Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
STATISTICAL HYPOTHESIS TESTING
BY
Dr. K.R. SUNDARAM
Professor & Head
Department of Biostatistics
All India Institute of Medical Sciences
New Delhi-110029
Workshop on
“Essentials of Epidemiology and Research Methods”
October 8-12 , 2003, Surajkund,Faridabad
STATISTICAL METHODS
(A)Descriptive methods
(B)Inference methods
(A) Descriptive Methods :-Statistical methods used for describing
( summarizing ) the collected data:--Statistical Tables,
Diagrams & Graphs,
Computation of Averages, Location Parameters,
Proportions & Percentages,
Deviation measures and Correlation measures and
Regression analysis .
(B) Inference Methods:-Statistical methods used for making inferences
(generalizations) from the results obtained from
the sample to the population from where the
sample was selected
Two important questions raised
in scientific studies
(A) How reliable are the results obtained---ESTIMATION
(B)
How probable is it that the differences
between observed & expected results on the
basis of the hypothesis have been produced
by chance alone
TEST OF STATISTICAL SIGNIFICANCE
:---by computing the chance element
Important terms / concepts concerned with the
Statistical Inference :-Standard Error
Null Hypothesis
Confidence Interval
Alternate Hypothesis
Type-I error ( level of significance / ‘p’ value’/ ‘’value )
Type – II () error
Probability and Probability distributions or Statistical distributions
( Normal , Binomial, Poisson etc. )
Test Statistic ( Test Criterion )
Critical Ratio and Decision making .
Notations used :-Statistical
figure
Number of
subjects
Value of observation
Mean
Proportion
Standard
deviation
Variance
Correlation
coefficient
Population
Sample
N
n
-
X
M ( )
P
m (X )
p
s
2
s2
r
Concept Of Standard Error (SE)
Standard Deviation (SD):
average amount of deviation of different sample values
from the mean value.
SD = SQRT ( (X-m)2/n )
X – sample value n - sample size
the sample
m – Mean value in
Standard Error (SE) :--Average amount of deviation of different sample mean
values from the population ( true ) mean value.
SE =SQRT ((m-)2/r)
( = Grand ( combined ) mean = estimate of population
mean , r - no of samples)
Computation of SE using the above
formula is difficult and may not be feasible.
Hence, SE is usually computed from one
randomly selected sample of adequate size,
as follows:-
SE = SD / SQRT(n)
Probability
:--Relative frequency or probable chances of occurrences
with which an event is expected to occur on an average –in
the long run.
:--Relative frequency of the number of occurrences of a
favorable event to the total number of occurrences of all
possible events.
No conclusion can be drawn with 100 % certainty
( confidence )
Probability is the measurement of chance / uncertainty /
subjectivity associated with a conclusion.
Two Types of Probability:-
( A ) Mathematical
( B ) Statistical
(A) Mathematical probability:
An experiment or a trial where the probabilities of
occurrences of various events / possibilities are
already established mathematically.
Examples:--(1) Prob. of getting a head when a coin is
tossed
(2) Prob. of getting five when a dice is
thrown
(3) Prob. of getting spade ace from a deck
of
cards
(B)Statistical / Empirical Probability:
An experiment or a trial is required to find out the probabilities
of occurrences of various events / possibilities.
Examples :---(1 ) Prob. of getting a boy in the first pregnancy
(2 ) Prob. of getting a twin for a couple.
(3 ) Prob. of improvement after the treatment for a specified
period
(4 ) Prob. of getting lung cancer in smokers
(5 ) Prob. of an association of sedentary type of work with diabetes
(6 ) Prob. that drug-A is better than drug-B in curing a disease.
Probability Distributions
Several basic theorems based on which several types of
probabilities are computed.
A series of probabilities associated with various occurrences/
outcomes/ possibilities of events in an experiment/ trial/ study
will generate a probability distribution.
Basically -three types of probability distributions:
Binomial , Poisson and Normal distribution.
Probability Distributions
Binomial and poisson distributions --for discrete
variables
Normal distribution --for continuous variables .
Most important probability distribution in statistical
inference is Normal distribution(Guassian distribution )
Normal distribution will generate a Normal (Guassian )
curve .
Normal Curve
Properties of Normal Curve:
(1 ) It is bell shaped & symmetrical
(2 )The three types of averages--- the mean,the median & the
mode will be almost equal
(3 ) The total area under the normal curve will be equal to “1”
(4) Fifty percent of the sample values will lie on the left of the
perpendicular drawn on the middle and the remaining 50 %
will lie on the right of this line
Properties of Normal Curve:
(5 ) Mean - 1 SD & mean + 1 SD will include about 68 % of
the sample values
(6 ) Mean – 2 SD& Mean + 2 SD will include about 95 % of the
sample values
(7 ) Mean – 3 SD & mean + 3 SD will include about 99 % of
the sample values
Properties of Normal Curve
(8 ) Theoretically the curve touches the horizontal line only at
the infinity
(9 ) (Sample value – Mean ) / SD which is called as Standard
Normal Deviate / Z- score is distributed with a mean of “ 0 “
and a SD of “ 1 “ , what ever the variable may be .
