Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
CS252
Graduate Computer Architecture
Lecture 14
3+1 Cs of Caching and
many ways Cache Optimizations
John Kubiatowicz
Electrical Engineering and Computer Sciences
University of California, Berkeley
http://www.eecs.berkeley.edu/~kubitron/cs252
Review: Cache performance
• Miss-oriented Approach to Memory Access:
MemAccess
CPUtime IC CPI Execution
MissRate MissPenalty CycleTime
Inst
• Separating out Memory component entirely
– AMAT = Average Memory Access Time
MemAccess
CPUtime IC CPI AluOps
AMAT CycleTime
Inst
AMAT HitTime MissRate MissPenalty
HitTime Inst MissRate Inst MissPenalty Inst
HitTime Data MissRate Data MissPenaltyData
3/16/2009
cs252-S09, Lecture 15
2
12 Advanced Cache Optimizations (Con’t)
• Reducing hit time
1. Small and simple
caches
2. Way prediction
3. Trace caches
• Reducing Miss Penalty
7. Critical word first
8. Merging write buffers
• Increasing cache
bandwidth
4. Pipelined caches
5. Multibanked caches
6. Nonblocking caches
3/16/2009
• Reducing Miss Rate
9. Victim Cache
10. Hardware prefetching
11. Compiler prefetching
12. Compiler Optimizations
cs252-S09, Lecture 15
3
3. Fast (Instruction Cache) Hit times
via Trace Cache
Key Idea: Pack multiple non-contiguous basic
blocks into one contiguous trace cache line
BR
BR
BR
BR
BR
BR
•
Single fetch brings in multiple basic blocks
•
Trace cache indexed by start address and next n
branch predictions
3/16/2009
cs252-S09, Lecture 15
4
3. Fast Hit times via Trace Cache
(Pentium 4 only; and last time?)
•
•
Find more instruction level parallelism?
How avoid translation from x86 to microops?
Trace cache in Pentium 4
1. Dynamic traces of the executed instructions vs. static sequences
of instructions as determined by layout in memory
–
Built-in branch predictor
2. Cache the micro-ops vs. x86 instructions
– Decode/translate from x86 to micro-ops on trace cache miss
+ 1. better utilize long blocks (don’t exit in middle of
block, don’t enter at label in middle of block)
- 1. complicated address mapping since addresses no
longer aligned to power-of-2 multiples of word size
- 1. instructions may appear multiple times in multiple
dynamic traces due to different branch outcomes
3/16/2009
cs252-S09, Lecture 15
5
4: Increasing Cache Bandwidth by
Pipelining
• Pipeline cache access to maintain bandwidth, but
higher latency
• Instruction cache access pipeline stages:
1: Pentium
2: Pentium Pro through Pentium III
4: Pentium 4
- greater penalty on mispredicted branches
- more clock cycles between the issue of the load
and the use of the data
3/16/2009
cs252-S09, Lecture 15
6
5. Increasing Cache Bandwidth:
Non-Blocking Caches
• Non-blocking cache or lockup-free cache allow data
cache to continue to supply cache hits during a miss
– requires F/E bits on registers or out-of-order execution
– requires multi-bank memories
• “hit under miss” reduces the effective miss penalty
by working during miss vs. ignoring CPU requests
• “hit under multiple miss” or “miss under miss” may
further lower the effective miss penalty by overlapping
multiple misses
– Significantly increases the complexity of the cache controller as
there can be multiple outstanding memory accesses
– Requires muliple memory banks (otherwise cannot support)
– Penium Pro allows 4 outstanding memory misses
3/16/2009
cs252-S09, Lecture 15
7
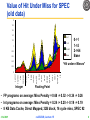
Value of Hit Under Miss for SPEC
(old data)
Hit Under i Misses
2
1.8
Avg. Mem. Access Time
1.6
1.4
0->1
1.2
1->2
1
2->64
0.8
Base
0.6
0.4
0->1
1->2
2->64
Base
“Hit under n Misses”
0.2
Integer
ora
spice2g6
nasa7
alvinn
hydro2d
mdljdp2
wave5
su2cor
doduc
swm256
tomcatv
fpppp
ear
mdljsp2
compress
xlisp
espresso
eqntott
0
Floating Point
• FP programs on average: Miss Penalty = 0.68 -> 0.52 -> 0.34 -> 0.26
• Int programs on average: Miss Penalty = 0.24 -> 0.20 -> 0.19 -> 0.19
• 8 KB Data Cache, Direct Mapped, 32B block, 16 cycle miss, SPEC 92
3/16/2009
cs252-S09, Lecture 15
8
6: Increasing Cache Bandwidth via
Multiple Banks
• Rather than treat the cache as a single monolithic
block, divide into independent banks that can support
simultaneous accesses
