Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
OPERATING SYSTEMS
DESIGN AND IMPLEMENTATION
Third Edition
ANDREW S. TANENBAUM
ALBERT S. WOODHULL
Chapter 2
Processes
The Process Model (1)
Figure 2-1 (a) Multiprogramming of four programs.
The Process Model (2)
Figure 2-1 (b) Conceptual model of
four independent, sequential processes.
The Process Model (3)
Figure 2-1 (c) Only one program is active at any instant.
Process Creation
Principal events that cause processes to be created:
1. System initialization.
2. Execution of a process creation system call by a running
process.
3. A user request to create a new process.
4. Initiation of a batch job.
Process Termination
Conditions that cause a process to terminate:
1. Normal exit (voluntary).
2. Error exit (voluntary).
3. Fatal error (involuntary).
4. Killed by another process (involuntary).
Process States (1)
Possible process states:
1. Running
(actually using the CPU at that instant).
2. Ready
(runnable; temporarily stopped to let another process run).
3. Blocked
(unable to run until some external event happens).
Process States (2)
Figure 2-2 A process can be in running, blocked, or ready state.
Transitions between these states are as shown.
Process States (3)
Figure 2-3 The lowest layer of a process-structured operating
system handles interrupts and scheduling. Above that layer
are sequential processes.
Implementation of Processes
Figure 2-4. Some of the fields of the MINIX 3 process table.
The fields are distributed over the kernel,
the process manager, and the file system.
Process States (2)
What causes (1) to occur?
–
Process makes blocking system call – wait for event
What causes (2)?
–
Process runs out of time quantum
What causes (3)?
–
Scheduler picks the ready process to get CPU, dispatches it
What causes (4)?
–
Event process was waiting on occurs – often an interrupt
Stack needed
By service routine
Interrupts
In table of addresses
indexed by interrupt #
pointing to handler code
Figure 2-5 Skeleton of what the lowest level of the operating
system does when an interrupt occurs.
Threads (1)
Figure 2-6 (a) Three processes each with one thread. Thread is a
sequence of instruction execution – a path through the code
is the static version of this – that is running (has state)
Each thread has its own program counter and registers, etc.
Threads (1.5)
Process creation:
Expensive (copy entire image)
Often run same code – can save space and time if text
segment is shared
Often want shared objects as well – for coordination and for
communication
=> Share data segment as well (less copying)
Child process shares same owner, etc. - much of process
table entry is also shared
Threads - “Lightweight processes”
Idea is to copy only what must be individual to separate
execution sequence: stack, program counter, etc.
Much faster to create and destroy
Threads (2)
Figure 2-6 (b) One process with three threads.
Each thread has its own program counter and registers, etc.
Threads (3)
Figure 2-7. The first column lists some items shared by all
threads in a process. The second one lists some items
private to each thread.
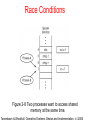
Race Conditions
Figure 2-8 Two processes want to access shared
memory at the same time.
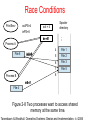
Race Conditions
PrintServ
outPS=4
Spooler
directory
out = 4
inPS=6
...
in = 8
6
7
Process A
File 53
inA=8
inA=7
inA=6
Process B
4
File 1
5
File 2
6
File 3
7
8
File 5
4
inB=7
inB=8
File 4
Figure 2-8 Two processes want to access shared
memory at the same time.
Race Condition Example
Load–Store atomicity: Loads and stores occur atomically
X = X+1 translates to machine instructions:
–
–
–
Load X location contents into register
increment register
store register in X location
Lost Update:
P1 runs and loads X;
P2 runs and loads X, increments register, stores into X;
P1 runs again, increments register, stores into X
Race Condition Example (2)
P1
Load A, X
P2
Load A, X
Incr A
Sto A, X
Incr A
Sto A, X
If initial value of X was 0, final value of X is 1, not 2.
Critical Sections
Necessary to avoid race conditions:
1. No two processes may be simultaneously inside their
critical regions. (Safety)
2. No assumptions may be made about speeds or the
number of CPUs.