This is a very important property.Inference theory is based on
this property.
Estimation of Population Parameters
Two types of Estimation
(1)
Point estimation – (Estimation without Confidence)
Values of mean, proportion,correlation coefficient
etc.
computed from sample serve as estimates of the population
parameters.
This estimate is a single value and is called Point estimate.
(2) Interval estimation:
(Estimation with Confidence)
A lower limit (LL) and an upper limit (UL) are
computed
from sample values
It can be said with a certain amount of confidence,
that the population value (true value) of the parameter
will lie within these limits.
These limits are called Confidence limits or
Interval estimates.
The LL and UL estimates for the Population mean are
given as :-
mean - C* SE
and
mean + C*SE
C= Confidence coefficient, SE ={ SD / (n) },
n = sample size.
( * = multiplicative sign )
If 95% confidence is desired , C = 1.96 ,
for 99% confidence,
C = 2.58
for 99.9% confidence,
C = 3.29
Example-1:
In a study of a sample of 100 subjects it was found that
the mean systolic blood pressure was 120mm. of hg.
with a standard deviation of 10mm. of hg. Find out
95% confidence limits for the population mean of
systolic blood pressure.
SE = SD / ( n ) = 10/ ( 100 ) = 10/10 =1
LL :--- mean - 1.96*1 :--- 120 - 1.96 = 118.04
UL :--- mean +1.96*1 :--- 120 + 1.96 = 121.96
i.e. the population mean value of systolic blood pressure
will lie between 118.04 and 121.96 and we can have a
confidence of 95% for making this statement.
Example-2:
(2) In a study of 10,000 persons in a town , it is found that 100 of
them are affected by tuberculosis. Find out 99% confidence limits
for the population prevalence rate.
SE = (( pq)/(n)),
where, p= (100/10000 ) * 100 = 1%
q = 100 – p = 100 – 1 = 99%,
SE= ( (1*99) / 10000 )= 0.0995
LL = p - 2.58*0.0995 = 1- 0.2567 = 0.7433
=
0 .74 %
UL= p +2.58*0.0995 = 1 +0.2567 = 1.2567
=
1.26 %
i.e. the population prevalence rate of tuberculosis will lie between
0.74% and 1.26% and we can say this with 99% confidence
Statistical Hypothesis
A declarative statement about the
parameters (of population) or the
distribution form of the variable in the
population.
Examples
1. Mean systolic blood pressure (m) in normal subjects of 30 years of
age in the population is equal to 120mm i.e. M=120.
2.
Mean cholesterol value in hypertension patients (M1) > mean
cholesterol value in normals (M2) i.e. M1>M2.
3. Percent of babies born with low birth weight to anaemic women (P1) is
greater than that in normal women (P2) i.e. P1>P2.
4.
Occurrence of lung cancer is associated with smoking.
5. Birth weights of children are normally distributed
Null Hypothesis --- Ho
No difference in average values or percentages
between two or several populations.
Examples:--( 1 ) Mean cholesterol value in normal (M1) =Mean
cholesterol value in hypertension patients ( M2 )
( 2 ) Percentage of babies born with low birth weight
in anaemic women ( P1 ) = Percentage of babies
born with low birth weight in normal women ( P2 )
( 3 ) no association between lung cancer and smoking
Alternative Hypothesis( H1)---two sided
There is difference in average values or percentages between
two or several populations:--M1 M2
P1 P2
Alternate Hypothesis (H1 )---one sided
M1 > M 2
or
M 2 > M1
P1 > P2
or
P2 > P1
Examples:--( 1 ) Mean cholesterol value in hypertension
patients (M1) > Mean cholesterol value in
normals( M2 )
( 2 ) Percentage of babies born with low birth
weight in anaemic women ( P1 ) > Percentage of
babies born with low birth weight in normal
women ( P2 )
( 3 ) There is an association between lung
cancer and smoking---Prevalence of lung cancer is
higher in smokers than in non-smokers
TYPE - I & TYPE- II ERRORS
Consider the following 2X2 Table:--
Ho
True
False
Accept
(no error) - (type- II )
Reject
- (type –I)
(no error)
Type- I error :----
: p- value : level of
significance
probability of rejecting Ho when it is actually true.
= probability of finding an effect when actually there is
no effect.
measures the strength of evidence by indicating the
probability that a result at least as extreme as that
observed would occur by chance
1- = Confidence coefficient = probability of rejecting
Ho when it is false
= probability of finding an effect when actually
there is an effect.
Type - II error :- = Probability of accepting Ho when it
is actually false.
= Probability of not finding an effect
when actually there is an effect.
1-
= Power of the test = Probability of accepting Ho
when it is true
= Probability of not finding an effect
when actually there is no effect.
