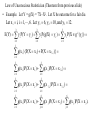Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Random Variables
• A random variable is simply a real-valued function defined on
the sample space of an experiment.
• Example. Three fair coins are flipped. The number of heads, Y,
that appear is a random variable. Let us list the sample space, S.
Sample Point
(H,H,H)
No. of Heads, Y
3
Probability
1/8
(H,H,T)
(H,T,H)
(T,H,H)
(H,T,T)
2
2
2
1
1/8
1/8
1/8
1/8
(T,H,T)
(T,T,H)
(T,T,T)
1
1
0
1/8
1/8
1/8
Example, continued.
• P{Y = 0} = P({s|Y(s) = 0}) = P{(T,T,T)} = 1/8
• P{Y = 1} = P({s|Y(s) = 1}) = P{(H,T,T),(T,H,T),(T,T,H)} = 3/8
• P{Y = 2} = P({s|Y(s) = 2}) = P{(H,H,T),(H,T,H),(T,H,H)} = 3/8
• P{Y = 3} = P({s|Y(s) = 3}) = P{(H,H,H)} = 1/8
• Since Y must take on one of the values 0, 1, 2, 3, we must have
3
3
1 P {Y i} P{Y i},
i 0
i 0
and this agrees with the probabilities listed above.
Cumulative distribution function of a random variable
• For a random variable X, the function F defined by
F(t) P{X t}, t ,
is called the cumulative distribution function, or simply, the
distribution function. Clearly, F is a nondecreasing function of t.
• All probability questions about X can be answered in terms of the
cumulative distribution function F. For example,
P{X a} 1 F(a)
P{a X b} F(b) F(a) for all a b.
Proof of P{a X b} F(b) F(a) for all a b.
• For sets A and B, where B A, P(A B) = P(A) P(B).
• Let A = {s| X(s)
b},
B = {s| X(s) a}, a < b.
• A B = {s| a< X(s) b}.
• P(A B) = P(A) P(B) = F(b) – F(a).
Properties of the cumulative distribution function
• For a random variable X, the cumulative distribution function
(c. d. f.) F was defined by F(x) P{X x}, x .
• 1. F is non decreasing.
2. lim F(b) 1.
b
3. lim F(b) 0.
b
4. F is right continuous.
• The previous properties of F imply that
P(X a) F(a) F(a ).
Example of a distribution function
• Suppose that a bus arrives at a station every day between 10am
and 10:30am, at random. Let X be the arrival time.
t - 10
P(X t)
2( t 10), 10 t 10.5
10.5 - 10
• Therefore, the distribution function is:
0, t 10
F(t) 2(t 10), 10 t 10.5
1, t 10.5
Discrete vs. Continuous Random Variables
• If a set is in one-to-one correspondence with the positive
integers, the set is said to be countable.
• If the number of values taken on by a random variable is either
finite or countable, then the random variable is said to be
discrete. The number of heads which appear in 3 flips of a
coin is a discrete random variable.
• If the set of values of a random variable is neither finite nor
countable, we say the random variable is continuous. The
random variable defined as the time that a bus arrives at a
station is an example of a continuous random variable.
• In Chapter 5, the random variables are discrete, while in
Chapter 6, they are continuous.
Probability Mass Function
• For a discrete random variable X, we define the probability
mass function p(a) of X by
p(a) P{X a}.
• If X is a discrete random variable taking the values x1, x2, …,
then
p(x i ) 1.
i 1
• Example. For our coin flipping example, we plot p(xi) vs. xi:
p(x)
0.375
0.25
0.125
x
0
1
2
3
Example of a probability mass function on a countable set
• Suppose X is a random variable taking values in the positive
integers.
1
• We define p(i) = i for i = 1, 2, 3, …
2
• Since
p(i) 1,
this defines a probability mass function.
i 1
• P(X is odd) = sum of heights of red bars = 2/3 and
• P(X is even) = sum of heights of blue bars = 1/3.
Cumulative distribution function of a discrete random variable
• The distribution function of a discrete random variable can be
expressed as
F(a)
p(x),
all x a
where p(a) is the probability mass function.
• If X is a discrete random variable whose possible values are
x1, x2, x3 …, where x1<x2< x3 …, then its distribution function is a
step function. That is, F is constant on the intervals [xi-1, xi) and
then takes a step (or jump) of size p(xi) at xi. (See next slide for an
example).
Random variable Y, number of heads, when 3 coins are tossed
Probability Mass
Function
Cumulative Distribution
Function
Random variable with both discrete and continuous features
• Define random variable X as follows:
(1) Flip a fair coin
(2) If the coin is H, define X to be a randomly selected
value from the interval [0, 1/2].
(3) If the coin is T, define X to be 1.
The cdf for X is derived next.
• For t < 0, P(X t) = 0 follows easily.
• For 0 t 1 2, P(X t) = P(X t| coin is H)∙P(coin is H)
= (2t)∙(1/2) = t
• For 1 2 t 1, P(X t) = P(X 1/2) = 1/2.
• For t 1, P(X t) = P(X 1/2) + P(X = 1) = 1/2 + 1/2 = 1.
CDF for random variable X from previous slide
• Let the cdf for X be F. Then
0, t 0
F(t)
t, 0 t 1 2
1 , 1 t 1
2
2
1, t 1
Expected value of a discrete random variable
• For a discrete random variable X having probability mass function
p(x), the expectation or expected value of X, denoted by E(X), is
defined by
E(X) xp(x).
x:p(x) 0
• We see that the expected value of x is a weighted average of the
possible values that x can take on, each value being weighted by
the probability that x assumes it. The expectation of random
variable X is also called the mean of X and the notation µ = E(X)
is used.