– E.g.,T1 (“Niagara”) L2 has 4 banks
• Banking works best when accesses naturally spread
themselves across banks mapping of addresses to
banks affects behavior of memory system
• Simple mapping that works well is “sequential
interleaving”
– Spread block addresses sequentially across banks
– E,g, if there 4 banks, Bank 0 has all blocks whose address modulo 4
is 0; bank 1 has all blocks whose address modulo 4 is 1; …
3/16/2009
cs252-S09, Lecture 15
9
7. Reduce Miss Penalty:
Early Restart and Critical Word First
• Don’t wait for full block before restarting CPU
• Early restart—As soon as the requested word of the
block arrives, send it to the CPU and let the CPU
continue execution
– Spatial locality tend to want next sequential word, so not clear size of
benefit of just early restart
• Critical Word First—Request the missed word first
from memory and send it to the CPU as soon as it
arrives; let the CPU continue execution while filling
the rest of the words in the block
– Long blocks more popular today Critical Word 1st Widely used
block
3/16/2009
cs252-S09, Lecture 15
10
8. Merging Write Buffer to
Reduce Miss Penalty
•
•
•
•
•
3/16/2009
Write buffer to allow processor to continue
while waiting to write to memory
If buffer contains modified blocks, the
addresses can be checked to see if address of
new data matches the address of a valid write
buffer entry
If so, new data are combined with that entry
Increases block size of write for write-through
cache of writes to sequential words, bytes since
multiword writes more efficient to memory
The Sun T1 (Niagara) processor, among many
others, uses write merging
cs252-S09, Lecture 15
11
9. Reducing Misses: a “Victim Cache”
• How to combine fast hit
time of direct mapped
yet still avoid conflict
misses?
• Add buffer to place data
discarded from cache
• Jouppi [1990]: 4-entry
victim cache removed
20% to 95% of conflicts
for a 4 KB direct mapped
data cache
• Used in Alpha, HP
machines
3/16/2009
TAGS
DATA
Tag and Comparator
One Cache line of Data
Tag and Comparator
One Cache line of Data
Tag and Comparator
One Cache line of Data
Tag and Comparator
One Cache line of Data
cs252-S09, Lecture 15
To Next Lower Level In
Hierarchy
12
10. Reducing Misses by Hardware
Prefetching of Instructions & Data
• Prefetching relies on having extra memory bandwidth that can be
used without penalty
• Instruction Prefetching
– Typically, CPU fetches 2 blocks on a miss: the requested block and the next
consecutive block.
– Requested block is placed in instruction cache when it returns, and
prefetched block is placed into instruction stream buffer
• Data Prefetching
1.97
3/16/2009
gr
id
eq
ua
ke
1.49
1.40
m
1.32
ap
pl
u
1.26
sw
im
1.21
ga
lg
el
fa
ce
re
c
w
up
w
is
3d
fa
m
cf
SPECint2000
1.20
e
1.18
1.16
1.29
lu
ca
s
1.45
m
2.20
2.00
1.80
1.60
1.40
1.20
1.00
ga
p
Performance Improvement
– Pentium 4 can prefetch data into L2 cache from up to 8 streams from 8
different 4 KB pages
– Prefetching invoked if 2 successive L2 cache misses to a page,
if distance between those cache blocks is < 256 bytes
SPECfp2000
cs252-S09, Lecture 15
13
Issues in Prefetching
• Usefulness – should produce hits
• Timeliness – not late and not too early
• Cache and bandwidth pollution
CPU
RF
L1
Instruction
Unified L2
Cache
L1 Data
Prefetched data
3/16/2009
cs252-S09, Lecture 15
14
Hardware Instruction Prefetching
Instruction prefetch in Alpha AXP 21064
– Fetch two blocks on a miss; the requested block (i) and the next
consecutive block (i+1)
– Requested block placed in cache, and next block in instruction
stream buffer
– If miss in cache but hit in stream buffer, move stream buffer
block into cache and prefetch next block (i+2)
Req
block
Stream
Buffer
Prefetched
instruction block
CPU
RF
3/16/2009
L1
Instruction
Req
block
cs252-S09, Lecture 15
Unified L2
Cache
15
Hardware Data Prefetching
• Prefetch-on-miss:
– Prefetch b + 1 upon miss on b
• One Block Lookahead (OBL) scheme
– Initiate prefetch for block b + 1 when block b is
accessed
– Why is this different from doubling block size?
– Can extend to N block lookahead
• Strided prefetch
– If observe sequence of accesses to block b, b+N, b+2N,
then prefetch b+3N etc.