• When the null hypothesis is rejected, type-I error is to be
stated
Maximum error allowed---5 % i.e.,
Minimum confidence required---95 %
• When the null hypothesis is accepted, type- II error is to
be stated
Maximum error allowed---20 % i.e;
Minimum power required ----80%
•
• When the null hypothesis is rejected at a chosen level of
significance ,what ever may be the sample size it may be
adequate but,
• when the null hypothesis is accepted, the adequacy of the
sample size has to be checked before accepting Ho by
computing the Power of the test
Testing The Statistical Significance Of
Hypothesis
Testing the statistical significance of Hypothesis is the
process of calculations using sample results to see
whether the null hypothesis is true or false
Steps :--1. State the null hypothesis: H0
2. State the alternate hypothesis: H1
(one sided / tailed or two sided / tailed)
3. State the distribution of the sample statistic or the
difference (normal or student’s ‘t’ or chi- square).
4. State the level of significance
( or p - value or type -I error) desired.
5. Compute the Test Statistic (TS) =
(difference in parameter values)
= ------ ----------------------------(SE of difference)
6. Find out the Critical Ratio (CR) from the statistical table at the
chosen level of significance
• Take decision :-a. If TS <CR: accept Ho i.e. difference in
parameter values is not statistically significant
b. If TS > CR: reject Ho : accept H1 i.e.
difference in parameter values is statistically
significant .
If p < 0.05, Confidence (C) > 95 %;
if p < 0.01,
C > 99 % and
if p < 0.001,
C > 99.9%
Guidelines , Steps and Examples in Tests of
Significance
(A) Continuous variable :(1) Ho : Null Hypothesis: μ1=μ2
μ1= Mean gain in weight of infants who
received supplementary diet
μ2= Mean gain in weight of infants who did not
receive supplementary diet
(2) H1 : Alternate Hypothesis: μ1 μ2
(3-a) If Population distribution of gain in weight in
both the groups is NORMAL (either known from
earlier studies or could be established from the
random samples ) or both the sample sizes are
large ( n1 and n2 > 30 ) the TEST STATISTIC is Z
and the test is called NORMAL TEST.
(3-b) If n1 or n2 or both n1 and n2 < 30 , the TEST
STATISTIC is Student`s “t” and the test is
called Student`s “t” TEST.
Level of Significance ( :-Type I Error:- p-Value )
If = 0.05, Confidence ( C ) = 95% ,
if = 0.01, C=99 %
if = 0.001, C=99.9 %
(5)
Test Statistic or Test Criteria (Z)
If Normal or n1 , n2 > 30 Z
, X1 X 2
S12 S 22
n1 n2
•
-----where, X1 and X2 are the mean values of weight in
Samples A and B respectively and S12 and S22 are the
corresponding standard deviations.
(6) Critical Ratio ( C.R )
If = 0.05, C.R =1.96 , if = 0.01,
C.R.= 2.58 and if = 0.001 ,C.R.= 3.29
(7) Taking Decision
Difference in means
between the Two Groups
_________________________
If Z < 1.96
Not
Significant
( Ho is acceptable )
( p > 0.05 )
( a ) Z > 1.96
Significant
( p < 0.05 )
( b ) Z > 2.58
Highly
Significant
( p < 0.01 )
( c ) Z > 3.29
Very Highly
Significant
( p < 0.001 )
( Ho is rejected in ‘a’ ‘ b’ and ‘c’ )
Various Tests of Statistical Significance
(a)To test the statistical significance of the
difference in sample and population Means
H1 : X
H0 : X
= 0.05 , CR = 1.96 ,
TC = Z = ( X ) S / n
Example : Mean SBP in population= 120,
Mean SBP in Sample= 115
( n = 100 SD = 20 )
Z = ( 120 – 115 ) 20 / 100
= 2.5
ie ,
TC > CR . p < 0.05
Means in the population and sample are significantly
different or
The sample does not represent the population w.r.t.
SBP
( b ) To test the statistical significance of the
difference in Mean values between two
Populations
X X
Z
(1) Large Sample:
1
2
S12 S 22
n1 n2
If Z < 1.96 ,The difference in means in the population
and sample can be considered as statistically not
significant
Test of Homogeneity of Variances
( Fisher`s ‘F ‘ )
• One of the assumption which has to be satisfied for applying Student`s
t test is Homogeneity of variances in the two populations .This is tested
by computing Fisher`s F statistic.
12
F= 2
2
for (n1-1) , (n2-1) d.f. (
1
2)
• If the computed F value is less than the Critical ratio of F at (n1-1) ,
(n2-1) d.f. , then the assumption of Homogeneity of variances in the
two populations can be accepted. Otherwise , the variances in the two
populations will be Heterogeneous.
