Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Multiple testing and false discovery rate in
feature selection
Workflow of feature selection using highthroughput data
General considerations of statistical testing
using high-throughput data
Some important FDR methods
Benjamini-Hochberg FDR
Storey-Tibshirani’s q-value
Efron et al.’s local fdr
Ploner et al.’s Multidimensional local fdr
Gene/protein/metabolite expression data
After all the pre-processing, we have a feature by sample matrix of
expression indices.
It is like an molecular “fingerprint” of each sample.
The most common use: to find biomarkers of a disease.
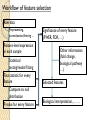
Workflow of feature selection
Raw data
Preprocessing,
normalization,filtering …
Feature-level expression
in each sample
Statistical
testing/model fitting
Test statistic for every
feature
Compare to null
distribution
P-value for every feature
Significance of every feature
(FWER, FDR, …)
Other information
(fold change,
biological pathway
…)
Selected features
Biological interpretation, … …
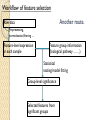
Workflow of feature selection
Another route.
Raw data
Preprocessing,
normalization,filtering …
Feature-level expression
in each sample
Feature group information
(biological pathway ……)
Statistical
testing/model fitting
Group-level significance
Selected features from
significant groups
Gene/protein/metabolite expression data
The simplest strategy:
Assume each gene is independent from others.
Perform testing between treatment groups for every gene.
Select those that are significant.
When we do 50,000 t-tests, if the alpha level of 0.05 is
used, we expect ~50,000x0.05 = 2,500 false-positives !
If we use Bonferonni’s correction? 0.05/50000= 1e-6
Unrealistic!
General considerations
Family-wise error rate (FWER)
When we have multiple tests, let V be the number of
true nulls called significant (false positives)
FWER = P(V ≥ 1) = 1-P(V=0)
“Family”: a group of hypothesis that are similar in
purpose, and need to be jointly accurate.
Bonferroni correction is one version of FWER control.
It is the simplest and most conservative approach.
General considerations
Control every test at the level α/m
For each test,
P(Ti significant | H0) ≤ α/m
Then
P(some T are significant | H0) ≤ α
i.e.
FWER = P(V ≥ 1) ≤ α
It has little power to detect differential expression
when m is big.
References
Non-technical Reviews:
Gusnanto A, Calza S, Pawitan Y. Curr Opin Lipidol 2007; 18:187-193.
Pounds SB. Brief Bioinf 2005; 7(1): 25-36.
Saeys Y, Inza I, Larranaga P. Bioinformatics 2007, 23 (19): 2507-2517.
Original papers:
Benjamini Y, Hochberg Y. JRSS B 1995; 57(1):289–300.
Storey JD, Tibshirani R. Proc Natl Acad Sci U S A 2003; 100:9440–
9445.
Efron B. Ann Stat 2007; 35(4):1351-137.
Ploner A, Calza S, Gusnanto A, Pawitan Y. Bioinf 2006;22(5):556-565.
(A number of figures were taken from these papers.)
General considerations
Significant
Nonsignificant
No change
V
U
Q
Differentially
expressed
S
T
M-Q
R
M-R
M
Simultaneously test M hypotheses.
Q is # true null – genes that didn’t change (unobserved)
R is # rejected – genes called significant (observed)
U,V, T, S are unobservable random variables.
V: number of type-I errors; T: number of type-II errors.
General considerations
Signific
ant
Nonsignifican
t
No change
V
U
Q
Differentially
expressed
S
T
M-Q
R
M-R
M
In traditional testing, we consider just one test, from a
frequentist’s point of view.
we control the false positive rate: E(V/Q)
Sensitivity: E[S/(M-Q)]
Specificity: E[U/Q]
Signific
ant
Nonsignifica
nt
No change
False
positive
True
negative
Total
true
negative
Differentially
expressed
True
positive
False
negative
Total
true
positive
Total
positive
calls
Total
negative
calls
total
General
considerations
There is always the
trade-off between
sensitivity and specificity.
Receiver operating
characteristic (ROC) curve.
Example from Jiang et al. BMC
Bioinformatics 7:417.
General considerations
http://upload.wikimedia.org/wikipedia/en/b/b4/Roc-general.png
General considerations
Significant
Nonsignificant
No change
V
U
Q
Differentially
expressed
S
T
M-Q
R
M-R
M
False discovery rate (FDR) = E(V/R)
Among all tests called significant, what percentage are false
calls?
General considerations
Significant
Nonsignificant
No change
5
49795
49800
Differentially
expressed
95
105
200
100
49900
50000
It makes more sense than this, which leans too
heavily towards sensitivity:
Significant
Nonsignificant
No change
320
49480
49800
Differentially
expressed
180
20
200
500
49500
50000
General considerations
Significant
Nonsignificant
No change
5
49795
49800
Differentially
expressed
95
105
200
100
49900
50000
It makes more sense than this, which leans too
heavily towards specificity:
Significant
Nonsignificant
No change
1
49799
49800
Differentially
expressed
14
186
200
15
49985
50000
Was the BH definition the first? No.