Example: IBM Power 5 [2003] supports eight independent
streams of strided prefetch per processor, prefetching 12
lines ahead of current access
3/16/2009
cs252-S09, Lecture 15
16
Administrivia
• Exam:
This Wednesday
Location: 310 Soda
TIME: 6:00-9:00pm
– Material: Everything up to next Monday, including papers
(especially ones discussed in detail in class)
– Closed Book, but 1 page hand-written notes (both sides)
– Meet at LaVal’s afterwards for Pizza and Beverages
• We have been reading Chapter 5
– You should take a look, since might show up in test
3/16/2009
cs252-S09, Lecture 15
17
11. Reducing Misses by
Software Prefetching Data
• Data Prefetch
– Load data into register (HP PA-RISC loads)
– Cache Prefetch: load into cache
(MIPS IV, PowerPC, SPARC v. 9)
– Special prefetching instructions cannot cause faults;
a form of speculative execution
• Issuing Prefetch Instructions takes time
– Is cost of prefetch issues < savings in reduced misses?
– Higher superscalar reduces difficulty of issue bandwidth
3/16/2009
cs252-S09, Lecture 15
18
12. Reducing Misses by Compiler
Optimizations
• McFarling [1989] reduced caches misses by 75%
on 8KB direct mapped cache, 4 byte blocks in software
• Instructions
– Reorder procedures in memory so as to reduce conflict misses
– Profiling to look at conflicts(using tools they developed)
• Data
– Merging Arrays: improve spatial locality by single array of compound
elements vs. 2 arrays
– Loop Interchange: change nesting of loops to access data in order
stored in memory
– Loop Fusion: Combine 2 independent loops that have same looping
and some variables overlap
– Blocking: Improve temporal locality by accessing “blocks” of data
repeatedly vs. going down whole columns or rows
3/16/2009
cs252-S09, Lecture 15
19
Merging Arrays Example
/* Before: 2 sequential arrays */
int val[SIZE];
int key[SIZE];
/* After: 1 array of stuctures */
struct merge {
int val;
int key;
};
struct merge merged_array[SIZE];
Reducing conflicts between val & key;
improve spatial locality
3/16/2009
cs252-S09, Lecture 15
20
Loop Interchange Example
/* Before */
for (k = 0; k < 100; k = k+1)
for (j = 0; j < 100; j = j+1)
for (i = 0; i < 5000; i = i+1)
x[i][j] = 2 * x[i][j];
/* After */
for (k = 0; k < 100; k = k+1)
for (i = 0; i < 5000; i = i+1)
for (j = 0; j < 100; j = j+1)
x[i][j] = 2 * x[i][j];
Sequential accesses instead of striding through
memory every 100 words; improved spatial
locality
3/16/2009
cs252-S09, Lecture 15
21
Loop Fusion Example
/* Before */
for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)
a[i][j] = 1/b[i][j] * c[i][j];
for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)
d[i][j] = a[i][j] + c[i][j];
/* After */
for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)
{
a[i][j] = 1/b[i][j] * c[i][j];
d[i][j] = a[i][j] + c[i][j];}
2 misses per access to a & c vs. one miss per access;
improve spatial locality
3/16/2009
cs252-S09, Lecture 15
22
Blocking Example
/* Before */
for (i = 0; i < N; i = i+1)
for (j = 0; j < N; j = j+1)
{r = 0;
for (k = 0; k < N; k = k+1){
r = r + y[i][k]*z[k][j];};
x[i][j] = r;
};
• Two Inner Loops:
– Read all NxN elements of z[]
– Read N elements of 1 row of y[] repeatedly
– Write N elements of 1 row of x[]
• Capacity Misses a function of N & Cache Size:
– 2N3 + N2 => (assuming no conflict; otherwise …)
• Idea: compute on BxB submatrix that fits
3/16/2009
cs252-S09, Lecture 15
23
Blocking Example
/* After */
for (jj = 0; jj < N; jj = jj+B)
for (kk = 0; kk < N; kk = kk+B)
for (i = 0; i < N; i = i+1)
for (j = jj; j < min(jj+B-1,N); j = j+1)
{r = 0;
for (k = kk; k < min(kk+B-1,N); k = k+1) {
r = r + y[i][k]*z[k][j];};
x[i][j] = x[i][j] + r;
};
• B called Blocking Factor
• Capacity Misses from 2N3 + N2 to 2N3/B +N2
• Conflict Misses Too?