3. No process running outside its critical region may block
other processes. (Liveness)
4. No process should have to wait forever to enter its
critical region. (Liveness)
Synchronization Criteria
Safety – what MUST NOT happen to avoid disaster
–
e.g., No two processes may be simultaneously inside their
critical regions
Liveness – what MUST happen to keep everyone happy
–
–
e.g., No process running outside its critical region may block
other processes
e.g., No process should have to wait forever to enter its critical
region
The exact nature of these depend on system, but generally
want to avoid deadlock and starvation
Deadlock = no processes can proceed
Starvation = some process waits indefinitely
Synchronization Code
Generic Structure of a Process using a CS:
Process () {
while (TRUE) {
Other()
/* arbitrarily long time outside CS */
Entry()
/* code to make sure it's OK to enter */
Critical Section()
/* risky business */
Exit()
/* code to let others know I'm done */
}
}
Synchronization Code
Generic Code for a System of Processes:
Main () {
init_vars()
/* initialize shared variables */
for (i=0; i<NUM_PROCS; i++) {
StartProc(i)
/* fork and run process i */
}
for (i=0; i<NUM_PROCS; i++) {
WaitProc(i)
/* wait for process i to terminate */
}
}
Processes may all be the same, or they may be of various
types (depending on nature of system), or they may do
one thing sometimes and something else other times;
BUT they all execute entry and exit codes for critical sections
Mutual Exclusion
Figure 2-9 Mutual exclusion using critical regions.
Synchronization Mechanisms
Basic flavors of synchronization mechanisms:
Busy waiting (spin locks) – S/W or H/W based
Semaphores (scheduling based) – OS support
Monitors – language support
Message-based – OS support
... others as well ...
Mutual Exclusion with Busy Waiting
With busy waiting, B may be using the CPU while “blocked” and
so A can't leave critical region (until A gets CPU)
Mutual Exclusion with Busy Waiting
A enters critical region
A's quantum runs out
A leaves critical region
Process A
B's quantum runs out
B tries to enter critical region
B enters critical region
Process B
T1
T2
T3
B wastes CPU time busy waiting
T4
T5
B leaves critical region
With busy waiting, B may be using the CPU while “blocked” and
so A can't leave critical region (until A gets CPU)
Strict Alternation
Where is entry code?
Tight spin on turn
Where is exit code?
What is so bad about this solution?
Figure 2-10. A proposed solution to the critical region problem.
(a) Process 0. (b) Process 1. In both cases, be sure to note
the semicolons terminating the while statements.
Peterson’s Solution (1)
{ ...
Figure 2-11 Peterson’s solution for achieving mutual exclusion.
Peterson’s Solution (2)
Figure 2-11 Peterson’s solution for achieving mutual exclusion.
H/W: The TSL Instruction
Figure 2-12. Entering and leaving a critical region
using the TSL instruction.
Generic Synchronization Code
Process (i) {
while (TRUE) {
Other(i)
/* arbitrarily long time outside CS */
Entry(i)
/* code to make sure it's OK to enter */
Critical Section()
/* risky business */
Exit(i)
/* code to let others know I'm done */
}
}
Key point: Often want to allow multiple processes to do
dangerous stuff at the same time, but the entry and
exit code prevents bad stuff from happening – i.e., not
always critical region problem
Classic Synchronization Problems
Critical Section Problem: Mutual exclusion – only one
process can be in CS at a time
Producer-Consumer Problem: Producers can write items
into buffers at the same time Consumers are
consuming other items, but two Producers must not
write into same buffer at the same time, two
Consumers must not consume the same item, and a
Consumer must not consume an item until a Producer
has finished writing it, nor may a Producer write an
item into a buffer before a Consumer has finished
emptying that buffer
Bounded Buffer Problem: P-C with finite # buffers
Readers-Writers: Any number of readers can read from a
DB simultaneously, but writers must access it alone
Dining Philosophers: See below
The Producer-Consumer Problem (1)
...
Figure 2-13. The producer-consumer problem
with a fatal race condition.
The Producer-Consumer Problem (2)
...
So what is (are) the problem(s)?
