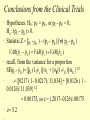Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Lecture Ten
1
Where Do We Go From Here?
Contingency Tables
Regression
Properties
Assumptions
Violations
Diagnostics
Modeling
P Probability
r
o
b
Count
ANOVA
2
Lecture
• Part I: Regression
–
–
–
–
properties of OLS estimators
assumptions of OLS
pathologies of OLS
diagnostics for OLS
• Part II: Experimental Method
3
Properties of OLS Estimators
• Unbiased:
E (bˆ) b
• Note: y(i) = a + b*x(i) + e(i)
• And summing over observations i and dividing by n:
y a b* x e
so, subtracting , y (i ) y b *[ x(i ) x ] [e(i ) e ]
• Recall, the estimator for the slope is:
n
n
i 1
i 1
bˆ [ y (i ) y ][ x(i ) x ] [ x(i ) x ]2
4
• And substituting in this expression for the estimator, the
expression for
y (i ) y
n
n
i 1
i 1
bˆ {b * [ x(i ) x ] [e(i ) e ]} * [ x(i ) x ] [ x(i ) x ]2
n
n
i 1
i 1
bˆ b [e(i ) e ][ x(i ) x ] [ x(i ) x ]2
• And taking expectations
E (bˆ) b
n
n
• Note: bˆ E (bˆ) bˆ b
[ x(i ) x ][e(i ) e ] [ x(i ) x ]2
i 1
•
i 1
2 2
ˆ
ˆ
ˆ
VAR(b) E[b E (b)] E{ [ x(i ) x ][e(i ) e ] [ x(i ) x ] }
n
n
i 1
i 1
2
5
• So
n
VAR(bˆ) [ x(i ) x ]2
2
i 1
• The dispersion in the estimate for the slope
depends upon unexplained variance, and
inversely on the dispersion in x.
• the estimate, the unexplained mean square,
is used for the variance of e.
6
Other Properties of Estimators
• Efficiency: makes optimum use of the
sample information to obtain estimators
with minimum dispersion
• Consistency: As the sample size increases
the estimator approaches the population
parameter
7
Outline: Regression
• The Assumptions of Least Squares
• The Pathologies of Least Squares
• Diagnostics for Least Squares
8
Assumptions
• Expected value of the error is zero, E[e]= 0
• The error is independent of the explanatory
variable, E{e [x-Ex]}=0
• The errors are independent of one another,
E[e(i)e(j)] = 0 , i not equal to j.
• The variance is homoskedatic, E[e(i)]2=E[e(j)]2
• The error is normal with mean zero and
2
variance sigma squared,
18.4 Error Variable: Required
Conditions
• The error e is a critical part of the regression
model.
• Four requirements involving the distribution of
e must be satisfied.
–
–
–
–
The probability distribution of e is normal.
The mean of e is zero: E(e) = 0.
The standard deviation of e is e for all values of x.
The set of errors associated with different values of
y are all independent.
10
The Normality of e
E(y|x3)
The standard deviation remains constant,
m3
b0 + b1x3
E(y|x2)
b0 + b1x2
m2
but the mean value changes with x
b0 + b1x1
E(y|x1)
m1
From the first three assumptions we have:
x1
y is normally distributed with mean
E(y) = b0 + b1x, and a constant standard
deviation e
x2
x3
Pathologies
• Cross section data: error variance is
heteroskedatic. Example, could vary with
firm size. Consequence, all the information
available is not used efficiently, and better
estimates of the standard error of regression
parameters is possible.
• Time series data: errors are serially
correlated, i.e auto-correlated.
Consequence, inefficiency.
12
Lab 6: Autocorrelation?
13
Lab Six: Durbin-Watson Statistic
14
15
Genr: Error = resid
Genr: errorlag1=resid(-1)
Error (t) = a +b *error(t-1) + e(t)
16
Pathologies ( Cont. )
• Explanatory variable is not independent of
the error. Consequence, inconsistency, i.e.
larger sample sizes do not lead to lower
standard errors for the parameters, and the
parameter estimates (slope etc.) are biased.
• The error is not distributed normally.
Example, there may be fat tails.
Consequence, use of the normal may
underestimate true 95 % confidence
intervals.
17
Pathologies (Cont.)
• Multicollinearity: The independent
variables may be highly correlated. As a
consequence, they do not truly represent
separate causal factors, but instead a
common causal factor.