3/16/2009
cs252-S09, Lecture 15
24
Reducing Conflict Misses by Blocking
Miss Rate
0.1
Direct Mapped Cache
0.05
Fully Associative Cache
0
0
50
100
150
Blocking Factor
• Conflict misses in caches not FA vs. Blocking size
– Lam et al [1991] a blocking factor of 24 had a fifth the misses vs.
48 despite both fit in cache
3/16/2009
cs252-S09, Lecture 15
25
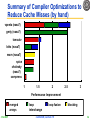
Summary of Compiler Optimizations to
Reduce Cache Misses (by hand)
vpenta (nasa7)
gmty (nasa7)
tomcatv
btrix (nasa7)
mxm (nasa7)
spice
cholesky
(nasa7)
compress
1
1.5
2
2.5
3
Performance Improvement
merged
arrays
3/16/2009
loop
interchange
loop fusion
cs252-S09, Lecture 15
blocking
26
Impact of Hierarchy on Algorithms
• Today CPU time is a function of (ops, cache misses)
• What does this mean to Compilers, Data structures,
Algorithms?
– Quicksort:
fastest comparison based sorting algorithm when keys fit in memory
– Radix sort: also called “linear time” sort
For keys of fixed length and fixed radix a constant number of passes
over the data is sufficient independent of the number of keys
• “The Influence of Caches on the Performance of
Sorting” by A. LaMarca and R.E. Ladner. Proceedings of
the Eighth Annual ACM-SIAM Symposium on Discrete
Algorithms, January, 1997, 370-379.
– For Alphastation 250, 32 byte blocks, direct mapped L2 2MB cache, 8
byte keys, from 4000 to 4000000
3/16/2009
cs252-S09, Lecture 15
27
Quicksort vs. Radix: Instructions
Quick
(Instr/key)
Radix
(Instr/key)
800
700
600
500
400
300
200
100
0
1000 1000 1E+ 1E+ 1E+
0
05
06
07
Job size in keys
3/16/2009
cs252-S09, Lecture 15
28
Quicksort vs. Radix Inst & Time
800
700
600
500
400
300
200
100
0
Time
Insts
Quick
(Instr/key)
Radix
(Instr/key)
Quick
(Clocks/key)
Radix
(clocks/key)
1000 1000 1E+ 1E+ 1E+
0
05 06 07
Job size in keys
3/16/2009
cs252-S09, Lecture 15
29
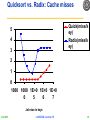
Quicksort vs. Radix: Cache misses
Quick(miss/k
ey)
Radix(miss/k
ey)
5
4
3
2
1
0
1000 1000 1E+0 1E+0 1E+0
0
5
6
7
Job size in keys
3/16/2009
cs252-S09, Lecture 15
30
Experimental Study (Membench)
• Microbenchmark for memory system performance
s
•
3/16/2009
for array A of length L from 4KB to 8MB by 2x
for stride s from 4 Bytes (1 word) to L/2 by 2x
time the following loop
(repeat many times and average)
for i from 0 to L by s
load A[i] from memory (4 Bytes)
cs252-S09, Lecture 15
1 experiment
31
Membench: What to Expect
average cost per access
memory
time
size > L1
cache
hit time
total size < L1
s = stride
• Consider the average cost per load
– Plot one line for each array length, time vs. stride
– Small stride is best: if cache line holds 4 words, at most ¼ miss
– If array is smaller than a given cache, all those accesses will hit
(after the first run, which is negligible for large enough runs)
– Picture assumes only one level of cache
– Values have gotten more difficult to measure on modern procs
3/16/2009
cs252-S09, Lecture 15
32
Memory Hierarchy on a Sun Ultra-2i
Sun Ultra-2i, 333 MHz
Array length
Mem: 396 ns
(132 cycles)
L2: 2 MB,
12 cycles (36 ns)
L1: 16 B line
L1:
16 KB
2 cycles (6ns)
L2: 64 byte line
8 K pages,
32 TLB entries
See www.cs.berkeley.edu/~yelick/arvindk/t3d-isca95.ps for details
3/16/2009
cs252-S09, Lecture 15
33
Memory Hierarchy on a Power3
Power3, 375 MHz
Array size
Mem: 396 ns
(132 cycles)
L2: 8 MB
128 B line
9 cycles
L1: 32 KB
128B line
.5-2 cycles
3/16/2009
cs252-S09, Lecture 15
34
Compiler Optimization vs. Memory
Hierarchy Search
• Compiler tries to figure out memory hierarchy
optimizations
• New approach: “Auto-tuners” 1st run variations of
program on computer to find best combinations of
optimizations (blocking, padding, …) and algorithms,
then produce C code to be compiled for that
computer
• “Auto-tuner” targeted to numerical method
– E.g., PHiPAC (BLAS), Atlas (BLAS),
Sparsity (Sparse linear algebra), Spiral (DSP), FFT-W
3/16/2009
cs252-S09, Lecture 15
35
Sparse Matrix – Search for Blocking
for finite element problem [Im, Yelick, Vuduc, 2005]
Mflop/s
Best: 4x2
Reference
3/16/2009
Mflop/s
cs252-S09, Lecture 15
36
Best Sparse Blocking for 8 Computers
8
row block size (r)
Sun Ultra 2,
Sun Ultra 3,
AMD Opteron
Intel
Pentium M
IBM Power 4,
Intel/HP Itanium
Intel/HP
Itanium 2
IBM
Power 3
4
2
1
1
2
4
column block size (c)
8
• All possible column block sizes selected for 8 computers; How could
compiler know?