Figure 2-13. The producer-consumer problem
with a fatal race condition
Flaws in P-C Solution
Several ways things can go wrong:
1 – Corrupt shared variables indicating how many empty
buffers and/or how many full buffers there are
2 – Two producers try to fill same buffer
3 – Two consumers try to empty same buffer
4 – Producer and consumer try to access same buffer
Semaphores
Semaphores are a special type of shared memory:
1 – A semaphore S can only be declared and initialized, or
accessed by Up(S) or Down(S);
NO direct access
2 – When Down(S) is called, if S > 0, S-- and continue;
otherwise block the caller and put on S's queue Q
3 – When Up(S) is called, if Q empty, S++ and continue;
otherwise remove a process P from Q and unblock P
4 – Up() never blocks
5 – A process blocked on Down() does not use the CPU
Semaphores Types and Uses
Binary Semaphores: take only values 0 or 1
Uses:
–
Initialized to 1, used for mutual exclusion (a
process does Down(mutex); CS; Up(mutex) )
–
Initialized to 0, used for synchronization (one
process does Down(S) to wait for another
process to reach a point in its code where it does
Up(S) )
Multivalued Semaphores: take integer values >= 0
Uses:
–
Initialized to N, where N is the number of
instances of a shared resource
–
Up(S) to release an instance, Down(S) to take
one
The Producer-Consumer Problem (3)
...
Figure 2-14. The producer-consumer problem
using semaphores.
The Producer-Consumer Problem (4)
...
Figure 2-14. The producer-consumer problem
using semaphores.
Comments on P-C Solution
Concurrency issues solution must handle:
1 – Corrupt shared variables indicating how many empty
buffers and/or how many full buffers there are
2 – Two producers try to fill same buffer
3 – Two consumers try to empty same buffer
4 – Producer and consumer try to access same buffer
Semaphore solution given solves (1) by ...
counting semaphores,
solves (2)-(4) by
using a mutex
Timing Diagram of P-C Soln
P1
P2
P3
C1
C2
C1 must wait for a full buffer; P2 (et al.) must wait for P1 to finish
copying item into buffer1; P3 must wait until there is an empty
buffer, etc.
Running/ready
outside CS
Blocked
waiting for CS
Running/ready
inside CS
Comments on P-C Solution (2)
But solution does not permit maximum concurrency:
only one process can insert or remove item at a time
Why is this potentially an issue?
What if items are very large, and take a long time to
insert or remove?
So, what can we do about it????
Better
P-C
Solution
Producer() {
while (TRUE) {
Produce(item)
/* arbitrarily long time */
Get_Empty(&buffer)
/* find an empty buffer */
CopyTo(item,&buffer)
/* could take a while */
Alert_Full(&buffer)
/* tell consumers */
}
}
Consumer() {
while (TRUE) {
Get_Full(&buffer)
/* find a full buffer */
CopyFrom(item,&buffer)
/* could take a while */
Alert_Empty(&buffer)
/* tell consumers */
Consume(item)
/* arbitrarily long time */
}
}
Better P-C Solution (2)
Get_Empty(&buffer) {
down(&empty)
/* wait for empty buffer to be available */
down(&mutex)
/* only one process touches control vars */
buffer=find_empty_buffer()
/* find a buffer marked empty*/
Mark_Busy(&buffer) /* buffer is neither full nor empty */
up(&mutex)
}
Alert_Full(&buffer) {
down(&mutex)
/* only one process touches control vars */
Mark_Full(&buffer)
/* this buffer is full */
up(&mutex)
up(&full)
/* let consumers know a full buffer is available */
}
Better P-C Solution (2)
Get_Full(&buffer) {
down(&full)
/* wait for an item to be available */
down(&mutex)
/* only one process touches control vars */
buffer=find_full_buffer()
/* find a buffer marked full */
Mark_Busy(&buffer)
/* buffer is neither full nor empty */
up(&mutex)
}
Alert_Empty(&buffer) {
down(&mutex)
/* only one process touches control vars */
Mark_Empty(&buffer)
/* this buffer is empty */
up(&mutex)
up(&empty)
/* let producers know an empty buffer is available */
}
Timing Diagram Better P-C Soln
Full:
Empty:
Busy:
0 0 0 01 0 01 0 00 1 1 1 1 1 2 3
5 4 3 22 2 22 2 23 3 2 2 1 2 2 2
0 1 2 32 3 32 3 32 1 2 2 3 2 1 0
Starting with N=5
Empty buffers
P1
P2
P3
C1
C2
C1 must wait for a full buffer; P2 (et al.) must wait for P1 to find
buffer1, but can find buffer2 while P1 fills buffer1, etc.
