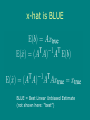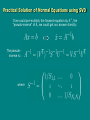Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Linear Regression Statistical Anecdotes: Do hospitals make you sick? Student’s story Etymology of “regression” Andy Jacobson July 2006 Linear Regression Statistical Anecdotes: Do hospitals make you sick? Student’s story Etymology of “regression” Andy Jacobson July 2006 Outline 1. 2. 3. 4. 5. 6. Discussion of yesterday’s exercise The mathematics of regression Solution of the normal equations Probability and likelihood Sample exercise: Mauna Loa CO2 Sample exercise: TransCom3 inversion http://www.aos.princeton.edu/WWWPUBLIC/ sara/statistics_course/andy/R/ corr_exer.r 18 July practical mauna_loa.r Today’s first example transcom3.r Today’s second example dot-Rprofile Rename to ~/.Rprofile (i.e., home dir) hclimate.indices.r cov2cor.r ferret.palette.r Get SOI, NAO, PDO, etc. from CDC Convert covariance to correlation Use nice ferret color palettes geo.axes.r Format degree symbols, etc., for maps load.ncdf.r Quickly load a whole netCDF file svd.invert.r mat4.r svd_invert.m atm0_m1.mat R-intro.pdf faraway_pra_book.pdf Multiple linear regression using SVD Read and write Matlab .mat files (v4 only) Multiple linear regression using SVD (Matlab) Data for the TransCom3 example Basic R documentation Julian Faraway’s “Practical Regression and ANOVA in R” book Multiple Linear Regression Basis Set Data Parameters Basis Functions “Design matrix” A gives values of each basis function at each observation location. Basis Functions Observations Note that one column of (e.g., ai1) may be all ones, to represent the “intercept”. From the Cost Function to the Normal Equations “Least squares” optimization minimizes sum of squared residuals (misfits to data). For the time being, we assume that the residuals are IID: Expanding terms: Cost is minimized when derivative w.r.t. x vanishes: Rearranging: Optimal parameter values (note that ATA must be invertible): x-hat is BLUE BLUE = Best Linear Unbiased Estimate (not shown here: “best”) Practical Solution of Normal Equations using SVD If we could pre-multiply the forward equation by A-1, the “pseudo-inverse” of A, we could get our answer directly: For every M x N matrix A, there exists a singular value decomposition (SVD): S is diagonal and contains the Singular Values The columns of U and V are orthogonal to one another: The pseudoinverse is thus: U is M x M S is N x N V is N x N Practical Solution of Normal Equations using SVD If we could pre-multiply the forward equation by A-1, the “pseudo-inverse” of A, we could get our answer directly: The pseudoinverse is: where Practical Solution of Normal Equations using SVD If we could pre-multiply the forward equation by A-1, the “pseudo-inverse” of A, we could get our answer directly: The pseudoinverse is: And the parameter uncertainty covariance matrix is: with Gaussian Probability and Least Squares Residuals vector: Observations Predictions Probability of ri : Likelihood of r : N.B.: Only true if residuals are uncorrelated (independent). Maximum Likelihood Log-Likelihood of r : Goodness-of-fit: 2 for N-M degrees of freedom has a known distribution, so regression models such as this can be judged on the probability of getting a given value of 2. Probability and Least Squares • Why should we expect Gaussian residuals? Random Processes z1 <- runif(5000) Random Processes hist(z1) Random Processes z1 <- runif(5000) z2 <- runif(5000) What is the distribution of (z1 + z2) ? Triangular Distribution hist(z1+z2) Central Limit Theorem There are more ways to get a central value than an extreme one. Probability and Least Squares • Why should we expect Gaussian residuals? (1) Because the Central Limit Theorem is on our side. (2) Note that the LS solution is always a minimum variance solution, which is useful by itself. The “maximum-likelihood” interpretation is more of a goal than a reality. Weighted Least Squares: More General “Data” Errors Minimizing the 2 is equivalent to minimizing a cost function containing a covariance matrix C of data errors: The data error covariance matrix is often taken to be diagonal. This means that you put different levels of confidence on different observations (confidence assigned by assessing both measurement error and amount of trust in your basis functions and linear model). Note that this structure still assumes independence between the residuals. Covariate Data Errors Recall cost function: Now allow off-diagonal covariances in C. N.B. ij = ji and ii = i2. Multivariate normal PDF: J propagates without trouble into the likelihood expression. Minimizing J still maximizes the likelihood Fundamental Trick for Weighted and Generalized Least Squares Transform system (A,b,C) with data covariance matrix C into system (A’,b’,C’), where C’ is the identity matrix: The Cholesky decomposition computes a “matrix square root” such that if R=chol(C), then C=RR. You can then solve the Ordinary Least Squares problem A’x = b’, using for instance the SVD method. Note that x remains in regular, untransformed space.