3/16/2009
cs252-S09, Lecture 15
37
Technique
Hit Time
Band
width
Miss
penalty
Miss
rate
HW cost/
complexity
–
0
Trivial; widely used
Comment
Small and simple caches
+
Way-predicting caches
+
1
Used in Pentium 4
Trace caches
+
3
Used in Pentium 4
Pipelined cache access
–
1
Widely used
3
Widely used
1
Used in L2 of Opteron and
Niagara
+
Nonblocking caches
+
Banked caches
+
+
Critical word first and
early restart
+
2
Widely used
Merging write buffer
+
1
Widely used with write through
Victim Caches
–
+
1
Fairly Simple and common
+
0
+
+
2 instr.,
3 data
+
+
3
Compiler techniques to
reduce cache misses
Hardware prefetching of
instructions and data
Compiler-controlled
prefetching
3/16/2009
cs252-S09, Lecture 15
Software is a challenge; some
computers have compiler option
Many prefetch instructions; AMD
Opteron prefetches data
Needs nonblocking cache; in
many CPUs
38
Main Memory Background
• Performance of Main Memory:
– Latency: Cache Miss Penalty
» Access Time: time between request and word arrives
» Cycle Time: time between requests
– Bandwidth: I/O & Large Block Miss Penalty (L2)
• Main Memory is DRAM: Dynamic Random Access Memory
– Dynamic since needs to be refreshed periodically (8 ms, 1% time)
– Addresses divided into 2 halves (Memory as a 2D matrix):
» RAS or Row Address Strobe
» CAS or Column Address Strobe
• Cache uses SRAM: Static Random Access Memory
– No refresh (6 transistors/bit vs. 1 transistor
Size: DRAM/SRAM 4-8,
Cost/Cycle time: SRAM/DRAM 8-16
3/16/2009
cs252-S09, Lecture 15
39
Core Memories (1950s & 60s)
DEC PDP-8/E Board,
4K words x 12 bits,
(1968)
First magnetic core memory,
from IBM 405 Alphabetical
Accounting Machine.
• Core Memory stored data as magnetization in iron rings
– Iron “cores” woven into a 2-dimensional mesh of wires by hand
(25 billion a year at peak production)
– invented by Forrester in late 40s/early 50s at MIT for Whirlwind
– Origin of the term “Dump Core”
– Rumor that IBM consulted Life Saver company
• Robust, non-volatile storage
– Used on space shuttle computers until recently
– Core access time ~ 1ms
• See: http://www.columbia.edu/acis/history/core.html
3/16/2009
cs252-S09, Lecture 15
40
Semiconductor Memory, DRAM
• Semiconductor memory began to be competitive in
early 1970s
– Intel formed to exploit market for semiconductor memory
• First commercial DRAM was Intel 1103
– 1Kbit of storage on single chip
– charge on a capacitor used to hold value
• Semiconductor memory quickly replaced core in 1970s
• Today (March 2009), 4GB DRAM < $40
– People can easily afford to fill 32-bit address space with DRAM (4GB)
– New Vista systems often shipping with 6GB
3/16/2009
cs252-S09, Lecture 15
41
DRAM Architecture
Col.
1
M
word lines
Row 1
Row Address
Decoder
N
N+M
bit lines
Col.
2M
Row 2N
Column Decoder &
Sense Amplifiers
Data
Memory cell
(one bit)
D
• Bits stored in 2-dimensional arrays on chip
• Modern chips have around 4 logical banks on each chip
– each logical bank physically implemented as many smaller arrays
3/16/2009
cs252-S09, Lecture 15
42
Review:1-T Memory Cell (DRAM)
row select
• Write:
– 1. Drive bit line
– 2.. Select row
• Read:
– 1. Precharge bit line to Vdd/2
– 2.. Select row
bit
– 3. Cell and bit line share charges
» Very small voltage changes on the bit line
– 4. Sense (fancy sense amp)
» Can detect changes of ~1 million electrons
– 5. Write: restore the value
• Refresh
– 1. Just do a dummy read to every cell.