( n1 or n2 or both n1 & n2 < 30 ) : (1 = 2)
Homogeneity of variances in the two populations is assumed and
accepted,
(2) Small Samples
t
where S,
S
X1 X 2
1 1
S
n1 n2
rr1 1 S12 n2 1 S22
n1 n2 2
Critical ratio values depend upon degree of freedom - ( n1+n2-2 )
3 Small Samples (n < 30 ) and (1 2) : Homogeneity of variances in
the two populations is not accepted, In such a case . Modified ‘t’ test
has to be applied.
t
X1 X 2
1 1
S
n1 n2
S12
S22
t n1 1
t n2 1
n1
n2
t1
S12 S22
n1 n2
If t > t` ; p<0.05 (significant) , if t < t` p > 0.05 ( not significant)
Weight ( kg ) of school going ( A ) and non-School going ( B ) children of 5
years of age in slum areas :--Population
(1) n1 & n2 > 30
A
B
Sample Size
Mean
S.D
100
100
17.4
13.2
3.0
2.5
Z = 15.56 ( p < 0.001 ) i.e. ---
A B
A B
(2) n1 & n2 < 30 ( σ1 = σ2 )
A
B
15
10
17.4
13.2
3.0
2.5
F = ( 3.0 )2 / (2.5)2 =1.44 < 3.00 ( for 14 & 9 d.f. at = 0.05 ).
Hence, assumption of homogeneity of variances in the two populations can
be accepted.
t = 3.65 > 2.81 ( for 23 d.f at = 0.01 )< 3.77 (for 23 d.f at = 0.001 )
i.e., p < 0.01
i.e,
A B
A B
(3) n1 & n2 < 30 and
1 2
A
B
15
10
17.4
13.2
1.8
4.2
F = ( 4.2 )2 / (1.8)2 =5.44 > 2.65 ( for 9 & 14 d.f. at = 0.05 )
i.e . The assumption of Homogeneous variances in the two populations cannot be
accepted ( 1 2 ) and hence modified ‘t’ test has to to be applied .
t =2.98 > 2.25 t` (t`at
i.e. A B
……
=0.05
A B
) but, < 3.22 t` ( t`at =0.01 )
( p<0.05 )
(4) Paired Samples :
Where :
d
d w
t
Sd
Mean of the difference ,
Sd: SD of the difference
degrees of freedom = n-1
Systolic B.P
Patient Number
1
2
3
4
5
6
7
8
9
10
Before Drug
160 150
170
130
140
170
160
160
120
140
After
140 110
165
140
145
120
130
110
120
130
Drug
Mean
S.D.
Before
drug
150
17.00
After
drug
131
17.13
19
22.46
Change
(Decrease)
19 10
t
22.46
=2.67 > 2.26 ( t at
=0.05
with 9 d.f.
) i.e
p < 0.05
i.e The decrease of 19 units ,on average, in the Systolic BP
after giving the drug is statistically significant at 5 % level of
significance.
(5) Analysis of Variance (ANOVA)
•
To test the statistical significance of the differences in
mean values of a variable among different groups
(more than TWO groups).
• In case of two groups, student's `t' test is applied.
• The added advantage in ANOVA is that the total
variance can be partitioned into different components
(due to several factors)which will enhance the
validity of comparison of the means among the
different Groups.
• This is not possible in the case of `t' test.
Designs
Basically THREE important Experimental Designs are
used in ANOVA.
They are :–
1. Completely Randomized Design (CRD) ( One-way
ANOVA )
2. Randomized Complete Block Design (RCBD):(Two or Multiple-way ANOVA )
3. Repeated Measures Design ( Before & After Design )
( Two-way, Between TIME Analysis )
• 1. CRD
If there is only ONE FACTOR studied affecting the
study variable Completely Randomized Design
(CRD)/One-way ANOVA is used
Example:
The study population consists of only children who are
severely malnourished and a Clinical Trial is
conducted to study the efficacy of three methods: diet,
drug and placebo, in increasing their weight.
• 2.
RCBD
If TWO or more factors are studied affecting the
study variable OR if the study elements in the
population are HETEROGENEOUS with respect
to the Factor(s), in addition to the main Factor
studied,Randomized complete Block Design
(RCBD)/Two or Multiple-way ANOVA is used.
Example:
• The population consists of children who are mildly,
moderately or severely malnourished and a Clinical
Trial is conducted to study the efficacy of three
methods: diet, drug and placebo, in increasing their
weight.
• Here, the children are classified according to their
malnourishment status, and in each group are
randomly allocated into three methods of treatment.
• This design will enhance the validity of comparison of
the mean weight increase among the three Groups as
compared to the Completely Randomized Design
Repeated measures design :
If the values of a variable of the subjects are
recorded
BEFORE
and
AFTER
an
INTERVENTION (more than once after the
intervention) Repeated Measures Design is
adopted, for a valid comparison of the mean
values of the variable between various Timings of
recording taking into consideration, the variation
between the Subjects.
Example :
Blood Pressure values of Hypertension
patients were recorded before and after
ONE week and after TWO weeks after
giving a drug. To test the statistical
significance of the differences in mean BP
among the THREE Timings of recording ,
Repeated Measures Analysis will enable us
to make a more valid comparison.
Homogeneity of variances
Before applying ANOVA test ,HOMOGENEITY( EQUALITY)
of VARIANCES of the variable in the different Groups has to
be tested.