Running/ready
outside CS
Running/ready
buffer access
Blocked
waiting for CS
Running/ready
inside CS
Comments on Better P-C Solution
Semaphore solution only allows one process in the buffer
store at a time (uses counting semaphores to make
sure that they will find what they are after)
Better P-C solution has copy operations OUTSIDE critical
regions – allows multiple processes to access different
buffers concurrently
The two “Get” procedures must
–
–
–
Find an idle buffer in the right state (full or empty)
Mark that buffer as BUSY so nobody else uses it
Return location to caller
The two “Alert” procedures must
–
–
Mark buffer as FULL or EMPTY
Signal other processes by up on counting semaphore
All four Get and Alert procedures are themselves CS's
But the Copy procedures are NOT exclusive!
Monitors (0)
Monitors are a language construct
– With spin locks and semaphores, programmer must
remember to obtain lock/semaphore, and to release
the same lock/semaphore when done: this is prone to
errors!
– Monitor acts like an Abstract Data Type or Object – only
access internal state through public methods, called
entry procedures
– Monitor guarantees that at most one process at a time is
executing in any entry procedure of that monitor
– What if a process can't continue while in entry proc?
Condition Variables
Monitors are a language construct
– What if a process can't continue while in entry proc?
– Condition “variables” local to monitor allow a process to
block until another process signals that condition
– Unlike semaphores, condition vars have NO memory!
– If no process is waiting on the condition, signaling the
condition variable has NO effect at all!
– A process that waits on a condition variable can be
awakened and resume execution in entry procedure
– So what about the process that woke the waiting
process up?
- May force it to wait (on a stack), or
- May require it to leave entry procedure
Monitors (1)
Figure 2-15. A monitor.
Monitors (2)
Figure 2-16. An outline of the
producer-consumer problem
with monitors. Only one
monitor procedure at a
time is active. The buffer
has N slots
Monitors (3)
Figure 2-16. An outline of the producer-consumer problem with
monitors. Only one monitor procedure at a time is active.
The buffer has N slots
Comments on Sync Mechanisms
Shared memory solutions – either software only or
hardware supported (TSL or swap) have spin-locks;
shared memory location can be accessed directly
(read/written); “blocked” process consumes CPU
cycles
Semaphores – requires OS support – scheduling based;
semaphores CANNOT be accessed directly, only
through UP() and DOWN(), and semaphore values are
persistent; heavier cost than spin-lock code (system
call); blocked process does not consumer CPU cycles
Condition Variables – within monitor construct (language
support needed); scheduling based (blocked process
does not use CPU); condition “variables” are more like
signals and queues – they are NOT persistent and can
not be accessed directly, only through wait and signal
Message Passing (1)
...
Figure 2-17. The producer-consumer problem with N messages.
Message Passing (2)
...
Initialize system
Figure 2-17. The producer-consumer problem with N messages.
The Dining Philosophers Problem (1)
Figure 2-18. Lunch time in the Philosophy Department.
The Dining Philosophers Problem (2)
Figure 2-19. A nonsolution to the dining philosophers problem.
The Dining Philosophers Problem (3)
...
Figure 2-20. A solution to the dining philosophers problem.
The Dining Philosophers Problem (4)
...
...
Figure 2-20. A solution to the dining philosophers problem.
The Dining Philosophers Problem (5)
...
Figure 2-20. A solution to the dining philosophers problem.
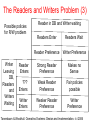
The Readers and Writers Problem (0)
Read-write and write-write conflicts cause race conditions
Must avoid them!
Reads do NOT conflict with other reads, are allowed.
Reader can access database at same time,
but writers must have exclusive access to it.
Hence, readers get read locks and writers get write locks.
Read locks are compatible with read locks, but not write locks
Write locks are not compatible with read or write locks.
Policy issues surround when readers can enter
and who gets in next when a writer leaves.
The Readers and Writers Problem (0.5)
Lock type requested
Lock type held
None
Read
Write
Read
Yes
Yes
No
Write
Yes
No
No
Lock Compatibility Matrix
The Readers and Writers Problem (1)
...
Figure 2-21. A solution to the readers and writers problem.
The Readers and Writers Problem (2)
...
Figure 2-21. A solution to the readers and writers problem.
The Readers and Writers Problem (3)
Possible policies
for R/W problem
Writer
Leaving
DB,
Readers
and
Writers
Waiting
Reader in DB and Writer waiting
Readers Enter
Readers Wait
Reader Preference
Writer Preference
Reader
Enters
Strong Reader
Preference
Makes no
Sense
???
