Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
8. Code Generation
• Generate executable code for a target machine
that is a faithful representation of the semantics
of the source code
• Depends not only on the characteristics of the
source language but also on detailed information
about the target architecture, the structure of
the runtime environment, and the operating
system running on the target machine
Contents
8.1 Intermediate Code and Data Structure for code
Generation
8.2 Basic Code Generation Techniques
8.9 A Survey of Code Optimization Techniques
8.1 Intermediate Code and Data
Structures for Code Generation
• A data structure that represents the source program during
translation is called an intermediate representation, or IR, for
short
• Such an intermediate representation that resembles target
code is called intermediate code
– Intermediate code is particularly useful when the goal of the compiler
is to produce extremely efficient code;
– Intermediate code can also be useful in making a compiler more easily
retarget-able.
• Study two popular forms of intermediate code: Three Address code and P-code
8.1.1 Three-Address Code
• The most basic instruction of three-address code is designed to
represent the evaluation of arithmetic expressions and has the
following general form:
X = y op z
• Here op may be an arithmetic operator such as + or – or can
be any other operator on the values of y and z
• The name “three-address code” comes from this form of
instruction.
• x, y and z represents an address in memory.
• The use of address of x differs from the use of the addresses of
y and z and that y and z may represent constants or literal
values with no runtime address.
2*a+(b-3) with syntax tree
+
*
2
-
ab
3
The corresponding three-address code is
T1 = 2 * a
T2 = b – 3
T3 = t1 + t2
TAC for FOR LOOP
FOR LOOP
in 3 TA code
a=3;
b=4;
for(i=0;i<n;i++){
a=b+1;
a=a*a;
}
c=a;
a=3;
b=4;
i=0;
L1:
L4:
L2:
L3:
VAR1=i<n;
if(VAR1) goto L2;
goto L3;
i++;
goto L1;
VAR2=b+1;
a=VAR2;
VAR3=a*a;
a=VAR3;
goto L4
c=a;
TAC for while LOOP
WHILE Loop
in 3 TA code
a=3;
b=4;
i=0;
while(i<n){
a=b+1;
a=a*a;
i++;
}
c=a;
a=3;
b=4;
i=0;
L1:
VAR1=i<n;
if(VAR1) goto L2;
goto L3;
L2:
VAR2=b+1;
a=VAR2;
VAR3=a*a;
a=VAR3;
i++;
goto L1
TAC for DO while LOOP
DO WHILE Loop
in 3 TA code
a=3;
b=4;
i=0;
do{
a=3;
b=4;
i=0;
L1:
VAR2=b+1;
a=VAR2;
VAR3=a*a;
a=VAR3;
i++;
a=b+1;
a=a*a;
i++;
}while(i<n);
c=a;
VAR1=i<n;
if(VAR1) goto L1;
goto L2;
L2:
c=a;
Figure 8.1 Sample TINY program:
{ sample program
in TINY language -- computes factorial
}
read x ;
if 0 > x then
fact:=1;
repeat
fact:=fact*x;
x:=x-1
until x=0;
write fact
ends
• The Three-address codes for above TINY program
read x
t1=x>0
if_false t1 goto L1
fact=1
label L2
t2=fact*x
fact=t2
t3=x-1
x=t3
t4= x= =0
if_false t4 goto L2
write fact
label L1
halt
8.1.2 Data Structures for the Implementation
of Three-Address Code
• The most common implementation is to
implement three-address code as quadruple,
which means that four fields are necessary:
– One for the operation and three for the addresses
• A different implementation of three-address code
is called a triple:
– Use the instructions themselves to represent the
temporaries.
• It requires that each three-address instruction be
reference-able, either as an index in an array or as
a pointer in a linked list.
• Quadruple implementation for the threeaddress code of the previous example
(rd, x , _ , _ )
(gt, x, 0, t1 )
(if_f, t1, L1, _ )
(asn, 1,fact, _ )
(lab, L2, _ , _ )
(mul, fact, x, t2 )
(asn, t2, fact, _ )
(sub, x, 1, t3 )
(asn, t3, x, _ )
(eq, x, 0, t4 )
(if_f, t4, L2, _)
(wri, fact, _, _ )
(lab, L1, _ , _ )
(halt, _, _, _ )
read x ;
if 0 > x then
fact:=1;
repeat
fact:=fact*x;
x:=x-1
until x=0;
write fact
ends
•
C code defining data structures for the
quadruples
Typedef enum { rd, gt, if_f, asn, lab, mul, sub, eq, wri, halt, …}
OpKind;
Typedef enum { Empty, IntConst, String } AddrKind;
Typedef struct
{ AddrKind kind;
Union
{ int val;
char * name;
} contents;
} Address
Typedef struct
{ OpKind op;
Address addr1, addr2, addr3;
} Quad
8.2.3 Generation of Target Code
from Intermediate Code
• Code generation from intermediate code involves
either or both of two standard techniques:
– Macro expansion and Static simulation
• Macro expansion involves replacing each kind of
intermediate code instruction with an equivalent
sequence of target code instructions.
• Static simulation involves a straight-line
simulation of the effects of the intermediate code
and generating target code to match these effects.
Code Optimization
• Need of Optimization
• Classification of Optimization
– Peep hole optimization
– Local optimization
– Loop optimization
– Global optimization
– Interprocedural optimization
Code Optimization
• Themes of behind Optimization Techniques
– Avoid redundancy
– Less Code
– Straight line codes , Fewer jumps
– Code locality
8.9.1 Principal Sources of Code
Optimizations
(1) Register Allocation
Good use of registers is the most important
feature of efficient code.
a) Increase the number and speed of operations that
can be performed directly on memory.
Once it has exhausted the register space, can
avoid the expense of having to reclaim registers
by storing register values into temporary
locations and loading new values.
b) Decrease the number of operations that can be
performed directly in memory.
at the same time increase the number of
available registers to 32, 64, or 128
(2) Unnecessary Operations
The second major source of code
improvement is to avoid generating code for
operations that are redundant or
unnecessary.
Common sub-expression elimination
Unreachable code or Dead Code
Jump Optimizations
(3) Costly Operations
A code generator should not only look for
unnecessary operations, but should take
advantage of opportunities to reduce the cost
of operations that are necessary,
but may be implemented in cheaper ways than
the source code or a simple implementation
might indicate.
Reduction in strength
Constant Folding
Procedure inlineing
Tail Recursion Removal
Use of Machine Idioms or Instruction Selection
(4) Prediction Program Behavior
To perform some of the previously described
optimizations, a compiler must collect
information about the uses of variables, values
and procedures in programs: whether
expressions are reused, whether or when
variables change their values or remain constant,
and whether procedures are called or not.
A different approach is taken by some compilers
in that statistical behavior about a program is
gathered from actual executions and the used
to predict which paths are most likely to be
taken, which procedures are most likely to be
called often, and which sections of code are
likely to be executed the most frequently.
8.9.2 Classification of Optimizations
• Two useful classifications are the time during the
compilation process when an optimization can be
applied and the area of the program over which
the optimization applies:
– The time of application during compilation.
Optimizations can be performed at practically every
stage of compilation.
• For example, constant folding….
– Some optimizations can be delayed until after target
code has been generated-the target code is examined
and rewritten to reflect the optimization.
• For example, jump optimization….
• The majority of optimizations are performed
either during intermediate code generation, just
after intermediate code generation, or during
target code generation.
• To the extent that an optimization does not
depend on the characteristics of the target
machine (called source-level optimizations)
• They can be performed earlier than those that do
depend on the target architecture (target-level
optimizations).
• Sometimes both optimizations do.
• Consider the effect that one optimization may have on
another.
• For instance, propagate constants before performing
unreachable code elimination. Occasionally, a phase
problem may arise in that each of two optimizations may
uncover further opportunities for the other.
• For example, consider the code
x = 1;
...
y = 0;
...
if (y) x = 0;
...
if (x) y = 1;
• A first pass at constant propagation might result
in the code
x = 1;
...
y = 0;
...
if (0) x = 0;
...
if (x) y = 1;
• Now, the body of the first if is unreachable code;
eliminating it yields:
x = 1;
...
y = 0;
...
if (x) y = 1;
• The second classification scheme for
optimizations that we consider is by the area of
the program over which the optimization applies
• The categories for this classification are called
local, global and inter-procedural optimizations
(1)Local optimizations: applied to straight-line
segments of code(code sequence with no jumps
into or out of the sequence), or
basic blocks(maximum sequence of a straight line
code).
(2)Global optimizations: applied beyond the basic
block, but confined to an individual procedure.
(3)Inter-procedural optimizations: beyond the
boundaries of procedures to the entire program.
8.9.3 Data Structures and Implementation
Techniques for Optimizations
• Some optimizations can be made by transformations
on the syntax tree itself
– Including constant folding and unreachable code
elimination.
– However the syntax tree is an unwieldy or unsuitable
structure for collecting information and performing
optimizations
• An optimizer that performs global optimizations will
construct from the intermediate code of each
procedure
– A graphical representation of the code called a flow graph.
– The nodes of a flow graph are the basic blocks, and the
edges are formed from the conditional and unconditional
jumps.
– Each basic block node contains the sequence of
intermediate code instructions of the block.
• A single pass can construct a flow graph, together
with each of its basic blocks, over the
intermediate code
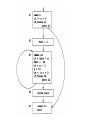
• Each new basic block is identified as follows:
– The first instruction begins a new basic block;
– Each label that is the target of a jump begin a
new basic block;
– Each instruction that follows a jump begins a
new basic block;
read x
t1=x>0
if_false t1 goto L1
fact=1
label L2
t2=fact*x
fact=t2
t3=x-1
x=t3
t4= x= =0
if_false t4 goto L2
write fact
label L1
halt
• A standard data flow analysis problem is to
compute, for each variable, the set of reaching
definitions of that variable at the beginning of each
basic block.
– Here a definition is an intermediate code instruction that
can set the value of the variable, such as an assignment or
a read
• Another data structure is frequently constructed for
each block, called the DAG of a basic block.
– DAG traces the computation and reassignment of values
and variables in a basic block as follows.
– Values that are used in the block that come from
elsewhere are represented as leaf nodes.
• Operations on those and other values are
represented by interior nodes.
– Assignment of a new value is represented by
attaching the name of target variable or temporary
to the node representing the value assigned
• For example:
• Repeated use of the same value also is represented in the
DAG structure.
• For example, the C assignment x = (x+1)*(x+1) translates
into the three-address instructions:
t1 = x + 1
t2 = x + 1
t3 = t1 * t2
x = t3
• DAG for this sequence of instructions is given, showing the
repeated use of the expression x+1
• The DAG of a basic block can be constructed by
maintaining two dictionaries.
– A table containing variable names and constants, with
a lookup operation that returns the DAG node to which
a variable name is currently assigned.
– A table of DAG nodes, with a lookup operation that,
given an operation and child node
• Target code, or a revised version of intermediate
code, can be generated from a DAG by a traversal
according to any of the possible topological sorts
of the nonleaf nodes.
t3 = x - 1
t2 = fact * x
x = t3
t4 = x == 0
fact = t2
Of course, wish to avoid the unnecessary use of temporaries, and so would want to
generate the following equivalent three-address code, whose order must remain
fixed:
fact = fact * x
x=x-1
t4 = x == 0
the C assignment x = (x+1)*(x+1)
translates into the three-address
instructions:
t1 = x + 1
t2 = x + 1
t3 = t1 * t2
x = t3
A similar traversal of the DAG of above Figure results in the following
revised three-address code:
t1 = x + 1
x = t1 * t1
Using DAG to generate target code for a basic block, we automatically get
local common sub expression elimination
The DAG representation also makes it possible to eliminate redundant
stores and tells us how many references to each value there are