3/16/2009
cs252-S09, Lecture 15
43
DRAM Capacitors: more capacitance
in a small area
• Trench capacitors:
–
–
–
–
3/16/2009
• Stacked capacitors
Logic ABOVE capacitor
Gain in surface area of capacitor
Better Scaling properties
Better Planarization
– Logic BELOW capacitor
– Gain in surface area of capacitor
– 2-dim cross-section quite small
cs252-S09, Lecture 15
44
DRAM Operation: Three Steps
• Precharge
– charges bit lines to known value, required before next row access
• Row access (RAS)
– decode row address, enable addressed row (often multiple Kb in row)
– bitlines share charge with storage cell
– small change in voltage detected by sense amplifiers which latch
whole row of bits
– sense amplifiers drive bitlines full rail to recharge storage cells
• Column access (CAS)
– decode column address to select small number of sense amplifier
latches (4, 8, 16, or 32 bits depending on DRAM package)
– on read, send latched bits out to chip pins
– on write, change sense amplifier latches. which then charge storage
cells to required value
– can perform multiple column accesses on same row without another
row access (burst mode)
3/16/2009
cs252-S09, Lecture 15
45
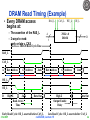
DRAM Read Timing (Example)
• Every DRAM access
begins at:
RAS_L
– The assertion of the RAS_L
– 2 ways to read:
early or late v. CAS
CAS_L
A
WE_L
256K x 8
DRAM
9
OE_L
D
8
DRAM Read Cycle Time
RAS_L
CAS_L
A
Row Address
Col Address
Junk
Row Address
Col Address
Junk
WE_L
OE_L
D
High Z
Junk
Data Out
Read Access
Time
Data Out
Output Enable
Delay
Early Read Cycle: OE_L asserted before CAS_L
3/16/2009
High Z
Late Read Cycle: OE_L asserted after CAS_L
cs252-S09, Lecture 15
46
Main Memory Performance
Cycle Time
Access Time
Time
• DRAM (Read/Write) Cycle Time >> DRAM
(Read/Write) Access Time
– 2:1; why?
• DRAM (Read/Write) Cycle Time :
– How frequent can you initiate an access?
– Analogy: A little kid can only ask his father for money on Saturday
• DRAM (Read/Write) Access Time:
– How quickly will you get what you want once you initiate an access?
– Analogy: As soon as he asks, his father will give him the money
• DRAM Bandwidth Limitation analogy:
– What happens if he runs out of money on Wednesday?
3/16/2009
cs252-S09, Lecture 15
47
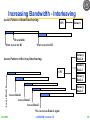
Increasing Bandwidth - Interleaving
Access Pattern without Interleaving:
CPU
Memory
D1 available
Start Access for D1
Start Access for D2
Memory
Bank 0
Access Pattern with 4-way Interleaving:
CPU
Memory
Bank 1
Access Bank 0
Memory
Bank 2
Memory
Bank 3
Access Bank 1
Access Bank 2
Access Bank 3
We can Access Bank 0 again
3/16/2009
cs252-S09, Lecture 15
48
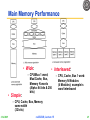
Main Memory Performance
• Wide:
• Simple:
• Interleaved:
– CPU/Mux 1 word;
Mux/Cache, Bus,
Memory N words
(Alpha: 64 bits & 256
bits)
– CPU, Cache, Bus 1 word:
Memory N Modules
(4 Modules); example is
word interleaved
– CPU, Cache, Bus, Memory
same width
(32 bits)
3/16/2009
cs252-S09, Lecture 15
49
Main Memory Performance
• Timing model
– 1 to send address,
– 4 for access time, 10 cycle time, 1 to send data
– Cache Block is 4 words
• Simple M.P.
= 4 x (1+10+1) = 48
• Wide M.P.
= 1 + 10 + 1
= 12
• Interleaved M.P. = 1+10+1 + 3 =15
address
address
address
address
0
4
8
12
1
5
9
13
2
6
10
14
3
7
11
15
Bank 0
3/16/2009
Bank 1
Bank 2
cs252-S09, Lecture 15
Bank 3
50
Avoiding Bank Conflicts
• Lots of banks
int x[256][512];
for (j = 0; j < 512; j = j+1)
for (i = 0; i < 256; i = i+1)
x[i][j] = 2 * x[i][j];
• Even with 128 banks, since 512 is multiple of 128,
conflict on word accesses
• SW: loop interchange or declaring array not power of 2
(“array padding”)
• HW: Prime number of banks
–
–
–
–
3/16/2009
bank number = address mod number of banks
bank number = address mod number of banks
address within bank = address / number of words in bank
modulo & divide per memory access with prime no. banks?
cs252-S09, Lecture 15
51
Finding Bank Number and Address
within a bank
• Problem: Determine the number of banks, Nb and the number of
words in each bank, Wb, such that:
– given address x, it is easy to find the bank where x will be found,
B(x), and the address of x within the bank, A(x).
– for any address x, B(x) and A(x) are unique
– the number of bank conflicts is minimized
• Solution: Use the following relation to determine B(x) and A(x):
B(x) = x MOD Nb
A(x) = x MOD Wb where Nb and Wb are co-prime (no factors)
– Chinese Remainder Theorem shows that B(x) and A(x) unique.
• Condition is satisfied if Nb is prime of form 2m-1:
– Then, 2k = 2k-m (2m-1) + 2k-m 2k MOD Nb = 2k-m MOD Nb= 2j with j < m
– And, remember that: (A+B) MOD C = [(A MOD C)+(B MOD C)] MOD C
• Simple circuit for x mod Nb
– for every power of 2, compute single bit MOD (in advance)
– B(x) = sum of these values MOD Nb
(low complexity circuit, adder with ~ m bits)
3/16/2009
cs252-S09, Lecture 15
52
Quest for DRAM Performance
1. Fast Page mode
– Add timing signals that allow repeated accesses to row buffer
without another row access time
– Such a buffer comes naturally, as each array will buffer 1024 to
2048 bits for each access
2. Synchronous DRAM (SDRAM)
– Add a clock signal to DRAM interface, so that the repeated
transfers would not bear overhead to synchronize with DRAM
controller
3. Double Data Rate (DDR SDRAM)
– Transfer data on both the rising edge and falling edge of the
DRAM clock signal doubling the peak data rate
– DDR2 lowers power by dropping the voltage from 2.5 to 1.8
volts + offers higher clock rates: up to 400 MHz
– DDR3 drops to 1.5 volts + higher clock rates: up to 800 MHz
•
3/16/2009
Improved Bandwidth, not Latency
cs252-S09, Lecture 15
53
Fast Memory Systems: DRAM specific
• Multiple CAS accesses: several names (page mode)
– Extended Data Out (EDO): 30% faster in page mode
• Newer DRAMs to address gap;
what will they cost, will they survive?
– RAMBUS: startup company; reinvented DRAM interface
» Each Chip a module vs. slice of memory
» Short bus between CPU and chips
» Does own refresh
» Variable amount of data returned
» 1 byte / 2 ns (500 MB/s per chip)
– Synchronous DRAM: 2 banks on chip, a clock signal to DRAM, transfer
synchronous to system clock (66 - 150 MHz)
» DDR DRAM: Two transfers per clock (on rising and falling edge)
– Intel claims FB-DIMM is the next big thing
» Stands for “Fully-Buffered Dual-Inline RAM”
» Same basic technology as DDR, but utilizes a serial “daisy-chain”
channel between different memory components.
3/16/2009
cs252-S09, Lecture 15
54
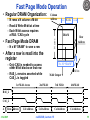
Fast Page Mode Operation
• Regular DRAM Organization:
– N rows x N column x M-bit
– Read & Write M-bit at a time
– Each M-bit access requires
a RAS / CAS cycle
Column
Address
N cols
DRAM
– N x M “SRAM” to save a row
N rows
• Fast Page Mode DRAM
Row
Address
• After a row is read into the
register
– Only CAS is needed to access
other M-bit blocks on that row
– RAS_L remains asserted while
CAS_L is toggled
1st M-bit Access
N x M “SRAM”
M bits
M-bit Output
2nd M-bit
3rd M-bit
4th M-bit
Col Address
Col Address
Col Address
RAS_L
CAS_L
A
Row Address
3/16/2009
Col Address
cs252-S09, Lecture 15
55
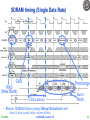
SDRAM timing (Single Data Rate)
CAS
RAS
(New Bank)
x
CAS Latency
Precharge
Burst
READ
• Micron 128M-bit dram (using 2Meg16bit4bank ver)
– Row (12 bits), bank (2 bits), column (9 bits)
3/16/2009
cs252-S09, Lecture 15
56
Double-Data Rate (DDR2) DRAM
200MHz
Clock
Row
Column
Precharge
Row’
Data
[ Micron, 256Mb DDR2 SDRAM datasheet ]
3/16/2009
cs252-S09, Lecture 15
400Mb/s
Data Rate
57
Fastest for sale 4/06 ($125/GB)
DRAM name based on Peak Chip Transfers / Sec
DIMM name based on Peak DIMM MBytes / Sec
Standard
Clock Rate
(MHz)
M transfers
/ second
DRAM
Name
Mbytes/s/
DIMM
DIMM
Name
DDR
133
266
DDR266
2128
PC2100
DDR
150
300
DDR300
2400
PC2400
DDR
200