Enters
Weak Reader
Preference
Fair policies
possible
Writer
Enters
Weaker Reader
Preference
Writer
Preference
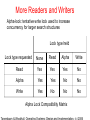
More Readers and Writers
Alpha-lock: tentative write lock used to increase
concurrency for larger search structures
Lock type held
Lock type requested
None
Read
Alpha
Write
Read
Yes
Yes
Yes
No
Alpha
Yes
Yes
No
No
Write
Yes
No
No
No
Alpha Lock Compatibility Matrix
Summary of Classical Synch Problems
Critical Section Problem
–
Symmetric – simplest problem – mutual exclusion
Producer-Consumer Problem
–
Asymmetric – wait on event from other type of process – also
have mutual exclusion for access to buffers, control variables
Dining Philosophers Problem
–
Symmetric – must wait for access to two resources – five is
smallest interesting number of philosophers
Reader-Writers Problem
–
Asymmetric – readers can share with each other, but not with
writers, writers must have exclusive access – want maximum
concurrency – many flavors depending on policies
Need for Process Scheduling
Recall process behavior...
Figure 2-22. Bursts of CPU usage alternate with periods of waiting for I/O.
(a) A CPU-bound process. (b) An I/O-bound process.
For good resource utilization, want to overlap I/O of on process with CPU burst
of another process
When to Schedule
When scheduling is absolutely required:
1. When a process exits.
2. When a process blocks on I/O, or a semaphore.
i.e. - when the running process can no longer run!
When scheduling usually done (though not absolutely
required):
1. When a new process is created.
2. When an I/O interrupt occurs.
3. When a clock interrupt occurs.
i.e., when another process has higher priority
Scheduling Algorithm Goals
Figure 2-23. Some goals of the scheduling algorithm under
different circumstances.
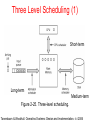
Three Level Scheduling (1)
Short-term
Long-term
Medium-term
Figure 2-25. Three-level scheduling.
Three Level Scheduling (2)
Criteria for deciding which process to choose:
• How long has it been since the process was
swapped in or out?
• How much CPU time has the process had
recently?
• How big is the process? (Small ones do not get
in the way.)
• How important is the process?
Three Level Scheduling (3)
Main goal for long-term (admission) scheduler:
• Get good mix of jobs in RAM
Main goal for medium-term (memory) scheduler:
• Prevent thrashing (more on this later)
Main goals for short-term (CPU) scheduler:
• Be efficient and fair
All share goals of:
Maximizing resource utilization
Giving best service to clients
Enforcing system policies
Scheduling Algorithm Measures
Turn-around time = Finish time – arrival time
includes time spent waiting for CPU
Mean Turn-around Time (MTT)
Average TT over all jobs
Fairness – various measures, including maximum
difference in fraction of time each job got CPU
over some period
Makespan = Finish time of last job to finish –
start time for set of jobs
Used for multiprocessor scheduling
Processor utilization = fraction of time CPU used
Turn-around Time
CPU time
A
B
B takes 4 units of time if run by itself
C
Arrival time
A takes 9 units of time if run by itself
C takes 3 units of time if run by itself
A
A arrives at time 0
B arrives at time 1
B
C
C arrives at time 2
FCFS Schedule
B arrives at time 1 C arrives at time 2
C must wait
B must wait
A finishes at time 9 B finishes at time 13
A running
Now B can run
Now C can run
B waiting
B running
C finishes at time 16
C waiting
C runs
All done!
Schedule
A arrives at time 0
A gets CPU
A
B
C
MTT= (9+12+14)/3= 35/3
TT(A) = 9 – 0 = 9
TT(B) = 13 – 1 = 12
TT(C) = 16 – 2 = 14
Scheduling Algorithms
Non-preemptive algorithms:
Running job must give up CPU/system voluntarily
First-Come First-Serve (FCFS):
• Jobs run in order of arrival
Shortest Job First (SJF):
• Ready job that will finish first is run first
Priority
• Ready job with highest priority is run first
Optimal (Crystal Ball)
• Uses future knowledge of arrivals to optimize
Shortest Job First
A arrives at time 0, take 9 units
A
B arrives at time 1, takes 4 units
B
C arrives at time 2, takes 3 units
C
What is SJF Schedule?
Schedule
A arrives at time 0
A gets CPU
C arrives at time 2
C must wait
B arrives at time 1
B must wait
A
A A
B
B
C
C goes next – why?