The most commonly used test is BARTLETT`s Test.
If this test shows non-significance ANOVA can be applied on
the original values of the Variable .If this shows statistical
significance, appropriate transformation ( Log, Square root
,inverse etc. ) has to be done for the original values before
applying ANOVA.
MULTIPLE RANGE TESTS
If the Analysis of Variance provides statistically
significant F-value for the treatment variation
( ie;if the ANOVA shows statistically significant
differences in the mean values among the Groups)
appropriate Multiple Range Test is to be applied
to find out significantly different pairs of groups.
The most commonly used Multiple Range Test is
Student Newman Keul's (SNK) Test.
PROBLEMS IN ANOVA :--(1) ONE – WAY ANOVA ( COMPLETELY
RANDOMIZED DESIGN
A study was conducted to investigate the effect of supplementary
nutrition, a drug and placebo in increasing the weight of severely
malnourished children. Fifteen severely malnourished children were
randomly divided into three Groups A , B & C. Group A was given
supplementary nutrition , Group B , the drug and Group C , the
placebo. Gain in weight in these children was noted after one month
of treatment. Test whether tht differences in weight gain, on an
average,among the three groups are statistically significant or not at 5 %
level of significance.
Also test whether the difference between any two groups is statistically
significant or not at 5% level of significance.
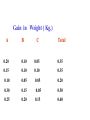
Gain in Weight ( Kg.)
A
B
C
Total
0.20
0.10
0.05
0.35
0.15
0.10
0.10
0.35
0.10
0.05
0.05
0.20
0.30
0.15
0.05
0.50
0.25
0.20
0.15
0.60
ANOVA TABLE
Source of Variation
d.f.
S.S.
14
0.0833
Between Groups
2
Error
12
Total
M.S.S.
F
p
0.0373
0.0186
4.91
< 0.05
0.0460
0.0038
d.f. –Degrees of freedom ; S.S.—Sum of squares ; M.S.S. –Mean sum of
squares ; F—F statistic ; p—level of significance
F at = 0.05
F at = 0.01
with 2, 12 d.f. = 3.89 ,
with
2, 12 d.f. = 6.93
Computed F (4.91) > 3.89, but < 6.93 .
i.e., Differences in gain in weight in children
among the three groups are statistically
significant, on an average (p < 0.05) –
Confidence = 95%
Multiple Comparison Test:
Since the ANOVA gave a significant F value ,
we may have to find out the groups which
are significantly different
by applying
Multiple comparison test.
The most commonly used
multiple
comparison test is Student-Newman Keul`s
(SNK) test.
Treatment Group
A
B
C
Mean gain in weight ( kg)
0.20
0.12
0.08
On applying SNK test using a statistical software , it is found
that gain in weight in severely malnourished children who
received supplementary diet was significantly larger than in
those who received placebo, on an average (p < 0.05;
confidence = 95%). However, differences observed in gain in
weight between those who received supplementary diet and
drug or between those who received drug and placebo were
statistically not significant (p > 0.05)
(2)Two - way ANOVA ( Randomized
Complete Block Design - RCBD)
In a clinical trial to test the efficacy of two drugs
and a placebo in the sleeping hours of mental
patients it was thought that age of the patient
could also influence the sleeping hours. Hence ,
the patients were stratified according to their age
group and then randomly distributed into three
treatment groups.
Age group
( Years )
IMPROVEMENT IN
SLEEPING HOURS
A
B
Placebo
Total
24-34
2.3
1.6
0.6
4.5
35-44
2.0
1.4
0.4
3.8
45-54
1.8
1.0
0.3
3.1
55 and
More
1.2
0.8
0.3
2.3
ANOVA TABLE
Source of
Variation
d.f.
S.S.
(n-1)= 11
5.19
Due to age
(r-1)= 3
Due to drug
Error
Total
M.S.S
.
F
p
0.89
0.297
8.2
< 0.05
(p-1)=2
4.0825
2.0412
56.4
<0.001
(n-1)-(r-1)-(p-1)=n-r-p+1=6
0.2175
0.0362
Conclusions:
Influence of age on treatment effect is significant ( p
<0.05). i.e., accounting variation due to age has helped
in reducing the error (MESS) i.e, in improving the
precision of the estimate.
Differences in mean improvement in sleeping hours
among the three treatment groups are statistically
significant (p <0.001)
Drug
Drug : A
Drug : B
Placebo:
Mean improvement in sleeping hours
-1.825 (A)
-1.200 (B)
-0.400(C)
On applying SNK test using a statistical software ,it was
found that improvement in sleeping hours with drug A
was significantly higher than that with drug B and
placebo (p < 0.01) and that with drug B was significantly
higher than that with placebo, on an average
(3) Two – way ANOVA ( RCB design where
individuals themselves serve as blocks):
Systolic blood pressure values of 10 patients, before
treatment and after 1 week and after 2 weeks after
treatment are given below. Test whether the change
(reduction) in systolic blood pressure after 1 week
and 2 weeks after treatment is statistically
significant or not.