Defined in 1955….
True discovery rate
True positive rate
False positive rate
http://en.wikipedia.org/wiki/Precision_and_recall
FDR – BH procedure
Testing m hypotheses:
The p-values are:
Order the p-values such that:
Let q* be the level of FDR we want to control,
Find the largest i such that
Make the corresponding p-value the cutoff value, the FDR is
controlled at q*.
FDR – BH procedure
The method assumes weak dependence between test statistics.
In computation, it can be simplified by taking mP(i)/i and compare
to q*.
Intuitively,
mP(i) is the number of false-positives expected if the cutoff is P(i)
If the cutoff were P(i), then we select the first i features.
So, mP(i)/i is the expected fraction of false-positives – the FDR.
FDR – BH procedure
Higher power
compared to FWER
controlling methods:
ST q-value
FDR = E[V/(V+S)] = E[V/R]
Let t be the threshold on pvalue, then with all p-values
observed,V and R become
functions of t.
Signific
ant
Nonsignificant
No change
V
U
Q
Differentially
expressed
S
T
M-Q
R
M-R
M
V(t) = # {null pi ≤ t}
R(t) = # {pi ≤ t}
FDR(t) = E[V(t)/R(t)] ≈ E[V(t)]/E[R(t)]
For R(t), we can simply plug in # {pi ≤ t};
For V(t), true null p-values should be uniformly distributed.
ST q-value
V(t) = Qt
However, Q is unknown.
Let π0=Q/M
Signific
ant
Nonsignificant
No change
V
U
Q
Differentially
expressed
S
T
M-Q
R
M-R
M
Now, try to find π0.
Without specifying the
distribution of the
alternative p-values, but
assuming most of them are
small, we can use areas of
the histogram that’s
relatively flat to estimate π0
Density of p-values
λ
Significan
Nont
significant
ST q-value
This procedure involves
tuning the parameter λ.
With most alternative pvalues at the smaller end,
the estimated
Should stabilize when λ is
above a certain value.
No change
V
U
Q
Differentially
expressed
S
T
M-Q
R
M-R
M
ST q-value
“The more mathematical definition of the q value is the minimum
FDR that can be attained when calling that feature significant”
Given a list of ordered p-values, this guarantees the corresponding
q-values are increasing in the same order as the p-values.
The q-value procedure is robust against weak dependence between
features, which “can loosely be described as any form of
dependence whose effect becomes negligible as the number of
features increases to infinity.”
ST q-value
ST q-value
Efron’s Local fdr
The previous versions of FDR make statements about features falling
on the tails of the distribution of the test statistic. However they
don’t make statements about and individual feature, i.e. how likely is
this feature false-positive given its specific p-value ?
------------------------------Efron’s local FDR uses a mixture model and the empirical Bayes
approach. An empirical null distribution is put in the place of the
theoretical null.
With z being the test statistic, local FDR:
Efron’s Local fdr
The test statistic come from a mixture of two distributions:
The exact form of f1() is not specified. It is required to be longertailed than f0().
We need the empirical null. But we only have a histogram from the
mixture. So the null comes in a strong parametric form.
And we need the proportion p0, the Bayes a priori probability.
Efron’s Local fdr
One way to estimate
in the R package locfdr “central matching”:
Use quadratic form to approximate
Efron’s Local fdr
6033 test statistics
Efron’s Local fdr
Now we have the null distribution and the proportion. Define the
null subdensity around z:
The Bayes posterior probability that a case is null given z,
Compare to other forms of Fdr that focus on tail area,
(the c.d.f.s of f0 and f1)
Fdr(z) is the average of fdr(Z) for Z<z
Efron’s Local fdr
A real data example. Notice most non-null cases (bars plotted
negatively) are not reported. A big loss of sensitivity to control FDR,
which is very common.
Multidimensional Local fdr
A natural extension to the local FDR.
Use more than one test statistics to capture different
characteristics of the features. Now we have a
multidimensional mixture model.
Comment:
Remember the “curse of dimensionality” ? Since we don’t
have too many realizations of the non-null distribution, we
can’t go beyond just a few, say 2, dimensions.
Multidimensional Local fdr
Using t-statistic in one dimension and the log standard error in
the other.
Simulated:
Genes with small s.e. tend to have higher FDR.
This approach discounts genes with too small s.e. – similar to the
fold change idea but in a theoretically sound way.
Multidimensional Local fdr
The null distribution is generated by permutation:
Permute the treatment labels of each sample, and re-compute
the test statistics.
Repeat 100 times to obtain the null distribution f0(z).
The f(z) is obtained by the observed Z.
Like local FDR, smoothing is involved. Here two densities in 2D
need to be obtained by smoothing. In 2D, the points are not as
dense as in 1D. So the choice of smoothing parameters becomes
more consequential.
Multidimensional Local fdr
To address the problem, the authors did smoothing on the ratio
(details skipped):
p is the number of permutations.
Afterwards, the local fdr is estimated by:
Multidimensional Local fdr
Real data:
Multidimensional Local fdr
Using other statistics: