Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
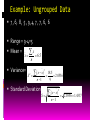
CHAPTER 1 Basic Statistics Statistics in Engineering Collecting Engineering Data Data Summary and Presentation Probability Distributions - Discrete Probability Distribution - Continuous Probability Distribution Sampling Distributions of the Mean and Proportion STATISTICS IN ENGINEERING Statistics is the area of science that deals with collection, organization, analysis, and interpretation of data. It also deals with methods and techniques that can be used to draw conclusions about the characteristics of a large number of data points, commonly called a population. By using a smaller subset of the entire data called sample. Because many aspects of engineering practice involve working with data, obviously some knowledge of statistics is important to an engineer. Specifically, statistical techniques can be a powerful aid in designing new products and systems, improving existing designs, and improving production process. Engineers apply physical and chemical laws and mathematics to design, develop, test, and supervise various products and services. Engineers perform tests to learn how things behave under stress, and at what point they might fail. As engineers perform experiments, they collect data that can be used to explain relationships better and to reveal information about the quality of products and services they provide. Collecting Engineering Data Direct observation The simplest method of obtaining data. Advantage: relatively inexpensive Drawbacks: difficult to produce useful information since it does not consider all aspects regarding the issues. Experiments More expensive methods but better way to produce data Data produced are called experimental Surveys Most familiar methods of data collection Depends on the response rate Personal Interview Has the advantage of having higher expected response rate Fewer incorrect respondents. Data Presentation Data can be summarized or presented in two ways: 1. Tabular 2. Charts/graphs. The presentations usually depends on the type (nature) of data whether the data is in qualitative (such as gender and ethnic group) or quantitative (such as income and CGPA). Data Presentation of Qualitative Data Tabular presentation for qualitative data is usually in the form of frequency table that is a table represents the number of times the observation occurs in the data. The most popular charts for qualitative data are: 1. bar chart/column chart; 2. pie chart; and 3. line chart. Example: frequency table Observation Malay Chinese Indian Others Frequency 33 9 6 2 Bar Chart: used to display the frequency distribution in the graphical form. Pie Chart: used to display the frequency distribution. It displays the ratio of the observations Malay Chinese Indian Others Line chart: used to display the trend of observations. It is a very popular display for the data which represent time. Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 10 7 5 10 39 7 260 316 142 11 4 9 Tabular presentation for quantitative data is usually in the form of frequency distribution that is a table represent the frequency of the observation that fall inside some specific classes (intervals) There are few graphs available for the graphical presentation of the quantitative data. The most popular graphs are: 1. histogram; 2. frequency polygon; and 3. ogive. Frequency Distribution When summarizing large quantities of raw data, it is often useful to distribute the data into classes. There are no specifics rules to determine the classes size and the number of individual belonging to each class. Example: Frequency Distribution CGPA (Class) Frequency 2.50 - 2.75 2 2.75 - 3.00 10 3.00 - 3.25 15 3.25 - 3.50 13 3.50 - 3.75 7 3.75 - 4.00 3 Histogram: Looks like the bar chart except that the horizontal axis represent the data which is quantitative in nature. There is no gap between the bars. Frequency Polygon: looks like the line chart except that the horizontal axis represent the class mark of the data which is quantitative in nature. Ogive: line graph with the horizontal axis represent the upper limit of the class interval while the vertical axis represent the cummulative frequencies. Data Summary Summary statistics are used to summarize a set of observations. Two basic summary statistics are measures of central tendency and measures of dispersion. Measures of Central Tendency Mean Median Mode Measures of Dispersion Range Variance Standard deviation Measures of Central Tendency Mean Mean of a sample is the sum of the sample data divided by the total number sample. Mean for ungroup data is given by: _ x x1 x2 ....... xn x , for n 1,2,..., n or x n n _ Mean for group data is given xby: n x fx fx or f f i 1 n i 1 i i i Median: The middle value after the data is arranged from the lowest to the highest value. If the number of data is even, median is the average of the two middle values. Mode: The value with the highest frequency in a data set. *It is important to note that there can be more than one mode and if no number occurs more than once in the set, then there is no mode for that set of numbers. Example-> Example: Ungrouped Data Example: Grouped Data CGPA(x) Frequency(f) fx 2.625 2 5.250 2.875 10 28.750 3.125 15 46.875 3.375 13 43.875 3.625 7 25.375 3.875 3 11.625 Total 50 161.750 n Mean: x fx i 1 n i i f i 1 161.75 3.235 50 i Median:(3.125+3.375)/2=3.25 Mode:3.125 Measures of Dispersion Range = Largest value – smallest value Variance: measures the variability (differences) existing in a set of data. The variance for the ungrouped data: 2 ( x x ) S2 n 1 The variance for the grouped data: S 2 fx 2 2 nx n 1 The positive square root of the variance is the standard deviation S ( x x) n 1 2 fx 2 2 nx n 1 A large variance means that the individual scores (data) of the sample deviate a lot from the mean. A small variance indicates the scores (data) deviate little from the mean. Example: Ungrouped Data 7 , 6, 8, 5 , 9 ,4, 7 , 7 , 6, 6 Range = 9-4=5 Mean = x x 6.5 _ n Variance= S 2 2 ( x x ) n 1 Standard Deviation= S 18.5 2.0556 9 2 ( x x ) n 1 2.0556 1.4337 Using excel and click data analysis, choose descriptive statistics to get the data summary result. Column1 Mean 6.5 Standard Error Median Mode 0.453 6.5 7 Standard Deviation 1.434 Sample Variance Kurtosis Skewness Range Minimum Maximum Sum Count 2.056 0.239 0 5 4 9 65 10 Example: Grouped Data x 4 3 2 1 0 f 10 12 8 6 4 n Mean, x fx i 1 n f i 1 5 Variance i 1 2.45 i fi xi 2 nx 2 n 1 10 4 12 3 8 2 6 1 4 0 40 2.45 2 i i 2 1.69 Std 1.69 1.30 2 2 39 2 2