C has shorter run time
A finishes at time 9
Who gets CPU next?
A running
B waiting
wait…
C waiting
C runs
TT(A) = 9 – 0 = 9
C finishes at time 12
Now B runs..
And finishes at time 16
B running
TT(C) = 12 – 2 = 10
MTT= (9+10+15)/3= 34/3
TT(B) = 16 – 1 = 15
Optimal Non-preemptive
A arrives at time 0, take 9 units
A
B arrives at time 1, takes 4 units
B
C arrives at time 2, takes 3 units
C
What is Optimal Schedule? (using MTT)
Schedule
A arrives at time 0
A waits! – Why?
C arrives at time 2
C must wait – Why?
B arrives at time 1
B runs
A
B
C
A A A waits A waits
C goes next – why?
C has shorter run time
B finishes at time 5
Who gets CPU next?
A running
C finishes at time 8
Now A finally runs…
and finishes at time 17
B B runs
C waits C runs
TT(B) = 5 – 1 = 4
TT(C) = 8 – 2 = 6
MTT= (4+6+17)/3= 27/3
TT(A) = 17 – 0 = 17
Scheduling Algorithms
Preemptive algorithms:
Running job may be forced to give up
CPU/system involuntarily
Round Robin (RR):
• Jobs run in order of arrival, with maximum
quantum (go to end of queue if preempted)
Shortest Remaining Time First (SRTF):
• Ready job that will finish first is run first
Preemptive Priority
• Ready job with highest priority is run first
CTSS
• Attempts to approximate SRTF
SJF Scheduling
Figure 2-24. An example of shortest job first scheduling.
(a) Running four jobs in the original order (FCFS).
(b) Running them in shortest job (SJF) first order.
What is the mean turn-around time for the set of jobs?
A:8, B:12, C:16, D:20
Mean = 56/4 = 14
A:20, B:4, C:8, D:12
Mean = 44/4 = 11
Tanenbaum & Woodhull, Operating Systems: Design and Implementation, (c) 2006
Round-Robin Scheduling
Figure 2-26. Round-robin scheduling.
(a) The list of runnable processes.
(b) The list of runnable processes after B uses up its quantum.
For our problems in scheduling, if process C arrives at the same
time that process D uses up its quantum, C will be added to
the ready queue before D is added to it.
Round-Robin Scheduling
Process Name:
Arrival Time (AT):
CPU Burst Length (CT):
A
0
8
Arrivals-> A
E
B C
D
B
2
5
C
3
1
D
5
2
E
7
2
Quantum = 1: A A B A C B A D B E A D B E A B A A
A C B A D B E A D B E A B A
B A D B E A D B E A B
A D B E A
Turnaround times: A:18-0, B:16-2, C:7-3,
C:5-3, D:11-5,
D:12-5, E: 15-7
14-7
Average TT = (18+14+4+6+8)/5
(18+14+2+7+7)/5 = 50/5
48/5 = 10
9.6
Quantum = 2: A A B B A A C B B D D A A E E B A A
A A C C B D D A A E E B B A
C B B D A A E E B B A A
D A E E B B
FCFS, SJF, SRTF Scheduling
Process Name:
Arrival Time (AT):
CPU Burst Length (CT):
A
0
8
B
2
5
C
3
1
D
5
2
E
7
2
FCFS Schedule: A A A A A A A A B B B B B C D D E E
Turnaround times: A:8-0, B:13-2, C:14-3, D:16-5, E: 18-7
Average TT = (8+11+11+11+11)/5 = 52/5 = 10.4
SJF Schedule: A A A A A A A A C D D E E B B B B B
Turnaround times: A:8-0, B:18-2, C:9-3, D:11-5, E: 13-7
Average TT = (8+16+6+6+6)/5 = 42/5 = 8.4
SRTF Schedule: A A B C B D D E E B B B A A A A A A
Turnaround times: A:18-0, B:12-2, C:4-3, D:7-5, E: 9-7
Average TT = (18+10+1+2+2)/5 = 33/5 = 6.6
(Preemptive) Priority Scheduling
Figure 2-27. A scheduling algorithm with four priority classes.