Sl.No.
1
2
3
4
5
6
7
8
9
10
Total
Mean
Before
170
165
180
175
165
180
175
160
155
165
1690
196
After 1
week
160
160
170
165
160
160
170
150
140
145
1580
158
After 2
weeks
140
135
140
135
135
140
145
125
120
120
1335
133.5
Total
470
460
490
475
460
480
490
435
415
430
4605
TWO-way ANOVA TABLE
Source of
Variation
d.f.
S.S.
29
8857.5
Between
Time (T)
2
Between
Patients (P)
Error (E)
Total (T)
M.S
.S.
F
p
6605.0
330
2.5
26
0.2
<
0.001
9
2024.17
224.
9
17.
7
<
0.001
18
228.33
12.6
9
Conclusions:
Variation due to patients was found to be statistically
significant at = 0.001
i.e. variation in BP among patients is statistically
significant.
After accounting for this variation, the differences in mean
BP among the three Time periods are found to be
statistically significant (p < 0.001).
On applying SNK test ,it was found that reduction in BP, 1
week after treatment and 2 weeks after treatment was
statistically significant (p < 0.001).Reduction from 1 week
to 2 weeks after treatment is also statistically significant
(p < 0.001) .
INFERENCE METHODS for
DISCRETE VARIABLES
Estimation :
1. Point Estimate : Proportion , Percentage , Ratio ,
Rate
2. Interval Estimate :95% or 99%or 99.9 %
Confidence
intervals for proportion , Percentage.
Point Estimate :
1. Proportion of persons diagnosed as cases in a survey of
diabetes ( p = 0.14 or 14 % )
2. Proportion of smokers with lung cancer
(p = 0.24 or 24% )
3. Sex Ratio : 970 females / 1000 males
Doctor / Population Ratio : 1 : 10,000
4. Birth rate , Death rate etc.
Interval Estimate :S.E = (pq / n )
(1) If p = 0.14 and n = 900, S.E = = 0.0116
95% Confidence limits : p – 1.96 SE and p + 1.96 SE
: 0.1172-3 and 0.1627
(2) If p = 24% and n = 10,000 , SE = 0.43
99% Confidence limits : p –2.58 SE and p+2.58
SE ; 23.2 & 24.8
Tests of Significance :1.
Z - test ( Proportion )
2. λ 2 test ( 22 , 2n , rn )
3. Matched λ 2 test ( McNemar’s )
( 2 2 or pp )
Examples:
Distribution of children according to their sex and nutritional
grading is given in the table below:Sex
Nutritional Grading
Total
Normal
Gr I
Gr II
Gr III/IV
Male
25 (18)
45(42)
25(30)
5(10)
100
Female
11(18)
39(42)
35(30)
15(10)
100
Total
36(18)
84(42)
60(30)
20(10)
200 ( 100 )
( 1 ) 22 Contingency Table :
Normal
Malnourished
Total
Sex
M
25(18)
75(82)
100
F
11(18)
89(82)
100
164
200
T
36
Malnourished = Gr-I , Gr- II , Gr. III & Gr. IV
Ho: No association between sex and nutritional status
H1 : There is an association between sex and nutritional status
x
2
Test Statistic =
O E
E
2
with 1 d.f. (degree of freedom ).
Degrees of freedom is the number of independent cells ( groups ) in the data .
If there are four cells , d.f. will be 1 since if there is only one independent cell
and the number in the other three cells can be determined by subtraction of
the available cell number from the corresponding marginal totals.
O—Observed number E--- Expected number
λ 2 =6.64 =6.64 ( Critical ratio with1d.f.at 1 %level of significance.)
0.01.
i.e., p =
When the expected number in any cell is less than 5
which may happen in case of small samples and
rare events,continuity correction has to be applied in
the formula as given below :x
2
O E
2
E
(O-E) should be replaced by
O E 0.5
Since the sample sizes in males and females are
larger and the expected numbers in all the four cells
are more than 5 , continuity correction need not be
applied for this data.
Conclusions :
i.e., The association between sex of the child and
nutritional status is statistically significant at 5%
level .
Proportion of male children with normal nutrition
is significantly higher ( 25 % ) than that of female
children( 11 % ) .
This statement can be made with 99 % confidence .
In case of 2*2 contingency table , statistical significance of association can
be tested by applying Proportion test also :-
(2) Proportion Test:
z
1 1 1
2 n1 n2
1 1 1
2 n1 n2
1 1
pq
n1 n2
p1 p2
p
p1n1 p2 n2
n1 n2
q (1 p)
is to be included in the formula only in case of small sample
sizes
and if the expected number in any cell is less than 5.
z
(0.25 0.11)0.01
0.0543
=2.58 = CR of 2.58 at 1 % level of significance (p =0.01)
i.e,Proportion of male children with normal
nutrition is significantly higher ( 25 % ) than that
of female children( 11 % ) .
This statement can be made with 99 %
confidence
(3) 2n Table:
In the example giving data on the Nutritional grading of
children, there are four nutritional groups ( N,Gr I,
Gr II , Gr. III & Gr. IV ) and two sexes ( Males & Females )
Degrees of freedom = (4-1) * (2-1) = 3
λ 2= 12.54 > 11.35 ( p < 0.01 )
i.e. Association between sex and Nutritional grading of
children is statistically significant at 1 % level of significance
( Confidence = 99 % )
(4) Matched λ 2 test :
To test the significance of the association between two
categorical variables in correlated samples Matched λ 2
due to McNemar has to be applied.
McNemar`s λ 2 = {( b-c)-1 }2/ (b+c)
‘ – 1 ‘ need to be included in the formula when
the sample size is small.
The data in the table given below gives the results ( + ve &
- ve ) of two tests ,TA & TB ,done on 100 subjects to
diagnose the presence of a certain disease . TA is the
existing test which is expensive and TB is the new test
,which is comparatively cheaper.It has to be investigated
whether the results of the two tests are statistically
comparable or not so that , if found comparable test A can
be replaced by the less expensive test B
Example:
T-A ( Expensive , but confirmative )
+
-
8 ( a)
12 (c )
20
8 (b)
72 (d)
80
Total
T-B
( cheap )
+
Total
16(16%)
84(84%)
100
McNemar`s λ 2 = 0.8 i.e., the discrepancy in the results is
statistically not significant .
The results of the two tests agree well. Test A can be replaced
by test B.
NON-PARAMETRIC
STATISTICAL METHODS
The meaning of the word “ Science “ as given in the
dictionary is “ the truth ascertained by observation ,
experiment and induction . “
A vast amount of time , money and energy is being
spent by society today in the pursuit of Science knows,
the processes of observation, experiment and induction
do not always lay bare the “ Truth “.
One experiment with one set of
observations may be lead two scientists
to two different conclusions.
The purpose of the body of the
method known as “ STATISTICS “ is
to provide the means for measuring
the amount of subjectivity that goes
into the scientist’s conclusion.
•This is accomplished by setting up a theoretical
model for the experiment in terms of probability.
•Laws of probability are applied to this model in
order to determine what the (chance) ‘
probabilities’ are for various possible outcomes of
the experiment, under the assumption that chance
alone determines the outcome of the experiment.
•Then the experimenter has an objective basis for
deciding whether the fact was the result of the
treatment that was applied or whether it could
have occurred by chance alone!
•
Although it is sometimes difficult to describe an
appropriate theoretical model for the experiment,
the real difficulty often comes after the model
has been defined in the form of finding the
probabilities associated with the model.
Many reasonable models have been invented for
which probability solutions have been found. This
body of Statistics, i.e., applying the probability
model for making inferences from the sample of
experiment in order to arrive at valid conclusion
- known as ‘ PARAMETRIC STATISTICAL
METHODS ‘
Student`s t test ---F test
In parametric method, exact solutions for the
approximately suitable probability model are found.
However, in the late 1930s, a different approach to the
problem of finding probability began to gather momentum.
This approach involves making few changes in the model
and using simple unsophisticated methods to find out the
desired probability.
Thus, approximate solutions to the exact problems were
found as opposed to the exact solution to approximate
problem.
This new package of Statistical Methods became to be
known as “ NON PARAMETRIC METHODS “
Advantages of Non parametric statistics
over parametric statistics :
1. Simpler Models
2. Easy Computability
3. No assumption on the form of population
distribution of the variable.
4. No need of larger sample for making
inferences.
In case of applying parametric inferences model, the
specific form of distribution of the variable in the
population is required.
Also, the computability is sometimes not easier and
hence not quicker.
However randomness of the sample is required in
applying non parametric methods as in case of
parametric methods.
There are no parameters such as mean and standard
deviation in the Non-parametric models and hence it is
called NON-PARAMETRIC METHODS
Since the assumption of specific form of distribution
of the variable is not required, Non parametric
methods are also known as
‘ DISTRIBUTION FREE METHODS ‘
Since non-parametric methods are based on
RANKS it is also called RANKING METHODS
OR ORDER STATISTICS
Since the development of nonparametric
methods has been taken place only
recently, no comparable methods have
been developed for all the inference
methods which are used in parametric
methods.
However, most of the commonly used
parametric inference methods have got
corresponding non-parametric methods.
:-
Non Parametric methods may be applied when :-1. The form of distribution of the values of the
variable in the population (s) is not known.
2.
Sample size is very small.
3. The researcher does not have the mathematical
background to understand and apply the parametric
methods. Of course, this is not a compromise.
4. The researcher would like to make inference as
quickly as possible.
It has been shown by some researchers that the Power of
many Non parametric methods is lesser compared to the
corresponding parametric methods.
Hence, it is suggested that one should try his best to apply
the parametric inference methods if the conditions for
applying such methods are met with .
This can be achieved by suitable transformation of the
values of the variables.