18
View/open selected/one window/one group
In Group Window: View/ correlations
View/open selected/one window/one group
In Group Window: View/Multiple Graphs/Scatter/
Matrix of all pairs
19
20
Price = a +b*bedrooms+c*house_size01 + d*lot_sixe01+e
21
22
23
Price = a*dummy2 +b*dummy34 +c*dummy5 +d*house_size01 +e
24
18.9 Regression Diagnostics - I
• The three conditions required for the
validity of the regression analysis are:
– the error variable is normally distributed.
– the error variance is constant for all values of x.
– The errors are independent of each other.
• How can we diagnose violations of these
conditions?
25
Residual Analysis
• Examining the residuals (or standardized
residuals), help detect violations of the
required conditions.
• Example 18.2 – continued:
– Nonnormality.
• Use Excel to obtain the standardized residual
histogram.
• Examine the histogram and look for a bell shaped.
diagram with a mean close to zero.
26
Diagnostics ( Cont. )
• Multicollinearity may be suspected if the tstatistics for the coefficients of the
explanatory variables are not significant but
the coefficient of determination is high. The
correlation between the explanatory
variable can then be calculated. To see if it
is high.
27
Diagnostics
• Is the error normal? Using EViews, with the
view menu in the regression window, a
histogram of the distribution of the
estimated error is available, along with the
coefficients of skewness and kurtosis, and
the Jarque-Bera statistic testing for
normality.
28
Lab 6
29
30
View/Residual tests/Histogram-Normality Test
31
32
Diagnostics (Cont.)
• To detect heteroskedasticity: if there are
sufficient observations, plot the estimated
errors against the fitted dependent variable
33
Heteroscedasticity
• When the requirement of a constant variance is violated we
have a condition of heteroscedasticity.
• Diagnose heteroscedasticity by plotting the residual against
the predicted y.
+
++
^y
Residual
+ + +
+
+
+
+
+
+
+
+
+
++ +
+
+ +
+
+
+
+ +
+
+ +
+
+
+
The spread increases with ^y
y^
++
+ ++
++
++
+
+
++
+
+
Homoscedasticity
• When the requirement of a constant variance is not
violated we have a condition of homoscedasticity.
• Example 18.2 - continued
Residuals
1000
500
0
13500
-500
14000
14500
15000
15500
16000
-1000
Predicted Price
35
Diagnostics ( Cont.)
• Autocorrelation: The Durbin-Watson
statistic is a scalar index of autocorrelation,
with values near 2 indicating no
autocorrelation and values near zero
indicating autocorrelation. Examine the plot
of the residuals in the view menu of the
regression window in EViews.
36
Non Independence of Error
Variables
– A time series is constituted if data were
collected over time.
– Examining the residuals over time, no pattern
should be observed if the errors are
independent.
– When a pattern is detected, the errors are said to
be autocorrelated.
– Autocorrelation can be detected by graphing the
residuals against time.
37
Non Independence of Error Variables
Patterns in the appearance of the residuals over time indicates
that autocorrelation exists.
Residual
Residual
+ ++
+
0
+
+
+
+
+
+ +
+
+
+
++
+
+
+
Time
Note the runs of positive residuals,
replaced by runs of negative residuals
+
+
+
0 +
+
+
+
Time
+
+
Note the oscillating behavior of the
residuals around zero.
38
Fix-Ups
• Error is not distributed normally. For
example, regression of personal income on
explanatory variables. Sometimes a
transformation, such as regressing the
natural logarithm of income on the
explanatory variables may make the error
closer to normal.
39
Fix-ups (Cont.)
• If the explanatory variable is not
independent of the error, look for a
substitute that is highly correlated with the
dependent variable but is independent of the
error. Such a variable is called an
instrument.
40
Data Errors: May lead to outliers
• Typos may lead to outliers and looking for
ouliers is a good way to check for serious
typos
41
Outliers
• An outlier is an observation that is unusually small or
large.
• Several possibilities need to be investigated when an
outlier is observed:
– There was an error in recording the value.
– The point does not belong in the sample.
– The observation is valid.
• Identify outliers from the scatter diagram.
• It is customary to suspect an observation is an outlier
if its |standard residual| > 2
42
An outlier
+ +
+
+ +
+ +
+ +
An influential observation
+++++++++++
… but, some outliers
may be very influential
+
+
+
+
+
+
+
The outlier causes a shift
in the regression line
43
Procedure for Regression
Diagnostics
• Develop a model that has a theoretical basis.
• Gather data for the two variables in the model.
• Draw the scatter diagram to determine whether a linear
model appears to be appropriate.
• Determine the regression equation.
• Check the required conditions for the errors.
• Check the existence of outliers and influential observations
• Assess the model fit.
• If the model fits the data, use the regression
equation.