Run a process at priority i+1 over any process at priority i
Run processes at priority i in round robin (or whatever) order
Preempt process if higher priority process arrives
Priority Scheduling
Process Name:
Priority:
Arrival Time (AT):
CPU Burst Length (CT):
A
4
0
8
B
2
2
5
C
3
3
1
D
1
5
2
E
5
7
2
Priority Schedule: A A B B B D D B B C A A A A A A E E
Turnaround times: A:16-0, B:9-2, C:10-3, D:7-5, E: 18-7
Average TT = (16+7+7+2+11)/5 = 43/5 = 8.6
Priority is usually preemptive
Scheduler is run whenever a process arrives
Scheduler runs whenever a process unblocks
Priority is most general policy
It can model any other policy by priority definition
CTSS Scheduling
CTSS used by Multics OS – try to approximate SRTF
Multi-level feedback queue –
Enter at queue 0, drop to next queue if TRO
Queue i gets 2i for time quantum, i = 0, 1, 2, ...
Process Name:
Arrival Time (AT):
CPU Burst Length (CT):
CTSS:
A
0
8
AA B C A D B
B C
-
D
C
3
1
D
5
2
E
B
D
E
-
-
E
7
2
E AAAA BB A
Q0
A -
Q1
- AA A ABB = BB BBDD BDD BDDEE DDEE EE - . . . - . -
Q2
- -
- -
- A4
=
=
=
A4B4 =
= . . . B4 . -
Q3
- -
- -
-
-
-
-
-
- . . . A8 . =
-
-
B
2
5
-
-
- . . . - . -
Turnaround times: A:18-0, B:17-2, C:4-3, D:10-5, E: 11-7
Average TT = (18+15+1+5+4)/5 = 43/5 = 8.6
Tanenbaum & Woodhull, Operating Systems: Design and Implementation, (c) 2006 Prentice-Hall, Inc. All rights reserved. 0-13-142938-8
Thread Scheduling
•
•
•
Recall that a thread is essentially an execution state
within a process.
Each thread has its own
• PC
• status register
• Stack
• State
• priority, etc.,
But shares with the other threads in the same
process
• text segment,
• data segment,
• owner, group,
• accounting information, etc.
Tanenbaum & Woodhull, Operating Systems: Design and Implementation, (c) 2006 Prentice-Hall, Inc. All rights reserved. 0-13-142938-8
Thread Scheduling
•
Two types of threads:
• User-level threads – the OS only sees the
parent process, and doesn’t know about
individual threads.
• Process is scheduled, not threads
• Threads are handled by thread run-time
support within process
• One thread blocks => the whole process
blocks.
• Kernel threads – the OS knows about the
threads and can schedule them independently,
allow each to have its own state (e.g., one may
be blocked, while another is running and others
in the same “pod” are ready).
Tanenbaum & Woodhull, Operating Systems: Design and Implementation, (c) 2006 Prentice-Hall, Inc. All rights reserved. 0-13-142938-8
Thread Scheduling (1)
(a)
Figure 2-28. (a) Possible scheduling of user-level threads with a
50-msec process quantum and threads that run 5 msec per
CPU burst.
Tanenbaum & Woodhull, Operating Systems: Design and Implementation, (c) 2006 Prentice-Hall, Inc. All rights reserved. 0-13-
Thread Scheduling (2)
(b)
Figure 2-28. (b) Possible scheduling
of kernel-level threads with the same characteristics as (a).
Multi-Core Thread Scheduling
•
•
•
User-level threads
• OS sees only the process...
• Can only schedule the process on one core
• All threads in process run on same core
Kernel threads
• OS sees the threads (has a thread table in addition to
process table)
• Can schedule different threads from same process on
different cores
• Higher overhead for scheduling
LWP/thread approach
• Sun Microsystems provided for kernel threads (LWPs –
essentially VMs) and user-level threads
• Threads assigned to LWPs, LWPs assigned to cores
Tanenbaum & Woodhull, Operating Systems: Design and Implementation, (c) 2006 Prentice-Hall, Inc. All rights reserved. 0-13-142938-8
The Internal Structure of MINIX
Figure 2-29. MINIX 3 is structured in four layers.
Only processes in the bottom layer may use
privileged (kernel mode) instructions.
MINIX 3 Startup
Figure 2-30. Some important MINIX 3 system components.
Others such as an Ethernet driver and
the inet server may also be present.
MINIX Memory (1)
top half
(See next slide)
Figure 2-31. Memory layout after MINIX 3 has been loaded
from the disk into memory. The kernel, servers, and
drivers are independently compiled and linked programs,
listed on the left. Sizes are approximate and not to scale.