• Example. A single fair die is thrown. What is the expectation of
the number of dots showing on the top face of the die? Let X be
the number of dots on the top face. Then
E(X) 1 (1 / 6) 2 (1 / 6) 3 (1 / 6)
4 (1 / 6) 5 (1 / 6) 6 (1 / 6) 21 / 6 3.5.
Intuitive idea of expectation of a discrete random variable
• The expected value of a random variable is the average value that
the random variable takes on. If for some game, E(X) = 0, then the
game is called fair.
• For random variable X, if half the time X = 0 and the other half of
the time X = 10, then the average value of X is E(X) = 5.
• For random variable Y, if one-third of the time Y = 6 and twothirds of the time Y = 15, then the average value of Y is E(Y) = 12.
• Let Z be the amount you win in a lottery. If you win a million
dollars with probability 10-6 and it costs you $2 for a ticket, your
expected winnings are E(Z) = 999998(10-6) + (–2)(1 – 10-6) =
–1 dollars.
Pascal’s Wager—First Use of Expectation to Make a Decision
• Suppose we are unsure of God’s existence, so we assign a
probability of ½ to existence and ½ to nonexistence.
• Let X be the benefit derived from leading a pious life.
• X is infinite (eternal happiness) if God exists, however we lose
a finite amount (d) of time and treasure devoted to serving God
if He doesn’t exist.
• E(X) = 12 d 12 .
• Thus, the expected return on piety is positive infinity.
Therefore, says Pascal, every reasonable person should follow
the laws of God.
Expectation of a function of a discrete random variable.
• Theorem. If X is a discrete random variable that takes on one of
the values xi, i 1, with respective probabilities p(xi), then for any
real-valued function g,
E(g(X)) g(x i )p(x i ).
i
• Corollary. For real numbers a and b,
E(ag1 (X) bg 2 (X)) aE(g1 (X)) bE(g 2 (X)).
• Example. Let X be a random variable which takes the values
–1, 0, 1 with probabilities 0.2, 0.5, and 0.3, respectively. Let g(x)
= x2. We have that g(X) is a random variable which takes on the
values 0 and 1 with equal probability. Hence,
E(g(X)) g( 1)p( 1) g(0)p(0) g(1)p(1)
1 (0.2) 0 (0.5) 1 (0.3) 0.5.
• Note that E(X 2 ) (E(X)) 2 .
Law of Unconscious Statistician (Theorem from previous slide)
• Example. Let Y = g(X) = 7X–X2. Let X be outcome for a fair die.
Let x i i, i 1,,6. Let y1 6, y 2 10, and y3 12.
3
3
3
i 1
i 1
i 1
E(Y) y i P(Y y i ) y i P(g(X) y i ) y i P(X g -1 (y i ))
3
g(x ){P(X x ) P(X x
i 1
i
i
3
7 -i
)}
3
g(x )P(X x ) g(x )P(X x
i 1
i
i
3
i 1
3
g(x )P(X x ) g(x
i 1
i
i
3
i 1
7 -i
6
g(x )P(X x ) g(x
i 1
i
i
i
j 4
7 -i
)
)P(X x 7-i )
6
j
)P(X x j ) g(x j )P(X x j ).
j1
Determining Insurance Premiums
• Suppose a 36 year old man wants to buy $50,000 worth of term
life insurance for a 20-year term.
• Let p36 be the probability that this man survives 20 more years.
• For simplicity, assume the man pays premiums for 20 years. If
the yearly premium is C/20, where C is the total of the premiums
the man pays, how should the insurance company choose C?
• Let the income to the insurance company be X. We have
E(X) C p36 50000 (1 p36 )
50000 (1 p 36 )
.
• For the company to make money, C
p 36
Variance and standard deviation of a discrete random variable
• The variance of a discrete random variable X, denoted by Var(X),
is defined by
Var(X) E[(X E(X)) 2 ].
The variance is a measure of the spread of the possible values of X.
• The quantity X Var(X) is called the standard deviation of X.
• Example. Suppose X has value k, k > 0, with probability 0.5 and
value –k with probability 0.5. Then E(X) = 0 and Var(X) = E(X2)
= k2. Also, the standard deviation of X is k.
Keno versus Bolita
• Let B and K be the amount that you win in one play of Bolita
and Keno, respectively. (See Example 4.26 in the textbook.)
• E(B) = –0.25 and E(K) = –0.25
• In the long run, your losses are the same with the two games.
• Var(B) = 55.69 and Var(K) = 1.6875
• Based on these variances, we conclude that the risk with Keno
is far less than the risk with Bolita.
More about variance and standard deviation
• Theorem. Var(X) = E(X2) – (E(X))2.
• Theorem. For constants a and b,
Var(aX b) a 2 Var(X), and
aX b | a | X .
• Problem. If E(X) = 2 and E(X2) = 13, find the variance of
–4X+12.
Solution. Var(X) = E(X2) – (E(X))2 = 13 – 4 = 9.
Var( 4X 12) 16Var(X) 144.
• Definition. E(Xn) is the nth moment of X.
Standardized Random Variables
• Let X be a random variable with mean and standard
deviation . The random variable X* = (X )/ is called
the standardized X.
• It follows directly that E(X*) = 0 and Var(X*) = 1.
• Standardization is particularly useful if two or more random
variables with different distributions must be compared.
• Example. By using standardization, we can compare the home
run records of Babe Ruth and Barry Bonds.