If all these approaches fail, then the only method of arriving
at conclusions with some validity and robustness is by
applying the non-parametric methods.
1. Wilcoxon’s Rank Sum test :
For testing whether two independent samples
with respect to a variable come from the same
population or not.
i.e, “ does one population tend to yield larger
values than the other population
do the two Medians are equal or not .
Corresponds to the Normal test (Z) or the student’s
‘t” test for two independent samples.
2. Wicoxon’s Signed Rank test :
For testing whether the differences observed in
the values of the variable between two
correlated populations ( before and after Design )
are statistically different or not.
Corresponds to the Paired ‘t’ test in parametric
methods.
3. Kruskal Wally`s One-way
Analysis of Variance:
For testing whether several independent
samples come from the same population or not.
Corresponds to One - way Analysis of Variance
in parametric method.
4.Friedman`s Two-way Analysis of
Variance :
For testing whether the differences observed
in the values of the variable between different
time periods are statistically significant or not.
Corresponds to the Two-way Analysis of
Variance in parametric methods.
All the Non parametric methods can be applied
manually by ranking the observations appropriately
and doing simple computation.
Computer packages :---
BMDP, SPSS, SAS and SYSTAT
Statistical Estimation:
Parametric
1. Representative
Non-Parametric
Mean, Median
Mode
Median, Mode
2. Variation
Standard Deviation
(SD)
Quartile Deviation,
Range.
3. Correlation
Pearson’s Product
Moment-corr.
Coefficient ()
4. Intervals for
the estimate
Mean SD
Value
Spearman’s
Rank Corr.
Coefficient ()
Quartiles (Q10-Q90), Percentiles(P3-P97)
Statistical Tests of Significance
1. Comparison between two independent populations :
Parametric
Non-Parametric
Continuous :
Z-test
t-test
Wilcoxon’s Rank
Sum test
Discrete
Z-test
2-test
:
2.Comparison between two Correlated populations :
Parametric
Non parametric
Continuous : Paired ‘t’ test
Discrete
---
Wilcoxon’s Signed Rank test
McNemar’s 2-test
3. Comparison among several independent
populations:
Parametric Non Parametric
Continuous :
Discrete
One- way Anova
---
Kruskal Wally`s One- way Anova
2-test
4. Comparison among several correlated
populations:
Parametric
Continuous :
Discrete
Non parametric
Two- way Anova Freidman’s Two-way
---
McNemar’s
Anova
2-test
EXAMPLES :
( A) Independent samples:
Intelligent quotient ( IQ ) of 5 normally nourished
children(NN) and 4 malnourished children(MN), aged 4
years, are given below:--NN--------- 60 , 80 , 120 , 130 , 100
MN-------- 50 , 60 , 100 , 45
Null hypothesis-- IQs in the two groups are statistically the
same , on an average.
On applying Wilcoxon`s Rank sum test
using statistical software p =0.11
Since p is greater than 0.05 ,the difference
in IQ values in the two groups is
statistically not significant and the
hypothesis of identical IQ values, on
average ,in the two groups is accepted .
( B ) Paired ( repeated ) samples:
IQ Values
Before ( b ) :-- 40 60 55 65 43 70 80
After ( a3 )
50 80 50 70 40 60 90
60
85
On applying Wilcoxon`s Rank sum test using the statistical
software p=0.18
Since p value is greater than 0.05 , the difference in IQ
values after giving the diet for three months is not
statistically significant and the Null hypothesis(Ho ) of no
difference in IQ after giving the diet is accepted. –
( C ) Independent samples---more than
two groups :
Intelligent quotient ( IQ ) of 5 normally nourished children
( NN), 4 moderately malnourished children(MN) and 5 severely
malnourished children
( MN ) , aged 4 years, are given below:--NN--------- 60 , 80 , 120 , 130 , 100
MN-------- 50 , 60 , 100 , 45
SN -------- 50 , 40 , 60 , 35 , 65
On applying Kruskal Wally`s One-way Analysis of
variance, p=0.0438.
i.e, The differences in IQ among the three groups on
an average, are statistically significant. On applying
Multiple range test ,it can be inferred that the
differences in IQ between NN & MN and between MN
& SN are statistically not significant and the
difference between NN & SN is significant at 5 % level.
( D ) Paired(repeated ) samplesmore than two occasions:
IQ of 8 malnourished children of 4 years of age ,before and
after giving some Nutritious diet for three months ( a3 )
and for six months ( a6 ) are given below :--Before ( b ) :-- 40 60 55
After ( a3 ) :-- 50 80 50
After ( a6 ) :-- 70 90 100
65 43 70 80
70 40 60 90
90 75 65 70
60
85
120
On applying Freidman`s Two-way Analysis of
variance , p=0.093
i.e, the differences in IQ after giving nutritious
food for three and six months are statistically not
significant.
Giving Nutritious food for three or six months is
not effective in increasing the IQ.
WISH YOU ALL
A VERY
FRUITFUL
USEFUL AND
MEANINGFUL
RESEARCH .
THANK YOU