400
DDR400
3200
PC3200
DDR2
266
533
DDR2-533
4264
PC4300
DDR2
333
667
DDR2-667
5336
PC5300
DDR2
400
800
DDR2-800
6400
PC6400
DDR3
533
1066
DDR3-1066
8528
PC8500
DDR3
666
1333
DDR3-1333
10664
PC10700
DDR3
800
1600
DDR3-1600
12800
PC12800
x2
3/16/2009
x8
cs252-S09, Lecture 15
58
DRAM Packaging
Clock and control signals
~7
Address lines multiplexed
row/column address ~12
DRAM
chip
Data bus
(4b,8b,16b,32b)
• DIMM (Dual Inline Memory Module) contains multiple
chips arranged in “ranks”
• Each rank has clock/control/address signals
connected in parallel (sometimes need buffers to
drive signals to all chips), and data pins work
together to return wide word
– e.g., a rank could implement a 64-bit data bus using 16x4-bit
chips, or a 64-bit data bus using 8x8-bit chips.
• A modern DIMM usually has one or two ranks
(occasionally 4 if high capacity)
– A rank will contain the same number of banks as each
constituent chip (e.g., 4-8)
3/16/2009
cs252-S09, Lecture 15
59
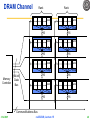
DRAM Channel
Rank
Rank
Bank
Bank
Chip
Chip
16
16
Bank
Bank
Chip
Chip
16
Memory
Controller
16
Bank
Bank
Chip
Chip
16
64-bit
Data
Bus
16
Bank
Bank
Chip
Chip
16
16
Command/Address Bus
3/16/2009
cs252-S09, Lecture 15
60
FB-DIMM Memories
Regular
DIMM
FB-DIMM
• Uses Commodity DRAMs with special controller on
actual DIMM board
• Connection is in a serial form:
FB-DIMM
FB-DIMM
FB-DIMM
FB-DIMM
FB-DIMM
3/16/2009
cs252-S09, Lecture 15
Controller
61
FLASH Memory
Samsung 2007:
– Has a floating gate that can hold charge 16GB, NAND Flash
• Like a normal transistor but:
– To write: raise or lower wordline high enough to cause charges to tunnel
– To read: turn on wordline as if normal transistor
» presence of charge changes threshold and thus measured current
• Two varieties:
– NAND: denser, must be read and written in blocks
– NOR: much less dense, fast to read and write
3/16/2009
cs252-S09, Lecture 15
62
Phase Change memory (IBM, Samsung, Intel)
• Phase Change Memory (called PRAM or PCM)
– Chalcogenide material can change from amorphous to crystalline
state with application of heat
– Two states have very different resistive properties
– Similar to material used in CD-RW process
• Exciting alternative to FLASH
– Higher speed
– May be easy to integrate with CMOS processes
3/16/2009
cs252-S09, Lecture 15
63
Tunneling Magnetic Junction
• Tunneling Magnetic Junction RAM (TMJ-RAM)
– Speed of SRAM, density of DRAM, non-volatile (no refresh)
– “Spintronics”: combination quantum spin and electronics
– Same technology used in high-density disk-drives
3/16/2009
cs252-S09, Lecture 15
64
Conclusion
• Memory wall inspires optimizations since much performance lost
– Reducing hit time: Small and simple caches, Way prediction, Trace caches
– Increasing cache bandwidth: Pipelined caches, Multibanked caches, Nonblocking
caches
– Reducing Miss Penalty: Critical word first, Merging write buffers
– Reducing Miss Rate: Compiler optimizations
– Reducing miss penalty or miss rate via parallelism: Hardware prefetching,
Compiler prefetching
• Performance of programs can be complicated functions of
architecture
– To write fast programs, need to consider architecture
» True on sequential or parallel processor
– We would like simple models to help us design efficient algorithms
• Will “Auto-tuners” replace compilation to optimize performance?
• Main memory is Dense, Slow
– Cycle time > Access time!
• Techniques to optimize memory
–
–
–
–
3/16/2009
Wider Memory
Interleaved Memory: for sequential or independent accesses
Avoiding bank conflicts: SW & HW
DRAM specific optimizations: page mode & Specialty DRAM
cs252-S09, Lecture 15
65