MINIX Memory (2)
Figure 2-31. Memory layout after MINIX 3 has been loaded
from the disk into memory. The kernel, servers, and
drivers are independently compiled and linked programs,
listed on the left. Sizes are approximate and not to scale.
MINIX Header File
Figure 2-32. Part of a master header which ensures inclusion of
header files needed by all C source files. Note that two const.h
files, one from the include/ tree and one from the local
directory, are referenced.
Sizes of Types in MINIX
Figure 2-33. The size, in bits, of some types on
16-bit and 32-bit systems.
MINIX Message Types
Figure 2-34. The seven
message types used in
MINIX 3. The sizes of
message elements will
vary, depending upon the
architecture of the
machine; this diagram
illustrates sizes on CPUs
with 32-bit pointers, such
as those of Pentium family
members.
Debug Dump
Figure 2-35. Part of a debug dump of the privilege table. The
clock task, file server, tty, and init processes privileges are
typical of tasks, servers, device drivers, and user processes,
respectively. The bitmap is truncated to 16 bits.
Debug Dump
ID 0 is for user processes (e.g., init server)
P flag – is process/task preemptable?
SRB traps – can process use send/receive/or send_rec?
ipc_to mask – who can process send a message?
Bootstrapping MINIX (1)
Figure 2-36. Disk structures used for bootstrapping.
(a) Unpartitioned disk. The first sector is the bootblock.
Bootstrapping MINIX (2)
Figure 2-36. Disk structures used for bootstrapping.
(b) Partitioned disk. The first sector is the master
boot record, also called masterboot.
Boot Time in MINIX
Figure 2-37. Boot parameters passed to the kernel at boot time in
a typical MINIX 3 system.
System Initialization in MINIX
Figure 2-38. How alternative assembly language
source files are selected.
Interrupt Handling in MINIX (1)
Figure 2-39. Interrupt processing hardware on a 32-bit Intel PC.
Interrupt Handling in MINIX (2)
Figure 2-40. (a) How a hardware interrupt is processed.
Interrupt Handling in MINIX (3)
Figure 2-40. (b) How a system call is made.
Restart
Figure 2-41. Restart is the common point reached after system
startup, interrupts, or system calls. The most deserving process
(which may be and often is a different process from the last one
interrupted) runs next. Not shown in this diagram are
interrupts that occur while the kernel itself is running.
Queueing
Process 3 tries to send to process 0, must wait.
Process 4 also must wait.
Figure 2-42. Queuing of processes trying to send to process 0.
Scheduling in MINIX
Low
Idle process
User
processes Servers
Priority
Drivers
High
Kernel tasks
Figure 2-43. The scheduler maintains sixteen queues, one per
priority level. Shown here is the initial queuing process as
MINIX 3 starts up.
Hardware-Dependent Kernel Support
Granularity (pages/bytes)
SEGMENTS
These are
Hardware, not
VM segments.
GDT – global
(points to LDTs)
IDT – interrupts
LDT – local
(1 per process)
Limit is 20-bit quantity of bytes or 4096-byte pages
How can you tell which it is?
Base is 32-bit quantity
Why split up in such a funny way?
Backward compatibility!
Figure 2-44. The format of an Intel segment descriptor.
Overview of System Task (1)
Figure 2-45. The message types accepted by the system task.
“Any” means any system process; user processes
cannot call the system task directly
Overview of System Task (2)
Figure 2-45. The message types accepted by the system task.
“Any” means any system process; user processes
cannot call the system task directly
System Calls in MINIX 3
Figure 2-46. (a) Worst case for reading a block requires
seven messages. (b) Best case for reading a
block requires four messages.
Clock Hardware
Figure 4-47. A programmable clock.
Clock Software (1)
Typical duties of a clock driver.
1. Maintain time of day
2. Prevent processes from running longer than
allowed
3. Accounting for CPU usage
4. Handling alarm system call by user processes
5. Providing watchdog timers for parts of system
itself
6. Doing profiling, monitoring, and statistics
gathering
Clock Software (2)
Figure 2-48. Three ways to maintain the time of day.
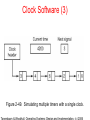
Clock Software (3)
Figure 2-49. Simulating multiple timers with a single clock.
Summary of Clock Services
Figure 2-50. The time-related services supported
by the clock driver.