44
Part II: Experimental Method
45
Outline
• Critique of Regression
46
Critique of Regression
• Samples of opportunity rather than random
sample
• Uncontrolled Causal Variables
– omitted variables
– unmeasured variables
• Insufficient theory to properly specify
regression equation
47
Experimental Method: # Examples
• Deterrence
• Aspirin
• Miles per Gallon
48
Deterrence and the Death Penalty
49
Isaac Ehrlich Study of the Death
Penalty: 1933-1969
Homicide Rate Per Capita
Control Variables
probability of arrest
probability of conviction given charged
Probability of execution given conviction
Causal Variables
labor force participation rate
unemployment rate
percent population aged 14-24 years
permanent income
trend
50
Long Swings in the Homicide Rate in the US: 1900-1980
Source: Report to the Nation on Crime and Justice
Ehrlich Results: Elasticities of
Homicide with respect to Controls
Control
Elasticity
Average Value
of Control
0.90
Prob. of Arrest
-1.6
Prob. of Conviction
Given Charged
Prob. of Execution
Given Convicted
-0.5
0.43
-0.04
0.026
Source: Isaac Ehrlich, “The Deterrent Effect of Capital Punishment
Critique of Ehrlich by Death
Penalty Opponents
Time period used: 1933-1968
period of declining probability of execution
Ehrlich did not include probability of
imprisonment given conviction as a control
variable
Causal variables included are unconvincing
as causes of homicide
53
United States Bureau of Justice Statistics
http://www.ojp.usdoj.gov/bjs/
54
Experimental Method
• Police intervention in family violence
55
United States Bureau of Justice Statistics
http://www.ojp.usdoj.gov/bjs/
56
United States Bureau of Justice Statistics
http://www.ojp.usdoj.gov/bjs/
57
Police Intervention with
Experimental Controls
A 911 call from a family member
the case is randomly assigned for “treatment”
A police patrol responds and visits the
household
police calm down the family members
based on the treatment randomly assigned, the
police carry out the sanctions
58
Why is Treatment Assigned
Randomly?
To control for unknown causal factors
assign known numbers of cases, for example
equal numbers, to each treatment
with this procedure, there should be an even
distribution of difficult cases in each treatment
group
59
911 call
(characteristics of household Participants unknown)
Random Assignment
code blue
code gold
patrol responds
patrol responds
settles the household
verbally warn the husband
settles the household
take the husband to jail
for the night
60
Experimental Method: Clinical Trials
•
•
•
•
Doctors Volunteer
Randomly assigned to two groups
treatment group takes an aspirin a day
the control group takes a placebo (sugar pill) per
day
• After 5 years, 11,037 experimentals have 139 heart
attacks (fatal and non fatal) pE = 0.0126
• after 5 years, 11034 controls have 239 heart
attacks, pc= 0.0217
61
Conclusions from the Clinical Trials
• Hypotheses: H0 : pC = pE , or pC - pE = 0.;
Ha : (pC - pE ) 0.
• Statistic:Z = [p̂C - p̂E ) – (pC - pE )]/( pC - pE )
VAR( pˆ c pˆ E ) VAR( pˆ c ) VAR( pˆ E )
• recall, from the variance for a proportionSE
SE(p̂C - p̂ E )={[p̂c (1-p̂ c )]/nc + [p̂E(1-p̂ E )]/nE }1/2
• { [0.={[0217 ( 1- 0.0217)/ 11,034] + [0.0126 ( 1 –
0.0126)/ 11,039}1/2
•
= 0.00175, so z = (.2017-.0126)/.00175
• z= 5.2
Pseudo Experimental Method
•
•
•
•
Observations assigned to two groups, 12 each
“treatment” group is low temperature , 5 failures
the “control” group is high temperature, 2 failures
“experimentals” have 5 failures (yesses) pL = 5/12
controls have 2 failures, pH= 2/12
63
Challenger
• Divide the data into two groups
– 12 low temperature launches, 53-70 degrees
– 12 high temperature launches, 70-81 degrees
64
Temperature
53
57
58
63
66
67
67
67
68
69
70
70
O-Ring Failure
Yes
Yes
Yes
Yes
No
NO
No
No
No
No
No
Yes
65
Temperature
70
70
72
73
75
75
76
76
78
79
80
81
O-Ring Failure
