696 0.011 *** *** 0.2419 0.0013 Graphical diagnostics of residuals for the GLMM estimated with SAS Scatterplot of the SAS and mean WinBUGS estimated spatially structured random effects terms Individual GLMM estimation results for each Puerto Rican sugar cane crop year Crop year Individ- Raw perual SF centages eigenvector MC GR #s Point-in-time estimation # 0s -a -belevelev μ̂ ξ σ̂ ξ2 P(SW) 1965/ 0.484 0.458 3 1.1959 0.0064 0.0020 1.0135 0.0055 66 1966/ 1,4,6,24 0.490 0.454 4 1.3786 0.0060 0.0021 1.1138 0.0027 67 1967/ 0.474 0.434 6 1.7354 0.0050 0.0018 1.0856 0.0017 68 Space-time data: preliminaries random effect (re) re + ss: 1966/67 re + ss: 1965/66 re + ss: 1967/68 Random effects term is constant across time; spatial structuring changes over time Space-time GLMM: Puerto Rican sugar cane crop years 1965/66-1967/68 when all fixed effects are year-specific crop year 1965/66 statistic b0 belevelev b E1 b E4 b E6 b E24 pseudo-R2 MC ξ̂ SS GR ξ̂ SS MCresiduals GRresiduals estimate se -1.2291 0.2336 -0.0065 0.0009 4.5040 1.1684 4.9713 1.2432 -4.5091 1.1620 -4.0290 1.0994 0.9950 0.449 0.580 0.019 0.916 crop year 1966/7 estimate se -1.3122 0.2336 -0.0064 0.0009 4.5785 1.1684 5.3372 1.2432 -4.8209 1.1620 -3.9657 1.0994 0.9976 0.467 0.562 0.042 0.839 crop year 1967/68 estimate se -1.4520 0.2336 -0.0065 0.0009 4.9226 1.1684 5.8053 1.2432 -5.0203 1.1621 -4.0285 1.0995 0.9929 0.493 0.537 0.009 0.808 Discussion & Implications 1. All three common specifications of spatial structuring—semivariogram, spatial autoregressive and SF models—for a random effect term in mixed statistical models perform in an equivalent fashion. 2. Matching Bayesian model priors with their implicit frequentist counterparts yields estimation results from both approaches that are essentially the same. 3. making use of spatially structured random effects tends to furnish an alternative to quasilikelihood estimation techniques for GLMMs 4. Semivariogram models offer a geostatistical theoretical basis and have been implemented in SAS for LMMs. • A spatial statistics practitioner with the necessary computer programming skills can employ WinBUGS in order to utilize them with GLMMs. 5. Spatial autoregressive modeling offers a theoretical basis for spatial structuring, and is available in GeoBUGS. • This would be very difficult to trick SAS into doing. 6. Spatial filtering, which can be derived from spatial autoregressive model specifications, • • • tends to be more exploratory in nature (being akin to principal components analysis) can be implemented in either SAS or WinBUGS for either LMMs or GLMMs, and can be easily extended to space-time datasets with either of these software packages. 7. Illustrative Puerto Rico sugar cane examples tend to have a random effect term that virtually equates to the corresponding LMM/GLMM residual variate. • This is not always the case, as is highlighted by the extension of a GLMM specification to a space-time sugar cane dataset. 8. All of the estimated random effects terms for the various Puerto Rico examples tend to be non-normal. 9. once a random effect term has been estimated with a frequentist approach, using it when calculating a deviance statistic allows its number of degrees of freedom to be approximated for GLMMs. • Although n values are estimated, because they are correlated, the resulting number of degrees of freedom is less than n. • This particular finding should help spatial statistics practitioners better understand the cost of employing a statistical mixed model. A df aside: future research • Spiegelhalter et al. (2002) address the df problem for complex hierarchical models in which the number of parameters is not clearly defined because, for instance, of the presence of random effects. • An information-theoretic argument is used to approximate the effective number of parameters in a model, equivalent to the trace of the product of the Fisher information and the posterior covariance matrices. – this particular approximation is equivalent to the trace of the ‘hat’ matrix for linear models with a normally distributed error term. k dfs for random effects deviance binomial k n (p 1) 1 deviance Poisson k n (p 1) deviance neativebinomial