Yes
No
No
No
Yes
No
No
No
No
No
No
No
66
H0: pL = pH, i.e, pL – pH =0
HA: pL > pH , i.e. pL – pH >0
z [( pˆ L pˆ H ) E ( pˆ L pˆ H )] / pˆ L pˆ H
z [( pˆ L pˆ H ) ( pL pH ) / pˆ L pˆ H
pˆ
z ( pˆ L pˆ H ) E ( pˆ L pˆ H ) / pˆ L pˆ H
ˆH
Lp
VAR( pˆ L ) z VAR( pˆ H )
Z = [(5/12-2/12) – 0]/[(5/12)(7/12)/12 +(2/12)(10/12)/12]1/2
Z = 0.25/0.178 = 1.40
67
H0: p(low temp) = p(high temp)
Binomial Prob(k≥5) in 12 Trials, Given p = 2/12
k
n
0
1
2
3
4
5
6
7
8
9
10
11
12
12
12
12
12
12
12
12
12
12
12
12
12
12
prob
0.112157
0.269176
0.296094
0.197396
0.088828
0.028425
0.006632
0.001137
0.000142
1.26E-05
7.58E-07
2.76E-08
4.59E-10
0.028424983
0.035057479
0.036194478
0.036336603
0.036349236
68
The Probability that O-Rings Fail In a Low Temperature Launch Given Probability
of Failure At High Temperature =1/6
0.35
0.3
Probability
0.25
0.2
0.15
0.1
0.05
0
0
1
2
3
4
5
6
7
8
9
10
11
12
Number of Launches with Failures
69
Experimental Method
• Experimental Design: Paired Comparisons
• comparing mileage for two different brands
of gasoline
• control for variation in car and driver by
having each cab use both gasolines. Each
cab is called a block in the experimental
design
• control for weather, traffic, and other factors
by assigning different days and times to
each cab.
70
Table 1: Miles Per Gallon for Brand A and Brand B
Cab
Brand A
Brand B
Difference
1
27.01
26.95
0.06
2
20.00
20.44
-0.44
3
23.41
25.05
-1.64
4
25.22
26.32
-1.10
5
30.11
29.56
0.55
6
25.55
26.60
-1.05
7
22.23
22.93
-0.70
8
19.78
20.23
-0.45
9
33.45
33.95
-0.50
10
25.22
26.01
-0.79
Sample Mean
25.20
25.80
-0.60
Standard Deviation
4.27
4.10
0.61
Test Whether the Difference
Between Gasolines is Zero:
• H0: diff = 0, Ha : diff not zero
• t-stat = (sample difference - zero)/(smpl. std. dev/n)
• t-stat = -0.60/(0.61/101/2) = - -0.60/0.190 = - 3.16
72
73
Lab 6: Exercises
74
Lab 6 Exercises
Percent Household Income Spent On the Lottey Vs. Income
14
12
Percent
10
8
6
4
2
0
0
10
20
30
40
50
60
70
80
90
100
Income, Thousands $
75
Percent Spent on Lottery Vs Income
14
12
actual
10
Tobit
OLS
8
Percent
6
4
2
0
0
10
20
30
40
50
60
70
80
90
100
-2
-4
-6
Income, Thousands $
76
Midterm 2000
• .(15 points) The following table shows the results of
regressing the natural logarithm of California
General Fund expenditures, in billions of nominal
dollars, against year beginning in 1968 and ending
in 2000. A plot of actual, estimated and residual
values follows.
– .How much of the variance in the dependent variable is
explained by trend?
– .What is the meaning of the F statistic in the table? Is it
significant?
– .Interpret the estimated slope.
– .If General Fund expenditures was $68.819 billion in
California for fiscal year 2000-2001, provide a point
estimate for state expenditures for 2001-2002.
•
77
• Cont.
– A state senator believes that state expenditures
in nominal dollars have grown over time at 7%
a year. Is the senator in the ballpark, or is his
impression significantly below the estimated
rate, using a 5% level of significance?
– If you were an aide to the Senator, how might
you criticize this regression?
78
Table
Dependent Variable: LNGENFND
Method: Least Squares
Sample: 1968 2000
Included observations: 33
Variable
Coefficient
Std. Error
t-Statistic
Prob.
YEAR
C
0.086958
-169.4787
0.003895
7.726922
22.32804
-21.93353
0.0000
0.0000
R-squared
Adjusted R-squared
S.E. of regression
Sum squared resid
Log likelihood
Durbin-Watson stat
0.941459
0.939570
0.213030
1.406835
5.235258
0.118575
Mean dependent var
S.D. dependent var
Akaike info criterion
Schwarz criterion
F-statistic
Prob(F-statistic)
3.046404
0.866594
-0.196076
-0.105379
498.5416
0.000000
Plot
Actual, Fitted and Residual Values from the Regression
of the Logarithm of General Fund Expenditures ($B) on Year
5
4
3
0.4
2
0.2
1
0.0
-0.2
-0.4
70
75
80
Residual
85
Actual
90
95
00
Fitted
79